一种提高云计算环境下检测入侵者速度和正确率的新方法
2021-04-15阿淑芳刘宁宁余桂莲余桂希余生晨
阿淑芳 刘宁宁 余桂莲 余桂希 余生晨
1(邢台学院 河北 邢台 054001) 2(固原市原州区第五中学 宁夏 固原 756000) 3(宁夏海原县职业中学 宁夏 中卫 756100) 4(华北科技学院计算机学院 北京 065201)
0 引 言
云计算以服务的方式提供计算资源(包括计算能力、存储能力和交互能力),形成了一种动态、可扩展、虚拟化的新型计算资源组织、分配和使用模式。这种模式使得计算资源成为向大众提供服务的社会基础设施,将对信息技术本身及其应用产生深刻影响。但是,多个用户在云计算平台上同时使用一个软件与在单个本地计算机上使用同一个软件给用户带来的体验差距还是很大的。这主要是云计算平台上的软件运行得太慢造成的,例如,传统的入侵检测技术在云环境下应用存在着响应速度慢、不能很好适应大数据集等诸多限制,无法满足实时性、有效性的需求[1-2]。解决这一问题的方法有多种,其中之一是提高在云计算环境中运行的IDS的检测速度和准确度,但是,提高IDS的检测速度和准确度又造成了用于IDS的BPNN经常出现“泛化问题”,即BPNN无解或总误差函数不能收敛于全局最小值。另外,随着云计算的飞速发展,对其入侵的技术也日新月异,入侵方法也越来越多样化与综合化,这使得现有的入侵检测系统(IDS)漏报率和误检率都大幅上升[3-4]。BPNN可以解决云计算环境中的复杂的具有非线性特征的入侵攻击活动。人们通常通过增加BPNN的网络层数,即增加BPNN的内部神经元数量(等效于增加人脑中的神经元数量),达到提高BPNN识别各类复杂的云计算环境中的入侵攻击活动能力的目的。另外,人们也通过增加BPNN的输入特征的数量,达到提高BPNN识别各类复杂的云计算环境中的入侵能力的目的,因为一般情况下,特征越多,携带的分类识别云计算环境中的入侵攻击活动的信息也越多,有利于提高BPNN识别各类复杂的云计算环境中的入侵者的正确率。但是,BPNN是通过数学方法模仿人脑工作的,采用最速下降法(梯度法)求BPNN总误差函数的全局最优解。BPNN总误差函数是神经元和输入特征的非线性的多维复杂函数,一般具有多个极值点。最速下降法(梯度法)能够精确地搜索到局部最优解,但是一般不能搜索到全局最优解,这与选择的初始值有关,这样就导致了BPNN的“泛化问题”[5]。“泛化问题”是指BPNN无解或总误差函数不能收敛于全局最小值。为了解决这些问题,本文提出基于重要特征的用遗传算法改进的反向传播神经元网络(BPNN)构造的入侵检测系统。在该系统中利用遗传算法(GA)能够搜索“全局”最优解的能力[6-7]改进传统BPNN利用梯度法搜索“局部”最优解的方法。由于遗传算法的变异引入了随机值,导致GA搜索到的是全局最优解的近似值。梯度法是用求方向导数法求最优解,求得的是问题的精确的局部最优解,当初值选择不当时,一般搜索不到全局最优解。本文把遗传算法与梯度法结合起来,取长补短,就会搜索到BPNN的全局最优解的精确解。
先用遗传算法求出BPNN全局最优解的近似值,然后,把该近似值作为最速下降法(梯度法)的初始值,进行迭代,最终求得BPNN全局最优解的精确值,达到解决BPNN“泛化问题”的目的。另外,本文提出通过分析BPNN的输入特征的相关性,剔除相关性大的那些特征(两个特征相关是指这两个特征描述了问题的同一个方面,例如,一个人的身高和腿长都描述了人的高度,用数学语言表述为身高和腿长是正相关的,可用y=kx表示),保留相关性较小或互相独立的重要特征,以便减少特征数量,从而降低BPNN的泛化性。减少特征数量,也可以减少BPNN的计算工作量,从而提高BPNN处理云计算环境中的数据包的速度[8],这样,当云计算环境中的流量较大时,可以少丢弃一些来不及处理的数据包,从而提高BPNN对入侵者的正确识别率。仿真实验证明本文给出的方法是有效的且能够提高BPNN识别入侵者的正确率。
1 搜寻BPNN的全局最优解的精确解
普通的BPNN利用梯度法修正其反向传播的权值和阈值,以便使BPNN的输出总误差平方和最小。
期望输出与实际输出之差的平方和被定义为总误差函数φ:
(1)
式中:yj是实际的输出,它是输入模式p和权值bj的函数,yj=f(p,b1,b2,…,bn);vj是输出单元的期望输出。
现在要寻找一组BPNN的权值b1,b2,…,bn,代入式(1),总误差函数φ为极小,是全局最小,不是局部极小。
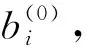
上述问题是一个多参量的非线性最优估计问题。传统的做法是采用“最速下降法”(或称为“梯度法”),直接寻找总误差函数φ的下降方向来求取修正量。如图1所示,其步骤如下:
(1) 在初值点b(0)的一个邻域内,将总误差函数φ在b(0)处泰勒级数展开,取至线性项,有:
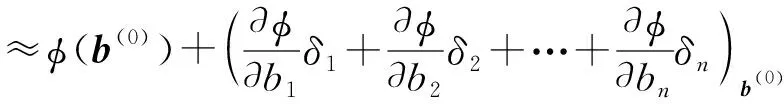

φ(b(0))-φ(b(0)+δ)=
-g·δ=-|g|×|δ|cos
(2)
式中:g表示总误差函数φ对权值b的各分量的导数所组成的向量,即梯度向量。
要使式(2)取得极大,有:
cos
(3)
式(3)说明了总误差函数φ值下降最快的方向δ应该与梯度方向g相反,即负梯度方向,那么修正量就应在负梯度方向上来求取。
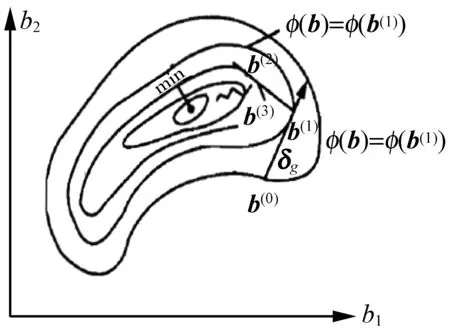
图1 最速下降法(梯度法)使总误差函数φ极小的迭代过程示意图
为了简化问题,用一维的情况说明BPNN总误差φ(x)是权值参数x的多极值函数。如图2所示,一般情况下,BPNN的总误差φ(x)是参数x(这里,参数x是BPNN的权值和阈值这两个参数)的多极值函数。如果BPNN的初值选在N点,按BPNN使用的梯度法,只能收敛于最近的极小点T2min,而不会收敛于全局最小点T1min(精确解),BPNN应当收敛于全局最小点T1min(精确解)。因此,初始阈值和权值x的选取,极大影响BPNN求得精确解的结果。本文将针对这个缺点进行改进。
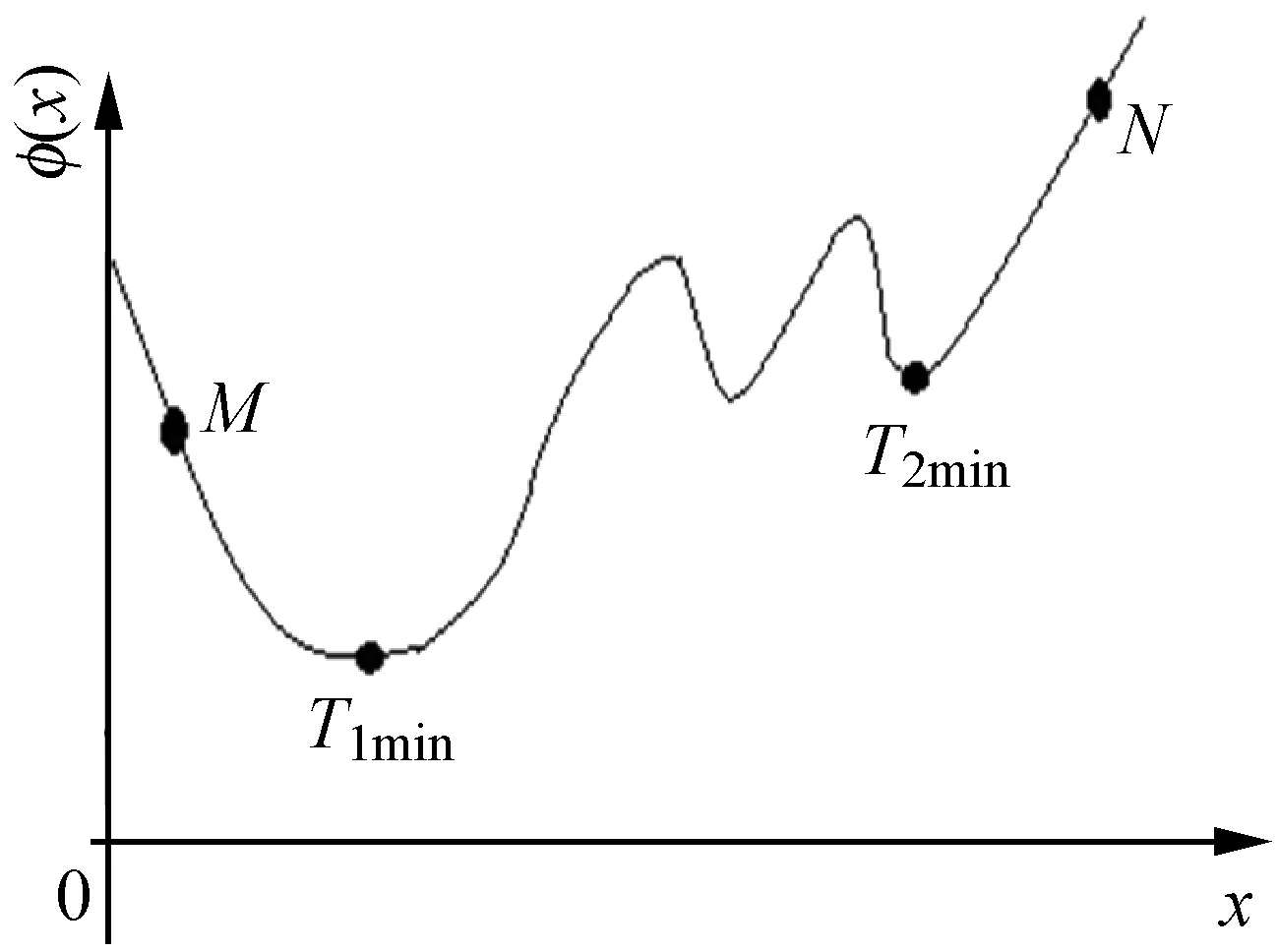
图2 BPNN总误差φ(x)是权值参数x的多极值函数
首先用遗传算法求出BPNN的近似值(M点),即全局最优解(T1min点)的近似值,梯度法的初始值不是随机选取的,而是选取该近似值,进一步就可以求出BPNN的全局最优解(T1min点,精确解)。
遗传算法是最近几年受生物免疫系统的启示而设计出来的新型算法。它是一种对多峰值函数进行搜索及全局寻优的新型算法。选择运算保留了想要的最优解,交叉和变异运算为取得全局最优解提供了基础,选择运算淘汰了那些不想要的解,只保留想要的最优解。这保证了在整体上(平均值)下一代比上一代更优秀。
一般情况下,遗传算法求不到全局最优解的精确解(T1min点),只能是近似解(相当于M点),这是由遗传算法的交叉和变异的随机运算所导致的必然结果。梯度法是稳健的,当初值选为M点时,会逐步接近精确解(T1min点)。
利用遗传算法和BPNN使用的梯度法的组合可较快地求得全局最优解的精确解(T1min点),例如,在图2中,从N点出发,用遗传算法求得M点,然后,再从M点出发,用梯度法求得全局最优解的精确解(T1min点)。
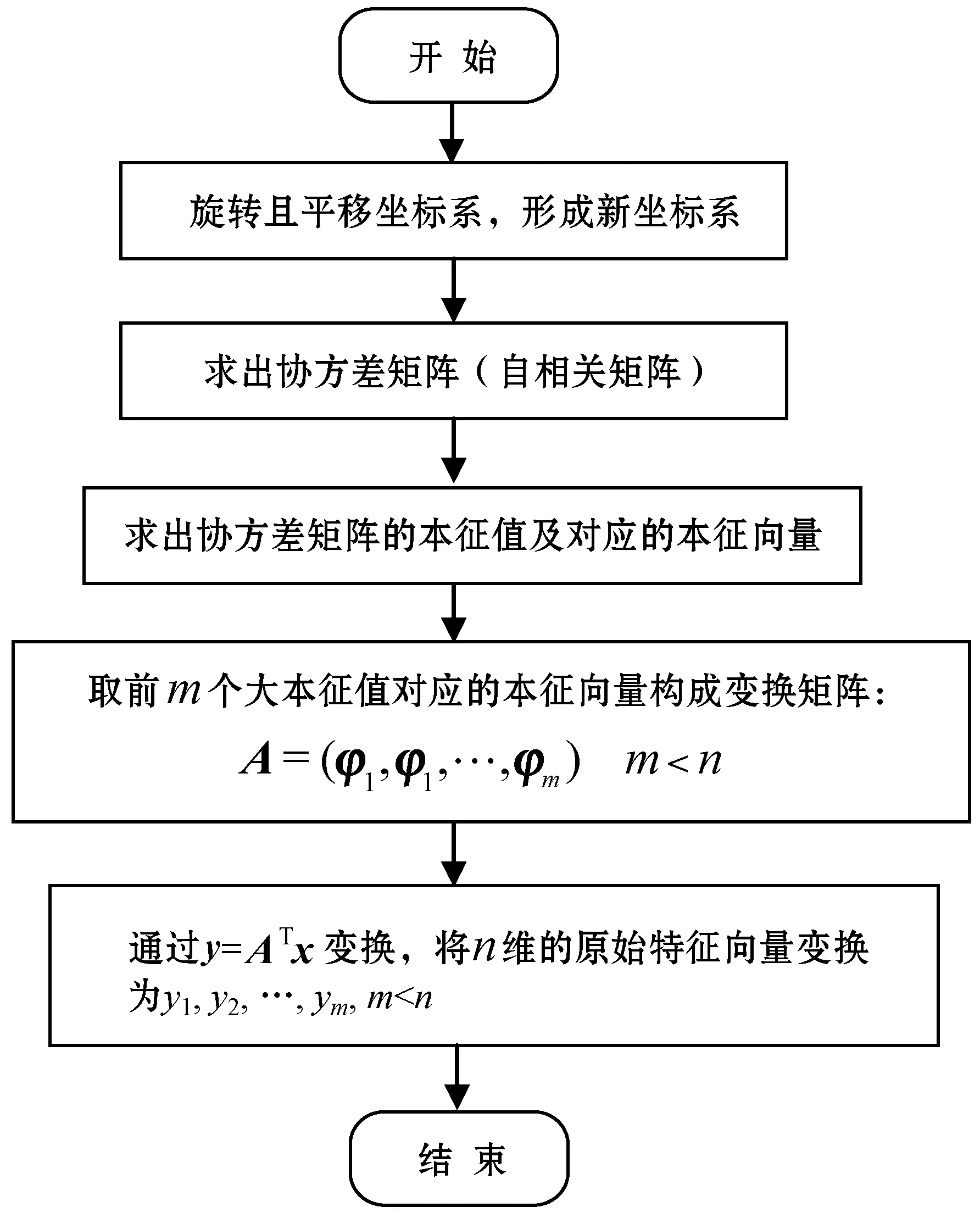
上述算法(利用遗传算法和最速下降法求得BPNN全局最优精确解)的具体算法流程如图3所示。
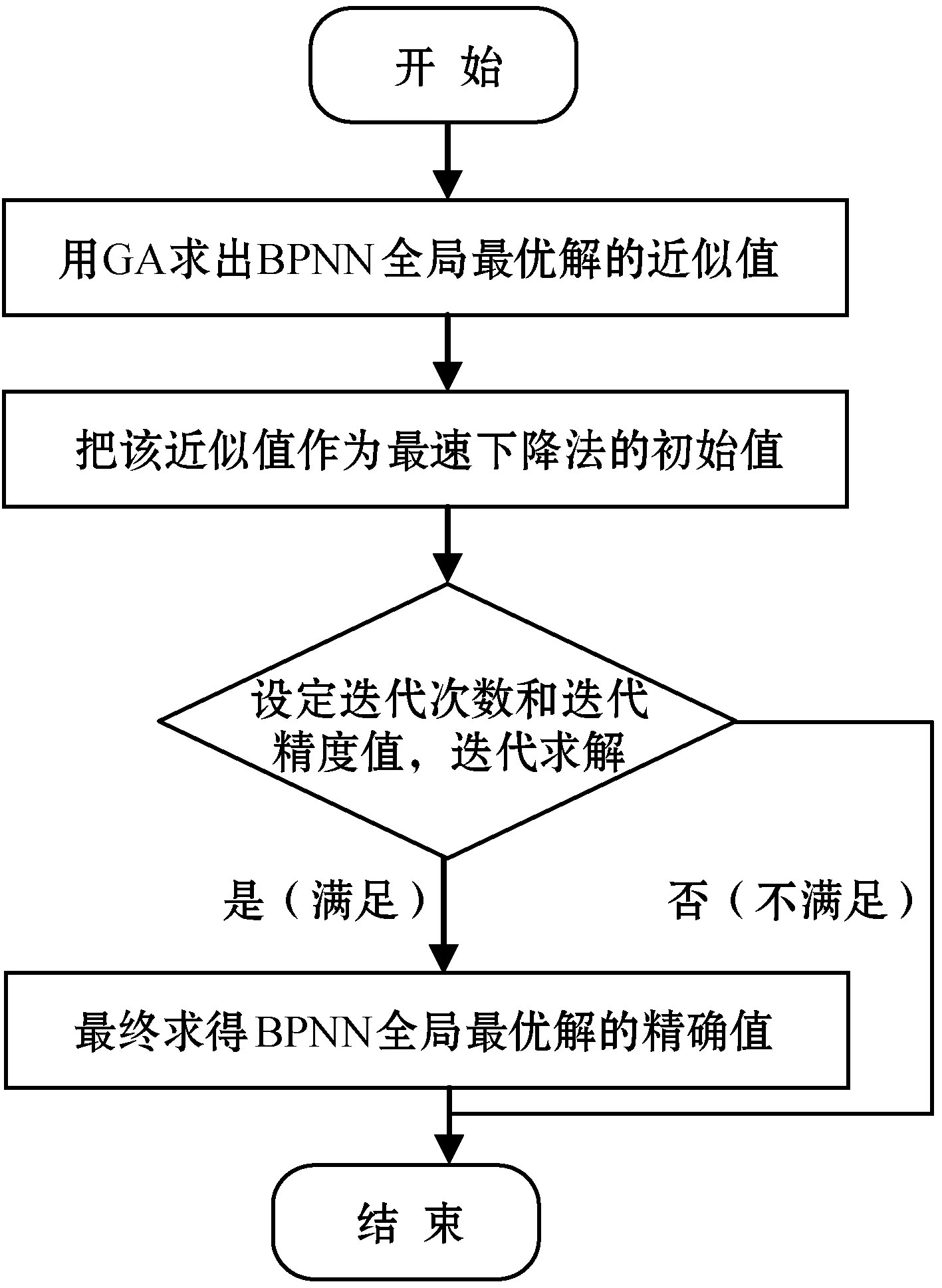
图3 利用GA和最速下降法求得BPNN全局最优精确解的具体算法流程
2 识别云计算环境中的入侵者
BPNN的网络层数和特征较多时,计算量将急剧增大,使得BPNN的收敛速度变慢。过多的输入特征会使BPNN出现“泛化问题”。因此,使用BPNN识别云计算环境中的入侵者时,使用相互独立的数量适中的重要特征是提高入侵检测系统的速度、减少漏报率和误检率的重要措施之一[6-7]。
2.1 相互独立的重要特征的定义及意义
如图4所示,有两类样本μ1和μ2,在x1和x2坐标系中,可以分类识别出μ1和μ2,但是,在y1和y2坐标系中,也可以分类识别出μ1和μ2。去掉y2,只用y1也可以分类识别出μ1和μ2,这时的分类误差并不大。

图4 相关特征与独立特征的关系示意图
对分类两类样本μ1和μ2而言,特征x1和x2具有较高的相关性,特征y1和y2具有较低的相关性,在一定程度上,也可以说,特征y1和y2是相互独立的两个特征。y2带有较少的分类信息,y1带有较多的分类信息。去掉带有较少分类信息的y2,只用带有较多分类信息的y1分类,并不会带来很大的分类误差,这样就可以达到降低特征空间维数的目的,减少BPNN的计算量,提高BPNN的分类识别入侵者的速度。在本文中,特征y1称为独立的重要特征。
在n维的原始特征向量x=(x1,x2,…,xn)中,有些特征具有较高程度的相关性。下面给出如何消除原始特征向量x中的相关性并求出相互独立的重要特征的方法。
2.2 求取相互独立的重要特征
可以用n个基向量的加权和表示BPNN选取的n个原始特征x:
(4)
式中:αi是加权系数;φi是基向量。
变换矩阵A是从n个向量中取出m个形成的,即:
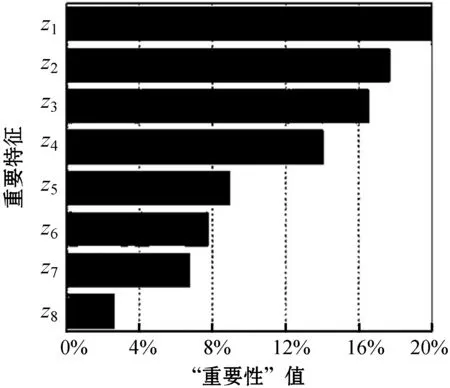
A=(φ1,φ1,…,φm)m 经过y=ATx变换,得到特征个数较少的m(m 在式(4)中,只取m(m 产生的误差为: 均方误差为: (5) 式中:E[]为求数学期望。 ε2取得最小值的条件是对bj的选择应满足下面的偏导数为零的条件: E-2(αj-bj) =0 故: bj=Eαj (6) 换句话说,应该用α中省略的那些分量的期望值来代替这些省略的分量。 新坐标系的原点选取为模式总体的均值向量等于0,即在新坐标系中,E[x]=0,式(6)可以转化为: 这样,由式(5)可得均方误差为: 式中:与λj对应的本征向量是φj;x的自相关矩阵R的第j个本征值是λj。 m(m BPNN使用这m(m m(m 一般情况下,转发云计算环境中的数据包的缓冲存储器的容量是有限的且也是很小的。当流量较大时,BPNN(IDS)会丢弃云计算环境中的一些来不及处理的数据包[6]。入侵者就可能隐藏在这些丢弃的数据包中。减少BPNN(IDS)所用的特征数量相当于减少了其计算量,从而提高了其处理数据包的速度。减少丢弃的未处理的数据包的数量,可以提高其识别云计算环境中的入侵者的正确率。为了提高BPNN识别入侵者的正确率,BPNN可选取λj值较大的新特征作为其使用的特征。 上述算法(剔除相关性大的那些特征,保留相关性较小或互相独立的重要特征,以便减少特征数量)的具体算法流程实现如图5所示。 图5 求取数量较少且相关性也较小或互相独立的重要特征具体算法流程 为了检测评价本文给出的方法的有效性,实验采用KDDCUP99数据集[9]。该数据集是目前比较公认的检测评价入侵检测系统性能的重要数据集[10]。 遗传算法的参数取值为:交叉概率范围为0.4~0.9,变异概率为0.004~0.010,最大遗传迭代次数大于或等于400次[11],当遗传算法停止当前迭代时,提高交叉概率值和变异概率值,直到交叉概率值和变异概率值都取最大值。 一般情况下,最速下降法(梯度法)迭代的初始值是随机选取的,但本文把遗传算法求出的BPNN全局最优解的近似值作为梯度法迭代的初始值。 在模拟实验中,第一阶段,选取了24个特征,它们[12-14]是:x1=发起攻击的主机(源)的IP地址,x2=来自发起攻击的主机的流量,x3=被攻击者(目标)主机的IP地址,x4=进入被攻击者(目标)主机的流量,x5=操作系统类型与版本探测次数,x6=服务器Tomcat的探测次数,x7=服务器IIS的探测次数,x8=传输协议类型的探测次数,x9=重要端口是否开放的扫描次数,x10=扫描允许连接的服务类型,x11=在近期一段时间内口令错误的次数,x12=口令文件尝试访问的次数,x13=尝试下载敏感信息的次数,x14=尝试修改或删除重要数据的次数,x15=尝试清除或篡改日志文件的次数,x16=修改系统时间的次数,x17=修改系统启动文件的次数,x18=修改服务器配置文件的次数,x19=替换系统本身的共享库文件的次数,x20=修改系统的源代码的次数,x21=修改注册表的次数,x22=出现同步洪流(SYN Flooding)的连接次数,x23=出现死亡之Ping的次数,x24=出现Smurf攻击的次数。 第二阶段,用本文第2节给出的提取相互独立的重要特征的求法,提取了8个相互独立的重要特征,它们是z1、z2、z3、z4、z5、z6、z7、z8。这8个相互独立的重要特征的意义是:z1=发起攻击的主机(源,被侵入的主机,俗称“肉鸡”)的IP地址,z2=被攻击者(目标)的IP地址,z3=采点扫描行为或称为云计算环境监听行为,z4=掌握系统控制权的行为,z5=实施攻击行为类型1,z6=实施攻击行为类型2,z7=隐藏攻击痕迹行为,z8=安装后门行为。按照本文方法,计算出的这8个重要特征的“重要性”值分别如图6所示。这8个重要特征所携带的分类识别入侵者的信息占原来24个原始特征组的总信息量的99%。这时,从24个原始特征组中剔除的16个相关性大的特征共同携带的分类识别入侵者的信息只占原来24个原始特征组的总信息量的1%。由此可见,从24个原始特征组中,剔除16个相关性大的特征后,丢弃的分类识别入侵者的信息并不多(只占1%),但是,特征数量大幅下降了。这也进一步说明可以用这8个重要特征代替原来的24个原始特征进行云计算环境中的入侵者分类识别工作。 图6 8个重要特征的“重要性”值 以这8个重要特征为输入特征,构建反向传播神经元网络(BPNN)。BPNN由三层构成,第一层有8个输入节点,第二层有7个输入节点,第三层有1个输入节点,输出量值为0代表正常用户程序的行为,输出量值为1代表入侵者或异常用户程序的行为。 初期,用350个不同类型的入侵者程序和250个一般正常用户程序,作为训练BPNN的样本集。BPNN训练成功后,就可用KDDCUP99数据集对其性能进行评价。 本次实验首先在模拟云计算环境下进行实验,然后再在Amazon(亚马逊)、Google、Salesforce、Microsoft Azure云计算环境下分别进行实验,几种不同的入侵检测系统(IDS)对入侵者的正确识别率测试结果如表1所示[11-14]。 表1 云计算环境下不同IDS识别入侵者的正确率 % 当云计算环境中的网络流量由1 000 MB/s增加到2 000 MB/s时,国外著名的Cisc公司和ITA公司研制的入侵检测系统(IDS)识别入侵者的正确率分别降低了14.29%和14.63%,用最初24个特征的反向传播神经元网络(BPNN)构造的入侵检测系统(IDS)识别入侵者的正确率也降低了13.10%。但是,用本文选出的8个特征的反向传播神经元网络(BPNN)构造的入侵检测系统(IDS)识别入侵者的正确率仅仅降低了1.04%。 其中的原因是用本文选出的8个重要的互相独立的重要特征比用最初24个特征的BPNN构造的IDS的“泛化问题”要小得多。训练BPNN就是一个多参量的非线性最优估计问题。特征数量越少,相当于BPNN的总误差函数的维数(度)也越低,总误差函数相对也越简单,这时,求出的总误差函数的全局最优解也越准确。用比较准确的全局最优解构造IDS后,其识别入侵者的正确率也较高。 另外一个原因是特征越少,IDS(BPNN)计算量也越少且计算速度也越快,这样,IDS丢弃的未检测的数据包也就越少,丢弃的未检测的数据包中可能含有入侵者。由此可见,用本文选出的8个重要的互相独立的重要特征比用最初24个特征的BPNN构造的IDS识别入侵者的正确率要高得多。 表1实验结果证明了本文研制并改进的IDS的正确性。 云计算的理念很好,但是其技术和一些软件的运行速度还有待提高[15],尤其入侵检测系统的检测速度要大幅提高。云计算环境中巨大的通信量对数据分析提出的新要求是入侵检测速度要更快,否则,前面的数据还没有分析完毕,后面的数据就跟着到来,以致于来不及分析就被丢弃,造成新的漏判。反向传播神经元网络(BPNN)的网络层数和特征较多时,计算量将急剧增大,使得BPNN的收敛速度变慢,过多的输入特征会使BPNN出现“泛化问题”。因此,使用BPNN识别云计算环境中的入侵者时,使用相互独立的数量适中(较少)的重要特征是提高入侵检测系统的速度、减少漏报率和误检率的重要措施之一。通过理论论证和仿真实验证明:在保持原始特征组所携带的分类识别入侵者的总信息基本不变的前提下,分析BPNN的输入特征的相关性,剔除相关性大的那些特征(两个特征相关是指这两个特征描述了问题的同一个方面,即y=kx),保留相关性较小或互相独立的重要特征,以便减少特征数量,可以降低BPNN的泛化性。综合利用遗传算法和最速下降法(梯度法)的优点,也可以解决BPNN的泛化性问题。首先用遗传算法求出BPNN全局最优解的近似值,然后把该近似值作为最速下降法(梯度法)的初始值,进行迭代,最终求得BPNN全局最优解的精确值,达到解决BPNN“泛化问题”的目的。另外,减少特征数量,也可以减少BPNN的计算工作量,从而提高BPNN的处理云计算环境中的数据包的速度。这样,当云计算环境中的流量较大时,可以少丢弃一些来不及处理的数据包,从而提高BPNN对入侵者的正确识别率。仿真实验证明本文给出的方法是有效的且能够提高BPNN识别入侵者的正确率。2.3 计算相互独立的重要特征的“重要性”值
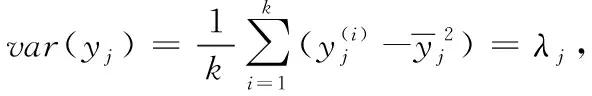
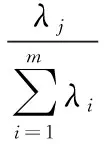
3 应用实验

4 结 语
