基于改进残差网络的单幅图像超分辨率重建算法研究
2021-04-10蔺国梁
蔺国梁
(兰州文理学院 数字媒体学院,甘肃 兰州 730010)
0 引言
图像是人类传递信息最便捷的载体之一,在医学、智能交通、安全监控、遥感及国防等领域应用广泛.然而在实际中因为环境和成像设备的限制,图像质量仍不理想,不利于信息传递的准确性和完整性.因此,如何提升图像质量成为研究者关注的热点.图像超分辨率(Super Resolution,SR)重建的主要思想是通过计算机软件技术在原有低分辨率(Low Resolution,LR)图像的基础上,产生单帧或多帧边缘和纹理清晰的高质量、高分辨率(High Resolution,HR)图像的过程[1-2].目前图像SR重建方法主要有3种:基于插值的方法、基于重建的方法和基于学习的方法[3-4].基于深度学习的方法近年来受到人们的青睐,其主要思想是利用观测到的LR图像和原始HR图像之间的映射关系及大量的训练样本数据,从中学习得到更多高频细节的HR图像.
2014年Dong等[5]在传统方法的基础上提出一种包含3层卷积的深度学习卷积神经网络(Convolutional Neural Network, CNN)实现图像SR重建,即SRCNN(Super Resolution Convolutional Network)方法,并取得了良好的效果.由于卷积层较少,HR图像预测仅依靠输入LR图像内较小局部区域像素之间相关信息,模型重建精度有限.Wang等[6]在CNN模型中应用稀疏编码表示先验信息,实现重建,提高了重建质量并简化了模型.Kim等[7]提出了一种带有深度反馈信息的网络模型SR方法(VSDR)运用20层的卷积网络来重建HR图像高频信息,利用残差学习加快网络收敛速度,证明了该方法有助于超分辨率重建的性能提升.但是VSDR方法增加了训练和重建的时间复杂度.以上方法在图像分块的过程中,容易破坏图像的整体结构,导致重建结果存在“网格化”效应,丢失图像的高频信息,出现计算复杂、重建效果不理想的问题.
基于以上问题,本文提出一种基于深度残差卷积神经网络的图像超分辨率重建方法.该方法以LR 图像为输入,采用残差卷积神经网络在 LR 空间提取特征,得到残差图像,最后将输入的LR图像与得到的残差图像进行线性相加实现图像超分辨率重建.
1 SRCNN方法
SRCNN方法是深度学习在图像超分辨率重建中的重要方法之一,其网络结构(如图1所示)有3层:特征提取、非线性映射和图像超分辨率重建.
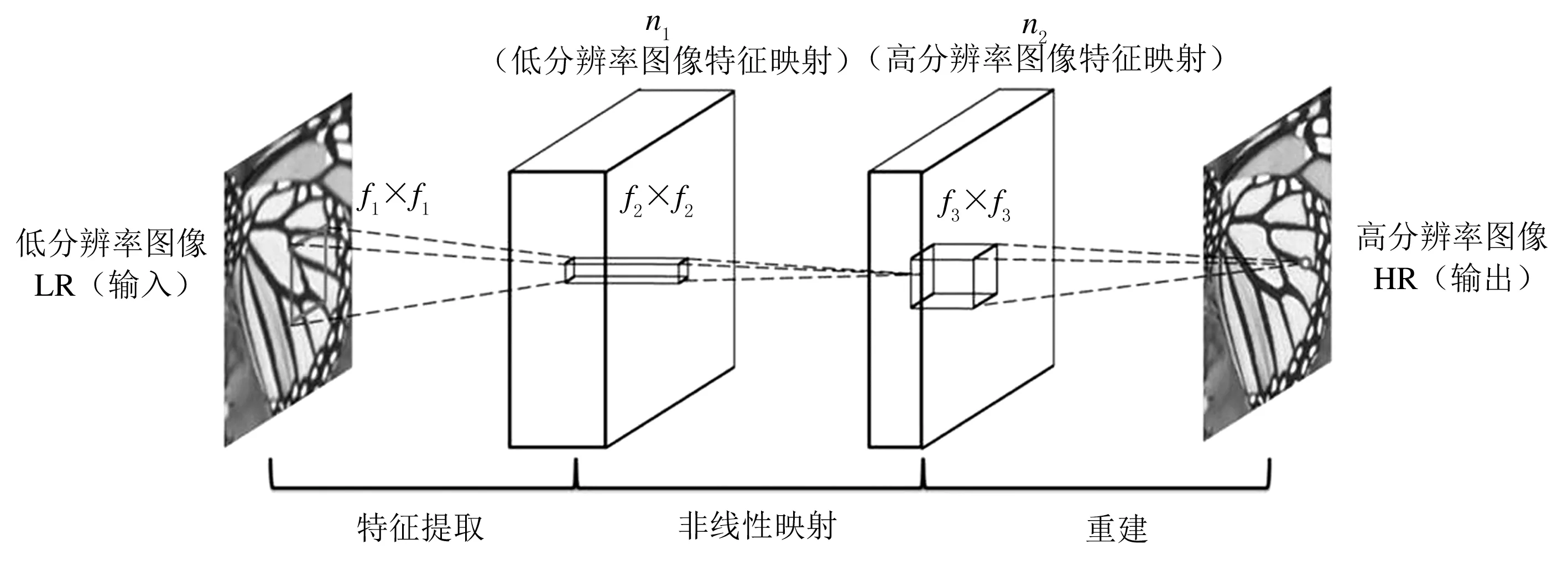
图1 SRCNN 网络框架
该网络的特征提取、非线性映射和图像HR重建3个过程的具体实现过程如公式(1)~(3)所示.
F1(Y)=max(0,W1*Y+B1).
(1)
F2(Y)=max(0,W2*F1(Y)+B2).
(2)
F3(Y)=W3*F2(Y)+B3.
(3)
其中:Fi(·),i=1,2,3表示图像的特征图,Wi,i=1,2,3是卷积核,大小为n×c×f×f,c为通道数,c=1,n1=64,f1=9,n2=32,f2=1,n3=1,f3=5.*表示卷积运算,Bi,i=1,2,3为偏移向量.max(0,x)表示卷积之后的结果经过ReLU激活函数处理,将其值取0和卷积结果的最大值为最终值,用于滤波器响应[8].
2 残差网络(ResNet)
随着CNN网络的发展,He等首次提出残差学习网络框架ResNet.残差结构是在网络中添加一个跳跃从而绕过一些层的连接,包含一个跳跃的几层网络称为一个残差块.如图2(a)中,H(X)为理想映射,F(X)为残差映射,H(X)=F(X)+X.通过将拟合目标函数H(X)转变为拟合残差函数F(X),此时,只需要F(X)=0,就能够构成恒等映射H(X)=X,使得拟合残差更加容易.因此,残差网络只需要学习输入与输出之间的差别,将其与LR图像的原始信息叠加,可以提高HR图像重建质量.由于ResNet中BN(Batch Normalization,BN)层降低了训练速度,会导致网络发散和不稳定,同时BN会破坏图像的原始信息而影响重建图像质量,因此在本文研究中去除BN层,改进后的残差单元如图2(b)所示.
同时,在本文残差网络中采用ELU激活函数[8],相比ReLU,ELU可以取到负值,这让单元激活均值可以更接近0,在输入较小值时具有软饱和的特性,提升了对噪声处理的鲁棒性,同时能减少数据的计算量.ELU激活函数如下:
(4)

(a)ResNet 残差单元结构
3 改进的图像超分辨率重建算法
3.1 本文网络结构
本文网络在SRCNN的基础上提出了一种改进的残差网络卷积神经网络超分辨率图像重建算法.该网络共包含18个卷积层,由5部分组成:低分辨率图像输入、卷积特征提取、4个残差块组成的非线性映射部分(每个残差块由4个残差单元构成)、残差图像特征层和高分辨率图像输出层,整体结构如图3所示.
3.2 图像超分辨率重建过程
(1)输入输出层.提出的网络以原始图像作为输入,输出层与输入层图像大小一致.
(2)特征提取层.输入图像经过Bicubic插值得到低分辨率图像.特征提取由一个卷积层和一个激活函数层组成,将输入的低分辨率图像Y与n1个特征图进行特征提取,提取特征的过程可描述为:
B0=σ(W1*Y+b1).
(5)
其中:*为卷积操作,σ为ELU激励函数,W1为第一个卷积层的卷积核.在特征提取时设置卷积核大小为3×3像素,滤波器数量n1=64.在卷积操作时,对所有卷积层进行“补零”操作,保证每次卷积后图像大小不变.(3)非线性映射层.在图像超分辨率重建中,训练深层卷积神经网络时,为保留不同水平的图像特征,非线性映射过程使用局部残差连接方式,本文在实验中非线性映射过程由4个残差模块组成,每个残差块由4个残差单元组成,对ResNet残差单元进行了改进,改进的残差单元可表示为:
Hm=Gm(Hm-1)=F(Hm-1,Wm)+Hm-1.
(6)
其中:Hm-1和Hm分别为第m个残差单元的输入和输出;F为学习到的残差映射,即
(7)

(4)网络重构.在网络最后一层设置单独的3×3像素的卷积层作为网络输出层,通过前面残差网络输出图像块的特征图,馈送到最后的卷积层,以便产生与输入图像相同数量通道的张量.将得到的残差图像与输入的插值LR图像相加,最终融合成一个完整的HR图像,具体重建过程如图4所示.

(a)低分辨率图像Y (b)残差图像R (C)高分辨率图像Z
4 实验结果与分析
4.1 实验环境与数据集
本实验环境为Windows7操作系统,软件平台为Python3.7,深度学习框架采用Tensorflow1.8版本,图形处理采用OpenCV,硬件配置CPU为Intel(R) Core i5-4580@3.2 GHz,内存为6GB,GPU为4GB的GTX1050.
训练数据集选Timofte发布的数据集DIV2K.本文选用该数据集中的800个训练图像.首先将训练集的高分辨率图像运用双三次差值(Bicubic)算法缩小为原来的1/3,然后再放大,使其变成低分辨率图像,并在训练过程中选取大小为32×32像素,步长为14的23 890张子图像作为网络输入.试集采用set5、set14和BSD100数据集.
4.2 网络评价指标
算法采用Adam梯度优化算法[9],学习率初始化为0.0001,权重衰减参数为0.0005,网络的动量参数为0.9.
为了定量表示重建结果,本文采用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似度(Structural Similarity,SSIM)2个指标作为重建效果的评价标准.PSNR是通过计算图像内像素最大值与加性噪声功率的比值来衡量重建图像是否存在失真问题,其数值越大,则说明重建图像效果越好.PSNR的计算方法如公式(8)所示.
(8)
其中,MSE表示原始图像与处理后图像的均方误差,MAXI表示图像颜色的最大值,采样图像的像素范围为0255.MSE的计算公式如下:
(9)
SSIM是衡量原始图像与处理图像之间的结构度、亮度和对比度的相似性,其值与1进行比较,越接近于1,表示输出图像质量越好,其计算公式如下:
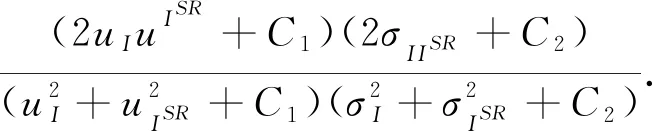
(10)
其中,uI和uISR表示低分辨率输入图像I和重建图像ISR的均值;σI和σISR表示I和ISR的方差;σIISR表示I和ISR的协方差;C1和C2表示防止分母趋于0的常数;通常SSSIM∈(-1,0].
4.3 实验分析
为了验证本文算法的有效性,将其分别与Bicubic算法、SRCNN算法和FSRCNN算法进行定性和定量比较.在set5数据集上图像尺寸放大2倍、3倍和4倍后,图像SR重建的定量比较结果如表1所列.在set14数据集上图像放大3倍后图像SR重建的定量比较结果如表2所列.通过PSNR和SSIM总结了几种方法对超分辨率的重建效果.
从表1中可以看出,本文算法相较于Bicubic、SRCNN和FSRCNN算法在PSNR值上扩大因子为2时,均值分别提升了0.432、0.778和0.63dB;扩大因子为3时提升了0.062、0.566、0.818dB,扩大因子为4时提升了0.32、0.6和0.772dB.在扩大因子为2时,SSIM均值提升了0.0112、0.0288和0.0324,扩大因子为3时提升了0.0100、0.02718和0.0213,扩大因子为4时提升了0.01214、0.01868和0.03834.
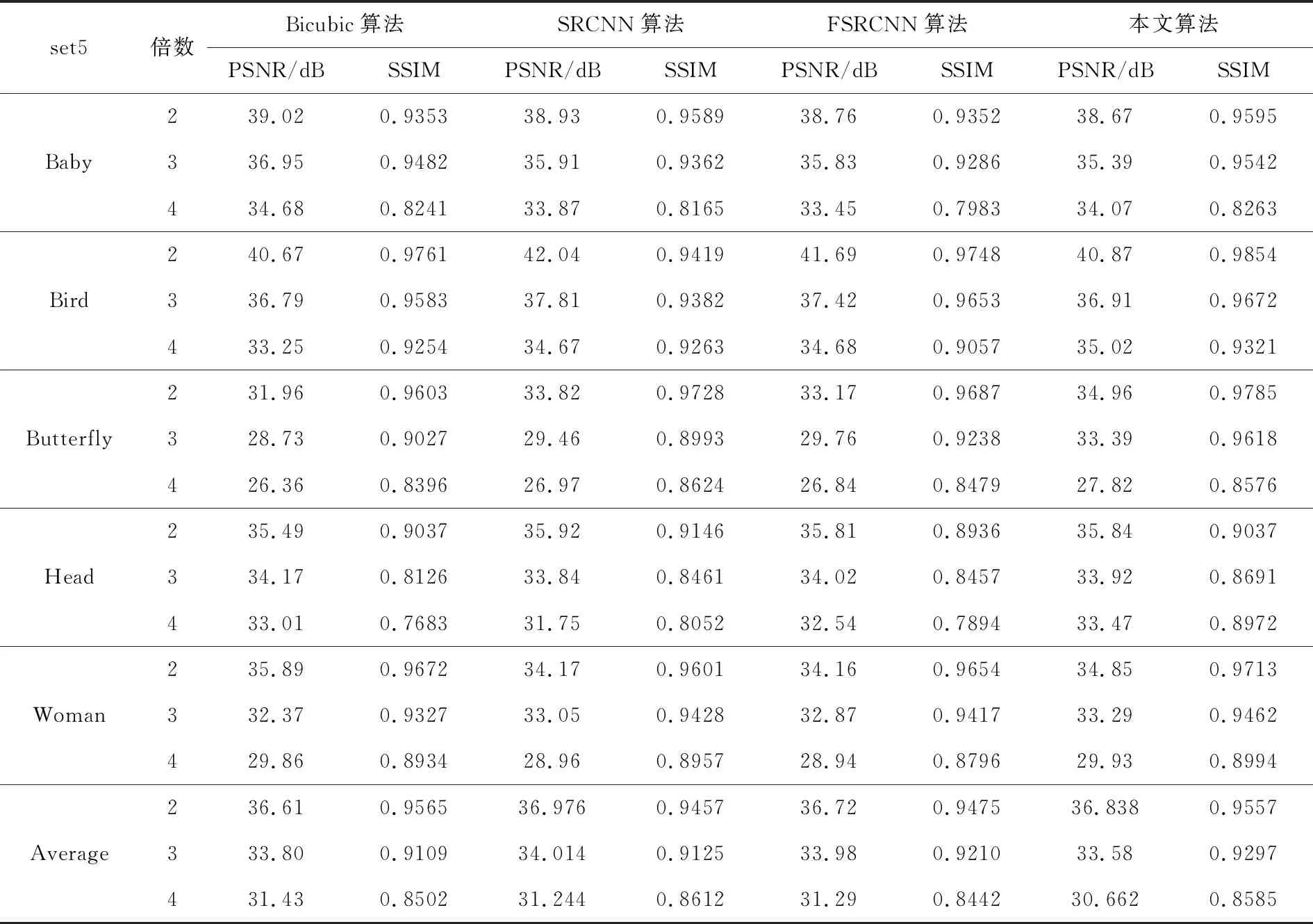
表1 不同方法在set5数据集上的PSNR和SSIM结果(放大倍数=2,3,4)
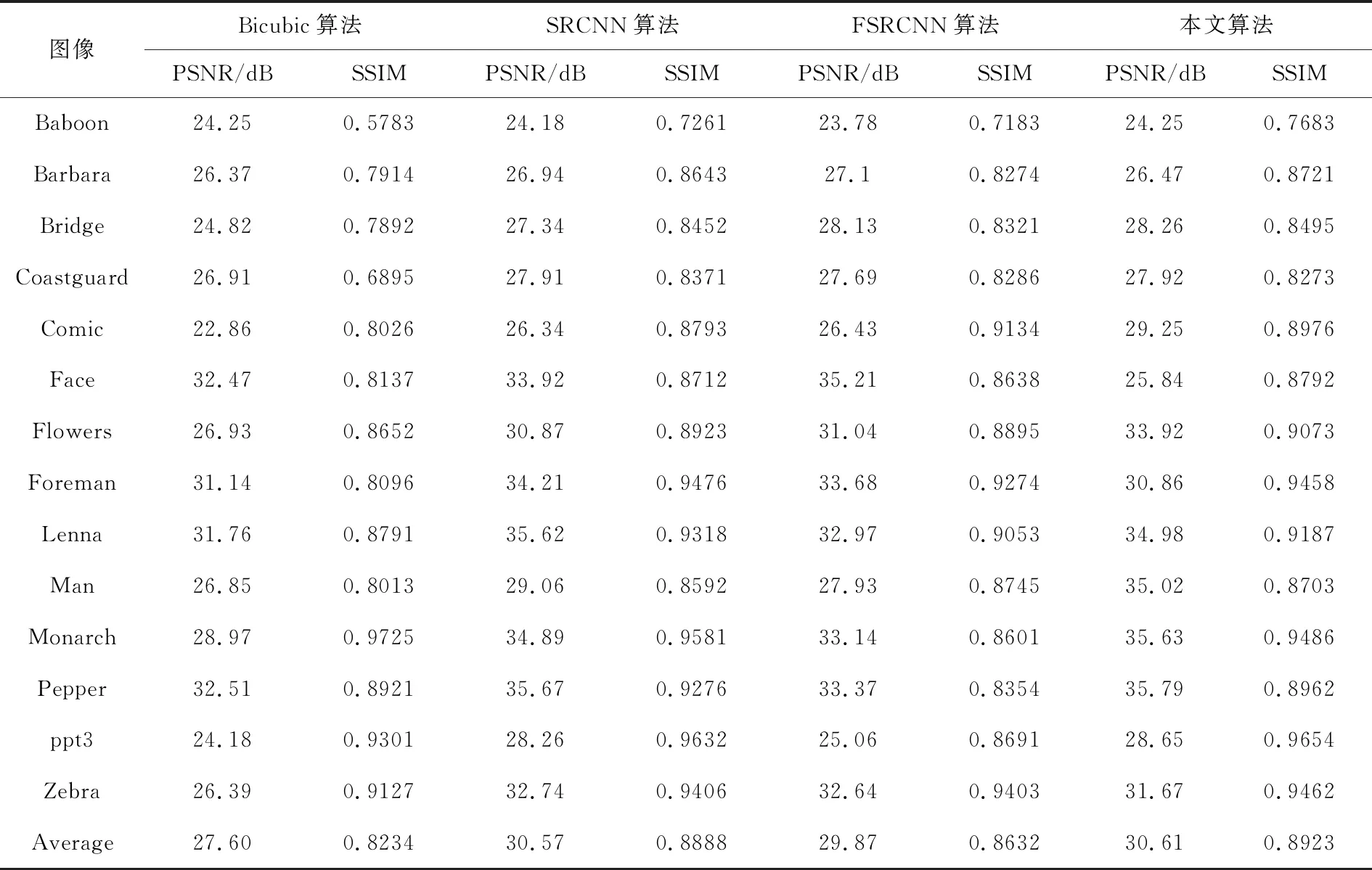
表2 不同算法在set14数据集上的PSNR/SSIM的对比
由表2的定量数值分析可以看出,本文算法的PSNR平均值比Bicubic算法、SRCNN算法和FSRCNN算法的PSNR平均值分别提高3.01、0.04和0.74,SSIM的平均值分别提高0.0689、0.0035和0.0291.实验结果较好地验证了本文算法的有效性,在一定程度上增强了重建图像的纹理信息和清晰度.
图5~7分别为在set14种的Baboon、Face和Pepper进行3倍尺寸放大后不同算法的视觉效果比较,比较结果如图5~7所示.
从图5~7可以看出本文算法重建出的图像较为清晰,细节更为丰富,并对噪声有一定的抑制作用.

(a)原图 (b)BIcubic (c)SRCNN (d)本文方法

(a)原图 (b)Bcubic (c)SRCNN (d)本文方法

(a)原图 (b)Bicubic (c)SRCNN (d)本文方法
5 结束语
本文提出了一种改进残差网络的单幅图像超分辨率重建算法.该网络包含18个卷积层,改进了ResNet的残差单元,移除BN层,有效抑制了图像空间信息的破坏.采用ELU激活函数,具有修正数据分布以及加速收敛的优点,同时又不完全丢失特征.改进后的残差网络较好地抑制了网络退化问题,并大大提高了收敛速度.实验结果表明本算法在重建效果和客观指标上均优于其他3种方法,不仅获得图像更多的纹理信息和边缘细节,而且重建效果真实.
