基于分布式数据采集和自然语言处理的高校网络舆情监控系统
2021-04-11张传营王世玉
张传营 王世玉 董 懂
(河北科技大学,河北 石家庄 050000)
2020年9月29日,中国互联网络信息中心发布第46次《中国互联网络发展状况统计报告》,截至2020年6月我国网民约9.04亿人,互联网普及率达67%,网民中学生群体占比达23.7%,人数为2.14亿,居于首位[1]。高校学生基数庞大,具有思想活跃、好奇心强、渴望表达等特点,其获取外界信息和发表观点的行为依托信息量庞大、内容繁杂、环境复杂的互联网平台,学生在复杂环境中思想动态极易受到影响,因此,高校学生网络舆情系统监控系统成为高校处理网络舆情问题的“利器”。
本系统以分布式数据采集和自然语言处理构建高效网络舆情监测系统,精准预测高校学生网络舆情的发生和发展规律,对高校网络舆情进行实时检测与防控疏导,这对把握引导高校学生意识形态具有重要意义,为我国教育事业的稳定发展和“三全”育人助力。
1 高校网络舆情现状
2020年4月,全国英语四六级考试取消,搜索量高达300万,热度值直线上升;甘肃某高校大学生家中刚脱贫就被电诈37万,这个事件在三个小时就达到了传播峰值,24小时被大V博主转发;蓝翔技校副校长带师生异地斗殴,不仅充斥媒体版面,也引发网友调侃“打架斗殴哪里强,中国山东找蓝翔”,学校名誉严重受损,还会影响招生,关系学校的生死存亡。
这几起高校舆情危机把高校舆情管理和应对问题推到公众视野。这些事件由校园突发事件引起,网上谣言四起,造成学生人心浮动,破坏正常校园秩序,一旦处置不力或不及时会直接演变为公共危机事件。近年来,高校网络舆情事件层出不穷,数量急剧上涨。据统计,2020年全国高校重大舆情同比增加33%,较2018年增幅达到133%。在互联网迅猛发展的新时代,如果妥当处置有苗头或者已经产生不良影响的危机事件,是所有高校现阶段的必修课。
2 高校网络舆情特点
高校网络舆情是指高校学生对于突发事件叙述、事件本身描述、个人观点的个人认知、情绪输出、解决措施,体现在互联网上不同方式不同程度的表现形式,是高校学生根据网络上舆情现状和自身思想动态状况结合加工后形成的反馈[2]。
第一,高校学生网络舆情具有网络舆情的一般特征:事件突发性、规律周期性和立场多元性等。不少同学生在面对同一内容讨论时,会根据自身的理解,从不同角度发表观点和见解。但同时,我们也必须清楚地认识到,由于人们对事件的认识和理解不同,自然发表的信息具有两极分化的特点,其中部分学生能够正确认识事件的原因和处置方法,同时也有很多学生的认知存有偏差,甚至利用互联网自由行性的特点,随意发表不当言论。如一些网民通过网络散布谣言、披露隐私、进行偏激和非理性的谩骂与人身攻击。
第二,传播集中性、诉求稳定性、规模易控性等独特特征。在传播上,高校网络舆情一般遵循“产生—发展—蔓延—衰退” 的成长周期,在舆情大规模爆发前都会经历一段酝酿时期在小范围内传播。若高校管理者能够尽早发现,提前行动,及时解决,对有效降低负面舆情信息传播规模,减少网络谣言带来的校园影响以及社会危害具有重要作用。
第三,如今,大学生所处的互联网环境是多平台多形式的新媒体环境,具有网络舆情分享方式更加便捷、参与限制性更低、信息更新迭代速度更快、信息传播范围更广等特点,给高校网络舆情控制带来挑战。它不仅仅与日常学习和生活相关,其他如国内外时事政治、军事和宗教等,均是校园网络讨论的范围。每当一个事件发生后,网络舆情的主题往往会随之发生变化。如以 2020年为例,发生的大事件包括:新型冠状病毒、女排在世界杯夺冠、华为被美国列入“实体清单”事件、疫情期间的封校管理等。每个事件发生后,均会引起学生在网络上的激烈评论和讨论。
3 系统的总体设计
互联网数据采集与分析系统软件采用开源的通用采集平台、自定义数据采集器、开源的Elasticsearch搜索引擎、大数据组件等,进行二次深度定制开发实现,系统后台使用Java、Python为主要工具语言,前端采用Vue框架,并可根据业务需求进行算法定制。
数据采集清洗子系统是自主研发的通用采集器,采用主从分离的分布式架构[3],在保证高效率数据采集的同时,也具备高可用性、高扩展性、快速定制采集规则等能力,从而保证数据在线处理子系统拥有增量式采集、按主题分类采集、可定制化采集的强大功能,因是自研发采集组件,可从底层优化采集效率,也可对抓取节点进行横向扩展,保障数据采集高效性。数据层的存储解决方案使用HBase+Elasticsearch的组合,均是基于Java开发的,其中Elasticsearch以Lucene的开源后端搜索引擎,同时也是目前发展最快、最受欢迎的搜索引擎,它具备强大的数据索引、快速搜索和海量存储能力。
数据资源管理子系统可通过开源的分布式数据存储组件,如Minio、HBase、Hive等,对文本文件、网页文件、PDF文档、Office文档等常见的数据类型提供统一的数据管理能力,并可从文本中提取关键信息、实体识别、实体属性等,构建领域知识图谱,对外提供知识服务。
数据分析应用子系统在使用开源的基础算法组件之上,根据业务需求定制算法,通过业务关注方向、专业设备分析模块、重要人物分析模块进行全方位、多角度、相关关联分析与扩展,为系统用户提供具有实际价值的具有前瞻性的综合分析内容。
系统采用“外网+内部局域网”方式进行部署,外网部署数据在线处理子系统基于Java开发的C/S架构设计,实现多节点、多进程、多线程并发的方式进行信息采集,能够部署在国产麒麟系统、Linux或Windows服务器平台上,实现互联网信息的采集清洗与跟踪,局域网部署数据分析管理子系统基于Java开发的B/S架构设计,前端使用主流的Vue框架以及阿里开源的ant-design组件,可达到完美兼容IE11和以Chrome、Firefox三款最主流的浏览器的目标,为机关首长提供一个信息浏览、统计与分析工具平台。
三个子系统之间可通过光盘方式实现数据摆渡,实现子系统间的数据交互。系统部署如图1所示。
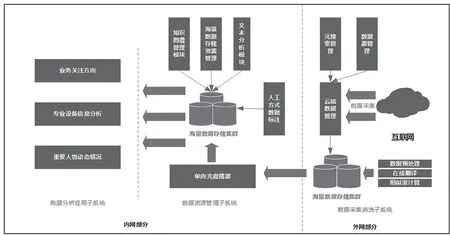
图1 系统总体设计图
4 系统总体架构设计
本舆情监控系统采用以Java语言为主、以开源软件为基础的定制化系统架构,系统共分4个层次,其中资源平台和基础平台层属于数据在线处理子系统,采用分布式的C/S架构,实现多线程并发信息采集与数据清洗,业务层和功能平台层属于数据分析管理子系统,采用B/S架构实现,使用浏览器来进行配置和浏览。系统的不同功能模块可灵活部署于不同系统和应用之上,功能模块间的通信通过消息中间件来完成。软件采用的系统架构具有与平台无关性,能够稳定运行在国产麒麟系统、Linux或Windows平台之上,便于进行现有资源调度和系统性能调优。为确保自身的高安全性。系统各功能模块间的通信均可采用数据加密和双向认证的方式进行,可防止网络窃听、报文监测等安全入侵。见图2。
5 系统部署
根据系统设计和实现方法开发出来的系统原型主要包括两大部分:第一部分是数据在线处理子系统,主要包括用户管理、采集器管理、网址管理以及系统自身运行维护管理;第二部分是数据分析子系统,主要给用户提供可视化的分析结果,浏览采集到的信息和各类统计图表。
系统将在外网和内网分别部署数据在线处理子系统和数据分析子系统,两个系统之间通过光盘进行单向数据摆渡。可在国产化的硬件平台上使用,如飞腾1500A CPU服务器平台,基础业务数据能够与国产达梦数据库实现兼容移植,同时系统能够运行在国产化的麒麟操作系统上。
整个系统主要由两大模块构成,外网负责实施采集互联网数据,通过主题管理和数据源管理对所采集数据源头进行控制,外网会部署数据存储集群,将清洗过后的数据存入其中。内外网将会使用单向的光盘进行数据的摆渡,将分析的基础数据传至内网,进行进一步深加工。内网环境将会部署多种语义分析服务,同时,内网也会提供对海量数据存储资源的管理系统。最后,数据分析应用部分,也将部署在内网环境中,用于展示数据分析结果。
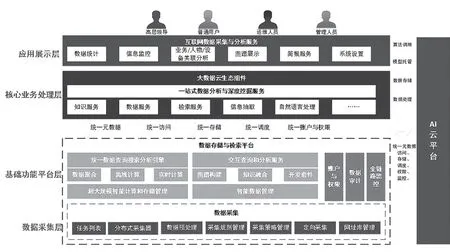
图2 系统总体架构设计图
6 结语
本系统利用网络爬虫等技术从繁杂的内容中筛选出与确定主题相关的舆情信息,然后对源数据进行清洗和净化获得特征词,以自然语言分析自动形成文摘、自动追踪主题的转换、察觉主体间的关系等。对此,高校网络舆情监测系统可以成为高校处理网络舆情问题的重要“利器”,助力高校尽早发现,提前行动,及时解决,防控疏导,有效降低负面舆情信息传播规模,最大限度降低负面影响。
