2000-2017 年联合国各成员国的SDGs 指标对相关性系数数据集
2021-04-15高天张丽丽黎建辉
高天,张丽丽,黎建辉*
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
引 言
联合国可持续发展目标(Sustainable Development Goals,SDGs)是联合国在《2030 议程》中提出的一系列新的发展目标[1],全球发达国家和发展中国家均将其作为社会经济协调发展的重要指导,来保障人类社会的长期稳定和健康发展。由于SDGs 的3 级指标主要支撑2 级具体目标的落实,且用于评估《2030 年议程》未来的落实情况[2],学界已经广泛地展开关于SDGs 目标和指标之间关联性的研究。
可持续发展目标的相关性分析需要以统计的指标数据为基础。《可持续发展报告2020》[3](以下简称报告)中提供的联合国全体193 个成员国的统计数据包括了每项指标从2000-2020 年的具体数值,但有些指标的数据不完整,个别年份存在缺失。且指标的时间序列数据只能反映指标本身随年份变化的结果,而无法看出与其他指标之间的关联性。因此,基于报告中已统计的元数据,通过分析计算得出指标的关联性数据,不仅可以直观反映出SDGs 整体指标框架之间的联系,还可以为各国的政策实施和完善提供方法学的支持。
本文涉及的SDGs 的3 级指标数据包含基于对比分析所得的最优相关分析算法——MIC 算法计算得出的指标对之间的相关系数和基于Spearman 算法计算得到的指标对相关方向,全面地描述了SDGs 指标数据之间的关联性,为联合国各成员国未来进一步研究和实施可持续发展目标提供了可靠的数据支撑。
1 数据采集和处理方法
1.1 数据来源
基于数据的规律性和可用性,本文所使用的SDGs 指标的时间序列数据来自于《可持续发展报告2020》数据[3]。其中包含联合国成员国家一共193 个,时间跨度为2000-2020 年共21 年,指标从SDG1 到SDG17 共包含85 项。
1.2 数据处理方法
数据处理方法一共有4 阶段:数据预处理,相关性算法对比,基于最优相关性算法MIC 的指标对相关系数的计算,和基于Spearman 算法的指标对相关方向的计算,以及南半球20 个国家的SDGs指标对系数可视化,整体流程如图1 所示。
1.2.1 数据预处理
(1)代码名称统一规范化
本文首先对原始数据中不一致的指标代码进行名称统一。原始数据中共有3 处指标代码不一致,统一后的结果为:“sdg2_stunting”修改为“sdg2_stuntihme”,“sdg2_wasting”修改为“sdg2_wasteihme”,“sdg5_familypl”修改为“sdg5_fplmodel”。
(2)数据组织
按照国家将指标数据分别进行存储,对每个国家的指标进行处理。
①完整性查验与预处理
处理规则为:a.对于21 年之中超过5 年以上没有数据的指标进行直接删除;b.根据每个国家每年的数据缺失率,最终选定了2000-2017 年的指标数据。
② 数据补全与存储
a.对于有一些年份缺失数据的指标利用Python 的Sklearn 库中KNNImputer 函数进行补全,其中k 的参数设为3;b.最后将每个国家预处理好的数据存储成CSV 格式的文件,方便未来对于数据的计算。
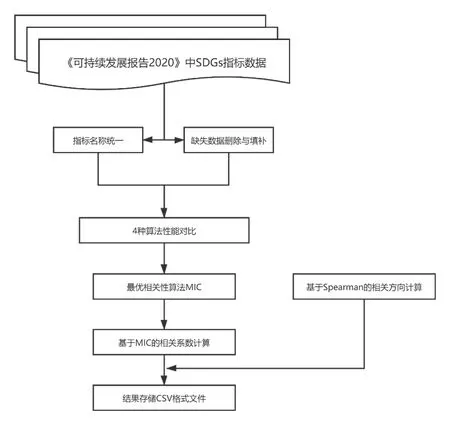
图1 SDGs 指标数据处理流程
1.2.2 相关性算法性能对比分析和选择
有代表性的相关性算法有以下4 种,其各自的优缺点如表1 所示。

表1 4 种相关性算法对比
SDGs 指标数据存在多种函数和非函数关系,由表1 可知,MIC 在与其他相关性算法相比之下,可以探测到更多的相关关系。无论两个变量是线性、立方、指数、周期,还是非线性关系,MIC 都可以探测出来,且可以给到较高的分数[7]。因此本文先将MIC 作为探测SDGs 指标对之间相关性的最优算法测度。但MIC 无法检测到相关方向,因此我们选取Spearman 相关系数来补充衡量指标对之间的相关方向。
1.2.3 基于MIC 算法的指标对相关系数计算
本研究利用MIC 算法,对193 个联合国成员国的共62 项可实际使用指标进行了相关系数的计算。根据每个国家的指标对,将每项指标两两配对,共有1766 个指标对。分别对每个国家的指标对进行MIC 的相关系数计算,每个国家的数据为一列,对193 个国家的数据进行合并存储。
1.2.4 基于Spearman 算法的指标对相关方向计算
由MIC 的定义和性质可知,MIC 系数的范围在0-1 之间,本质上提供了相关程度的参考,而对于相关方向,其并无法表示。Spearman 算法可以衡量2 个变量之间的单调性,且不受变量的分布和样本容量影响。因此本研究利用Spearman 算法,对每个指标对进行相关方向的判定,输出结果1 表示正相关,−1 表示负相关(1 和−1 与Spearman 的相关系数取值无关,仅为相关方向的符号),作为MIC 算法的补充。每个国家的处理过程和1.2.3 一样,最终结果存储到一个CSV 格式的文件中。
1.2.5 南半球20 个国家的SDGs 指标对系数可视化
SDGs 指标对相关系数可用于缺失数据补全,提供SDGs 实施方向指南,发掘SDGs 发展进程,有助于对SDGs 问题的及时发现与政策校准,这在发展中国家的意义尤为突出。由于地理位置和历史原因,南半球的国家绝大部分都是发展中国家,其更应该受到国际的关注。因此本研究根据南半球各国的指标数量,选取联合国成员国南半球国家中数据完整性前20 的国家,以热力图形式按国别展示其SDGs 指标对的相关关系,图片存储在数据集中。(注:图片中为显示出指标对的相关方向的颜色差异,因此将负相关的MIC 系数取负,负号仅代表相关方向。)
2 数据样本描述
本数据包括2000-2017 年间,共193 个联合国成员国的SDGs 的指标对的MIC 相关系数,以及相关方向。为方便计算和应用,本研究将数据存储名为Correlation coefficient of Indicator pairs.csv 的文件,横轴代表国家,纵轴代表指标对相关系数的和得分。原始数据集由文献[3]所提供,该数据集包括About、Overview、Codebook、SDR2020 Data、Raw Trend Data 4 共5 张子表。其中Codebook表中详细描述了每一项指标的特征,Raw Trend Data 是193 个国家2000-2020 年的指标原始数据集。根据预处理后所得数据集,最终一共有62 项可用指标,经无重复互相配对后共有1766 个指标对。为展示数据集样本,此节随机选取南半球的一个成员国“安哥拉(Angola)”的数据集以及其可视化结果,如表2 和图2 所示。整体数据集内指标对出现的国家数量和缺失国家部分结果见表3。

表2 SDGs 指标对相关系数和相关方向(Angola,前15 个指标对)
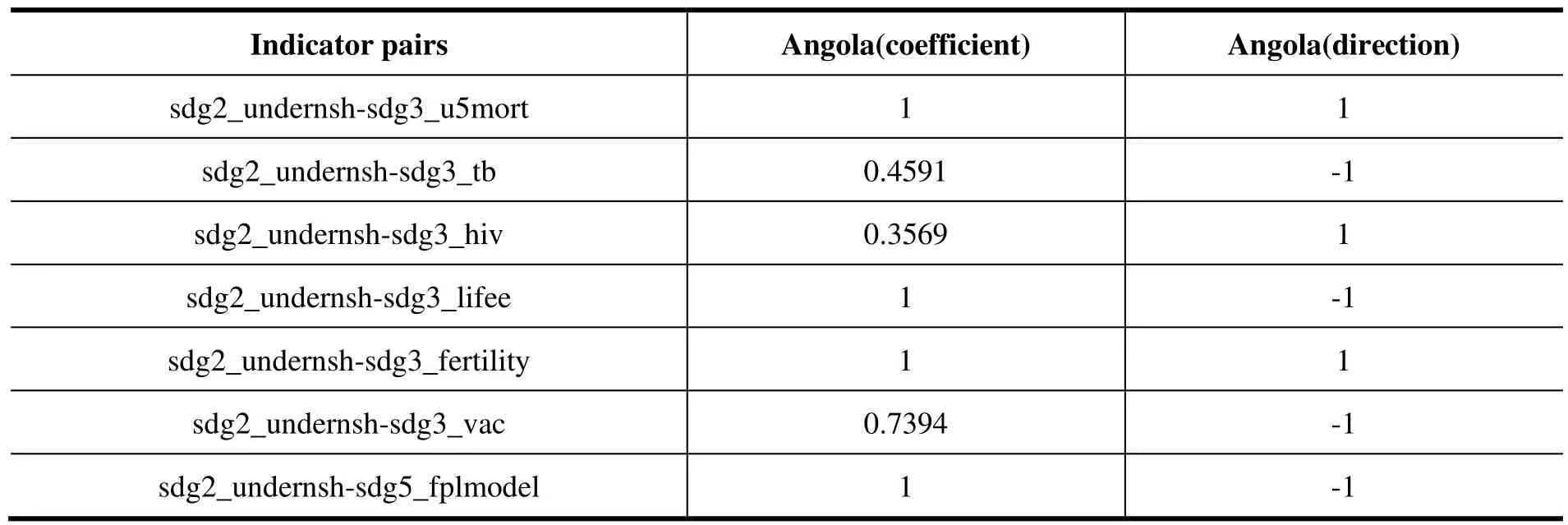
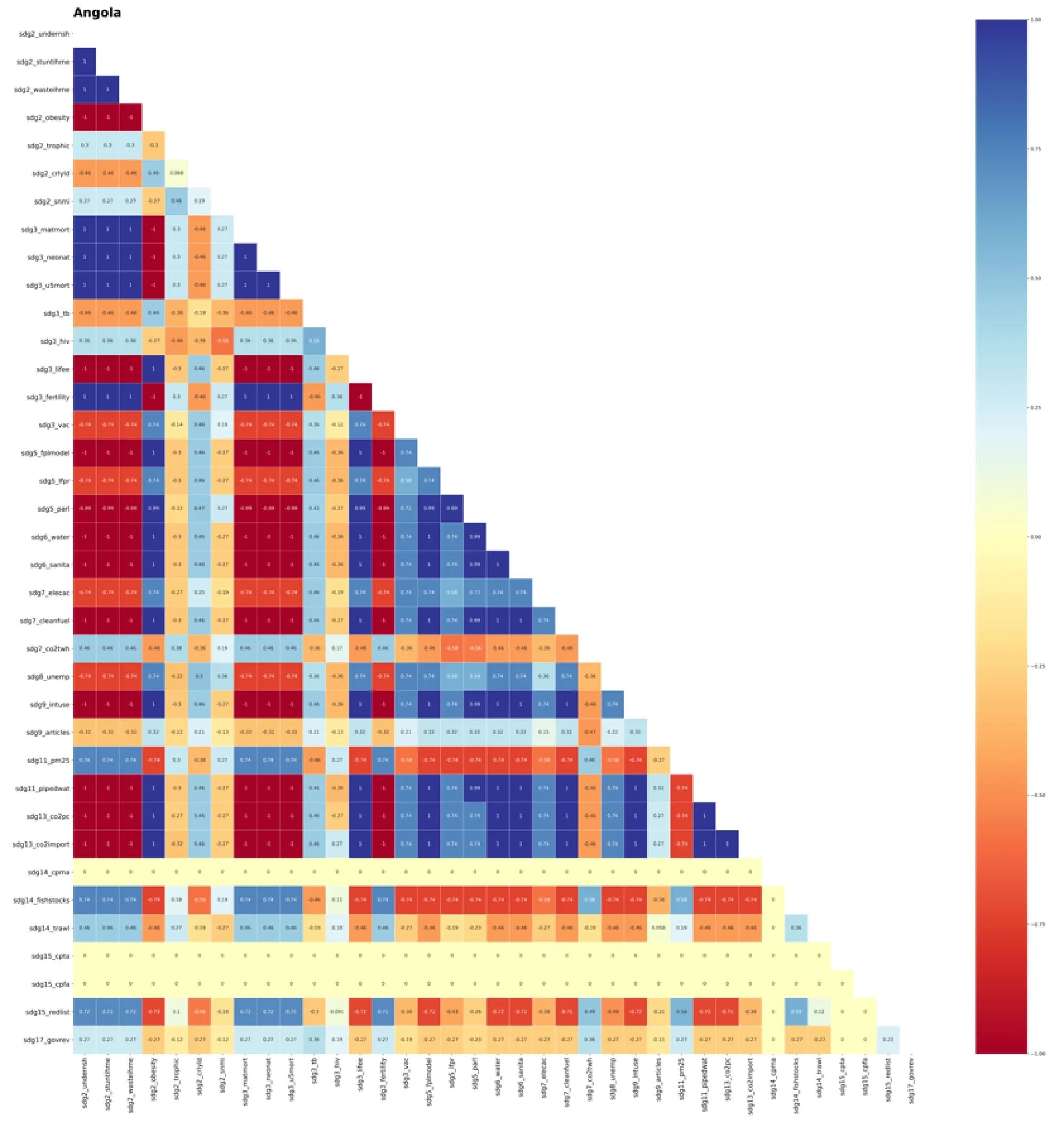
图2 SDGs 指标对相关系数热力图(Angola)

表3 SDGs 指标对出现国家数量和缺失国家(部分)
3 数据质量控制和评估
本数据集的质量控制体现在两方面:一是数据预处理中对原始指标时间序列的名称统一、删减和补全;二是对选取MIC 算法进行实际的验证。
3.1 数据预处理控制
对于原始数据的预处理是后期SDGs 指标数据相关性分析的必须前提,名称不统一和缺失的数据会对后续的分析产生很大影响。其中名称统一详见第1.2.1 节。Olga Troyanskaya 和Michael Cantor等人[8]基于无噪声的时间序列、有噪声的时间序列和非时间序列3 组基因微矩阵的数据集,利用KNN算法、SVD 算法和行平均算法进行对比验证,证实了KNN 算法在估算缺失值方面具有更好的稳定性和健壮性。因此本文选用KNN 填补法对SDGs 指标数据进行缺失值估算填充。
3.2 MIC 算法的质量检验
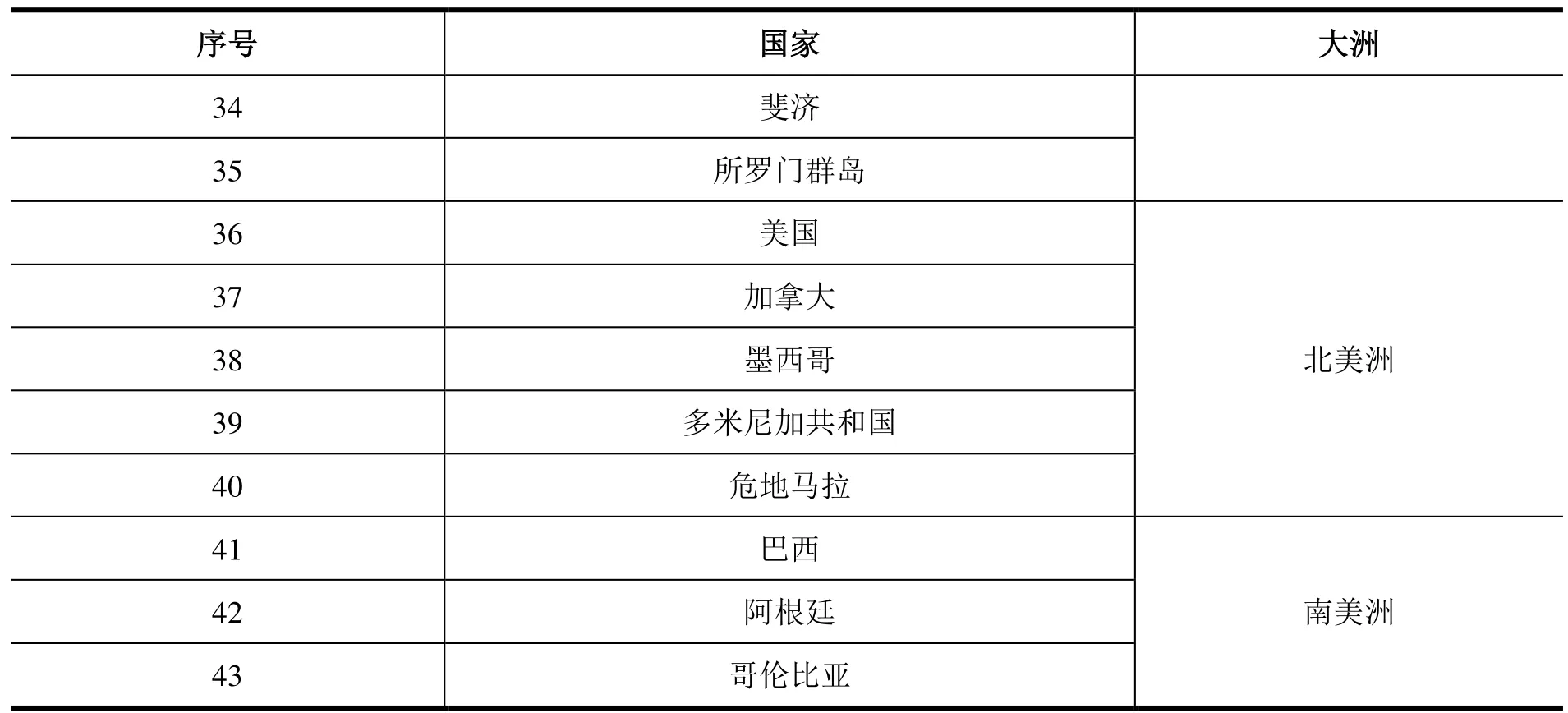
由于国家数量较多,本研究依据每个大洲的GDP 排名[9],选取了排名靠前的20%的国家(共43个)的指标数据对4 种相关性算法进行了对比实验。对SDGs 指标数据的相关性研究从根本上是要探索和发现指标之间更多的关联性,在此基础上本文提出了两种评价维度用来评价4 种相关性算法的优劣。43 个国家的名字如表4 所示。

表4 43 个国家(排名不分先后)
两种评价维度:公式(1)代表广度覆盖,公式(2)、(3)代表深度覆盖[10]。

其中,Sa代表利用Ma算法对相关系数矩阵进行阈值λ(|λ|∈[0,1])筛选后得到的指标对集合(其中不包含同一指标与本身的相关性得分),Sb同理。S代表总指标对的集合。广度覆盖表示在Ma方法下探测到的有效的指标对占总体指标对的比例;深度覆盖表示在Ma和Mb方法都能探测到的有效指标对中,分别占Ma方法下的指标对和Mb方法下的指标对的比例。
43 个国家的总指标对数量如图3 所示。

图3 43 个国家的总指标对数量
对于前3 种传统的统计学相关性算法进行显著性检验,Pearson、Spearman、Kendall 在显著性水平α=0.05的条件下,分别查表[11-12]得到相关系数临界值为:rp=0.468,rs=0.503,rk=0.317,自由度均为18-2=16。根据3 种测度算法的相关系数临界值,可以计算指标对在3 种算法测度下的相关系数满足|rp|>0.468,|rs|>0.503,|rk|>0.317 (包括了正相关和负相关两种相关方向)的条件下,指标对之间拒绝零假设,存在相关关系。
MIC 和其他3 种相关性算法测度的广度覆盖和深度覆盖分别如图4 和图5 所示。从图中分布可以看出,对于两种评价维度,MIC 对于其他3 种测度的覆盖,明显优于其他3 种测度对MIC 的覆盖。这说明MIC 可以探测到更广泛的相关关系,因此选取MIC 算法作为SDGs 指标数据相关性分析的最优算法。
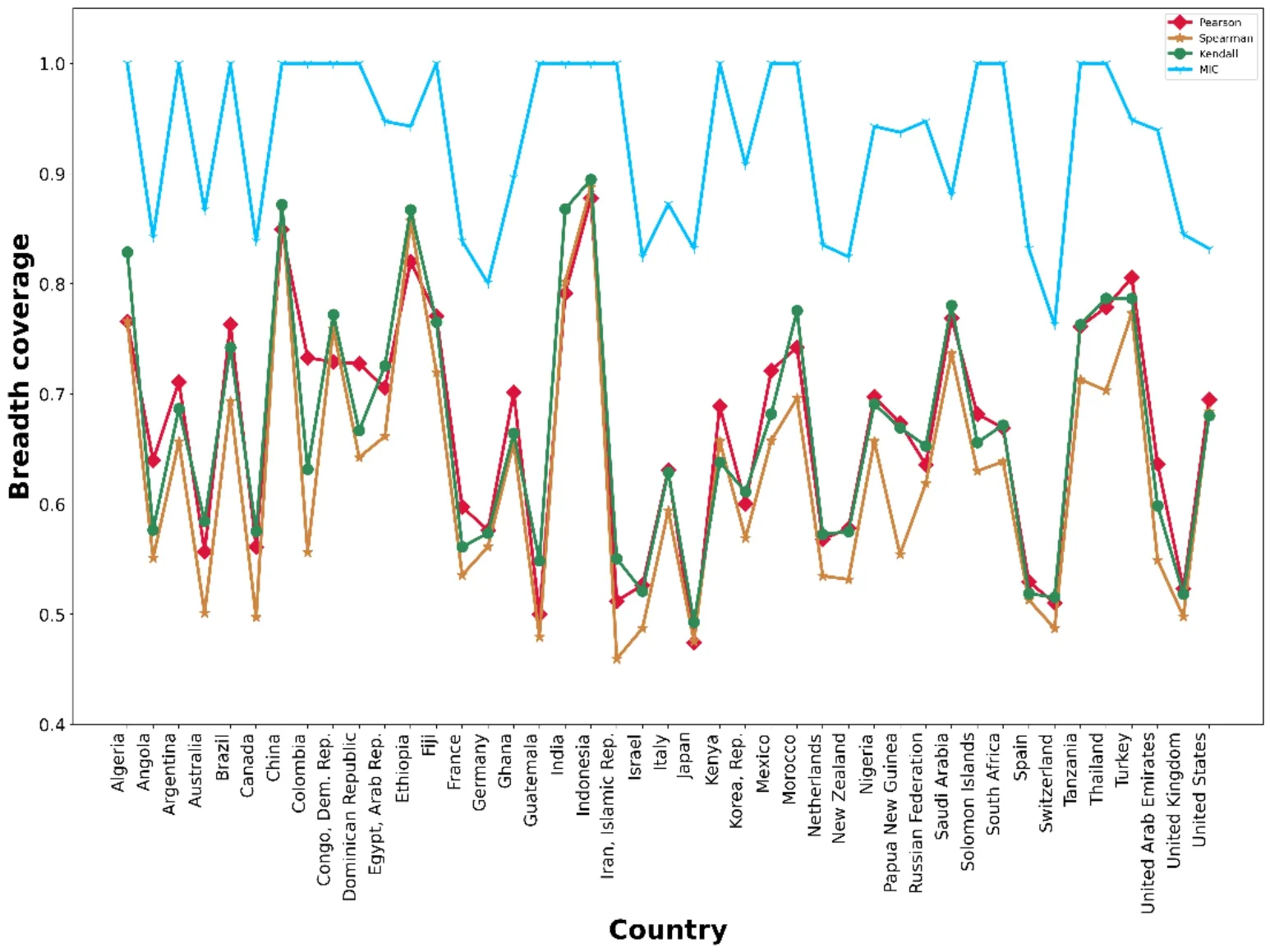
图4 43 个国家广度覆盖评价维度对比结果
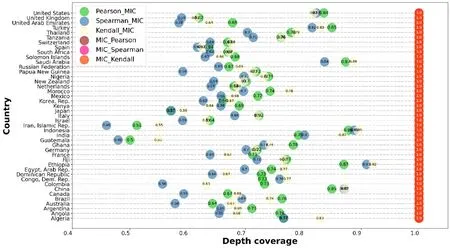
图5 43 个国家深度评价维度对比结果
4 数据价值
SDGs 的目标涵盖了经济、政治、人文等多个领域,截止到2020 年,SDGs 共有17 个总体目标,169 个相关目标和230 多个用来监测实施进展情况的指标。从出现国家次数排名前20 的总指标对中可以看出,科技期刊论文数量、与能源相关的二氧化碳排放量和物种生存指数红色名单这3 个指标均被所有国家统计,这意味着这些指标对所有国家都具有广泛的影响效应。可以更深层次地反映出,各国对于科技、能源和生物的重视应不亚于经济发展的重视。对于出现次数较少的指标如sdg9_netacc〔Gap in internet access by income (percentage points)〕和sdg10_adjgini(Gini coefficient adjusted for top income)等,可能与数据缺失量较大有关。需要各国政府进一步加强对这些问题的关注,督促有关部门尽快制定和完善监测工作和统计方案,以保障从各个方面推进可持续发展议程的实质进展。
本数据集包括联合国193 个成员国的2000-2017 年的SDGs 62 项可利用指标对相关系数和相关方向,以及南半球数据量排名前20 的国家的相关系数可视化结果。数据集存储在CAB 格式的文件中。相关系数和相关方向包含了SDGs 指标数据较为有价值的相关性信息,其中相关系数反映了指标之间的相关程度,进而反映了指标之间影响作用的大小;相关方向反映了指标之间互相影响的方向,揭示了SDGs 指标之间的促进和制约关系。本数据集为SDGs 指标监测和实施提供了一定的参考价值,用户既可用来分析SDGs 指标之间促进和制约的关系,亦可参考制定相应政策。
致 谢
感谢基金项目对于本研究的支持,以及感谢Sachs J、Schmidt-Traub 等人提供的原始数据。
数据作者分工职责
高天(1995—),男,内蒙古呼和浩特市人,在读硕士研究生,研究方向为大数据挖掘与应用。主要承担工作:数据处理、论文撰写。
张丽丽(1984—),女,高级工程师,研究方向为开放科学、开放数据技术政策,信息经济学。主要承担工作:数据校核、质量控制。
黎建辉(1973—),男,研究员,研究方向为大数据资源开放共享、大数据管理技术、大数据计算与分析技术等。主要承担工作:文章框架和方向的把握。
