基于深度神经网络的强对流天气识别算法
2021-04-13吕晶晶王璐瑶詹少伟
王 兴, 吕晶晶, 王璐瑶, 王 晖, 詹少伟
(1.南京信息工程大学大气科学与环境气象国家级实验教学示范中心, 南京 210044;2.南京信息工程大学大气科学学院, 南京 210044; 3.南京信大气象科学技术研究院, 南京 210044)
强对流天气是一种因大气强烈的垂直运动而产生的天气现象,往往具有很强的破坏力,常伴随雷暴、短时强降水、大风和冰雹等灾害性天气。在过去的20年间,全球因气象灾害造成的经济损失高达数万亿美元[1]。仅2019年,全国因各类自然灾害共造成1.3亿人次受灾,98.4万间房屋倒塌或损坏,农作物受灾面积19 256.9×103hm2(1 hm2=104m2),直接经济损失3 270.9亿元[2]。施瓦茨等[3]指出,天气在80% 的世界经济活动中起到关键性作用。
短时强降水和对流性大风是典型的强对流天气,其对交通运输、农业生产、建筑保护和城市排水等造成极大危害。天气雷达是对其进行监测和预测的电子设备,借助雷达探测资料能够直观地观察天气演变过程,结合专业理论和方法能够分析出风暴发生的空间位置、移动速度和发展趋势,以及大风或降水的强度等大量有价值的天气信息。利用雷达进行灾害性天气的识别是短临预报业务中重要的技术手段,经过数十年的发展已积累了很多卓有成效的理论和方法。雷暴识别跟踪分析与预报算法 (thunderstorm identification tracking analysis and nowcasting, TITAN) 和相关跟踪雷达回波算法(tracking radar echoes by correlation, TREC) 是该领域应用最广且影响最深远的两种方法,它们都是通过对雷达回波或卫星图像所表征的风暴形态的几何推理以及相邻时刻风暴中心的相关性分析,实现对强对流天气的识别与追踪。在这些方法的基础上相继产生了很多新的研究成果,提升了识别的准确性和可靠性。曹伟华等[4]将上述两种移动矢量进行融合,兼顾了TREC在提取大尺度风暴总体移动趋势方面的特长与TITAN在刻画小尺度风暴运动细节上的优势,融合后的外推移动矢量对提高降水落区和降水强度的预报起到积极作用。黄旋旋等[5]在传统TREC基础上通过增加相邻时刻雷达基本反射率强度连续约束检验和矢量全变分修正,提高了雷达回波移动矢量场的连续性,进而提升了台风降水预报的精度。Muoz等[6]结合光流技术,采用多组阈值对风暴进行识别,改善了TITAN无法准确识别小尺度且快速移动的风暴质心的问题,提高了短时强降水预报的准确性。
针对灾害性天气的识别,除了基于上述两种方法外,气象学者们还尝试结合多种极端天气指数进行分析。Yang等[7]利用雷达基本反射率信息和霰分布等物理量参数构建雷暴识别模型,并对南京地区17个天气过程共计312次雷暴雨进行检验试验,结果表明,该方法识别的成功率为85.3%。Wang等[8]采用光流技术对风暴质心垂直方向的运动趋势进行分析,结合对风暴质心中层径向速度场中“正负速度对”的识别,实现垂直辐散大风的特征识别,并实现对强对流天气的提前预警。赵畅等[9]利用新一代双偏振雷达,将多个双偏振参量引入雷达定量降水估测模型,结合地面自动气象站的观测进行检验,结果表明,强降水中心的降水估计量与实际观测结果较接近。冯晋勤等[10]以雷达资料作为输入数据,采用Fisher判别方法构建冰雹、雷雨大风和强雷暴天气的预警预报方程,实现多种灾害性天气的自动判别。窦冰杰[11]利用雷达反射率及径向速度数据构建三维辐合面,对强对流的一项特征指标“中层径向辐合”进行判别,进而实现大风预测。王萍等[12]针对“中层径向辐合”易被低估和遗漏问题,利用“径向矩形映射”将放射状分布的雷达数据转变为格点数据,并提出基于辐合线走向的辐合强度订正方法,提高了对“中层径向辐合”识别的准确率,进而也提高了对雷雨大风预报的准确率,实验结果表明,其预报准确率达到94.87%。
随着通用图形处理器(general-purpose computing on graphics processing units, GPGPU)的普及和深度学习技术的发展,利用深度神经网络进行各类图像目标物识别的技术已广泛应用于安监、医疗、交通和工业生产等领域[13-16]。利用深度学习等人工智能技术解决气象问题是近年来很多研究人员致力的一个重要方向。李银勇等[17]通过集成经验模态分解(ensemble empirical mode decomposition, EEMD)将大气电场分解为晴天天气和雷暴天气两类不同时间尺度变化分量,再对包含雷电信号的高频模态分量进行二阶差分计算,实现雷暴天气的识别预警。杨磊等[18]提出一种基于EEMD和广义回归神经网络的短期风速变权组合预测模型,用于风电场风速预测,实验结果表明,该模型比单一模型以及传统组合模型具有更高的预测精度。张远汀等[19]将分类回归树(classification and regression tree,CART)与神经网络结合,构建温度、湿度和积雪深度等物理量之间的关系模型,实现对雨雪冰冻天气的预测。Kim等[20]提出一种以卷积神经网络(convolutional neural networks, CNN)为基础构建的深度学习模型,对卫星图像中过冲云顶(overshooting top,OT)特征进行检测,其识别命中率(probability of detection,POD)为79.68%,误报率(false alarm ratio,FAR)为9.78%,较传统图像识别算法具有更好的识别效果。
将深度学习技术应用到对雷雨大风等强对流天气的智能识别也是近年来一些气象工作者努力的目标。但由于强对流天气的生消发展速度快、局地性强、空间尺度小,使得其在雷达回波图像上所表现的一些典型特征并不总是存在,而一些关键性特征又难以客观量化,这使得不论采用图像模式识别还是机器学习识别,都难以有效实施应用。
1 传统识别方法存在的技术问题
目前中国最常用的多普勒天气雷达基数据主要包括3种产品,分别为基本反射率因子、平均径向速度和速度谱宽。其中,基本反射率因子的大小反映了探测区域内部降水粒子的尺度和密度分布情况,在回波图像上常称作回波强度。一般情况下,回波强度越高,发生强对流天气的概率也越大。平均径向速度则反映了降水粒子接近或远离雷达中心点的移动情况。利用雷达基数据可绘制出回波图像和径向速度图像以及多种衍生产品图像,再运用图像识别算法或结合气象学的一些物理参量,能够有效识别出飑线、强降水和雷暴等灾害性天气[21-22]。但有关如何进一步提高强对流天气识别和预报的准确性,以更好地满足人们生活和社会产生的需求,仍有几方面技术难题需要攻克。
(1)识别算法的可靠程度受局地气象条件影响较大[23]。现有的各种强对流天气或灾害性天气识别算法多是基于某一地区进行研究和检验,所构建的算法模型普适能力较差。
(2)雷雨大风天气的识别能力日趋成熟,但提前预警能力相对较弱[24]。雷雨大风是强对流天气系统中生消发展极为复杂的一员,因其空间尺度小,变化速度快,尤其是在风暴形成初期和消亡阶段,对其形态特征的准确识别极为困难,进而也影响到提前预报预警的能力。
(3)实时气象观测数据量巨大,业务人员主观研读分析海量资料越发难以实施。随着气象信息化程度的不断提升,每天数以10 GB甚至100 GB的数据量已然超出气象工作者主观研读的能力,因此,亟需借助计算机智能识别相关技术,实现对强对流天气的快速识别和精准预报。
为了克服上述困难,提出一种以深度神经网络为模型,以雷达回波图像为主要输入,利用光流技术生成回波移动光流图像作为辅助输入,通过数据集增强、代价函数优化和模型泛化性能优化等步骤,实现对强对流天气智能识别的方法。
2 基于深度神经网络的雷雨大风识别算法
2.1 技术路线
深度神经网络是机器学习领域的一种技术,它通过多次组合低层特征形成更加抽象的高层次属性或特征,经过迭代训练数据集,调整网络参数,降低统计误差,进而自学习出一组用以发现数据分布特征或规律的超参数集合。其中,卷积神经网络(CNN)是深度神经网络中应用最广的一种单元结构,CNN在应对大型图像处理方面有着出色的表现,目前已被应用到图像分类、识别和物体检测等诸多领域。
与传统基于雷达图像特征识别的技术相比,运用CNN进行强对流天气智能识别的最大优势在于它不需要针对不同地区、不同季节的雷达图像分别梳理总结出一套发生规律或特征。只要输入神经网络的样本数量足够多,且样本的时间分布和地理空间分布相对均衡,再结合一些模型优化技术,即能通过CNN构建的网络模型完成对雷达图像所表征的天气现象的准确识别。方法的总体技术路线如图1所示。
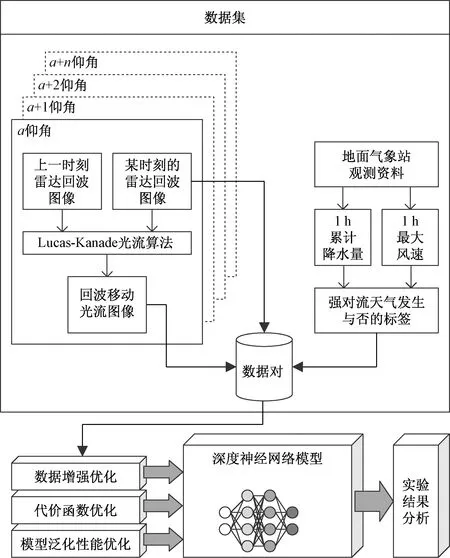
图1 总体技术路线Fig.1 Overall technical roadmap
目标是要构建一个以CNN为基础的深度神经网络模型,通过大量样本“数据对”的迭代训练,寻求雷达回波图像和回波移动光流图像与“是否发生了强对流天气现象”之间的一组函数映射关系。雷达回波图像可通过专业软件绘制输出,回波移动光流图像采用基于Lucas-Kanade的局部约束法计算得到。而判定“是否发生了强对流天气”的标签则通过地面气象观测资料中的小时降水量和最大风速以一定的规则计算得到,这些规则将在下文给出。
深度神经网络模型将预处理后的雷达图像与地面气象站的气象资料通过经纬度信息结合起来,生成用来训练和测试的数据集。实施过程主要包括数据集的构建、强对流天气识别模型的构建、数据集增强优化、代价函数优化,以及模型泛化性能优化等。检验过程通过客观量化的评价指标,统计每种优化技术产生的效果,并对结果加以分析。
2.2 数据集构建
数据集的构建主要是生成两种雷达图像(雷达回波图像和回波移动光流图像)与强对流天气发生与否的标签这两者间的“数据对”。其中,雷达回波图像常见有两种表现形式,一种是在一系列固定仰角上扫描一圆周得到的采样,即平面位置显示 (plane position indicator, PPI)方式扫描;另一种是将PPI数据通过空间插值算法计算出某一等高面上的回波采样,即等高平面位置显示(constant altitude plan position indictor, CAPPI) 方式扫描。在业务上,CAPPI回波图像更适用于对中层辐合辐散和强对流的分析。为了避免因插值计算造成的回波强度失真对模型训练结果的不利影响,本算法采用PPI方式扫描的回波图像作为模型的一部分输入。
光流是图形图像领域的一个基本概念,它能够刻画连续图像之间的运动特征。光流的概念最早由Gibson等提出,又由Horn、Lucas等一些学者先后提出图像光流的具体计算方法,为光流相关研究奠定了重要理论基础。近年来,光流技术已被应用到运动目标检测、机器人路径规划和天气外推预报等诸多领域[25-27]。回波移动光流图像是本算法模型的另一部分输入。由于回波图像中表征风暴中心的高值回波区域具有“非刚体”特征,其形态随风暴的生消发展持续变化,无法满足Horn-Schunck全局光流平滑的假设,因此,本算法采用了基于Lucas-Kanade的局部约束法来构建光流场。数据集中一组雷达回波图像和回波移动光流图像如图2所示。
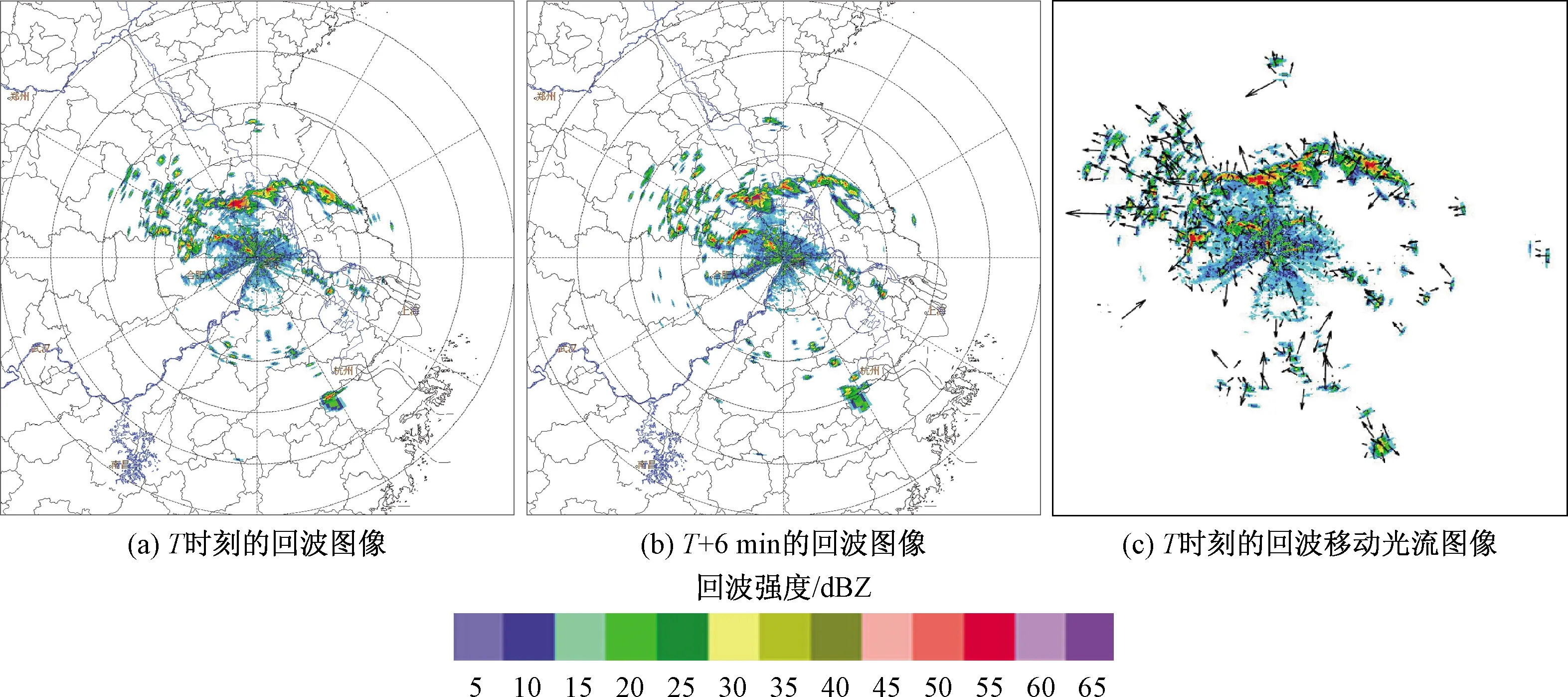
图2 本文算法使用的雷达图像示例Fig.2 Examples of radar images used in this algorithm
图2中3幅图像分为T时刻的回波图像、T+6 min时刻的回波图像以及T时刻的回波移动光流图像。由于本算法采用的是VCP21方式的雷达体扫,体扫周期为6 min,因此,图2(b)采用的是T+6 min的数据。图2(c) 是由图2(a) 和图2(b) 采用基于Lucas-Kanade的光流算法计算得到,为了在图像上清楚地标识光流信息,图2(c) 光流箭头进行了稀疏处理。
短时强降水和大风是最典型的强对流天气,本算法采用这两种易于被地面气象站观测到的天气现象作为判定强对流天气发生与否的标签。其中,降水量通过地面气象站(包括加密自动气象站)记录的分钟降水量信息累加得到近1 h的降水量。大风的风速则根据地面气象站记录的瞬时风速或极大风速,通过求取近1 h的最大风速得到。具体判定规则如下:①1 h的降水量达到或超过20 mm判定为发生短时强降水;②1 h最大风速达到或超过17.2 m/s判定为发生大风;③由于雷达探测到强对流天气特征的时间往往早于地面观测到短时强降水或大风,因此,以地面气象站观测时间为基准,往前推2 h的时间范围内,分析这期间是否存在雷达基本反射率数值达到或超过50 dBZ的情况。当仅满足条件①和③时,标记为发生了短时强降水;当仅满足条件②和③时,标记为发生了大风;当上述3项条件同时满足,标记为发生了强对流天气;其他情况下,均标记为无强对流天气。强对流天气发生与否的标签定义为表1所示的4类事件。

表1 事件定义Table 1 Event definition
由于雷达和地面气象站数据均包含地理经纬度信息,因此,可通过数学方法实现两种数据在空间上的一致性转换。又由于引发强对流的风暴质心的垂直高度一般不超过16 km,而雷达径向上各个探测点的高度随着与雷达位置的远离而不断增高,通常距离雷达中心点60 km外的高仰角探测点的垂直高度已超过16 km。因此,对所有图像统一截取以雷达所在位置为中心点,长宽均为120像素的图像作为本方法模型的输入。此外,由于VCP21体扫方式下9个仰角中,最高仰角的信息量较少,对强对流天气识别的意义不大。因此,输入的回波图像剔除了最高1个仰角的信息,只采用8个仰角面的回波图像。
与某一仰角回波图像相对应的回波移动光流图像是由前一探测周期,同一仰角的回波图像与当前回波图像,通过光流法计算得到的光流场生成。上述8个仰角的回波图像分别对应1个回波移动光流图像。综上所述,本算法输入到深度神经网络的数据是一个120×120×(8×2) 的三维向量。
2.3 深度神经网络模型构建
CNN是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的核心算法之一。CNN具有很强的特征学习能力,它对图像的缩放、平衡和倾斜等目标物形变具有良好的适应性。VGGNet是牛津大学计算机视觉小组(Oxford Visual Geometry Group)和Google DeepMind公司共同研发的一种深度卷积神经网络模型。该模型曾获得ILSVRC 2014年比赛的亚军和定位项目的冠军[28],在图像特征提取和图像识别领域具有非常优异的表现。
本算法借鉴了VGGNet的结构,搭建适用于强对流天气智能识别的网络模型,模型结构如图3所示。

图3 强对流天气智能识别的神经网络结构Fig.3 Neural network structure for intelligent recognition of strong convective weather
图3中,输入是一个长宽均为120像素,由16幅图像(8幅回波图像和8幅回波移动光流图像)构成的三维向量。经过10次卷积和3次池化,以120×120×64为例,前2项表示图像的大小,64表示卷积核的数量。图3中各层的作用与图例中名称的含义相一致。卷积层和全连接层所采用的激活函数均为ReLU函数。除了图3所示的各个神经元层外,在输入层后还增加了批规范化层(batch normalization),用于提升该模型训练的鲁棒性。
2.4 数据集增强
从数理角度来看,利用卷积神经网络进行强对流天气的雷达图像特征分类识别,其基本思想是利用结构风险最小化原则,通过大量样本数据的训练和迭代,以寻求期望风险上界的最小值。由于结构风险能较好地权衡训练误差和模型的复杂度,因此采用以卷积神经网络为代表的深度学习模型理论上具有较好的泛化能力。但由于强对流天气在一年中并不总是发生,标识为发生强对流的标签相较于数据集中所有标签,占比很少,属于小概率事件。如果采用传统的训练数据集分类方法,很可能会出现“不均衡数据”问题,导致深度学习模型的训练结果偏向于大概率事件,即没有强对流天气发生,大大增加了漏报的概率,降低了识别的准确性。
为了克服上述问题,本模型通过对低概率训练样本进行多重采样,实现数据集的增强优化。具体方法为将可能存在强对流天气特征的回波图像通过平移、旋转、变形和增加噪声等方式,生成多个新的训练样本,使得数据样本中发生强对流天气的占比有所增加,进而降低数据不均衡对模型训练产生的不利影响。图4所示为数据集增强的一个示例,其中,图4(a)所示为雷达回波图像原图,该图长宽均为120像素,图像中心位置对应雷达中心点,不同颜色代表不同的回波强度,强度的大小与图4右侧的图例相对应。图4(b)~图4(f)分别是由图4(a) 经顺时针旋转、逆时针旋转、放大、缩小和放大旋转生成。

图4 数据增强示例Fig.4 Examples of data enhancement
由于雷达图像上各个像素点的经纬度坐标可计算得到,同时,地面气象站的经纬度信息已知,因此,上述图像形变后,地面气象站的空间位置也随图像形变做出调整,以确保雷达图像与强对流天气发生与否的标签在地理位置上始终保持一致。
2.5 代价函数优化
机器学习中的代价函数 (cost function) 又称损失函数 (loss function),它是将随机事件或与其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数[29]。损失函数往往与学习准则和优化问题相关联,并且常通过最小化代价函数来求解或评估模型的优劣。为了进一步改善数据集的不平衡问题,本模型提出在代价函数中引入类别权重,赋予实际发生了强对流,但模型未识别出强对流这种情况更大的惩罚值。改进后的代价函数为

(1)
式(1)中:yi为强对流天气的示性函数;ti为CNN模型对应于强对流天气的输出,表示该区域被识别为强对流天气的概率;m为一次训练过程样本的数量;w为判定权重项,即惩罚值。该值越大模型会将更多的雷达图像判定为存在强对流天气,进而造成更高的误报率,但相应地,识别的成功率也会提升。很显然,w的取值将对模型识别结果产生重要影响,具体取值将在实验与结果分析部分进行论证。
2.6 模型泛化性能优化
由于强对流天气的发生具有一定的季节特征,而数据集中各个“数据对”是按气象资料的时间先后顺序组织的。为提升模型的泛化性能,进一步采用无重复抽样的K折交叉验证技术[30],使得神经网络在训练时每个“数据对”只有一次被划入训练集的机会。所谓K折,是将原有数据集拆分成K份,其中K-1份作为训练集,剩下的一份作为验证集。具体步骤如下:
(1)如图5所示,将原有数据集随机地拆分为K份。

图5 K折交叉验证示例Fig.5 Example of K-fold cross-validation
(2)挑选任意一份作为验证集,剩余均作为训练集,用于CNN模型的训练。通过该训练集训练后得到一个带有网络参数的模型,用此模型在验证集上进行测试,并保存模型的评价指标Ei。
(3)重复第2步K次以确保所有子集都有且仅有一次机会作为验证集。
(4)将各组评价指标的均值作为模型精度的估计,并将其作为当前K折交叉验证下CNN网络模型的综合评价指标,公式为

(2)
通常,对于原数据集的拆分采取的是均分方式,为了更好地均衡强对流天气实际发生在数据集中的分布,可以采取进一步的策略使每组内的有无发生强对流天气的占比跟总体数据集中占比近似一致。
K折交叉验证的优势在于:一方面,可从有限的数据集中获得尽可能多的有效信息,避免陷入局部的极值,并寻求最优参数;另一方面,多个模型可以用于模型集成,提升模型识别的准确率和稳定性。
3 实验与结果分析
3.1 数据说明
为了检验上述方法识别强对流天气的效果,实验准备了2019年3—8月安徽省多部雷达探测数据和地面气象观测资料作为数据集。该雷达体扫周期为6 min,经极坐标转换和空间插值计算,生成1 km×1 km 分辨率的网络化数据。地面气象站记录的周期为1 min,记录了降水量、风向和风速等气象要素信息。采用2.2节所述方法构建数据集,生成若干组由雷达探测资料(回波图像和回波移动光流图像)与强对流天气发生与否的标签构成的“数据对”。
通过分析所构建的数据集,发现晴好天气的占比超过80%,而强对流天气占比不足2%,尽管模型将采用数据集增强等优化技术,但数据集的严重“失衡”依然会影响模型训练的结果。因此,采用数据增强技术将数据集中存在强对流天气的样本数扩展了20倍,晴好天气且无高值回波的样本数做了适当缩减,保持总样本数与调整前相近。最终得到发生强对流天气的样本数近20 000组,未发生的近62 000组。
3.2 检验方法说明
采用气象上常用的命中率(POD)、误报率(FAR)两项指标来定量评估强对流天气识别的效果。其中,POD表示采用本文算法识别到强对流天气,并且实际发生了强对流天气的数量占实际发生强对流天气总数的比例。FAR表示采用本文算法识别到强对流天气,但实际未发生强对流天气的数量占本算法识别为强对流天气的总数的比例。计算方法为

(3)
3.3 实施过程说明
首先,采用3.1节和2.4节所述方法扩充数据集中发生强对流天气的“数据对”的占比,降低数据不均衡问题对模型训练的不利影响。
然后,按照2.5节所述方法,定义7个惩罚项参数w={1.0,1.5,2.0,2.5,3.0,3.5,4.0} 分别用于检验。
接着,按照2.6节所述方法,采用K折交叉验证,将数据集拆分为5、10、20份,分别进行模型的迭代训练。
最后,采用2.3节所述网络模型,将数据集应用于该模型进行训练和检验。为了检验数据增强优化和代价函数优化的效果,实验实施和结果分析时,首先列出了不做相关优化的统计结果。
3.4 结果统计分析
本模型最后一层采用softmax函数输出值域为[0, 1] 的概率值γ。在二分类问题中,常以γ=0.5作为区分类别的临界值,这里采用多组γ值,分别检测模型识别的效果。首先统计不做任何优化的深度神经网络模型识别强对流天气的效果。直接将3.1节所述的数据集拆分成5份,其中4份用于模型的训练,剩下1份用于检验。统计出4种事件和POD、FAR的值如表2所示。
从表2的10次检验结果可以看出,γ=0.45时该模型对强对流天气识别的命中率(POD)最高,但同时误报率(FAR)也相对最高。随着γ取值的增加,POD和FAR均逐步下降,且不同的γ取值对POD的影响大于对FAR的影响。由于整个数据集中发生强对流天气的样本数占比很低(不足2%),在识别出强对流天气的同时,不可避免会发生误报,而“未发生强对流天气”很大的基数导致误报数量相较于“发生了强对流天气”的数量大很多,超出了一个数量级,因此在统计上表现出极高的误报率(FAR)。

表2 未做优化的检验结果Table 2 Unoptimized test results
接着,采用数据集增强处理后的训练集再做相同检验,统计出4种事件和POD、FAR的值,如表3所示。

表3 数据集增强后的检验结果Table 3 Test results after data set enhancement
从表3可以看出,增强后的数据集大幅提高了“发生了强对流天气”样本的占比,识别命中率升了7%~12%,并且,误报率有了显著下降,从优化前的90%下降到50%左右。γ取值的不同对POD和FAR的影响,其规律与优化前基本一致,总体来看,γ=0.5仍是相对较优的用于判定是否发生强对流天气的临界值。以表3中γ=0.5的POD和FAR指标为基准,进一步评估各项优化产生的效果。
进一步采用2.5节所述的代价函数优化方法,检验式(1)中不同取值的惩罚值w对识别效果产生的影响。从图6可以看出,随着惩罚值w取值的增加,POD指标逐步提升,但提升幅度趋缓,当w增加到3.5后,POD不再有明显提升,保持在85.1%。同时,FAR指标也有所升高,升高幅度小于POD的升幅,且同样在w增加到3.5后不再有明显变化,保持在57.3%。
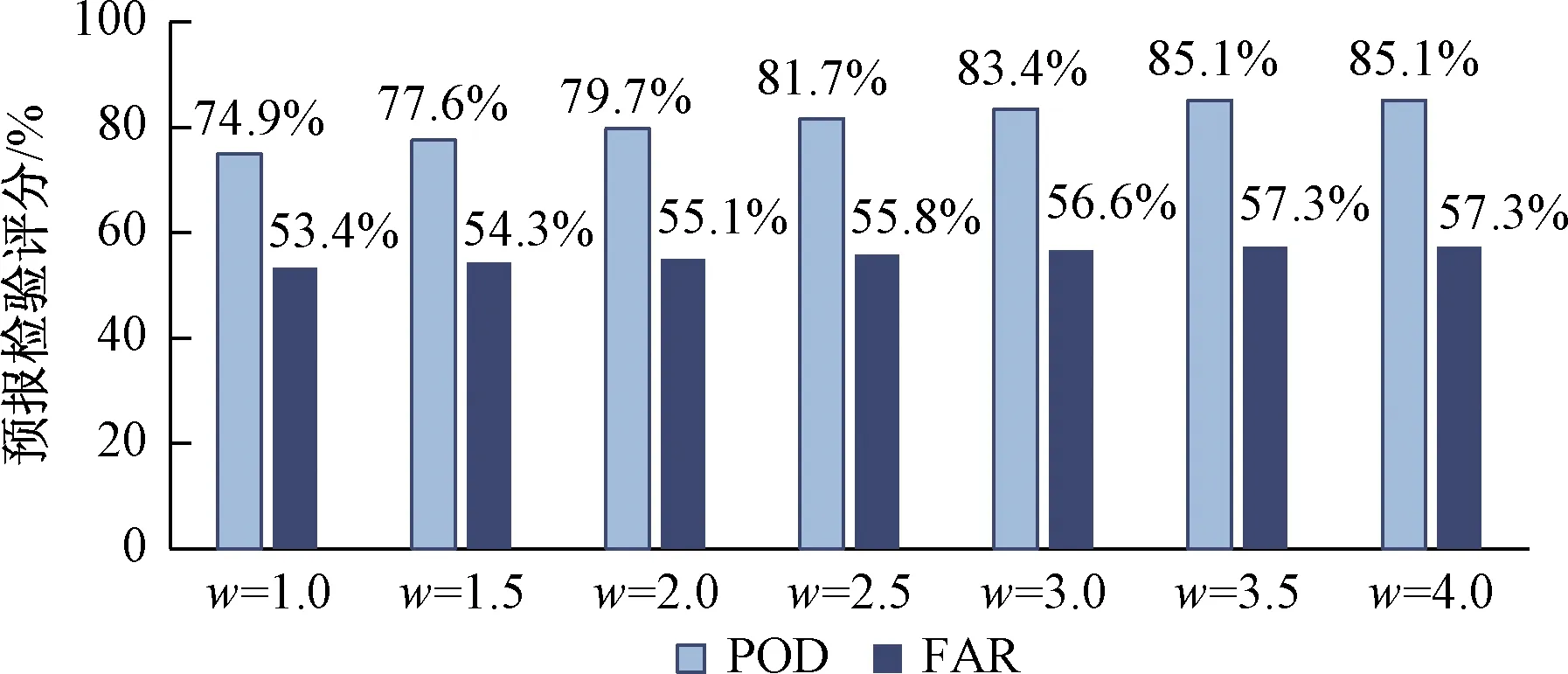
图6 代价函数优化效果统计Fig.6 Cost function optimization statistics
图7给出了K折交叉检验优化对对识别效果产生的影响,并使用w=1.0和w=3.0作为对标。
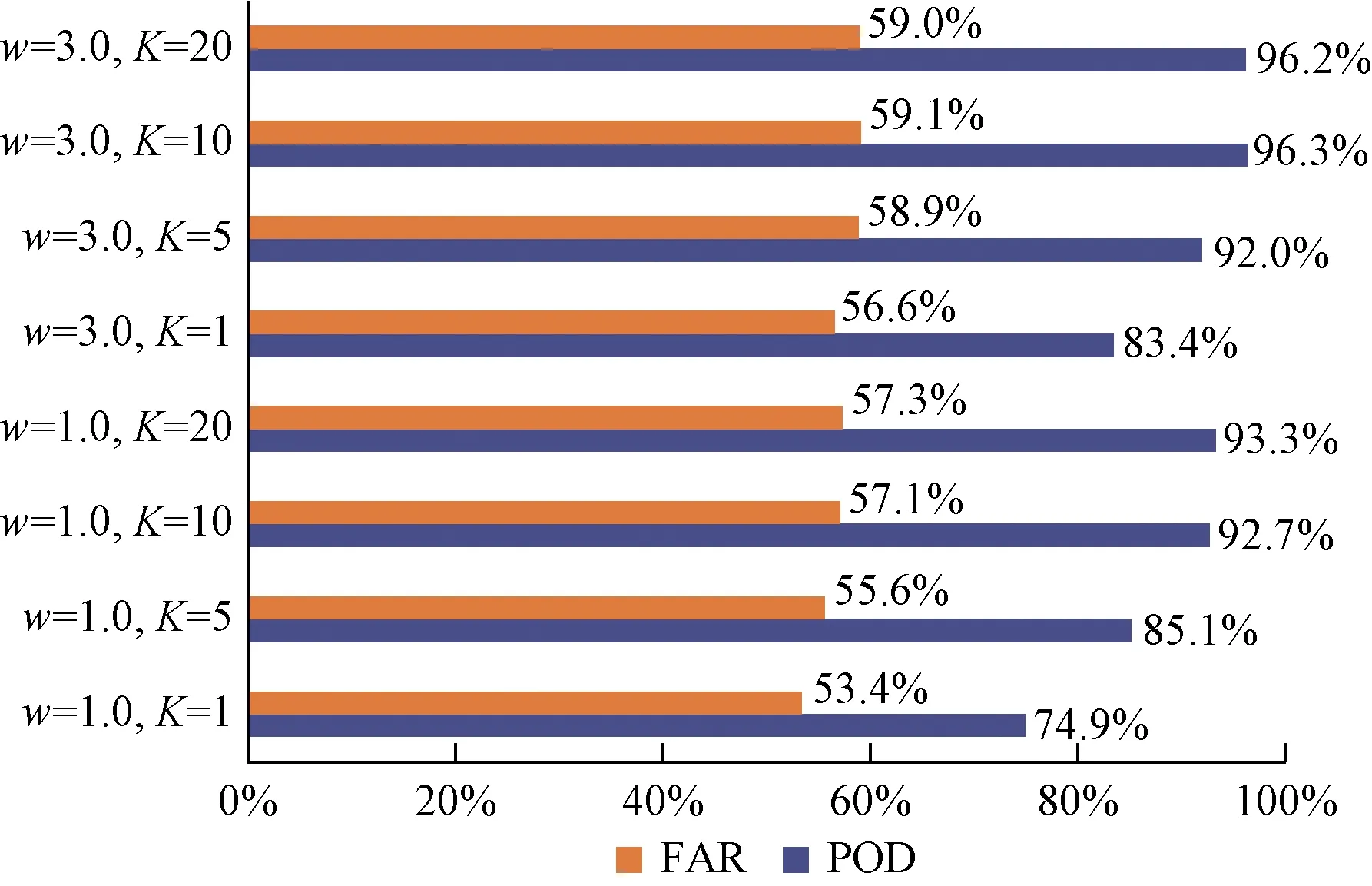
图7 K折交叉检验优化效果统计Fig.7 K-fold cross-validation optimization effect statistics
可以看出,采用K折交叉检验对于POD指标的提升是非常显著的,在w=1.0,K=10时,POD最高达到96.3%。而当K取更大的值时(K=20),并不能带来更高的识别命中率。K折交叉检验对FAR指标的影响,相较POD而言影响较小。此外,实验过程中还发现,设置较大的w值,在模型训练的初期,误差收敛的速度相对更快,而到了模型训练的后期,这一速度优势并不能带来识别准确率的显著提高。
为了进一步找出FAR指标“居高不下”的原因,对数据集的部分个例样本进行了深入分析,结果发现,很多有台风发生的时段,地面气象站都观测到短时强降水和大风,而此时的雷达回波并不强。
如图8所示,图8(a)中红色区域表示台风天气的数据加入训练集后模型识别出强降水和大风天气的高概率落区,白点为标识为存在强对流天气的地面气象站站点。图8(b)为同一时刻的雷达回波图像。可以看出,大量的地面气象站因观测到短时强降水和大风,按照2.2节所述规则,被标识为“发生了强对流天气”,而此时的雷达回波虽然覆盖区域很广,但回波强度普遍不高,并非真正的强对流天气。正由于存在大量被错误标定的“数据对”输入模型,使得很多弱回波特征被模型判定为“发生了强对流天气”,这在很大程度上增加了误报的机率。

图8 台风天气对模型识别率的影响Fig.8 Influence of typhoon weather on model recognition rate
4 结语
提出一种基于深度神经网络技术的强对流天气智能识别方法,该方法能够将以往由气象工作者主观研读雷达资料来分析强对流天气的过程自动化、定量化,提高了对强对流天气识别相关业务的可靠性和时效性。实验结果表明,采用上述方法优化后的深度神经网络模型对强对流天气识别的命中率可达96.3%,误报率低于60%。
由于大风和短时强降水的成因不仅是强对流天气,还可能受到台风的影响,而单纯由强对流天气引发的大风和短时强降水又很难逐一界定。如果在构建数据集时,能通过某些技术手段区分出台风等非强对流天气引发的强降水和大风,提高数据集中标签的准确性,势必在一定程度上提高模型对强对流天气识别的准确率,尤其是能降低识别的误报率。
