基于WOA-ELM算法的矿井突水水源快速判别模型
2021-04-11董东林陈昱吟倪林根覃华清韦仙宇
董东林,陈昱吟,倪林根,李 源,覃华清,韦仙宇
(中国矿业大学(北京) 地球科学与测绘工程学院,北京 100083)
为快速分析水害事故产生的原因,众多学者通过构建高效精准的水源判别模型来指导矿井安全生产。目前水源判别方法有很多,如水温水位法、水化学分析法、数理分析法、神经网络法、可拓识别法、GIS理论法、支持向量机法等[1-11]。然而,这些方法都有其自身的优势与局限。胡伟伟等[12]运用同位素法准确地判定了抚顺老虎台矿区的突水来源,该方法具有判别速度快、结果可靠的优点,但此方法成本较高,需考虑现实因素[13-14]。张好等[15]将PCA与Logistic模型相结合,在水源识别上取得了很好的效果,但Logistic模型具有分类精度不高、易产生过拟合等缺点,主要适用于线性拟合,难以适应绝大多数线性不可分的复杂庞大数据[16]。人工神经网络具有较强的自组织、自学习能力和较强的容错性,评价结果更客观,但是对训练样本要求高,训练样本的合适与否会严重影响到最终的评判结果[17-18]。灰色关联分析法计算简单、易于理解,能客观地找到各因素之间的密切程度,降低人为干扰因素[19],但在确定各含水层离子标准时需要大量的数据来进行模糊聚类分析,所得标准只适用于聚类分析样本采集地区[20]。对于可拓识别法[21-24],冯琳等[25]发现对一些在各含水层分布差异较小的数据来说,使用该方法易造成误判。因此,我们需从数据的特征、模型的精度与泛化能力、过度拟合现象、人为影响程度、经济条件等方面入手,以找到解决问题的最佳方法。笔者针对赵各庄矿突水水源,综合考虑各方面因素,选择鲸鱼算法对极限学习机的参数进行优化,旨在准确、快速地对矿井突水水源进行判别分类。
1 矿区概况
开滦赵各庄矿兴建于1909年,位于河北省唐山市古冶区内,具有典型的华北型石炭—二叠纪煤田特征。赵各庄矿井田的地质条件极为复杂,自寒武系至第四纪,发育有五大含水层系。经过调查发现,赵各庄矿的各种突水事故中,奥陶系含水层发生突水的频率最大。1992年7月,开滦矿务局统一矿区奥陶纪碳酸盐岩含水层及其以上含水层,将其定为7组,绘制出含、隔水层示意图(图1)[26-29]。其中,含水层IV和V均可再细分为A,B两个含水层段。根据布罗茨基水化学分类法:第四纪冲积层孔隙水的水化学类型以HCO3-Na·K型为主;煤系地层砂岩裂隙水的水化学类型以HCO3-Na型为主;奥灰水的水化学类型以HCO3-Ca·Mg型为主。

图1 含、隔水层垂向示意Fig.1 Vertical diagram of aquifer and waterproof layer
图1中编号为I,VI及VII的含水层为矿井间接充水含水层,主要特征如下:


图1中编号为II,III,IV及V的含水层为矿井直接充水含水层,主要特征如下:
(1)14煤层~唐山灰岩砂岩裂隙承压含水层II。以粉砂岩为主,夹有泥岩、泥灰岩、灰岩,裂隙较发育。唐山石灰岩一般厚2.5 m左右,在井下钻探和开拓工程中揭露时,涌水量很小。
(2)12~14煤层砂岩裂隙承压含水层III。以中、粉砂岩为主,岩性致密坚硬,裂隙较发育,含水性不均匀。14煤层顶板为青灰色中砂岩,发育稳定,含水性相对较强。12煤层底板以灰色粉砂岩为主,含少量裂隙水,在裂隙发育或破碎带较常见出水,但涌水量不大。
(3)5~12煤层砂岩裂隙承压含水层IV。该层划分为2个含水层段(IVA,IVB),其中IVB段以中粉砂岩为主,含水性较强,在巷道揭露过程中均有不同程度的淋水现象。当煤层开采后,顶板垮落产生裂隙,导致大淋水或涌水,对7煤层的开采影响较大。IVA段以中、粗砂岩为主,岩性致密坚硬,裂隙较发育,含水性不均匀。
(4)5煤层顶板砂岩裂隙承压含水层V。该层划分为2个含水层段(VA,VB),以中、粉砂岩为主,夹粗砂岩,坚硬,裂隙发育,其含水性不仅和岩性有关,同时也受补给条件和构造断裂的控制,属含水性较强含水层。该层为煤层直接顶板,当5煤层开采后,顶板垮落,会有较大涌水出现。

图2 ELM训练模型Fig.2 ELM training model
2 WOA-ELM模型的基本原理
2.1 极限学习机的基本原理
极限学习机(Extreme Learning Machine,ELM)由黄广斌等[30]提出。该算法包括输入层、隐含层、输出层(图2),通过随机产生权值和阈值,然后利用最小二乘法解方程组得到输出权值。ELM不依赖于梯度下降,学习速度比BP(Back-Propagation)算法等传统前馈网络快,对于大量及非线性样本也具有很好的适用性[31-32]。
设模型的输入层神经元个数为n,隐含层神经元个数为L,输出层神经元个数为m。给定N个不同的训练样本xj,j=1,…,N,通过激活函数g(ai,bi,xj)可以将样本映射到另一个特征空间。对于通过映射得到的矩阵H有如下表达式:
Hβ=T
(1)

(2)
式中,H为神经网络的隐含层输出矩阵;T为网络的输出矩阵;β为隐含层节点与输出层节点的连接权值矩阵;ai为由输入层第1~n个节点与隐含层第i个节点的连接权值构成的矩阵,i=1,…,L,表示第i个隐含层神经元;bi为第i个隐含层节点的阈值。

(3)
式中,H+是H的Moore-Penrose广义逆矩阵。
2.2 鲸鱼优化算法的基本原理
2.2.1包围捕食阶段(Encircling prey)
该算法是根据座头鲸捕食行为建立的数学模型。由于猎物位置不确定,WOA算法首先假设当前的最佳候选解是目标猎物位置或最靠近猎物的位置,然后会不断更新其位置[33]。这种行为用下列方程表示:
D=|CX*(t)-X(t)|
(4)
X(t+1)=X*(t)-AD
(5)
其中,D为包围步长;X(t+1)为下一次迭代后解的位置向量;X*(t)为当前的最优解的位置向量;X(t)为当前解的位置向量;t为当前迭代次数;A和C为随机系数向量;每次迭代过程中有更优解出现时就需要更新X*(t)。
A和C由如下公式得出:

(6)
C=2r
(7)
其中,a为控制参数,在迭代过程中从2线性地下降至0;tmax为最大迭代次数,本例中取值为300;r为[0,1]的随机向量。
2.2.2气幕袭击阶段(Bubble-net attacking method)
(1)收缩包围机制。新的个体位置可以定义在目前的鲸鱼个体和最佳鲸鱼个体间的任何一个位置[34],参见式(5)。
按照屋顶形式,平顺县东部民居可分为平屋顶、坡屋顶两种类型(图6)。平屋顶主要指土平房,房顶有梁、檩,上覆白矸土和石板,屋檐一般用石板作悬挑以保护前墙、山墙免受雨水侵蚀。小型附属性建筑多采用单坡顶,双坡屋顶又可细分为悬山、硬山两种。山区石板屋面为达到防水效果,一般会在屋脊处叠放多层较小的石片,有些民居屋脊两端甚至会叠出戗脊的效果(图7)。
(2)螺旋式更新位置。计算鲸鱼和猎物之间的距离D′,构建方程:
X(t+1)=D′eblcos(2πl)+X*(t)
(8)
其中,D′=|X*(t)-X(t)|;b为常数,定义了对数螺线的形状,l为[-1,1]的随机数。
本模型以0.5为分界点,通过产生一个0~1的随机概率p来决定鲸鱼捕食方式。当|A|<1,概率p<0.5时,选择收缩包围机制;当|A|<1,概率p>0.5时,选择螺旋运动更新位置。
2.2.3猎物搜索阶段(Searching prey)
当|A|>1时进入随机搜索阶段,随机地选择鲸鱼来更新位置,而不是根据已知的最优的鲸鱼个体。当达到最大迭代次数以后算法即终止[35-36]。随机搜索的数学模型如下:
D=|CXrand-X(t)|
(9)
(10)
式中,Xrand为随机位置向量。A决定了座头鲸是否进入随机搜索状态。
3 WOA-ELM算法应用
3.1 数据选取
根据《赵各庄水文地质类型划分报告》,1959—2016年矿区突水类型以奥灰水害为主(发生次数占比44%),其次是老空水害(占比36%),砂岩水害和地表水害也时有发生。鉴于影响大的含水层水样数量多、影响小的含水层水样数量少的特点进行了训练与测试样本的筛选,选取老空水、奥灰水(来源于I含水层)、13煤层砂岩裂隙水(来源于III含水层)、12煤层砂岩裂隙水(来源于IV含水层的A段),共4种水样类型(67个水样)进行训练与测试,具体水样特征见表1,2。表1中,数字1为老空水,数字2为奥灰水,数字3为13煤层砂岩裂隙水,数字4为12煤层砂岩裂隙水,表2,3中的数字含义同表1。
3.2 模型建立过程
利用WOA优化ELM的流程如下:首先对原始数据进行归一化,然后设置ELM网络的节点个数和待优化参数的个数,初始化鲸鱼数量和种群适应度值,通过鲸鱼算法不停地迭代寻优,最后得到的适应度值最小时对应的个体即为最优解,将此最优参数赋值给ELM网络,对ELM网络进行训练后应用于水源判别中(图3)。
具体可分为以下4个步骤:
(1)数据归一化处理。

表1 赵各庄矿水样(训练集)Table 1 Water sample data of Zhaogezhuang mine (training set)


(11)
式中,x为样本某一特征的输入值;xmin为样本中输入值的最小值;xmax为样本中输入值的最大值;y为归一化后输出的值。
(2)设置模型参数。
① ELM网络参数:根据输入的数据特征,设置ELM模型隐含层的节点个数为6,故待优化参数Z根据下式计算得出:
Z=nL+m
(12)
在本次训练中,n,L,m均为6。
② 鲸鱼优化算法的参数:设置算法的下界、上界[-1,1],最大迭代次数为300,鲸鱼数量为30,并初始化每个鲸鱼的位置。
(3)迭代寻优。
根据训练过程中的误判率计算所有个体的适应度值后选取最优个体,然后根据最低适应度值更新最优个体的位置。在到达设置的迭代次数之前不断地进行寻优,直到达到误判率低于设定值或达到最大迭代次数。

图3 WOA-ELM模型流程Fig.3 Flow chart of WOA-ELM model
(4)水源判别。
将输出的42个最优权值和阈值赋给ELM模型,对待测样本进行判别。
3.3 水源判别结果
利用MATLAB软件,将每次迭代的适应度值绘制成图,对训练样本和测试样本进行回判;同时将上述样本代入传统ELM模型中,绘制同样内容。结果如下。
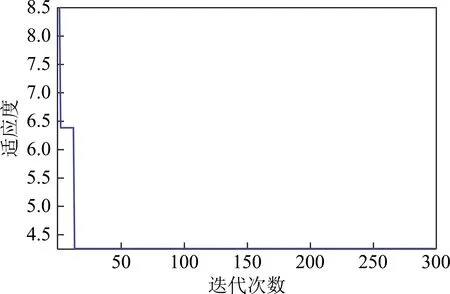
图4 WOA-ELM算法迭代轨迹Fig.4 Iteration trajectory of WOA-ELM algorithm
由图4可以看出在迭代次数不到20次的时候,WOA-ELM模型的适应度就已经降到最低值,之后的迭代适应度函数并没有变化,说明该模型的误判率已经达到最低。对于47个训练样本,由图5(a)和图6(a)可以看出,WOA-ELM模型的判别准确率高达95.74%,仅有2个样本被误判,2个样本均属于煤系地层砂岩裂隙水,含水层裂隙发育,构造条件复杂,需进一步研究水样的混合效应;而传统ELM方法只有85.11%。对于20个测试样本,由图5(b)和图6(b)可以看到,WOA-ELM模型准确率高达95%;而传统模型只有70%,准确率提高了25%,可见用WOA算法优化ELM模型十分成功,不但具有简便易行,迭代次数少的优点,还保证了极高的准确率。但由于采动效应、矿压与构造断裂等作用,12煤层至奥灰含水层间的裂隙发育程度不一,混合水效应为水源的识别带来一定程度上的困难。

图5 训练集与测试集的判别结果(WOA-ELM)Fig.5 Discriminant result of training set and test set

图6 训练集与测试集的判别结果(ELM)Fig.6 Discriminant result of training set and test set
在多次进行MATLAB仿真训练之后发现,由于单一ELM的权值和阈值具有随机性,训练后的网络判别效果并不稳定,而WOA-ELM模型则对权值和阈值进行了优化,在不断迭代过程中找到最优参数,提高了单一ELM模型的稳定性和泛化能力。
4 模型对比
为了进一步的体现WOA-ELM相结合的优势,采用不同方法对水样进行对比判别,并将结果列出(表3)。对于单一ELM、Fisher判别法[37]以及支持向量机(SVM)[38],其水样判别的准确率都低于WOA-ELM模型。

表3 各种水源判别模型结果对比Table 3 Comparison of results of various water source discriminant models
此外,还对ELM模型进行了与PSO[39]和GWO[40]2种优化算法的结合,结果表明WOA-ELM模型的准确率(95%)高于PSO-ELM模型的准确率(85%),但是和GWO-ELM模型相差无几。通过对表3以及3种结合模型的迭代曲线的对比观察发现(图7),尽管GWO和WOA两种优化模型的测试集判别准确率相同都为95%,但是WOA-ELM模型的最低误判率(即适应度的最低值)小于GWO-ELM模型,说明在大量数据情况下,WOA-ELM模型的准确率会更高;对于PSO-ELM模型来说尽管它的适应度曲线更低,但是它的实际判别准确度并不高于WOA-ELM模型,可能是由于过拟合导致的,同时经过多次仿真模拟发现,PSO-ELM模型同样存在不稳定性,多次运行的结果并不完全一致。

图7 不同优化算法迭代曲线Fig.7 Iteration curves of different optimization algorithms
5 结 论
(2)运用鲸鱼优化算法(WOA)对传统极限学习机(ELM)的权值和阈值进行了优化,建立了WOA-ELM水源判别模型,以矿区的不同含水层的水样为样本,以6项常规水化学指标作为识别对象,成功的判别了该矿的突水水源,准确率高达95%。
(3)由于煤系含水层裂隙发育,构造条件复杂,其水样混合造成了识别的难度,需进一步研究水样的混合效应。
