欧盟电子政务核心词汇表及应用
2021-04-15付清涛龚建华戴钰璁
付清涛,龚建华,戴钰璁
(1.国防科技大学信息通信学院,湖北 武汉 430010;2.武汉科技大学城市学院,湖北 武汉 430083;3.武汉理工大学计算机科学与技术学院,湖北 武汉 430070)
欧盟作为一个区域性的国际组织,组织内部成员复杂,由于各个成员国在行政管理过程和法律上的不一致,缺乏统一的数据模型和通用数据标准等原因,在执行公共服务中产生许多语义互操作冲突问题。为有效解决这些冲突问题,提高欧洲行政机构、商业企业和公民之间的互操作性,欧盟委员会自2010年1月开始实施了欧洲公共管理、企业和公民互操作方案(Interoperability Solutions for European Public Administrations,Businesses and Citizens,ISA)[1]。
根据对客观世界描述的抽象程度,欧盟ISA的数据模型共划分为核心数据模型、领域数据模型和信息交换数据模型3层结构,如图1所示。
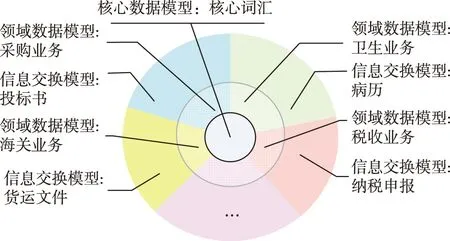
图1 欧盟ISA数据模型层次结构
核心数据模型(Core Data Model)是与具体业务领域无关的数据模型,用于捕获客观世界实体的基本特征,其抽象层级最高。领域数据模型(Domain Data Model)是对特定领域(如justice域、healthcare域)进行建模的数据模型,由核心数据模型扩展而来,用于描述具体业务领域所涉及的实体及其关系,其抽象层级较核心数据模型次之。信息交换数据模型(Information exchange Data Model)用于定义和描述满足具体交换需求的交换数据的结构和内容,由业务领域数据模型扩展而来,其抽象程度最低。
1 核心词汇表组成
本文所提到的核心词汇(e-Government Core Vocabularies)属于核心数据模型层级,由核心业务词汇、核心位置词汇、核心人员词汇、核心准则和证据词汇、核心公共机构词汇和核心公共服务词汇及应用规范6类[2]核心词汇组成。核心词汇定义为简化的、可重用的、可扩展的数据模型,与上下文和语法无关(语法中立),具有技术独立性、可扩展性,不依赖于任何特定的技术手段来表示,只单纯用于捕获记录所要描绘的数据实体的基本特征、定义等内容,可任意应用于信息系统数据模型、信息交换数据模型或关联数据模型创建。
1.1 核心业务词汇
核心业务词汇(Core Business)用于描述通过正式注册登记程序(通常在国家或地区层级)获得法律实体地位的组织机构(Registered Legal Organizations,RegORG)的基本特征。核心业务词汇包括legalEntity类和对机构的法定名称、法定标识符、注册地址、注册活动、组织类型等的描述。该类涵盖了业务注册数据库里的基本数据元素,用于整合不同来源的业务相关数据,并允许不同系统之间进行信息交换。如欧盟商业注册互联系统(Business Registers Interconnection System,BRIS)基于核心业务词汇实现了欧盟各成员国之间跨境的数据交换。BIRS连接了来自31个国家(欧盟成员国和欧洲经济区)的350 个欧洲企业注册库,每天进行10万条信息交换。另外,OpenCorporates门户网站是世界上最大的企业开放数据库之一,目前已有1亿多家企业注册,该门户网站是核心业务词汇最早的应用之一。
1.2 核心位置词汇
核心位置词汇(Core Location)主要对地点、地址、地理名称以及地理位置等地理信息进行描述,应用于土地登记和任何其他基于信息通信技术的解决方案之间交换和处理位置信息,实现互操作性。核心位置词汇主要有地名、几何图形、邮政地址3种描述方式。
1)地名形式(Location类)。如“巴黎”“柏林”等都是地名,通过一个简单的公认的名称,采用简单的字符串形式即可描述出地理位置信息,除位置的简单标签或名称外(字符串),Location类还定义了地理标识符属性,允许通过URI(例如GeoNames或DBpedia URI)定义位置,主要包括地名、地理标识符、地址、几何结构等属性。
2)几何图形形式(Geometry类)。采用图形的形式,通过设置不同的坐标参考系,使用坐标的形式也可以表示某个具体的地理位置,共包含坐标、坐标参考系统标识符、几何类型属性。
3)地址形式(Address类)。主要指邮政系统所使用的地址,如通过描述具体某条街道、某个小区,门牌编号同样可以定义某个具体的地理位置。
不同公共行政机构可以基于核心位置词汇以电子方式交换有关位置数据。如比利时政府以核心位置词汇为基础,集成了国家和地区的公共管理机构登记库,有效整合和融合了不同系统、组织的地址数据。
1.3 核心人员词汇
核心人员词汇(Core Person)主要用于描述各类业务活动中自然人的基本特征,由欧洲检察官组织(Eurojust)负责开发,为刑事案件库之间或其他基于ICT的解决方案交换和处理有关人员信息提供方法手段,以促进司法领域的互操作性,该规范于2012年5月7日发布了1.0版。
核心人员词汇主要包含Person类,该类涵盖了业务活动中用于描述“自然人”的基本数据元素,对“自然人”的概念和特征进行了定义,共包含姓氏、名、父名、性别、出生死亡日期、出生地、死亡地及出生地死亡地所在国家、居住权等属性。核心人员词汇可以反映人员的一些基本属性和信息,但不包括社会关系以及在社会中的身份等内容。
核心人员词汇实现了与人员有关的数据信息描述,公共行政机构之间可以基于核心人员词汇实现人员数据的电子交换。如欧盟“e-CODEX”项目以核心人员词汇为基础,在电子司法领域通过连接成员国家和欧洲的信息系统,促进与案件相关人员的数据信息交换,实现跨境司法合作。
1.4 核心准则和证据词汇
核心准则和证据词汇(Core Criterion and Core Evidence Vocabulary,CCCEV)[3]描述了私营实体为能够达到有资格履行公共服务的水平所必须遵循的原则和手段,准则(Criterion类)是用来判断、评估或测试某物的规则,包含准则类型、名称、描述、完成指标、权重等属性;证据(Evidence类)是包含证明准则存在或为真的依据信息,包含证据类型、名称、描述、语言、签发机构等属性。
核心准则和证据词汇用于实现不同单位之间对于准则和依据的规范一致性,降低跨境流程和交流的理解障碍,完善评估过程和手段。如欧洲的单一采购文件(European Single Procurement Document,ESPD),以CCCEV为基础,针对跨领域、不确定性业务需求进行扩展以满足特殊的采购流程。ESPD本质上是一种用于公共采购流程的自我描述表格,由欧盟各地的买家和企业提供证明材料,以满足跨境公共采购流程所需的条件。ESPD通过使用一种统一的、多语言的形式,大大简化了跨境投标流程,并减轻了参与企业的行政负担。同时ESPD与国家电子采购门户(e-Certis)进行了集成,为用户提供了多种语言搜索、查询、导出采购流程中证明材料信息的工具,保证了采购评估等项目的公开透明。
1.5 核心公共机构词汇
为促进欧洲各国国家内部与国家之间公共组织的管理与共同发展,欧盟于2016年12月19日发布了核心公共机构词汇(Core Public Organization Vocabulary,CPOV)[4],用于描述组织本身及其功能,并通过统一规范形成一个欧盟范围内共同认可的用于描述公共组织基本特征的方式。欧盟基于CPOV构建开发了通用信息系统、跨境公共服务及相关机构的数据库,实现公共机构数据的发布。核心公共机构词汇(CPOV)共定义有6个类,其中Public Organisation类为其核心类,包含公共机构的标签、描述、行政区域、职责、类型、标志、组织成员、从属关系等相关信息的属性。在现实社会中,核心公共机构词汇用于定义和描述各类公共组织的基本信息,实现对公共组织和机构的管理。如欧盟政府以核心公共机构词汇为基础,整合了欧洲和地区的各类公共机构数据信息,构建了公共机构管理登记库等。
1.6 核心公共服务词汇及应用规范
公共服务是由公共组织或代表公共组织执行的,由公共财政资助的、公共政策产生的强制性或可选择的一系列活动,包括由欧洲公共管理机构或代理机构向企业、公民或其他公共管理机构提供的任何服务。核心公共服务词汇(Core Public Service vocabulary,CPSV)[5]及应用规范(Core Public Service vocabulary Application Profile,CPSV-AP)主要包含描述服务本身的类和属性,包括必要的输入、可能的输出、主责公共机构和触发服务使用的事件,服务的上下文的类和属性(包括有关该服务的立法和操作规则),以及服务和用户之间的接口。
核心公共服务词汇为公共服务的统一描述和逻辑分组提供逻辑基础,有利于优化对公共服务信息的访问。以核心公共服务词汇为基础,可在各级行政机构(欧洲、国家、地区)建立以用户为中心的公共服务目录,促进不同层级政府一站式服务机构之间公共服务信息的交换和整合,并实现一站式的业务事件和相关公共服务信息的发布和访问。
2 核心词汇表扩展和映射
ISA数据模型层次关系如图2所示。核心词汇位于核心数据模型层级中,仅用于描述客观实体的基本特征,不能完全涵盖外两层建模需要。在实际应用过程中,需要根据实际情况对核心词汇表进行扩展或映射,构建符合应用需求的数据模型,其中,核心词汇表是领域数据模型和信息交换模型语义一致性的基础。
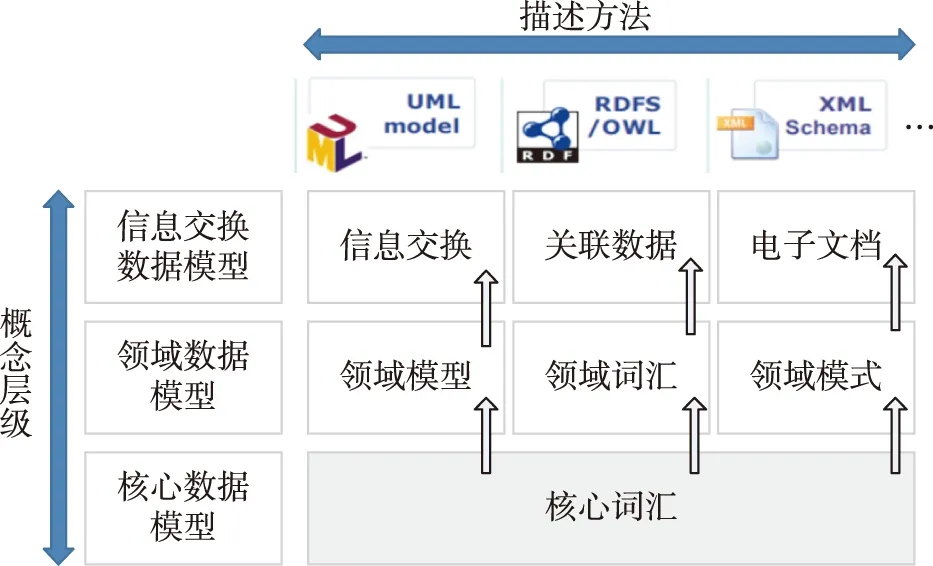
图2 ISA数据模型层次关系
2.1 核心词汇扩展方法
核心词汇表的扩展或限制方法主要包括以下4种。
1)向类中添加新属性或关联。当某特定域或信息系统中缺少某具体表示内容时,可在原基础上添加新的属性和关联。例如,在某个用于人的信息存储服务的数据模型中,需要一个新的属性来指示一个人是否有驾驶执照,则可以在“Person”类中添加一个新的属性,通过该属性值来指示描述对象是否有驾驶执照。
2)从类中删除不相关的属性和关联。
某些属性可能与特定域或特定的信息系统无关,在领域模型或信息交换模型中可以删除这些多余的属性或关联。例如,在为活人提供服务时,人的死亡日期属于无用属性,在这种情况下,可以从结果数据模型中删除无关的属性或关联。
3)具体化类、属性或关联。核心词汇在不同信息系统或信息交换数据模型中因为上下文关系,元素的含义可能有所不同。例如,在临床医学情况下,一个“人”可以指代病人或医生,两者在核心词汇表中共享“Person”类的共同属性,在不同应用场景中,需要增加不同的附加属性和关联。
4)替换类、属性或关联。当核心词汇中的元素接近数据模型的需求但仍不能完全匹配的情况下,可以对核心词汇表中的部分元素进行替换,从而保证完全符合数据模型的需求。
2.2 核心词汇映射方法
核心词汇表具有语法中立性,不依赖于任何特定的技术表达,同时核心词汇表提供了到现有标准数据模型的映射。通过对比数据模型与核心词汇表,可以分析数据模型之间的现有关系,发现可能存在的相似之处,解决不同数据模型之间的语义互操作性冲突问题。
从核心词汇表映射到其他数据模型,主要包含核心词汇表的类、属性、关联、数据类型和元素之间的映射关系。核心词汇表借鉴了SKOS(Simple Knowledge Organization System,SKOS)词汇[6]匹配方法,共定义了精确匹配(exact match)、近似匹配(close match)、关联匹配(related match)、宽匹配(broad match)、窄匹配(narrow match)5种映射关系。具体形式如图3所示。
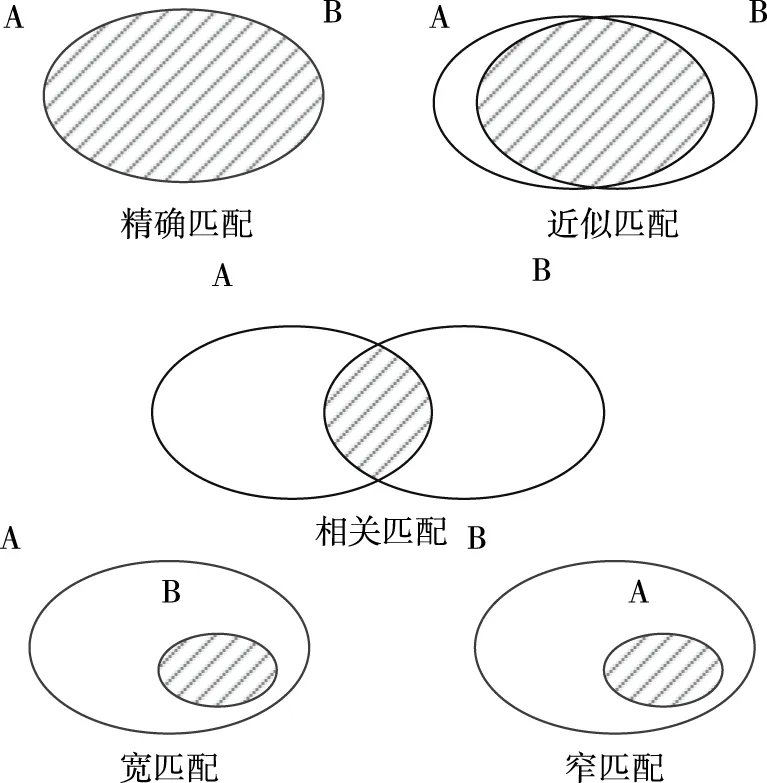
图3 映射关系示意图
1)精准匹配。如果A的集合等于B的集合,那么A和B的定义是等价的,A和B精确匹配。例如,“Person”类在核心词汇表中定义为“自然人”,在UN/CEFACT核心构件中定义为“个人”,这两个类表示同样的个体,因此是语义级别的精确匹配。精确匹配并不意味着“Person”类在结构上是完全一样的,它们可能定义额外的或删除现有的属性和关联。具有精确匹配关系的元素(类、属性或关系),可以在数据模型之间进行双向转换而不会造成语义缺失问题。
2)近似匹配。如果A的集合与B的集合基本相等,A的集合中部分不包含在B中,B的集合的部分不包含在A中,两者之间的差别可以忽略不计,则A和B近似匹配。例如,“AddressPostName”(城市中的邮政地址)与联合国贸易便利化与电子业务中心UN/CEFACT核心构件的“Address.CityName.Text”近似匹配。在大多数情况下,这两个属性将包含相同的值,但可能存在邮政地址既不是城市,也不是城镇或村庄的情况。具有近似匹配关系的元素可以在数据模型之间双向转换,在某些特定情况下,可能存在较小的语义损失。
3)关联匹配。如果A的集合和B的集合之间存在有意义的交集,则A和B关联匹配。关联匹配是最松散的映射关系。例如,核心词汇表中的PersonBirthName(人员出生全名)与UN/CEFACT核心构件的Person.MaidenName.Text(人员婚前姓氏)互相关联匹配。具有关联匹配关系的元素之间的转换,容易产生语义上的错误。
4)宽/窄匹配。如果A的集合大于B的集合,则A的定义概括了B的定义,A和B宽匹配。反之,如果B的集合大于A的集合,则B的定义概括了A的定义,A和B窄匹配。具有宽/窄匹配关系的元素之间的转换只能向更通用的数据元素方向转换。例如,ISA核心词汇表中的“legalEntity”与UN/CEFACT核心组件库中的“Organization”有着窄匹配关系,则数据源中“legalEntity”实例可以转换为“Organization”的实例,相反的转换则不正确,容易造成语义上的错误。
3 核心词汇表应用
核心词汇表作为保证语义一致性的基础规范,应用于欧盟电子政务服务和各业务领域各层级之间数据交换以及数据模型构建中,其主要作用包括以下4个方面:一是系统之间的信息交换,以核心词汇表为基础构建信息交换模型,实现现有信息系统之间交换数据;二是数据集成,利用核心词汇表集成来自不同数据源的数据;三是数据发布,公共机构按照核心词汇表发布机构数据;四是新系统的开发,核心词汇表可以作为新开发的信息系统概念和逻辑数据模型设计的起点。基于核心词汇表构建数据模型的步骤包括需求收集、信息建模、业务规则定义、语法绑定或新语法创建、模型映射及校验,如图4所示。

图4 基于核心词汇表创建数据模型的步骤
本文以电子订单文档创建为例,介绍欧盟电子政务核心词汇表的应用方法。电子订单表是通过计算机和通信技术存储和传递的电子数据形式的订单,主要应用于基于互联网的网上购物。电子订单文档设计涉及的业务流程是买方向卖方提交电子订单,卖方根据情况返回接受或拒绝订单的响应,该项目由卖方设计,向买家提供统一的电子订单格式和内容标准,以便统一订单语义,并改进与其他项目的互操作性。
3.1 需求收集
需求收集的任务是不考虑技术因素,分析该具体项目的业务背景,准确确定业务目标、范围、流程,并通过分析数据模型设计所要达到的目标进一步确定信息需求。
在电子订单审核流程中,其目标、业务范围及其他需求描述分别如表1、2、3所示。

表1 订单审核流程的目标

表2 订单审核流程的范围
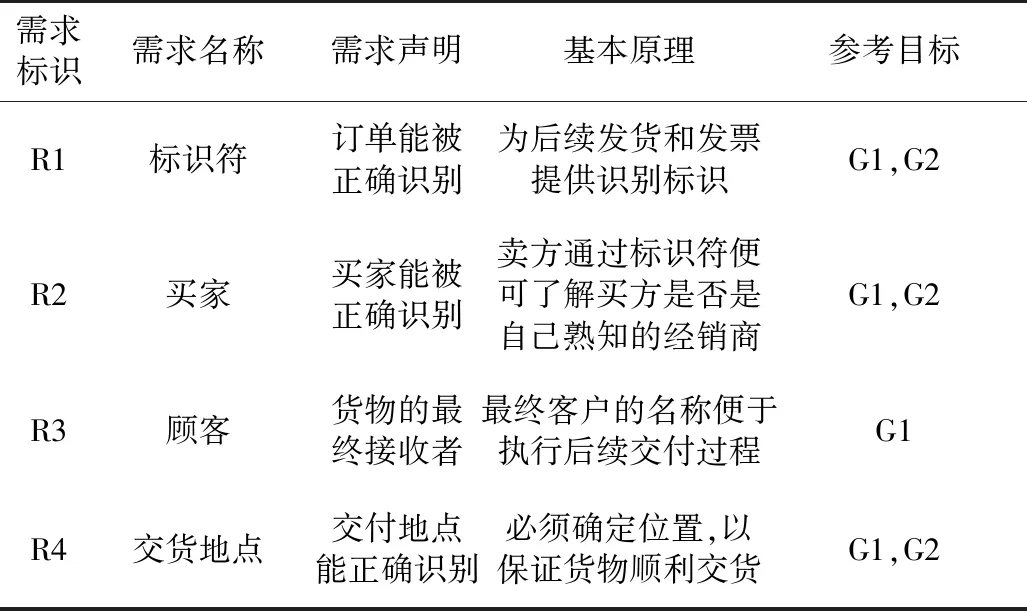
表3 订单审核流程高级要求
3.2 信息建模
信息建模环节是结合第一步所派生的信息需求创建一个与核心词汇表一致的概念数据模型。
3.2.1 概念数据模型的主要内容
概念数据模型应包含信息需求标识、业务术语的类型、业务术语名称、业务术语定义和核心词汇标识,具体内容描述如表4所示。

表4 概念数据模型内容描述
3.2.2 概念数据模型构建步骤
结合电子订单的创建进行分析,创建概念数据模型具体操作步骤如下。
1)从核心词汇库中下载核心词汇表电子表格。根据数据模型应用需求选取适当的核心词汇。如在创建订单时,考虑建模需求以及采购业务流程中具体项目,针对客户这一元素确定选用核心人员词汇,针对接收方地理位置信息确定选用核心位置词汇。
2)查找匹配的概念。将概念数据模型中元素所表示的概念与核心词汇中定义的概念进行比较,查找匹配项。如在创建订单数据模型时,确定Person类、Address类作为与数据模型中“人员”“地址”为匹配的概念,具体内容如表5所示。在具体业务流程中还可以细分为客户,快递员,发货地址,收货地址等详细概念。

表5 订单概念与核心词汇表匹配
3)对齐概念和类。主要包括:① 概念命名对齐,精确匹配时,用核心词汇表术语命名数据模型元素概念;非精确匹配时,在概念数据模型语境中查找同义词和精炼的名称。如在创建订单数据模型时,“买方”与“法人”是一种窄匹配关系,“买方”是“法人”的一种角色,故需要结合概念模型中语境对名称进行精炼;② 术语描述对齐,可以使用核心词汇表里的相应的描述,也可以在核心词汇表概念描述的基础上,增加特定业务的说明,对核心词汇表的描述具体化;③ 类对齐,将数据模型类与核心词汇类进行对齐;④ 概念模型需要对核心词汇表中对应的类具体化,结合新的上下文,在核心词汇表的基础上增加需要的新属性,删除不使用的属性,必要时替换属性和关联关系。
电子订单数据模型与核心词汇表具体对齐内容如表6所示。

表6 “订单”数据模型与核心词汇表对齐
4)确定标识符。概念数据模型的标识符必须使用核心词汇表对应的标识符。
3.3 业务规则定义
核心词汇表本身并不为属性定义基数、业务规则或其他约束,在信息需求定义的基础上,部分概念数据模型还需要定义操作断言、约束和派生等内容,设置基数和约束,以及限制编码元素的可能值等内容。主要包括以下内容。
1)信息模型的完整性约束,如对数据进行插入、修改、删除等操作时,数据库管理系统自动按照一定的约束条件对数据进行监测,防止不符合规范的数据进入数据库,需要信息模型设计中指定完整性约束。
2)定义推论和数学计算,在部分业务服务中需要设计数学推理和运算的规则。
3)定义业务规则条件和同现约束,对业务服务的规则条件或多个业务服务的共同约束进行定义。
4)设置编码数据元素允许的值集,如部分业务服务中,表示月份的数字范围为0~12,表示日期的数字范围为0~31等。
电子订单数据模型信息需求与核心词汇对应关系如表7所示。
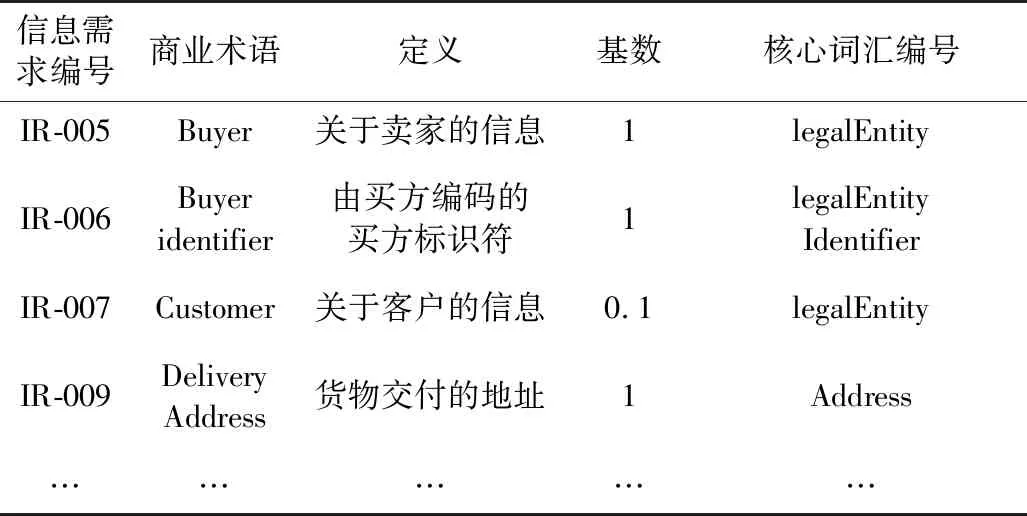
表7 信息需求与核心词汇对应表
3.4 语法绑定或创建新语法
语法绑定作用是将信息需求绑定到具有给定语法的实际元素中,实现信息需求模型到已有的语法模型的映射,其过程主要包括:
1)选择语法表示格式。信息需求的方式实现多样,根据应用情况不同可以选择不同格式,如在构建信息交换模型或领域模型时可选用XML Schema,关联数据(Link Data)[7],在构建数据库模型时选用SQL等。
2)选择语法绑定标准以及命名设计规则。根据概念数据模型的业务领域和选择的表示格式,可以选择多种标准语法。有些标准语法支持特定的业务领域,如HL7支持健康领域建模,XBRL(Extensible Business Reporting Language,XBRL)定义了财务报告业务的规范、分类标准、实例等内容,适用于财务报告业务领域建模。此外,除了标准语法的绑定,还可以通过选择命名设计规则创建实际应用中的语法。
3)使用现有可用映射。核心词汇表预定义了一组到现有标准语法的映射,将相同的概念映射到不同语法中的相同元素中,从而保证不同领域之间同样的语法元素具有概念一致性。目前,核心词汇表提供了与Core Vocabularies RDF Schemas、OASIS Universal Business Language 2.1、UN/CEFACT CCL 13B和NIEM 3.0等语法的映射关系。表8为本例中所用到核心词汇与UBL语法的部分映射。

表8 核心词汇表到UBL标准语法映射表
4)语法绑定。根据核心词汇表提供的映射关系,针对具体订购业务流程中每个信息需求进行具体的语法绑定。本例部分语法绑定如表9所示。
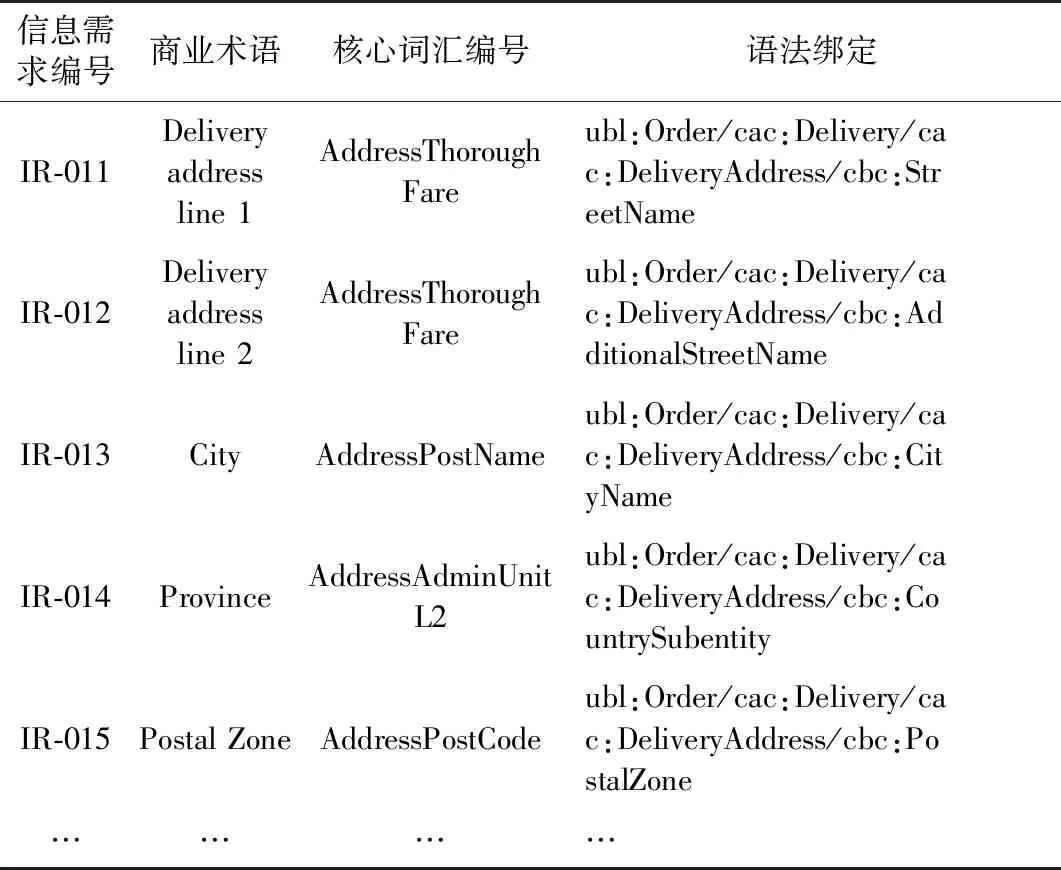
表9 核心词汇表语法绑定
5)创建校验模式文件。对于XML格式,可以利用XSD模式验证特定的XML文档实例是否满足标准定义的结构和类型约束。在标准限制之上添加额外约束的情况下,需创建额外的验证规则,以允许用户验证实例是否满足新的数据模型限制。具体的创建校验模式文件内容有:一是创建受限XSD模式,XSD受限模式可以限制新数据模型中元素和属性;二是Schematron验证文件,可以检查新模型中所需数据元素,并确保没有不属于该数据模型的元素。校验模式文件创建可以采用工具辅助完成,比如基于XML Schema的XGenerator、GEFEG.FX等工具,以及基于RDF Schema的Top Braid Composer、Protégé等工具。
3.5 数据模型映射与构建
此阶段主要通过映射方式创建用户使用的数据模型,同时在数据模型中指定在第四步创建的校验模式文件,实现对用户数据模型及数据的校验。映射应按照核心词汇表提供的映射电子表格文档实施,该映射电子表格在核心词汇表的最新版本压缩包中。
在数据模型中需要通过映射元数据对映射进行注释,实现数据模型的自描述。映射元数据一般包括标识符、标签、定义、URI、核心词汇表版本号、映射关系、映射说明等。
图5为XML Schema中的映射注释示例,映射元数据包含在
4 结束语
欧盟电子政务核心词汇表是为解决欧盟跨领域电子政务信息共享服务中面临的语义冲突问题,所定义的一套用于描述记录客观世界数据实体的基本特征、概念等内容的简化的、可重用的、可扩展的数据模型。核心词汇表使用了基于UML的概念模型、XML、RDF、JOSN-LD等技术描述手段,通过扩展类属性、关联的方式构建用于满足业务域数据交换需求的概念数据模型,实现从核心数据模型到领域数据模型、信息数据模型的扩展派生。同时,核心词汇表提供了到现有标准语法的映射,通过语法绑定方式实现信息需求到现有标准语法中实际元素的绑定,并最终通过映射方式创建供用户使用的数据模型。核心词汇表为实现欧盟不同领域、不同系统之间的数据交换与共享提供了共同认可的数据模型规范,为不同领域信息交换模型的开发提供了依据和参考,保证了交换数据的可理解、可共享、可整合。
欧盟电子政务核心词汇表为我国电子政务服务中跨领域信息共享服务建设提供了借鉴参考,主要有以下三点:一是构建开放共享的数据模型标准规范,为实现不同系统之间互操作提供依据;二是采用由核心层向具体领域层扩展的数据模型构建方式,保证了在构建具体领域数据模型时的灵活性和可扩展性;三是采用映射到现有的标准语法的方式构建数据模型,可有效促进不同语法之间的可理解性,同时在数据模型构建上简化了工作流程,提高了资源的利用。在“互联网+”背景下,信息资源高效共享逐渐成为我国电子政务建设中需要重点解决的问题。参考欧盟核心词汇设计特点,建立统一的数据交换模型标准,有利于建立兼容、开放、可扩展的政务服务系统架构,形成互联互通、共享共用的政务服务大数据应用环境,有效促进信息的开放共享和资源的整合,切实提高信息资源利用率以及政务服务的办事效率。
