中国典型城市建筑物实例数据集
2021-04-15吴开顺郑道远陈妍伶曾林芸张嘉辉柴生华徐文杰杨永亮李圣文刘袁缘方芳
吴开顺,郑道远,陈妍伶,曾林芸,张嘉辉,柴生华,徐文杰,杨永亮,李圣文,,刘袁缘,,方芳,*
1.中国地质大学(武汉)国家地理信息系统工程技术研究中心,武汉 430074
2.中国地质大学(武汉)地理与信息工程学院,武汉 430074
引 言
建筑物轮廓信息是最重要的基础地理信息之一,在日常生活、经济建设和国防建设中发挥着重要的作用。遥感影像建筑物检测和提取在城市规划、人口估计、地形图制作和更新等应用中都具有极为重要的意义[1]。相比人工遥感解译与矢量化,自动化的遥感影像建筑物轮廓提取方法,不仅节省人力物力,而且效率高、信息提取周期短。
近年来,随着深度学习技术的不断发展,出现了基于深度学习的高精度建筑物轮廓信息自动提取方法,识别精度获得显著提升。大量的数据样本是训练深度学习模型、提升建筑物自动提取性能的关键。在计算机视觉领域,ImageNet[2]、MS COCO[3]等开放数据集极大地促进了深度学习方法的发展。然而,可供开放使用的建筑物提取数据集相对缺乏[1]。目前常用的建筑物提取数据集主要有AIRS 数据集[4]、WHU 建筑物数据集[1]和Inria 遥感影像数据集[5]。此外,马萨诸塞数据集[6]由于影像质量和分辨率较低,较少应用于建筑物提取的相关研究;ISPRS[7]及竞赛数据集[8]覆盖区域过小,很难反映出建筑物的多样性。需要指出的是,遥感影像中的建筑物影像在时空分布、形态、背景环境上存在较大差异,模型精度和泛化能力与训练时采用的数据集密切相关。但是目前尚未见发表中国地区的建筑物提取公开数据集,这在一定程度上制约着适应中国地区建筑物自动提取方法及应用的研究。
笔者基于高分辨率遥感影像构建了中国地区面向城市建筑物检测和提取的建筑物实例分割数据集。本数据集覆盖了国内4 个具有代表性的城市,反映国内城市建筑物自身和背景环境的特点,为中国基础数据的构建提供数据支撑,以期推进相关学术的深入研究。
1 数据采集和处理方法
本数据集选取北京、上海、深圳、武汉等4 个具有代表性的城市中心城区作为数据采集目标区域,具体位置如表1 所示。原始数据源自由谷歌提供的19 级卫星影像,地面分辨率为0.29 m。为了提高数据集的通用性,数据区域的选取包括正射影像和非正射影像区域、建筑物稀疏分布和密集分布区域,同时考虑建筑物轮廓形状多样性等因素。数据集样本覆盖区域共计约120 平方公里。

表1 数据采集目标区域信息
数据处理及标注的流程如图1 所示,处理流程主要包含数据预处理阶段、人工标注阶段和人机交互标注阶段。
首先,在数据预处理阶段,针对4 个城市的原始卫星影像,人工筛选并截取无重叠的82 块5000×5000 像素大小的影像区域。同时,参考现有标准实例分割数据集格式,将每幅影像统一切割为100幅500×500 像素大小的瓦片。本数据集从以上瓦片数据中随机选取7260 个区域作为样本进行标注,其中北京2237 个,深圳2344 个,上海1231 个,武汉1448 个。
在人工标注阶段,首先采用数据标注软件(labelme[9])对20%的遥感影像数据建筑物轮廓进行标注,形成初始样本集;随后,基于初始样本集训练神经网络模型,使模型具有初步处理的能力。
在交互式标注阶段,借鉴反向传播修正机制(Backpropagating Refinement Scheme,BRS)[10]对其余80%的数据进行交互式数据标注。最终获得全部数据的建筑物实例标签,完成数据集的制作。
2 数据样本描述
本数据集以“遥感影像+数据标注文件”的形式组织存储,分别存储原始遥感影像和所对应的建筑物轮廓标注信息。数据集样本包括训练集和测试集两个文件夹,每个文件夹包含一个遥感影像数据文件夹和一个json 格式标注文件。数据集的文件组织形式如表2 所示。

图1 数据处理流程图

表2 数据集文件组织形式
其中,tif 格式文件为500×500 像素的包含位置信息的原始遥感影像;json 格式文件则描述了该遥感影像所对应的建筑物轮廓标注信息,主要包括4 个方面的信息:info、images、categories 和annotations。其中,info 记录的是数据集的制作年份、版本、描述等基本信息;images 记录了数据集中影像的大小等信息;categories 将类别从名称映射到类别编号;annotations 则记录了标注编号、标注对应的影像编号、建筑物轮廓点坐标等标注信息。数据标注文件的组织形式如图2 所示。

图2 数据标注文件的组织形式
图3 展示了在4 个城市中选取的具有代表性的遥感影像及相应的建筑物轮廓。
3 数据质量控制和评估
为保证数据集质量,我们在影像整理和检查、人工标注和交互式标注阶段均采用了完整的质量控制过程(如图4 所示),通过多重检查保证标注数据的可靠性、完整性和统一性。
在影像整理和检查阶段,人工剔除了失真、畸变、模糊等影像,以减少原始影像引入的噪声。在人工标注阶段采用人工交叉检验方法检查标注结果并修正发现的问题,检查内容包括标注轮廓不完整、建筑物标注遗漏以及非建筑物误标注为建筑物等。交互式标注阶段则重点检查标签文件的准确性、一致性,确保标注质量。为避免影像标签缺失、标签与影像匹配错误等问题,我们采用循环遍历算法进行检验,并对错误数据逐一确认和修改。

图3 数据集样例展示
此外,在制作最终的标注文件之前,为了确保数据组织按照既定的规则进行,所有的遥感影像及其所对应的标注信息均通过程序自动从原始数据中读取得到,并按照规则批量化自动命名,最后采取人工方式进行复核。通过以上步骤,本数据集的质量能够得到良好的保证。
4 数据价值
本数据集是首个公开的取材于国内城市的高分辨率遥感影像城市建筑物轮廓的实例分割数据集,从一定程度上反映了国内的建筑物特征和遥感影像的关系,丰富了遥感领域建筑物数据集,有望更好地支撑国内遥感影像建筑物提取的研究和生产。本数据集的组织和标注方式与常用实例分割数据集一致,可以很方便地服务于影像分割任务。
5 数据使用方法和建议
本数据集可用于实例分割任务和基于像素级别的语义分割任务。数据集的使用方法与常用于上述两种分割任务的标准数据集使用方法一致,总体步骤如图5 所示。
对于实例分割任务,本数据集采用的标注格式与实例分割数据集MS COCO 相同,使用方式相同。实例分割任务可通过解析json 文件,从annotations 字段中批量读取建筑物轮廓标注;从images字段中获取影像存储路径,进而获取实例标注所对应的建筑物影像。实例分割模型可将获取的标注和影像两类信息作为输入,进行模型的训练和预测。
语义分割的类别标签是像素级的,其中建筑物区域对应的像素值为1,非建筑物区域对应的像素值为0。每个样本的标签存储在一个png 文件中,其原始影像文件存储在与标签相同文件名的tif 文件中。语义分割任务依次读取每个样本的标注和影像文件,输入到语义分割模型中进行训练和预测。
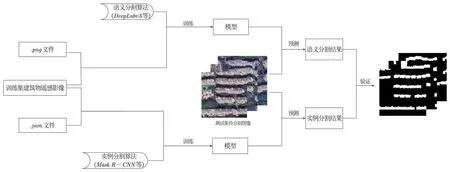
图5 数据使用流程
后续过程需根据实际任务进行设计,主要包括模型训练、预测和精度验证等。两种任务使用中的模型也在不断发展,现有经典模型如Mask R-CNN[11],DeepLabv3[12]等,此文不再赘述。
数据作者分工职责
吴开顺(1995—),男,四川省彭州市人,在读硕士研究生,研究方向为图像智能处理及遥感应用。主要承担工作:数据集整体结构设计,交互式标注算法研究与实现。
郑道远(1999—),男,湖北省荆州市人,在读硕士研究生,研究方向为目标检测、图像分割及遥感应用。主要承担工作:数据集人工及交互式标注,论文初稿撰写。
陈妍伶(1997—),女,四川省射洪市人,在读硕士研究生,研究方向为大数据城市意向分析。主要承担工作:数据集人工及交互式标注。
曾林芸(1996—),女,四川省成都市人,在读硕士研究生,研究方向为图卷积神经网络及应用。主要承担工作:数据集人工及交互式标注。
张嘉辉(1998—),女,山东省潍坊市人,在读硕士研究生,研究方向为多模态图像数据融合及应用。主要承担工作:数据集人工及交互式标注。
柴生华(2000—),男,河北省承德市人,在读本科生。主要承担工作:数据集人工标注。
徐文杰(2000—),男,湖北省武汉市人,在读本科生。主要承担工作:数据集人工标注。
杨永亮(1999—),男,甘肃省武威市人,在读本科生。主要承担工作:数据集人工标注。
李圣文(1978—),男,山东省济宁市人,博士,副教授,研究方向为时空大数据挖掘与机器学习。主要承担工作:论文方向指导与质量把关。
刘袁缘(1984—),女,江西省景德镇人,博士,副教授,研究方向为计算机视觉。主要承担工作:算法指导。
方芳(1976—)女,湖北省黄冈市人,博士,副教授,研究方向为智能信息处理。主要承担工作:项目规划与论文质量把关。
