基于非结构数据和EMD-WTS二层分解的AQI组合预测方法*
2021-04-13刘金培张了丹
刘金培,张了丹,丁 蓉,汪 漂,罗 瑞
(1.安徽大学 商学院,合肥 230601;2.北卡罗莱纳州立大学 工业与系统工程系,美国 罗利 27695)
0 引 言
近年来,我国空气污染问题日趋严重[1]。通过监测包括PM2.5、SO2、NO2等在内的空气污染物,空气质量指数(Air Quality Index,AQI)能够全面地反应空气污染状况。因此,AQI的有效预测有利于政府制定科学的环境保护政策,对于维护居民健康、改善生态环境而言意义重大。
已有预测模型大多仅以历史数据作为输入。然而,由于历史数据的收集与公布通常具有滞后性,模型的预测精度往往受到限制。此时,结合具有即时性的非结构数据能够弥补由历史数据预测带来的预测滞后性,从而增强预测结果的时效性。非结构数据主要指网络搜索数据。张玲玲等[2]将非结构数据融入旅游市场客流量预测模型,Francesco等[3]结合非结构数据与失业预测模型,陈声利等[4]将非结构数据引入股指期货波动率预测模型。上述研究均证实了非结构数据对于预测效果起正向促进作用,但目前将非结构数据应用于空气质量指数预测的研究仍为少见。由于空气质量相关关键词的网络搜索热度能够反映社会公众对空气质量关注程度的改变,可以对空气质量的变化起到一定的预见与解释作用。因此,尝试将网络搜索数据融入AQI预测框架,进一步改善预测效果。
非结构数据能弥补历史数据的不足,但同时增加了AQI预测模型输入数据的复杂性,同时AQI时序具有随机性、非平稳性等特征[5]。为解决上述问题,传统研究多采用单一分解方法对分解数据以有效获取数据所含有效信息,进而提高预测精度。已有研究表明,相较于单一分解方法模型,二层分解模型能够充分地提取数据特征并克服单一分解方法带有模态混叠等固有缺陷的问题,其预测效果更为显著[6]。罗宏远等[7]结合二层分解技术应用于PM2.5浓度预测,梁小珍等[8]将二层分解策略应用于航空客运需求预测。上述模型均证实了二层分解方法表现显著优于传统的单一分解策略。在此基础上,运用EMD-WTS模型对AQI非结构数据与历史数据进行二层分解,以充分刻画数据的细节波动,进而减小预测误差。
数据分解虽有助于提高预测精度,但由于分解后所得序列分别具有不同的特征,因此使用单一预测方法所得结果精度较低。研究表明,使用组合预测模型可以形成模型优势互补,能有效避免单一模型弊端[9]。具有多样性的组合预测模型能够充分利用分解所得维度所含信息,同时适用于具有不同特征的数据。因此,选取Holt指数平滑法、支持向量回归(SVR)以及人工神经网络(ANN)3种预测方法对二层分解所得预测结果开展预测,该组合预测框架同时适用于具有线性或非线性特征的数据,同时包含了传统计量模型与人工智能模型,能够全面考虑分解所得序列的特征,从而进一步提高了预测精度。
综合已有研究,可以发现AQI预测仍存在下述问题:(1)已有AQI预测方法大多对数据进行单一分解,而AQI数据的高复杂性与非平稳性导致该方法无法全面提取数据特征,且单一分解方法带有模态混叠等固有缺陷;(2)少部分研究对AQI历史数据进行二次分解,但基于历史数据的预测所得结果具有滞后性,现有AQI预测研究对于融入以及如何融入非结构数据以弥补历史数据不足仍缺乏探索;(3)单一预测方法难以同时捕捉分解所得序列的不同特征,此时运用包含多个不同特征预测方法的组合预测模型将显著提升预测效果。
因此,针对已有研究存在的问题,提出一种结合非结构数据的EMD-WTS的二层分解AQI组合预测方法。首先,基于百度指数“需求图谱”功能等筛选AQI相关百度指数关键词,并使用局部线性嵌入(LLE)进行降维。其次,对降维结果与AQI历史数据进行EMD分解,重构后得到降维结果与AQI历史数据的原始高频序列、低频序列与趋势序列。接着,对所得高频序列均进行WT分解,重构后得到原高频序列的高、低频与趋势项。然后,对上述所得序列分别运用Holt、SVR、ANN进行组合预测并将所得结果输入BP神经网络进行集成,集成所得结果相加后得到原高频序列预测值。同时,运用相同的组合预测方法对原始低频与趋势项分别开展预测,得到各自预测结果。最后,将原始高、低频与趋势项预测结果相加,得到融合非结构数据的AQI二层分解组合预测结果。为验证上述模型的预测精度,开展仿真及对比实验,证实了本模型预测精度更高、预测效果更为显著。
1 组合预测模型理论与框架
考虑到AQI非结构数据与历史数据的高复杂性与非平稳性等特征,提出一种融合非结构数据的二层分解组合预测新框架,具体内容如下。
1.1 非结构数据
1.1.1 非结构数据获取
AQI网络搜索数据反应了居民及政府对于空气质量的关注度。AQI相关关键词的网络搜索热度能够反映社会公众对空气质量关注程度的改变,可以对空气质量的变化起到一定的预见与解释作用。相对于谷歌搜索引擎,在我国百度搜索引擎占据更高市场份额,是体现我国居民关注度的重要数据来源。因此,选取百度指数作为非结构数据源,通过百度指数关键词体现居民对于AQI的关注度。
综合专家推荐与百度“需求图谱”功能,筛选AQI相关关键词。百度指数“需求图谱”功能展示了关键词与各时期内相关检索词之间的关联强度,能够充分体现出网民的需求。最终,确定了空气质量、PM2.5、CO、北京空气质量、大气污染、雾霾等30个最能反映居民对于AQI专注度的百度指数关键词,提取2019-01-01至2020-01-31的指数数据。
1.1.2 LLE降维
由于获取的百度指数维度高且存在信息冗余,直接用于预测将导致模型高度复杂、预测效率低等问题。因此,对非结构数据进行降维十分必要。选用局部线性嵌入(LLE)算法对之降维。LLE原理在于使得降维前后近邻之间的局部线性结构不变,具体步骤如下[10]。
Step 1根据数据集X=[x1,x2,…xn]各点之间的欧氏距离寻找每个样本点xi的k个最近邻{xj,j∈Ji},Ji表示样本点xi的k个最近邻点下标集合。
Step 2计算各点与对应邻域点之间的重构权值wij(非邻域点取权重为0),通过最小化重构误差计算权重矩阵W,如式(1)所示:
(1)
Step 3最小化降维带来的损失函数,如式(2)所示:

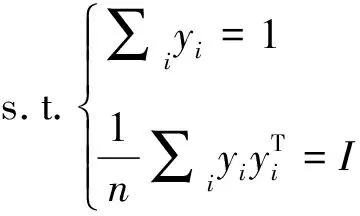
(2)
其中,I为单位矩阵。另取M=(I-W)T(I-W),求得低维嵌入Y取M的最小d+1个特征值对应的特征向量v2,v3,…,vd+1,即Y=[v2,v3,…,vd+1]T。
1.2 二次分解与重构
1.2.1 二次分解
由于AQI数据具有高复杂度于非平稳性特征,采用EMD-WTS二层分解模型对之进行数据分解,以全面获取数据特征。
(1)经验模态分解(EMD)。EMD分解能较好地分解非平稳、非线性时序,有较好的时间与频率分辨率[11]。分解后得到多个频率由高至低排列的IMF分量及一个残差项,如式(3)所示:
(3)
其中,x(t)代表原时间序列,IMFk(t)代表第k个本征模函数,RN(t)代表残差项。
(2)小波分解(WT)。小波分解所得各序列具有单一频率,因而具有更好的稳定性,其定义如式(4)所示[12]:
(4)
其中,m是比例因子,n=1,2,…,N是采样时间,N是样本数。
1.2.2 数据重构
根据数据特征对分解结果进行重构将有效降低模型复杂度,提高模型预测效率。首先,按频率由高至低排列分解结果并计算其均值,接着利用t检验确定均值显著偏离0的第m个序列,最后叠加第1个至m-1个序列获取原始序列的高频项,叠加第m至最后一个序列得到低频项[13]。
1.3 组合预测
组合预测由于其方法的多样性能降低预测误差。选取线性与非线性模型、传统计量与人工智能模型搭建组合预测框架,具体包括Holt指数平滑模型、SVR以及ANN。
1.3.1 Holt
Holt指数平滑法适用于含趋势成分的时间序列预测。Holt模型一般形式如式(5)所示。
St=αxt+(1-α)(St-1+Tt-1)
Tt=γ(St-St-1)+(1-γ)Tt-1
Ft+k=St+kTt
(5)
其中:α,β为平滑系数,St为第t期的指数平滑值,Tt为第t期趋势值,F为预测值。
1.3.2 SVR
SVR为支持向量机应用之一,通过在高维空间中构造线性决策函数来实现线性回归,并用核函数代替线性方程中的线性项。SVR问题公式描述如式(6)所示[14]:
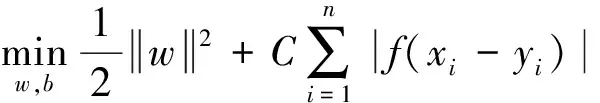
s.t.|f(xi)-yi|≤ε
(6)
其中,w为常向量,C为常量,(xi,yi)为给定数据训练集,f(xi)为映射函数。
1.3.3 人工神经网络
人工神经网络(ANN)算法启发于生物神经系统。类比于人脑学习,ANN将获得的“知识”存储于神经元之间的权重。ANN由输入层、隐含层以及输出层搭建而成,搭建时需要确定层数、每层的神经元数量、各层与拓扑网络之间的连接类型[15]。ANN由于其大规模并行、自组织、自学习等优点于包括预测在内的众多领域里得到了广泛的应用。
1.4 误差评价指标
为检验模型预测精度,通过对比各模型的平均绝对误差(MAE)、误差平方和(SSE)、均方误差(MSE)与平均绝对百分比误差(MAPE)数值来证实本预测模型结果的有效性。各指标计算公式如下所示:
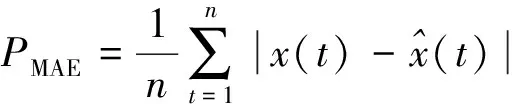

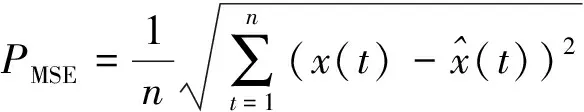
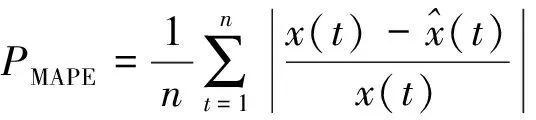
1.5 预测框架
根据上述文献梳理和理论基础,提出基于非结构数据和EMD-WTS二层分解的AQI组合预测框架(图1),具体步骤如下。
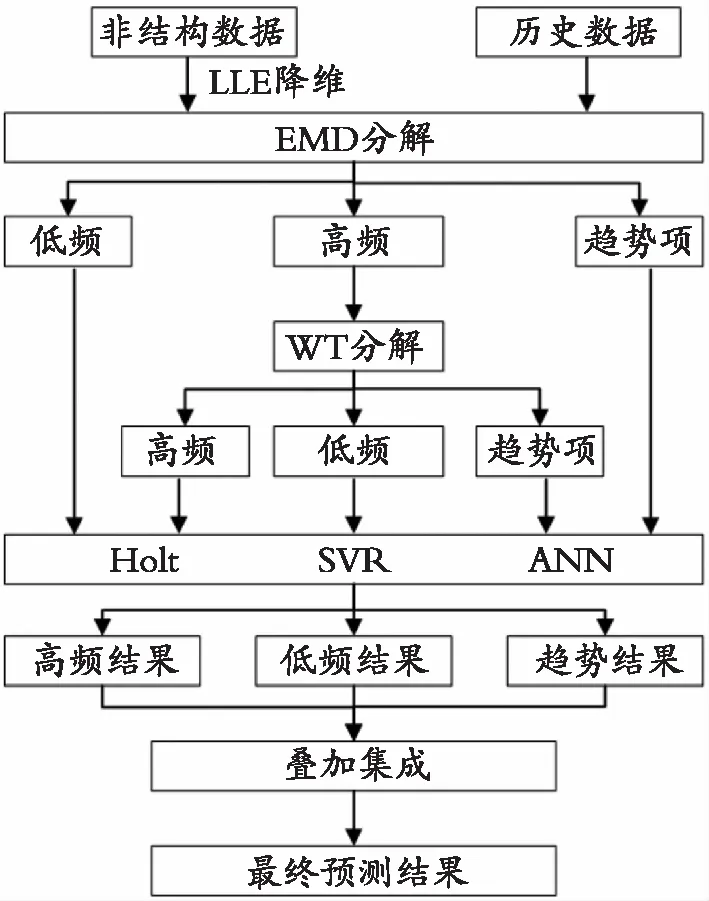
图1 本模型预测框架
Step 1根据专家推荐与百度“需求图谱”功能确定百度指数关键词作为非结构数据,并利用LLE方法对之降至2维得到序列L1与L2。
Step 2对AQI历史数据以及L1、L2分别进行EMD分解,而后运用均值检验进行重构得到各自的高频、低频与趋势序列。
Step 3对各高频序列进行WT分解,重构后得其高、低频与趋势项。
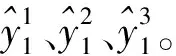
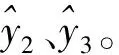
对比现有的AQI预测模型,上述预测框架存在如下优势:对AQI数据进行二层分解,更加全面地提取数据信息;运用非结构数据弥补历史数据滞后缺点,并运用LLE降维以降低模型复杂度,实现了非结构数据的有效利用;对特征各异的数据分解结果进行组合预测。模型既包含线性模型,又包含非线性模型,既包含传统计量模型,又包含人工智能模型,能够同时有效预测具有不同特征的数据。
2 仿真实验
2.1 数据来源于数据处理
在仿真实验中,以北京市为例,选取AQI在2019-01-01至2019-12-31期间的数据为训练集,在2020-01-01至2020-01-31期间的数据为测试集。同时,选取北京地域相应时间段的30个百度指数关键词的指数数据,并运用LLE对之降维,取k=6、d=2,得到两个降维后的序列L1、L2。
2.2 EMD-WTS二层分解与重构
首先,运用EMD模型对2019-01-01至2019-12-31的AQI历史数据与非结构数据降维结果进行分解。其中,EMD的趋势序列用res.表示,剩余序列用IMF表示。历史数据EMD分解结果如图2 所示。

图2 历史数据EMD分解结果
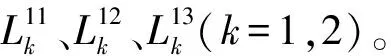
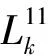
图3 历史数据高频WT分解结果
2.3 AQI组合预测
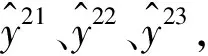
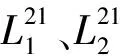
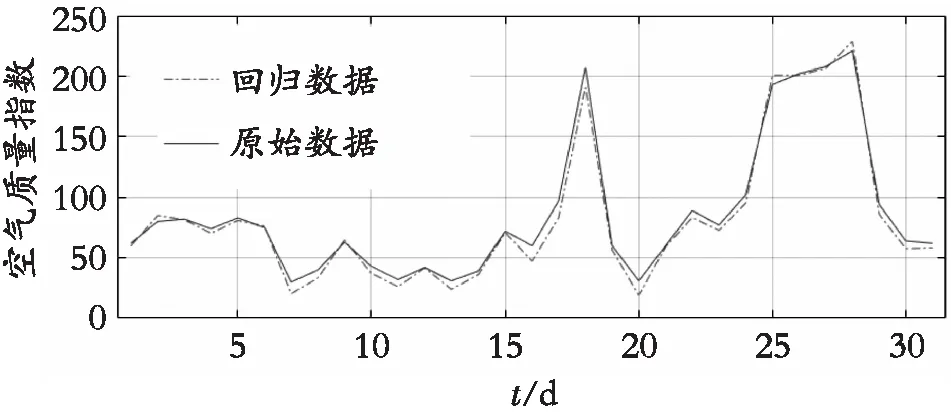
图4 历史数据预测结果图
2.4 各预测模型预测结果对比
为体现提出的结合非结构数据的二层分解组合预测模型的有效性,实验将对比本模型与其余5个模型。其中,模型1为二层分解-组合预测模型,对比本模型(即模型6)未使用非结构数据;模型2为非结构数据-EMD-组合预测,对比本模型未进行二层分解;模型3与模型4分别为非结构数据-二层分解-ANN模型与非结构数据-二层分解-SVR模型,对比本模型对分解结果仅单项预测;模型5为EMD-ARIMA,是现有研究预测方法[16]。通过记录各模型的MAE、SSE、MSE与MAPE指标来体现其预测精度,所得结果如表1所示。

表1 各模型预测精度评价指标对比
首先,对比各误差指标数值,发现本模型预测精度显著高于其他模型,体现了本文预测框架的实用性。其次,对各模型做详细对比:模型1相比本模型各误差指标值均较高,证实了非结构数据对于预测起显著信息补充作用,融入非结构可以提高预测精度;模型2对比本模型预测误差更大,说明二层分解能更为充分地刻画原始数据细节波动;模型3、模型4与本模型的误差数据对比突出了组合预测的重要性,由多种分解方法搭建的组合预测模型确实能吸收各模型优点,进而提高预测精度;模型5与本文模型的对比进一步体现了非结构数据、二层分解以及组合预测方法的显著效果,与现有研究方法的对比广泛地证实本模型的有效性。综上,对比实验综合地体现了本模型的有效性,证实了结合非结构数据的二层分解组合预测模型预测效果更为显著。
3 结束语
空气质量指数的精确预测对于维护居民健康、制定合理的环保政策以及改善生态环境具有重要意义。提出一种结合非结构数据的AQI二层分解组合预测模型,用非结构数据弥补历史数据预测的滞后性,并通过二层分解更为全面地提取数据包含的信息,最后利用组合预测克服单项预测无法适应不同特征分解结果的缺点,提高了模型的适用性。首先,基于百度指数提取非机构数据并运用LLE对之降维。其次,利用EMD分解AQI历史数据与降维结果,重构后得到AQI数据的高、低频与趋势项。接着,对各原始高频序列进行WT分解,得其高、低频与趋势序列。然后,对所得序列运用组合预测框架进行预测,并输入BP神经网络进行集成,得到各序列组合预测结果。累加上述结果输出原高频序列预测值。相同地,对原始低频与趋势序列进行组合预测与BP集成,得到各自预测结果。最后,叠加原高、低频与趋势项得到AQI最终预测结果。实验表明,非结构数据的加入对预测框架起显著信息补充作用,有效地提高了预测精度;二层分解相较单一分解更为全面地刻画了数据的细节波动,充分提取了原始数据特征,有助于减小预测误差;包含线性与非线性模型、传统计量与人工智能模型的组合预测体系充分结合各单项预测模型的优点,能同时适用于具有不同特征的分解所得序列,提高了模型预测效果。
参考文献(References):
[1] WU Q L,LIN H X.A Novel Optimal-hybrid Model for Daily Air Quality Index Prediction Considering Air Pollutant Factors[J].Science of the Total Environment,2019(683):808—821
[2] 张玲玲,张笑,崔怡雯.基于聚类方法的百度搜索指数关键词优化及客流量预测研究[J].管理评论,2018,30(8):126—137
ZHANG L L,ZHANG X,CUI Y W.Forecasting Tourist Volume Based on Clustering Method with Screening Keywords of Search Engine Data[J].Management Review,2018,30(8):126—137(in Chinese)
[3] D’AMURIF,MARCUCCIA J.The Predictive Power of Google Searches in Forecasting US Unemployment[J].International Journal of Forecasting,2017,33(4):801—816
[4] 陈声利,关涛,李一军.基于跳跃、好坏波动率与百度指数的股指期货波动率预测[J].系统工程理论与实践,2018,38(2):299—316
CHEN S L,GUAN T,LI Y J.Forecasting Realized Volatility of Chinese Stock Index Futures Based on Jumps,Good-bad Volatility and Baidu Index[J].Systems Engineering-Theory& Practice,2018,38(2):299—316(in Chinese)
[5] LI H M,WANG J Z,LI R R,et al.Novel Analysis-forecast System Based on Multi-objective Optimization for Air Quality Index[J].Journal of Cleaner Production,2019(208):1365—1383
[6] NA S N,ZHOU J Z,LU C N,et al.An Adaptive Dynamic Short-term Wind Speed Forecasting Model Using Secondary Decomposition and an Improved Regularized Extreme Learning Machine[J].Energy,2018(165):939—957
[7] 罗宏远,王德运,刘艳玲,等.基于二层分解技术和改进极限学习机模型的PM2.5浓度预测研究[J].系统工程理论与实践,2018,38(5):1321—1330
LUO H Y,WANG D Y,LIU Y L,et al.PM2.5Concentration Forecasting Based on Two-layer Decomposition Technique and Improved Extreme Learning Machine[J].Systems Engineering-Theory& Practice,2018,38(5):1321—1330(in Chinese)
[8] 梁小珍,邬志坤,杨明歌,等.基于二层分解策略和模糊时间序列模型的航空客运需求预测研究[J].中国管理科学,2020,28(2):1—11
LIANG X Z,WU Z K,YANG M G,et al.Air Passenger Demand Forecasting Based on a Dual Decomposition Strategy and Fuzzy Time Series Model[J].Chinese Journal of Management Science,2020,28(2):1—11(in Chinese)
[9] ZHU J M,LIU J P,WU P,et al.A Novel Decomposition-ensemble Approach to Crude Oil Price Forecasting with Evolution Clustering and Combined Model[J].International Journal of Machine Learning and Cybernetics,2019(10):3349—3362
[10] 贾晶晶,顾明亮,朱恂,等.基于流形学习与特征融合的汉语方言辨识[J].计算机工程与应用,2015,51(7):233—237
JIA J J,GU M L,ZHU X,et al.Chinese Dialect Identification Based on Manifold Learning and Feature Fusion[J].Computer Engineering and Applications,2015,51(7):233—237(in Chinese)
[11] 王书平,胡爱梅,吴振信.基于多尺度组合模型的铜价预测研究[J].中国管理科学,2014,22(8):21—28
WANG S P,HU A M,WU Z X.Forecasting of Copper Price Based on Multi-scale Combined Model[J].Chinese Journal of Management Science,2014,22(8):21—28(in Chinese)
[12] SUN W,ZHANG C C,SUN C P.Carbon Pricing Prediction Based on Wavelet Transform and K-ELM Optimized by Bat Optimization Algorithm in China ETS:The Case of Shanghai and Hubei Carbon Markets[J].Carbon Management,2018,9(6):605—617
[13] 杨云飞,鲍玉昆,胡忠义,等.基于EMD和SVMs的原油价格预测方法[J].管理学报,2010,7(12):1884—1889
YANG Y F,BAO Y K,HU Z Y,et al.Crude Oil Price Prediction Based on Empirical Mode Decomposition and Support Vector Machines[J].Chinese Journal of Management,2010,7(12):1884—1889(in Chinese)
[14] 甘中学,喻想想,许裕栗,等.基于周期性ARMA-SVR模型的空调冷热负荷预测[J].控制工程,2020,27(2):380—385
GAN Z X,YU X X,XU Y L,et al.Air-conditioning Cooling and Heating Load Prediction Based on Periodic ARMA-SVR Model[J].Control Engineering of China,2020,27(2):380—385(in Chinese)
[15] PKDM F,CAG S,GBL S D.Analysis of The Use of Discrete Wavelet Transforms Coupled with ANN for Short-term Streamflow Forecasting[J].Applied Soft Computing,2019(80):494—505
[16] 李勃旭,南西康,郑向东,等.基于EMD-ARIMA模型的地铁门传动系统早期故障预测[J].计算机系统应用,2019,28(9):110—117
LI B X,NAN X K,ZHENG X D,et al.Early Fault Prediction of Metro Door Transmission System Based on EMD-ARIMA Model[J].Computer Systems & Applications,2019,28(9):110—117(in Chinese)
