基于逻辑回归模型的汶川地震灾区崩塌滑坡易发性评估
2021-04-15杨伟华杨志强赵建林梁咏琪
杨伟华,杨志强,赵建林,梁咏琪
(长安大学地质工程与测绘学院,西安710054)
崩塌、滑坡灾害是常见的地质灾害,随着中国社会经济的发展、建设规模的扩大,特别是近年来洪涝、地震自然灾害的频繁发生和各种交通以及水利等工程的大规模建设,促使崩塌、滑坡灾害高发期的形成,崩塌、滑坡灾害造成的损失也愈来愈大[1]。因此,崩滑灾害的风险预警显得尤为重要。易发性(Susceptibility)评估是崩滑灾害预警常见的研究方法。
易发性的研究方法较多,在早期主要采用统计分析方法。然而,随着地理信息系统和人工智能技术的发展,各种机器学习方法开始应用于相关研究,如信息量模型[2]、支持向量机法[3]、确定性系数法[4]、层次分析法[5]、证据权法[6]、频率比模型[7]、逻辑回归模型[8]等。随着机器学习方法越来越多,一些研究将不同分析方法运用到同一区域崩滑易发性评价中,以比较不同方法的精度。国外学者中有Kalan⁃tar等[9]基于支持向量机、人工神经网络和逻辑回归模型对伊朗Dodangeh流域的滑坡易发性进行评价,并对比每种方法的准确性;Reis等[10]采用频率比模型、逻辑回归模型和模糊逻辑模型对伊朗Zab盆地滑坡易发性进行研究;国内程霄[11]基于逻辑回归模型和信息量模型对汶川映秀地区的崩滑易发性进行评估,并对比两种方法的结果;冯凡[12]应用信息量模型、证据权模型和逻辑回归模型对黄河中游流域的石楼-吉县段的崩滑易发性进行评价和分区;王潇[13]利用确定性系数法、信息量模型和逻辑回归模型对汶川灾区的崩滑易发性进行评估;Xu等[14]应用层次分析、证据权、二元统计、逻辑回归、人工神经网络和支持向量机模型对汶川地震灾区进行滑坡灾害易发性分区研究,并对各个结果进行了对比分析。通过上述对不同评价模型的对比研究,表明逻辑回归(Logistic regression)模型具有计算简单、物理意义明确和准确度高等优点,因而在崩滑易发性评估中取得了较广泛的应用。不仅如此,在大尺度区域范围进行崩滑易发性评价时,逻辑回归模型具有显著的优越性[15]。Broeckx等[15]应用逻辑回归模型预测了整个非洲区域的崩滑易发性并得到了较好的结果;Greco等[16]使用逻辑回归模型对意大利Calabria地区的滑坡易发性进行预测;Mandal等[17]采用逻辑回归模型对喜马拉雅山大吉岭地区崩滑易发性进行评估并取得良好的效果。
汶川地震灾区由于地质地貌条件复杂,震后崩塌滑坡灾害频发,因此对该区域的崩滑灾害易发性进行综合评估具有重要的研究意义[18]。很多专家学者对汶川灾区崩滑易发性开展了研究[19,20],但大部分研究都集中在小区域范围内[21,22],缺少对整个汶川地震灾区大尺度范围的研究。本研究基于汶川地震灾区的崩塌滑坡灾害监测数据库,选取地质、地貌、土地利用、降雨量等崩滑灾害诱发因子,利用逻辑回归(LR)模型对整个汶川震区进行崩滑易发性评估,以探讨LR模型在该区域的适用性,深入探索该区域崩滑灾害与影响因子的关系,研究成果也将为汶川灾区的防灾减灾工作提供数据支持。
1 研究区概况
5·12汶川地震是2008年5月12日14时28分04秒发生的8.0级地震,震中位于四川省汶川县的映秀镇与漩口镇交界处,波及范围包括震中50 km范围内的县城和200 km范围内的大中城市,中国除黑龙江、吉林、新疆外均有不同程度的震感,其中,以川陕甘三省震情最为严重。本研究主要基于中国四川省、陕西省、甘肃省3个震情严重的省份,根据胡伟华等[23]按照烈度区划分的汶川地震受灾等级,选取极重灾区、严重灾区和较重灾区中的22个县作为具体研究区域。22个县的地理区位以及地震影响程度如图1所示,该区域位于地貌第一阶梯向第二阶梯的过渡带上,南北大断裂带的鲜水河断裂(龙门山断裂)-安宁河断裂-小江断裂-红河断裂纵贯其间,巨大的地形起伏,复杂的地质构造,加上受西南季风影响形成的独特气候,导致该区域的崩塌、滑坡灾害频发[24]。

图1 研究区域
2 方法与数据
2.1 逻辑回归模型介绍
逻辑回归模型是二项分类因变量常用的统计分析模型,它描述的是因变量崩滑是否发生(0代表不发生,1代表发生)和多个致灾因子( )x1,x2,x3,…,xn之间的关系。该模型中自变量可以是连续的也可以是离散的,不需要满足正态的频率分布。逻辑回归函数表达式为:
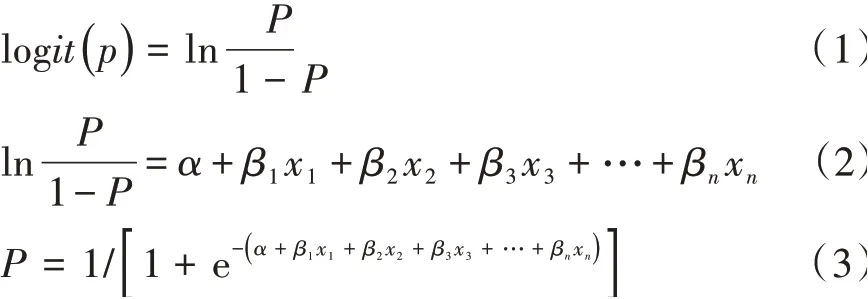
式中,P为崩滑发生概率,范围为[0,1];α为逻辑回归计算出的一个常数项;βi为逻辑回归计算而得出的回归系数;i为评价因子种类数目。
2.2 汶川地震灾区的崩塌滑坡分布
崩滑数据编录是研究区域内崩塌滑坡分布的重要依据。本研究采用的崩塌滑坡数据是通过查找文献资料以及当地相关部门建立的崩滑数据集所得,该数据集主要记录了发生在该区域的地质灾害,包括总共6 007条滑坡、崩塌数据,其中,滑坡点1 172个,崩塌点4 835个,崩滑灾害在该区域的分布如图2所示。在研究区范围内,崩滑灾害多发生在极重灾区,崩滑点占历史样本的65.6%,崩滑点尤其密集,甚至在几近重合的位置不断发生;严重灾区崩滑点数据占历史样本的22.4%;较重灾区崩滑点数据占历史样本的12%;总体来说呈现极重灾区、严重灾区、较重灾区崩滑密度不断减小的趋势。

图2 汶川灾区崩滑分布
2.3 崩滑影响因子的选择
崩滑灾害易发性评价准确性依赖于相关评价因子的选择,目前不同的地区针对崩滑灾害影响因子的选取存在差异,但主要包括地质条件、地貌情况、气候因子以及其他相关因子,如土地利用等人类活动因子[25]。基于前人研究基础以及研究区域相关数据可获得性,本研究选取高程、坡度、坡向、岩性、距断层距离、降雨量、土地利用类型共7个因子作为崩滑灾害影响因子。
研究区的地貌因子(高程、坡度和坡向)通过DEM数据提取。DEM数据为来源于地理空间数据云平台(http://www.gscloud.cn/search),空间分辨率为30 m。其中,高程因子以400 m为间隔分为12级;坡度以10°为间隔分为9级,坡向按方向分为9级。本研究选取2个地质条件因子即岩性和断层活动影响,地质条件及岩性数据主要来源于中国地质科学院地质数据共享网站(http://www.geoscience.cn)1∶250万的断层分布矢量图和岩性矢量图。研究区主要涵盖九大岩性,分别标记为岩性0、11、12、13、14、15、16、17、21,岩性数字所代表的具体岩土类型见表1。基于断层矢量图,对区域不同断层影响进行欧氏距离评价,并以1 000 m为间隔,将断层影响距离分为18级。本研究利用该区域1995—2015年20年平均降雨量代表该区域的气候条件,降雨量数据来源于中国科学院资源环境科学数据中心(http://www.resdc.cn/data.aspx?DATAID=229),空间分辨率为1 000 m。土地利用类型数据来源于全球变化科学研究数据出版系统(http://geodoi.ac.cn/We⁃bCn/doi.aspx?Id=177),本研究集中2010年的土地利用数据,按照土地利用类型不同,可分为耕地、林地、草地、水域、建设用地、未利用土地、其他用地共7类,空间分辨率为100 m。所有数据转换为30 m×30 m栅格数据(图3)。

表1 岩性类型及其代表的详细岩性说明
2.4 基于逻辑回归模型的易发性评价流程
首先,将研究区6 007个崩滑点作为崩滑样本点(图2)。随机选取2/3的崩滑点即4 005个崩滑点作为训练样本,余下1/3的崩滑点即2 002个崩滑点作为验证样本。对所有崩滑点建立1 km的缓冲区,在缓冲区外随机生成6 007个非崩滑点,随机选取2/3的非崩滑点即4 005个非崩滑点作为训练样本,余下1/3的非崩滑点即2 002个非崩滑点作为验证样本。至此,4 005个崩滑点和4 005个非崩滑点共8 010个点作为训练样本集。2 002个崩滑点和2 002个非崩滑点共4 004个点作为验证样本集。基于上述建立的训练样本提取相关崩滑影响因子,利用逻辑回归模型对该区域崩滑易发性进行评价,并用历史崩滑点分布情况和ROC(Receiver operating characteristic curve)曲线[26]来对评估结果精度进行交叉验证。本研究空间分析主要基于ArcGIS平台,逻辑回归及相关统计分析基于SPSS平台。

图3 研究区崩滑易发性评价因子分级
3 结果与分析
3.1 汶川震区崩滑灾害影响因子分析
利用SPSS软件的二元逻辑回归模块,采用向前最大似然法对建立的8 010个训练样本点进行逻辑回归分析,得到每个崩滑影响因子各个分级的回归系数,该系数越大,则表明该分级在这个崩滑影响因子中危险性越高[27]。各影响因子的分级回归系数以及各分级分类面积与崩滑点密度如图4所示。设每个影响因子的第一个分级的回归系数为0,同因子其他不同分级的回归系数值与其进行对比,若值为正,则表明该分级的崩滑易发性比第一个分级大;若值为负,则表明该分级的崩滑易发性比第一个分级小。整个回归分析结果的常数α为-25.76。
基于崩滑条目对各个影响因子进行分析,各因子对崩滑形成的影响情况(图4)如下。
1)高程。68%的崩滑点分布在1 000~2 600 m,这个区间段的崩滑点密度和回归系数也相对最高,说明这个区间段崩滑易发性较大(图4a)。
2)坡度。75%的崩滑点分布在20°至50°的坡度范围内,很大一部分原因是因为这个坡度区间段的面积较大,崩滑点密度基本上随着坡度升高而增大,回归系数完全随着坡度升高而增大,说明崩滑易发性是随着坡度升高而增大(图4b)。
3)坡向。39%的崩滑点分布在东向和东南向,这2个方向崩滑点密度和回归系数相对最高,表明东向和东南向风险较大(图4c)。
4)距断层距离。53%的崩滑点分布在距断层2 500 m的范围内,崩滑点密度和回归系数也相对较大,表明距断层距离越小,崩滑易发性越高(图4d)。
5)岩性。岩性0、17、21由于面积较小,参考性不足,岩性11、12、13、14、15、16崩滑点密度逐渐增大,回归系数也基本上逐渐增大,说明崩滑易发性逐渐上升(图4e)。
6)降雨量。77%的崩滑点集中在900~1 100 mm,崩滑点密度和回归系数也相对较高,表明该区间段易发性较高(图4f)。
7)土地利用类型。98%的崩滑点集中在耕地、林地和草地,其中,62%的崩滑点集中在林地,其崩滑点密度最大,回归系数也最大,说明林地崩滑易发性最高(图4g)。
3.2 崩滑易发性评估结果
通过对各影响因子分级回归系数的求取,将其代入逻辑回归模型中进而预测整个研究区域的崩滑易发性概率,并生成崩滑灾害易发性概率,如图5所示,该概率图反映了研究区域的崩滑易发性程度,概率值越大,则崩滑易发性越高。
每隔0.2为1个级别,根据崩滑易发性概率将研究区分为极低风险区(0~0.2)、低风险区(0.2~0.4)、中风险区(0.4~0.6)、高风险区(0.6~0.8)和极高风险区(0.8~1.0),如图6所示。高风险区和极高风险区的崩滑点密度极高,这2个区域也基本集中在汶川地震极重灾区,如北川县、汶川县、茂县、绵竹市、青川县、平武县。
3.3 模型精度评价与检验
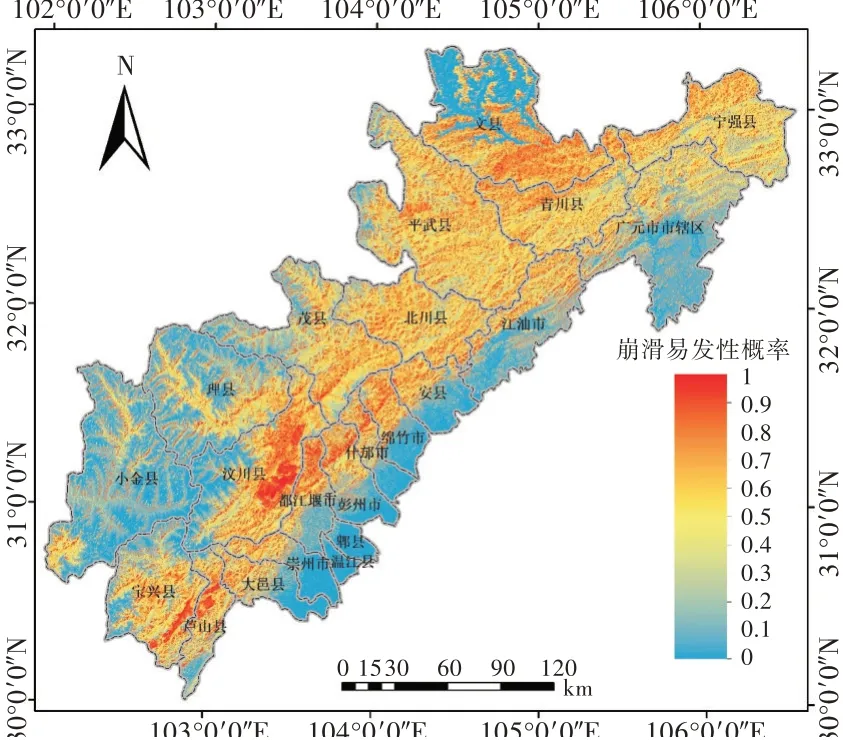
图5 崩滑易发性概率
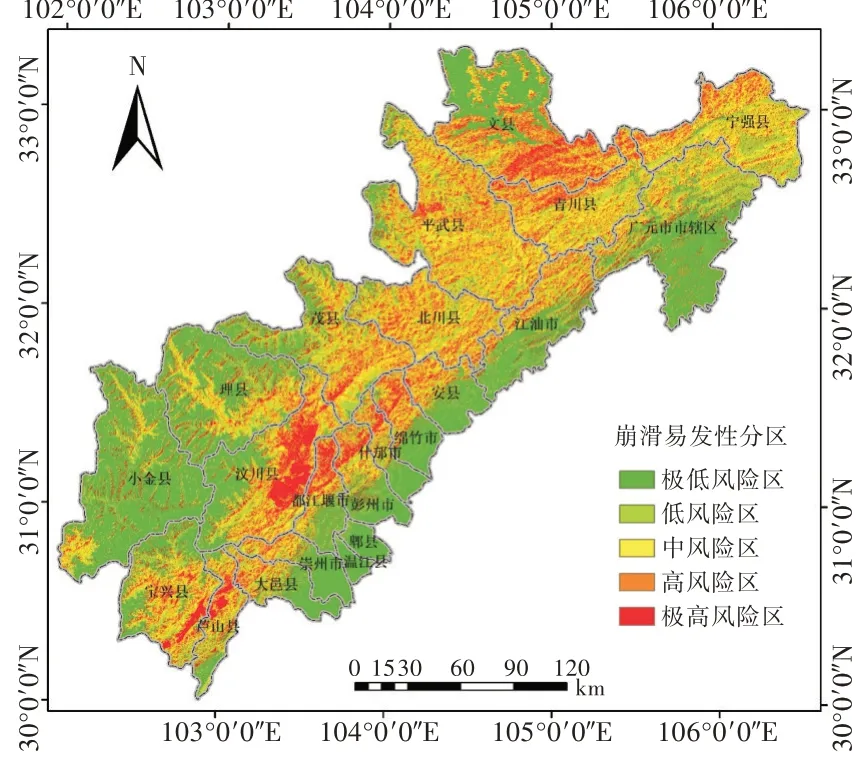
图6 崩滑易发性分区
为了对估算的汶川震区崩滑灾害易发性评价结果进行检验,本研究采取ROC曲线值以及历史崩滑点在不同崩滑易发性分区中的分布情况来进行交叉验证。受试者工作特征曲线(ROC曲线)是检验崩滑易发性评价模型精度的常用方法,以未发生崩塌滑坡的单元被正确预测的比例(假阳性率)为横坐标,以发生崩塌滑坡的单元被正确预测的比例(真阳性率)为纵坐标绘制曲线。其评估准则为:当AUC(ROC曲线下与坐标轴围成的面积)<0.5时,预测结果相反;当AUC=0.5时,模型预测结果随机;AUC为(0.5,0.7]时,模型预测结果准确度较低;AUC为(0.7,0.9]时,模型预测结果准确度较高;当AUC>0.9时,模型预测结果准确度极高[28]。
在本次研究中,将训练样本和验证样本的数据分别导入SPSS进行分析,得到训练样本的AUC为0.84,验证样本的AUC为0.79,如图7所示,表明本研究逻辑回归模型的预测准确率较高。
对每个易发性分区的面积与其中发生的崩滑点数量与密度的统计结果见图8和表2。由图8和表2可知,在低风险区和极低风险区,崩滑发育的数量极少,而随着风险性的提高,崩滑发育迅速增多,尤其在高风险区和极高风险区,崩滑点数量和密度急剧上升。说明历史崩滑点分布情况与崩滑易发性分区图拟合程度较好,本研究崩滑易发性分区图精确度较高。

图8 不同易发性分级崩滑点分布情况

表2 崩滑易发性分区统计
4 小结
以汶川地震灾区为研究区域,本研究选择了地质(岩性、断层)、地貌(高程、坡度、坡向)、气候(降雨)、土地利用类型共7个崩滑影响因子。基于逻辑回归模型得到每个因子各个分级的回归系数,进行图层叠加分析,得到整个研究区域的崩滑易发性分区图。结果表明,历史崩滑点分布状况与崩滑易发性分区图拟合程度较好,易发性分区图准确度较高,汶川县、茂县、北川县、绵竹市、青川县、平武县为崩滑易发性较高的区域,与划分的区县危险性等级一致。通过ROC曲线对模型精度进行验证,表明模型的成功率为84%,预测率为79%,研究成果准确率较高。由于预测结果准确度较好,本研究成果可为汶川地震灾区崩滑灾害的防灾减灾工作提供有价值的参考。
