基于协同过滤和标签的混合音乐推荐算法研究
2021-04-18黄川林鲁艳霞
黄川林 鲁艳霞


摘 要:结合音乐这一特定的推荐对象,针对传统单一的推荐算法不能有效解决音乐推荐中的准确度问题,提出一种协同过滤技术和标签相结合的音乐推荐算法。该算法先通过协同过滤技术确定相似用户,再通过相似用户对某一歌手的标签评分预测另一用户对该歌手的偏好程度,从而选择更符合用户喜好的音乐进行推荐,以此提升个性化推荐效率,为优化音乐推荐系统提供参考方法。
关键词:协同过滤;标签;音乐推荐;推荐系统
中图分类号:TP312 文献标识码:A
文章编号:2096-1472(2021)-04-10-04
Abstract: Traditional single recommendation algorithm cannot effectively solve the accuracy problem in music recommendation. In view of music, a specific recommendation object, this paper proposes a music recommendation algorithm combining collaborative filtering technology and tags. First, collaborative filtering technology is used to identify similar users. Then, another users preference for a singer is predicted through similar users' tag ratings for the singer. Thus, recommended music is more in line with the users preference, which enhances personalized recommendation efficiency and provides a reference method for optimizing music recommendation system.
Keywords: collaborative filtering; tags; music recommendation; recommendation system
1 引言(Introduction)
随着移动互联网、云计算、智能终端、物联网技术的飞速发展,文本、音频、视频、图像、社交网络等各种各样的信息在网络上正以爆炸式的形势增长,丰富了人们的日常生活和学习工作内容[1-2]。信息技术和互联网技术的迅速发展产生了海量信息,这些信息虽然极大地丰富了我们的个人需求,但也带来了信息过载的问题。为了更好地满足用户个性化需求,以及解决信息过载问题,推荐系统应运而生。在这个信息过载的时代,互联网已经成为人们生活中最重要的组成部分,然而,如何从海量的互联网信息中筛选出我们感兴趣的内容就成为一个难题。推荐系统根据用户兴趣爱好等特征,个性化推荐满足用户需求的对象,目前已经在电子商务、信息门户、社交网络、移动位置服务、多媒体娱乐等领域得到了广泛应用[3]。
硬件成本的降低和技术的进步导致了数字音乐的快速发展,无论是在线音乐还是移动音乐都深受人们的喜爱。Spotify、Pandora、豆瓣音乐等各类各样的音乐网站和音乐电台在飞速发展中为用户提供了成千上万首歌曲[1]。然而,大量可用的音乐使得用户更难以找到他们喜欢的音乐,这就是所谓的选择悖论[4]。由于音乐具有种类丰富、数量庞大、收听时间短以及连贯性和次序性等特点,传统单一的推荐算法并不能有针对性地解决音乐推荐的准确度问题。如Last.fm是通过协同过滤进行推荐的,Pandora是通过内容相似性进行推荐的[5]。本文根据用户偏好、歌曲标签进行深度数据挖掘,运用协同过滤和基于标签的AHP混合推荐算法为用户推荐适合的音乐,以此提升个性化推荐效率,为优化音乐推荐系统提供参考方法[6]。
2 推荐算法(Recommendation algorithm)
推荐算法是推荐系统的核心和关键部分,也是该领域研究最活跃的方向之一[7],推荐算法的好坏决定了推荐系统的性能和推荐结果的准确性[8]。协同过滤、基于内容、基于规则等推荐算法各有优缺点,为了取长补短,混合算法将各种推荐算法混合进行使用。
2.1 协同过滤算法
在音乐推荐系统中应用最多的一种算法是协同过滤算法,这种算法根据目标用户的习惯爱好、个人兴趣等历史信息而对事物进行评价[9],然后推荐相关物品给用户。这些历史信息可能是用户的浏览或购买记录,也可能是问卷调查等用户填写的相关信息。基于协同過滤的推荐算法具有很强的个性化,可以自动地发现用户潜在的兴趣,从而逐渐提高系统推荐性能[10]。这种方法适合很多推荐对象,包括处理电影、音乐、图书和酒店等非结构化的对象[11]。协同过滤算法的工作原理如图1所示。
2.2 层次分析法
层次分析法(Analytic Hierarchy Process, AHP)是1980年美国著名运筹学家T. L. Saaty在其论文中首次提出的简单而又灵活的多准则决策算法[12]。这种算法将决策专家的主观判断转换为定量的客观表述,本质是一种决策思维方式,把复杂系统分解为各个组成因素,进而按支配关系把这些决策问题的核心影响因素分组,构建层次结构,用层次化模型处理要解决的问题,设置优先级,然后利用两两比较的方式,计算每个因素对最终决策的影响程度,最后还要进行一致性检验[13]。AHP算法通过如下五个步骤来确定属性权重,并得出推荐的综合评分。
第一,定义其评估属性,把要解决的问题层次化处理,如图2所示。
第二,构造比较矩阵。
第三,检验比较矩阵一致性。
第四,计算矩阵权向量。
第五,得出推荐的综合评分。
本文核心算法综合使用了基于用户的协同过滤推荐算法和基于标签的AHP层次分析法。首先,分析计算用户的听歌记录,根据用户选择歌手的播放次数,建立了用户与歌手矩阵模型,模型中的每行表示一个用户,每列表示一个歌手,每个行向量表示用户对每个歌手的喜好程度,再使用余弦相似度算法寻找目标用户的相似用户。然后,基于歌手标签使用AHP层次分析法生成个性化推荐列表,以此推荐给经过协同过滤算法产生的目标用户。
3 个性化的音乐推荐系统(Personalized music recommendation system)
本文的实验数据来源于世界上最大的社交音乐平台Last.fm
在网上公布的数据,在这个音乐库里,有上亿首歌曲曲目和来自全球250个国家超过一千万的歌手[14]。用户可以在Last.fm音乐网站获取免费在线听歌或者下载音乐等多种音乐服务,这使得Last.fm有上千万的用户每个月都在线听歌,产生了海量的用户数据。这些数据包括用户编号、听歌记录、歌曲名、专辑、标签(歌手、流派、年代、心情等描述性信息)、好友关系等丰富的信息。
3.1 基于用户的协同过滤算法寻找相似用户
在个性化的音乐推荐系统中,采用基于用户的协同过滤算法,一般是通过计算用户对音乐的偏好相似度,从而得到最近邻用户。例如,若用户1需要进行个性化推荐,需要先找到同用户1有相同偏好的其他用户,然后将这些用户喜欢的、感兴趣的并且用户1没接触过的歌曲推荐给用户1。
余弦相似度是最常用的相似度算法之一,它被广泛地应用于图像处理、文档检索等领域之中。在协同过滤推荐算法中,评分矩阵中的一行向量代表一个用户。设向量分别为A、B,元素值是用户对产品的评分值,0值代表用户对该产品没有评分。两个向量A、B之间的夹角余弦值就代表了这两个用户之间的相似度。计算公式如下:
本文选取音乐平台中听歌行为比较频繁的用户,其用户编号为135、257、397、560、935、1551,以用户播放次数为评分依据,得到用户对歌手的行为矩阵,如表1所示。
根据矩阵数据,对用户进行两两比较,使用公式(1)计算用户之间的相似度,计算结果如表2所示,例如用户135与用户257的相似度为0.38。由此可知,与用户935最相似的用户为用户257,相似度为0.73。
用户257的播放列表中有50位歌手,其中有15首在用户935的播放列表中。即如果把用戶257的播放列表中的50位歌手都变成推荐列表推荐给用户935,则准确率为15/50×100%=30%。如果可以对用户257的播放列表中的50位歌手按照用户935的收听喜好再进行一次筛选推荐,则可以有效地提高推荐的准确率。
3.2 基于标签的AHP层次分析法推荐音乐
标签是信息系统中用来代表一段信息的无层次的关键词或术语,通过这种用来描述物品的关键词,可以辅助系统对物品的检索。不同系统打标签的方式不尽相同,有作者或专家打的标签,也有普通用户打的标签。用户可以以个人非正式化的语言来编辑标签,表达对物品的看法。利用这些标签数据能够反映用户的兴趣偏好,将其引入推荐系统中,可以辅助建立偏好模型,提高推荐系统的性能。通过数学的方法,使用AHP量化决策因素获得相对于目标层决策问题重要程度的比较值。整个过程需要经过以下四个步骤:
(1)建立问题模型
AHP层次分析法建立了目标层、准则层、方案层三层模型,来定量分析那些抽象而主观的决策问题。本文拟推荐的目标用户为用户935,影响用户对歌手喜爱度的因素有很多。在听歌过程中,用户935最感兴趣的标签包括电子音乐(electronic)、电子体音乐(ebm)、工业音乐(industrial)、德国音乐(german)、合成音乐(synthpop)、暗黑电音(dark electro),这些标签的使用次数如表3所示,以此构建的推荐层次分析模型如图3所示。
由表3可以看出,用户935在选择歌手时最看重的是“电子音乐”,而“暗黑电音”的重要性是最低的。
(2)构建比较矩阵
采用1—9量化指标构建比较矩阵,来量化因素之间的重要程度。通过评价因素两两之间的相对重要程度,来得到某一决策问题的影响因素相对于解决该问题的权重。通过对全局的统筹把握,决策人对比两两因素之间的重要性,以此划分为同等重要、稍微重要、明显重要、强烈重要和极其重要共五个等级,并且每个等级都用1—9的数字进行标注[13],如表4所示。
影响用户对歌手喜好的因素有很多,且不同的用户有不同的权重考量,通常用户意识中对于这些因素重要性的考虑都是不清晰的。采用九级标度法构造这些因素间重要程度比较矩阵,通过求解比较矩阵的特征向量,得到各因素相对重要性程度的权重向量,从而将各因素的重要性进行量化[15]。以目标用户935所做的比较矩阵为例进行说明,如表5所示,例如:“电子音乐”相对于“工业音乐”的重要程度是4,而“工业音乐”相对于“电子音乐”的重要程度是1/4。
(3)检验矩阵的一致性
使用AHP方法,无论在何种阶段、由何人分析,最终得到的决策结果都不能过分偏离理想决策方案,即需要保持思维的一致性。对于比较矩阵是否具有完全一致性,AHP决策分析法提出了数学化的指标:一致性指标CI(Consistency Index)。利用CI反映比较矩阵偏离一致性的程度,CI值越大,表示该矩阵偏移一致性程度越大,反之越小,其计算如公式(2)所示:
其中,为比较矩阵A的最大特征根,n为比较矩阵的阶数。通过计算可得,用户935所做的比较矩阵中最大特征值=6.3684,根据公式(2),CI=(6.3684-6)/5=0.0737。
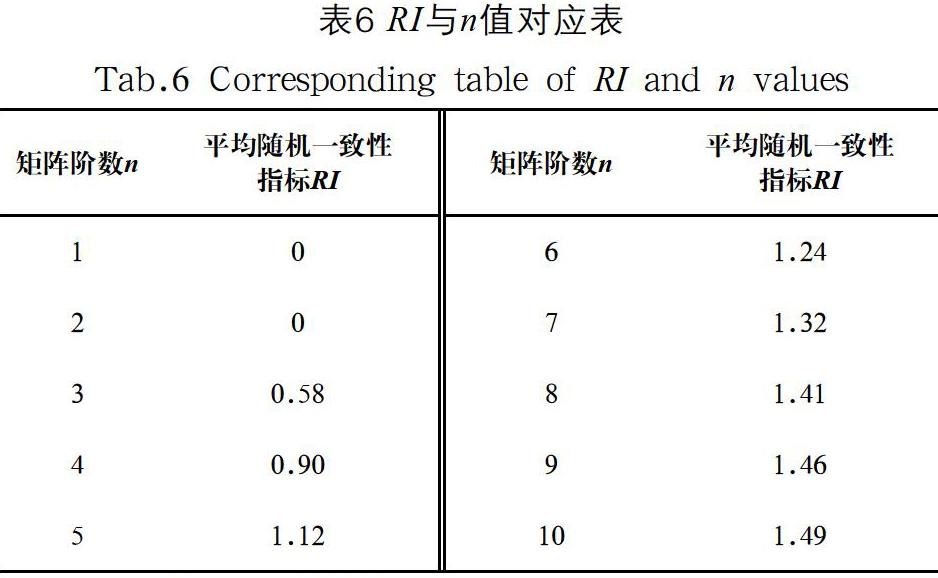
AHP通过引入平均随机一致性指标RI(Random Index),对比较矩阵进行一致性检验,避免比较矩阵出现逻辑性错误[16]。RI与n值的对应关系如表6所示。
通过随机一致性比率CR(Consistency Ratio)的大小检验比较矩阵的一致性,如公式(3)所示:
当CR<0.10时,说明比较矩阵构建合理,通过一致性检验;反之,当CR≥0.10时,说明该比较矩阵包含逻辑判断错误,就需要修正比较矩阵。用户935所做的比较矩阵A为六阶矩阵,所对应的RI值为1.24。根据公式(3),CR=0.0737/1.24=0.0594,经计算CR<0.10,通过一致性检验。
(4)计算矩阵权向量
一致性检验通过合格后,构建的比较矩阵就可以用来计算每个因素的权重值。计算得到的权向量为:
U=(0.8243,0.4700,0.2636,0.1454,0.0819,0.0480)
权向量U的各分量即为歌手在用户935心中的重要性量化数值,可以看出,电子音乐、电子体音乐、工业音乐、德国音乐、合成音乐、暗黑电音在用户935中的重要性依次为0.8243、0.4700、0.2636、0.1454、0.0819、0.0480。
(5)歌手的综合评分
本文在Last.fm音乐网站中抽取了目标用户935的相似用户257对六位歌手关于评价因素的播放次数,如表7所示。
这里把播放次数作为标签评分,用户257对某位歌手的“电子音乐”标签评分为h1,而“电子音乐”在用户935心中的重要性为0.8243,那么可以认为该歌手的“电子音乐”在用户935心中的加权评分为0.8243h1。同样,计算电子体音乐、工业音乐、德国音乐、合成音乐、暗黑电音在用户935心中的加权评分,分别计为0.4700h2、0.2636h3、0.1454h4、0.0819h5、0.0480h6。将各个因素的评分相加即为该歌手在用户935心中的综合评分H:
H=0.8243h1+0.4700h2+0.2636h3+0.1454h4+0.0819h5+0.0480h6
按照以上步骤分别计算歌手1、歌手2、歌手3、歌手4、歌手5、歌手6的综合评分:
H1=0.8243×2+0.4700×5+0.2636×8+0.1454×4+0.0819×9+0.0480×1=7.4741
H2=0.8243×6+0.4700×4+0.2636×5+0.1454×2+0.0819×7+0.0480×3=9.1519
H3=0.8243×9+0.4700×7+0.2636×2+0.1454×4+0.0819×5+0.0480×6=12.5150
H4=0.8243×7+0.4700×8+0.2636×3+0.1454×3+0.0819×2+0.0480×5=11.1609
H5=0.8243×8+0.4700×9+0.2636×4+0.1454×5+0.0819×6+0.0480×3=13.2412
H6=0.8243×6+0.4700×2+0.2636×3+0.1454×4+0.0819×7+0.0480×9=8.2635
最后將综合评分较高的歌手3、歌手4、歌手5推荐给用户935。
按照上述AHP推荐方法,对用户257的播放列表中的50位歌手全部进行综合评分,筛选出评分较高的25位歌手进行推荐,实验表明,推荐列表中有13首歌曲都是目标用户935测试集中的歌曲,准确率为13/25×100%=52%。
4 结论(Conclusion)
随着音乐业务的迅猛发展,音乐库越来越丰富,用户喜好的差异化也越来越大。现在音乐业务推广的一个难点就是如何便捷、快速地从庞大的音乐库中对用户进行精准的个性化推荐。本文通过对音乐网站中保存的海量用户行为记录进行分析,通过协同过滤算法确定相似用户,再基于用户的兴趣标签,为用户做出个性化音乐推荐,给音乐领域的推荐算法提供了一种新的思路和参考。
参考文献(References)
[1] 金蕾.个性化音乐推荐算法的研究与实现[D].济南:山东大学,2017.
[2] 卢丽静,朱杰,杨志芳.基于大数据的个性化音乐推荐系统[J].广西通信技术,2015 (1):24-27.
[3] 刘治宇.基于混合推荐算法的情境感知音乐推荐系统研究与实现[D].成都:电子科技大学,2015.
[4] HYUNG Z, LEE K. Music recommendation using text analysis on song requests to radio stations[J]. Expert Systems with Applications, 2014, 41(5):2608-2618.
[5] CAI R, ZHANG C, WANG C, et al. MusicSense: Contextual music recommendation using emotional allocation modeling[C]. The 15th ACM International Conference on Multimedia, 2007.
[6] 胡昌平,查梦娟,石宇.融合个体兴趣与群体认知的音乐个性化推荐模型[J].信息资源管理学报,2018,29(2):97-103.
[7] 李新卫.基于Hadoop的音乐推荐系统的研究与实现[D].西安:西安工业大学,2018.
[8] 李卓远,曾丹,张之江.基于协同过滤和音乐情绪的音乐推荐系统研究[J].工业控制计算机,2018,31(7):130-131;134.
[9] 林丽姗.基于协同过滤算法的社区音乐推荐系统的设计与实现[D].长沙:湖南大学,2016.
[10] 蔡英文.基于多属性评分的电子商务个性化推荐算法研究[D].南昌:江西财经大学,2016.
[11] 董晓梅.图书借阅系统中的协同过滤推荐技术研究[D].大连:大连理工大学,2015.
[12] 李亮.评价中权系数理论与方法比较[D].上海:上海交通大学,2009.
[13] 王璐.基于本体的个性化推荐系统[D].成都:电子科技大学,2013.
[14] 蔡瑞瑜.基于社会上下文约束和物品上下文约束的协同推荐[D].杭州:浙江大学,2012.
[15] 郭宇红,杨金然.一种基于AHP的智能电影推荐方法[J].南京邮电大学学报(自然科学版),2015(35):105.
[16] 单毓馥,李丙洋.电子商务推荐系统中服装推荐问题研究[J].毛纺科技,2016,335(5):70-73.
作者简介:
黄川林(1979-),女,硕士,副教授.研究领域:电子商务数据分析,个性化推荐.
鲁艳霞(1977-),女,硕士,教授.研究领域:舆情分析,应急管理.
