基于移动轨迹融合的旅游阅读推荐服务*
2021-04-09张佳琳
张佳琳
0 引言
旅行是心灵的阅读,而阅读是心灵的旅行。近年旅游景区景点纷纷开设免费的游客书吧,提供旅游阅读服务。从实际应用看,由于现场旅游阅读服务受到场地设置、图书/信息资源、服务人员与时间的限制,受众面有限,游客使用率与满意度不高;另一方面,移动旅游阅读随着移动互联网高速发展,为游客在旅游过程中进行“随时随地随心随意”阅读提供便利。2019年《中国旅游发展报告》显示,77.4%游客经常通过移动互联网在旅游过程中进行阅读;而移动互联网中的相关阅读资源数量巨大,游客难以有效的处理与使用,仅21.5%游客对移动互联网中的阅读服务表示满意,因此旅游阅读的精准化和个性化已成为旅游信息服务的必然要求。依托移动互联网中丰富的游客信息与旅游场景,推荐“适合、需要、实用”的阅读资源成为图书与旅游学界的研究热点[1]。
基于上述需求,研究人员为提供精准的阅读资源开展一系列游客-读者画像和旅游信息场景探索工作,重点研究基于游客端多源数据融合的游客行为感知、游客需求理解以及阅读-旅游匹配计算等方面的内容,主要思路与方法是运用信息情报采集技术,通过旅游环境中的通信服务器尽可能地采集游客数据,绘制游客画像,并通过该画像完成一定的旅游阅读服务或管理操作,如推荐服务、征信管理,而处理特定场景的服务器往往独立完成上述任务,缺少与其他服务器的信息互动与协作[2]。周亚等基于游记进行了游客画像绘制工作,发现孤立的信息服务器难以发现游客的阅读需求规律与潜在兴趣[3]。张佳琳设计一个非中心结构的游客数据服务发现系统,证明同一游客所处的不同情绪以及情景间存在一定的联系,为阅读推荐提供了需求依据[4]。Larbi Kzaz等[5]、Guneshwari Nemad 等[6]研 究 同 一 归 属“旅游-阅读”场景的局部信息融合模式与算法,其成果证明了即使是有限的场景序列融合,也能够为游客画像提供更为深入的信息。Robert P等[7]、Jitha P B等[8]通过研究局部场景序列的关键子序列搜索算法证明:孤立的场景系统是移动互联网信息孤岛的根源所在,必须研究“旅游-阅读”场景间信息交互的机制与协议。Mehrbakhsh Nilash等[9]通过局部场景融合,发掘了游客轨迹以及阅读场景中若干强相关场景的共有特征,并以此为依据,预测了游客的部分阅读需求发展;证明全景画像模型必须突破碎片式场景管理的禁锢,才能获得更为精准和全面的阅读需求信 息。Priyanka B Tiwar 等[10]、Yohei Kurata等[11]指出场景融合的应用前景广阔,如不同归属的场景进行融合可以预测游客的下一阅读场景,从而进行阅读等多方面的推荐。Thuy Ngoc Nguyen等[12]研究基于中心服务器模式,局部实现社交网络物理定位,为阅读环境建模提供了基础信息。Huang Yu等[13]构建中心服务式的游客画像管理系统,通过旅游场景与游客信息需求匹配来进行精准阅读推广。Annika Hinze等[14]通过移动互联网信息传播建模发现:一方面中心服务器已成为移动场景信息处理与阅读信息传导的性能瓶颈;另一方面移动游客端的存储与计算资源闲置比例很高。Daniel Herzog等[15]尝试采用智能终端代替中心服务器执行部分画像信息管理任务的解决方案,证明了游客画像信息处理迁移至游客端的可行性,同时发现可以由游客端承载孤立场景信息,实现场景间信息传导。上述研究受到当前移动网络游客画像模型及相关旅游阅读方法的禁锢,存在以下问题:(1)孤立的情景或场景难以完整描绘游客感知到的全景,且当前的移动互联网服务器领域尚缺少中心信息融合平台,难以实践上述旅游阅读推荐算法与模型;(2)游客画像与旅游阅读场景呈现单向信息流动,游客画像难于向场景进行反馈,旅游阅读场景难于实现自我刻画与表述;(3)旅游阅读场景间缺少信息互动桥梁,孤立的场景难以随周边环境同步更新。基于上述问题,本研究提出基于移动轨迹融合的旅游阅读推荐服务模型TRMTF(Travel Reading information recommendation model based on Mobile Trajectory Fusion)模型,利用游客智能终端生成旅游阅读场景信息(面板类数据),并将这些场景信息作为游客画像与游客轨迹节点的刻画依据,最终通过移动轨迹(场景)融入等算法在公共图书馆等部门的服务器端生成旅游信息空间,为游客提供阅读推荐服务,从而使“全民阅读”服务全面融入旅游领域。
1 旅游阅读推荐模型结构与流程
1.1 移动轨迹节点模型设计
本研究在前期成果[4]中构建了较完整的旅游场景与游客画像信息模型,但在实际应用中发现:孤立的场景信息难以为旅游阅读推荐提供充分与准确的支撑数据;因此本研究将这两种信息进一步融入全景轨迹节点模型,并将其作为阅读推荐工作的数据基础。轨迹节点(带有时间、用户特征等标签的场景)是包含有关游客授权管理的所有自身相关信息以及管理操作的高级信息对象。每一个全景轨迹节点最终将在用户终端中以信息对象形式存在,并可以在多个终端间进行信息同步和无缝迁移。基于前期研究的经验与成果,全景轨迹节点模型将采用树型分层结构;每个模型包括如下内容:第一是全景轨迹节点/从属对象标识,即用户在移动互联网中的唯一轨迹标识,而所有全景轨迹节点在该标识之下构成一棵信息树,连接树根节点到节点路径上,所有从属对象节点的标识构成全景画像模型中某个信息描述对象的标识。第二是处理画像的语法,即画像模型描述、解释或执行这些对象的代码以及规范,主要包含对象类型、对象获取方式、对象状态以及对象标识。第三是采取基本编码法生成的对象编码。基于上述总体设计方案,结合前期成果,进行画像模型的详细设计与构建,目前设计的全景轨迹节点中,从属对象的属性部分表述为:<对象类型与标识,信息类型,获取方式,对象状态>四元组。在语法项目中增加了自解释操作部分,可以表述为:<对象类型与标识,解释代码,更新代码>。两部分相辅相成,通过解释代码对属性部分信息进行自适应解释,并分离和提取用户特征与兴趣信息,能够满足目前主流移动互联网用户管理与服务系统的需要。该原型还具有一定的自收敛性,在扩展时不会占用过多存储空间,适合移动环境的终端应用。为保证该模型的通用性,本研究遵照国际旅游信息协会建议稿设计了全景画像模型中的从属对象,共分为4类12个明细组:(1)场景类,包含个体场景、自然场景、社交场景、兴趣场景与行为场景5个明细组;(2)系统类,包含系统、接口2个明细组;(3)信息交换类,包括地址转换、信息交互2个明细组;(4)管理类,包括本地管理、迁移、更新3个明细组。在完成上述对象与操作的详细设计与代码实施后,通过前期工作中构建的仿真实验系统与移动互联网用户数据集,对全景轨迹节点模型进行验证,重点考查用户信息覆盖度、完整性、统一性、全面性与适用性,详见图1。
1.2 旅游阅读推荐流程
基于移动轨迹的旅游阅读资源推荐流程见图2。
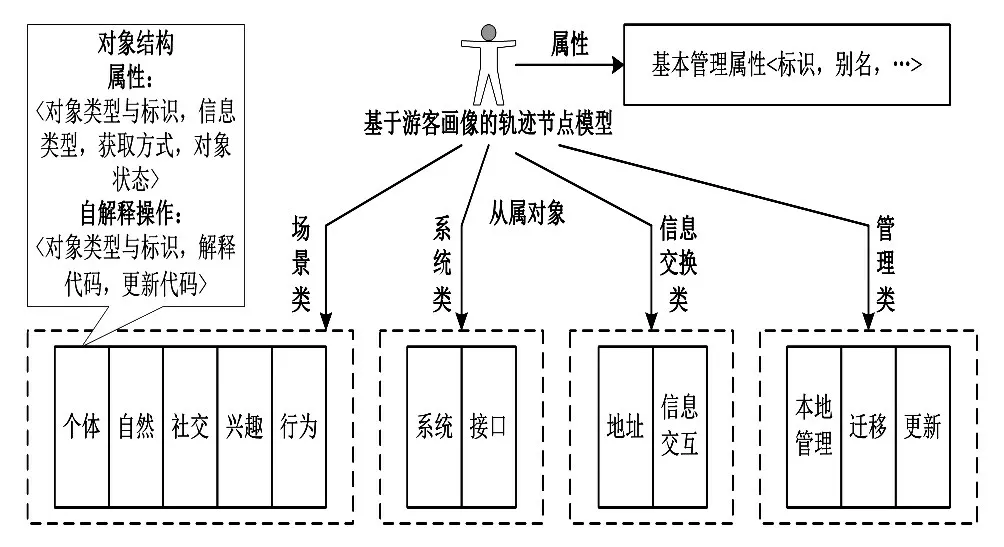
图1 轨迹节点模型与数据结构图
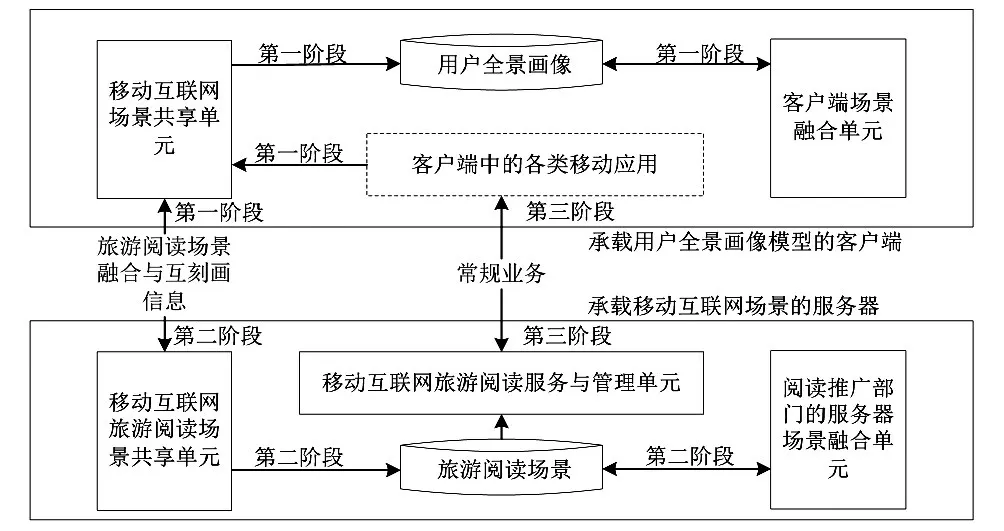
图2 模型结构与推荐流程图
定义U(Unit)是某一场景内(通常是某一地区或景点的阅读服务机构,如公共图书馆)服务器辖域内游客画像的群体状态集。定义W(will)为游客的意愿集合。客户端内的场景信息定义为:
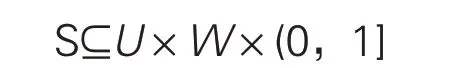
其中的局部视图(s,p)∈S,由此可以对某个游客全景画像中的5个场景明细组进行信息包络操作。在游客全景画像应用过程中,其局部场景视图s可以结合所在场景的阅读意愿集合,通过画像内部5个场景明细组的状态变迁,并通过添加时间戳形成客户端中的轨道节点信息,从而一方面对当前服务器中的旅游阅读场景进行刻画,一方面记录游客的旅游及相关行为变迁。从前期成果[4]来看,该方案的简化版能较为准确地刻画游客与旅游阅读场景的特征,而且结构简单高效,如进一步进行性能升级与功能扩展,后续阅读推荐算法处理应更为快速有效,在不过分占用客户端资源的情况下,实现较为精准和全面的移动轨迹模型管理与旅游阅读资源推荐应用。
第一阶段是个体游客轨迹节点更新与管理。在该阶段中,客户端根据游客所在场景,生成其个体的、微观的游客场景视图,并从中抽取个体场景、自然场景、社交场景、兴趣场景与行为场景明细组所需汇总信息,记录在个体游客的全景(阅读需求)场景模型中,待游客画像发生迁移后,再对上述场景信息进行融合成轨道节点,一方面存储在游客画像中。以经典旅游阅读场景为例,此时全景画像能够提供用户的景区类型喜好、景色偏好等信息,从而为推荐服务提供其阅读需求。另一方面客户端将记录游客经历过的景区明细场景,为后续相关轨道刻画生成奠定了阅读推荐基础,并在一定程度上解决了旅游阅读场景与轨道信息共享的问题。
第二阶段是轨道的融合与更新。该阶段中,一旦轨道节点携带者进入下一个信息场景,此时旅游阅读推荐服务器将根据其提供的轨道节点信息,生成一个局部的轨道融合视图;无论游客是否产生相关操作,其轨道的特征与游客阅读需求信息,及其场景明细组数据,都将传递给服务器,一方面对游客轨道进行持续深入、多维度的刻画;另一方面将游客轨道中包含的其他轨道节点信息传递给当前旅游阅读场景,从而丰富与细化其中的信息。
第三阶段是游客轨道信息的阅读推荐应用。在该阶段中,旅游阅读推荐服务器从客户端中获取所需的轨道信息,并将其与存储在服务器中的阅读场景特征(可以是公共图书馆的电子图书信息、特色景点的典故信息等)进行匹配,以匹配结果为依据提供个性化旅游阅读推荐服务,如电子图书推荐、景点典故提醒、游记精准应答;也可提供这些信息给阅读推广部门而实现精准读者管理,如游客需求聚类、旅游景区特征提取。
2 主要算法
2.1 移动轨迹信息融合算法
作为旅游阅读推荐服务的基础工作,游客移动轨迹信息融合的难点在于:移动互联网中阅读推荐服务器的场景特征信息如何融合生成游客的阅读需求与偏好特征信息,而游客的阅读需求与偏好特征信息又如何反馈优化旅游阅读场景的特征信息。因此,本模型采用的算法将众多游客画像中蕴含的局部场景视图(即独立游客视角下的局部阅读场景视图),结合自身的画像特征,以迭代融合的方式,一方面为阅读推荐服务器提供场景信息更新的依据;另一方面汲取旅游阅读场景信息,最终融合生成精细化的自身画像。详细的算法分为轨迹(场景)融入(画像)与画像融入(场景)两个子算法。
(1)轨迹融入子算法,其实现描述如下:
Step1:根据游客特征,对其需要融入的轨迹(场景面板数据)进行融入前的预处理,公式为:
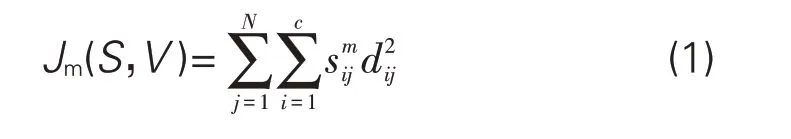
其中,(1)式里的S 为游客画像中的特征信息;而V是轨迹节点(场景)集合{v1,v2,…,vc},其中的vi是游客画像特征wi集合中的中心矢量,其中的权重值m∈(1,∞),而A是一个正定矩阵,当A=I时,可以定义dij为场景与期望的欧式距离,可得:
Step2:进一步对轨迹预处理后的游客画像进行调整,建立以(2)式为约束的融入方法,而(2)式中的u为正数。基于此,待融入轨迹(场景)的无约束调节函数为:
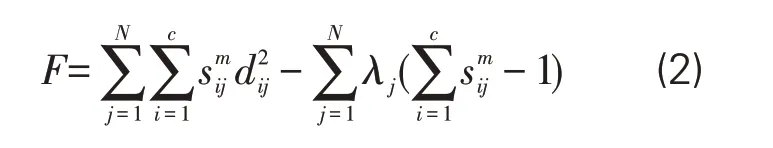
对公式(2)进行极值化处理,要求:
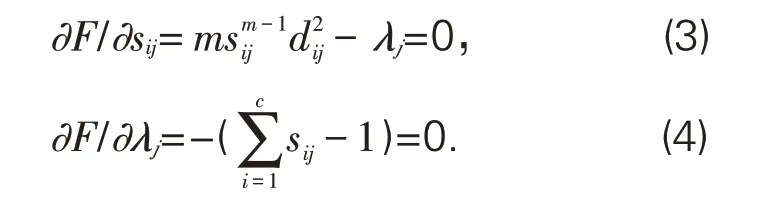
由(3)式得到:

此时(5)式代入(4)式,可得:
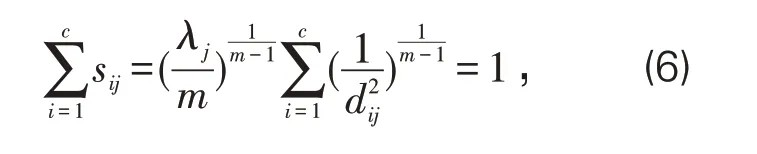
进一步可得:
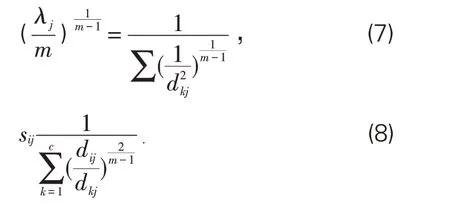
Step3:实际处理过程中发现,存在dij=0的情形,所以进一步对∀j定义与Ij与
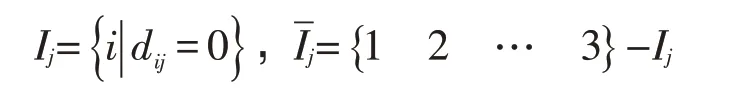
此时,如果Ij=Φ,则可得:

但若:Ij≠Φ,则∀i∈Ij,将定义有:sij=0,切而∂J(S,V)/∂vi=0,设定:
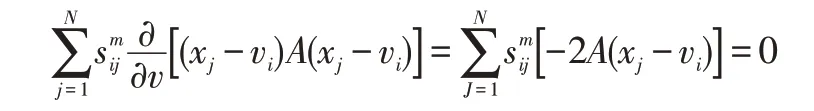
基于此,可得:

此时游客画像特征通过轨迹信息的融入得到更新,从而使画像更为清晰与精准。
(2)画像融入(轨迹)子算法,该步骤将通过画像信息的融入,使得轨迹(场景)最自身的刻画更为精准,实现轨迹融合的双向优化,其实现描述如下:
Step1:画像融入的初始化,该步骤将在更新信息超限(旅游阅读推荐服务器采集的画像信息超过20%)时进行,将通过配置程序设定自动计数器c(2≤c≤N)、轨迹标识counter,初始化轨迹矩阵A以及误差阈值ε>0。
Step2:虚拟化(内存导入)轨迹融入子算法中定义的:游客画像特征信息S(0),这一序列中包含了先后到达的游客画像,而uij是画像信息S里的元素;处理计数器初始化,可得:counter=0。
Step3:对S(counter)中的进行画像融入(场景):
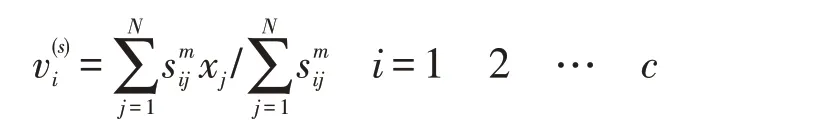
Step4:对后续的游客进行进一步融入,处理S(counter)之后,虚拟S(counter+1)(j=1-N);并引入Ij和此时,将通过临时寄存器xj实现下一步融合,即:Ij=Φ。如公式(9)所述,将否则,可得:
Step5:通过范数判定法对更新后的S(counter)与S(counter+1)进行对比;如果说明二者对轨迹的反馈强度已经非常小了,则退出融入;否则计数加1,从Step2继续迭代。
2.2 旅游信息推荐算法
为将旅游阅读信息资源推荐给匹配度较高的游客,本研究设计了游客侧驱动的阅读推荐算法。该算法以动态的游客画像为基础,主动获取游客的阅读需求画像,通过轨迹融合生成的阅读需求特征,从旅游信息资源空间中发现获得精准信息供给的总体方向,并通过逐步求精,和伙伴信息修正的方式,定位和获取所需的旅游信息。下文阐述旅游信息资源的优阅读推荐算法。
Step1:首先根据游客阅读需求与画像特征,对其在旅游信息资源空间中的初始位置进行伪随机化设置,可得:

Step2:根据游客既往的阅读需求强度、旅游阅读需求差异度、旅游区域特征等画像信息,生成其搜索旅游信息资源空间的大致方向以及步长等参数。
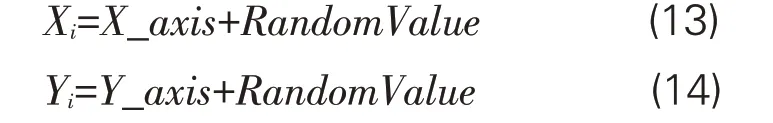
Step3:根据前两个步骤中设定的方位与步长等参数,生成游客阅读需求与旅游信息资源集合中点距离(Dist)值,进一步生成游客在当前旅游信息集合的信息资源密度获取概率(S)。
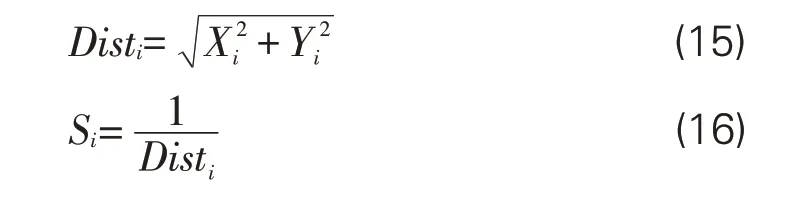
Step4:将游客的信息获取概率(Si)通过需求-信息匹配函数,生成该游客在所在空间(当前所在位置)的感觉值(Smelli)。
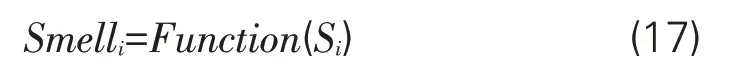
Step5:通过迭代,对查找当前旅游信息资源集合中感觉值最佳的游客。
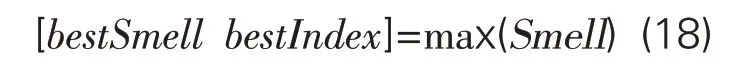
Step6:保存需求-信息匹配最佳值,及x、y位置,并将游客群体的阅读需求等信息与其进行拟合。
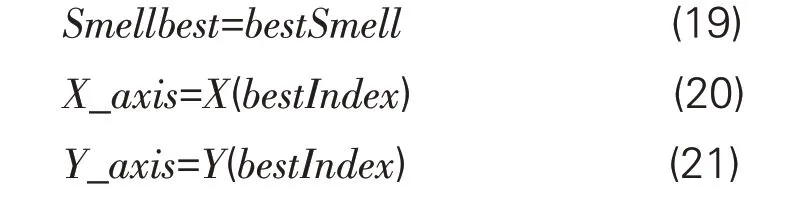
Step7:进一步进行迭优化,即再一次进行Step2~5,并判断游客的感觉值是否得到了提升;如果是,进入Step6执行,反之进入下一步。
Step8:当无法继续提升游客感觉值时,说明游客在这一旅游信息资源空间中搜索已经逼近其阅读需求度最高的信息,此时可以抽取其步长范围之内的信息资源,通过旅游阅读推荐服务器发布给该游客或相关游客团体。
需要说明的是:由于旅游的群体形式多样,本研究的初衷是尽可能地将阅读推荐服务覆盖到所有的形式,同时为了节省系统的开销,在实际项目中的设计是包含了对画像自相似团体(如家庭团体、自由组合团体、拼团)的阅读推荐,这样对团体内成员仅需进行一个旅游读者画像和相关场景的处理即可,能够节省服务器开销。
3 实验结果分析
3.1 性能实验结果
TRMTF模型的实际效能在后续的实验中得到检验。实验数据来自于中国计算机学会CCF提供的游客轨迹数据集,该数据集共包括2,107名游客在35 个旅游场景中的活动轨迹信息共计38万余条。限于实验人员人数(共54人)及处理服务器(联想SR550)的实际容量,本研究从中随机抽取200名游客及其旅游轨迹涉及的12个旅游场景涉及的4.7万条信息进行对比实验。实验中的阅读信息资源由哈尔滨商业大学图书馆提供,包含与12个旅游场景相关的232册电子图书,和1,802项旅游阅读材料(其选择依据为:与上述12个场景中的内容相关,能够被poi解析工具析出其中文本,方便阅读推荐模型检索并推荐)。实验人员为50名哈尔滨商业大学电子商务专业本科生,由每名学生操控8名虚拟游客的虚拟旅游活动,并根据虚拟游客的个体属性特征模拟其旅游活动。
虚拟游客共分为2组,A实验组所在虚拟场景采用TRMTF旅游推荐模型与算法,B实验组所在虚拟场景采用美国北卡罗来纳大学研制的移动旅游信息推荐模型MTRM(Mobile Tourism information Recommendaiton Model)与相同的游客进行实验[8],其中MTRM模型基于分布式游客信息交换机制,游客通过朋友圈进行信息交互,并主动过滤Facebook等社交媒体推送的信息。根据前人实验[5,7],本研究选取游客画像标签数、场景(轨迹节点)标签数等面板化指标,以及游客(阅读)覆盖度、阅读推荐准确度两项序列化性能指标来衡量两种模型的效能。
如表1所示,TRMTF模型的最终面板性能指标(各游客与各服务器的平均值)均超过了MTRM 模型,其中部分指标超过后者50%以上,说明TRMTF模型的游客阅读需求与旅游阅读场景刻画能力远超过MTRM模型,能够为旅游信息资源推荐提供良好的数据基础。
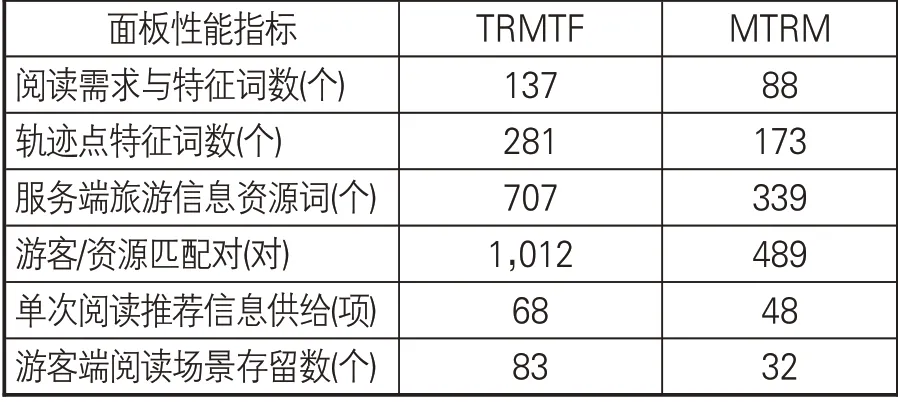
表1 两种模型的面板指标对比表
游客(阅读)覆盖度指标的计算方法是:游客(阅读)覆盖度=某区域中实际阅读了两个推荐资源的游客数/该区域中被推荐信息的游客数(以%计量)。如图3所示,A实验组(基于TRMTF模型)在10个监测周期中的平均游客(阅读)覆盖度、峰值游客(阅读)覆盖度,超过B 实验组的相关指标,充分体现了TRMTF模型及其关键算法通过移动轨迹融合技术,在游客行为特征与阅读需求挖掘方面取得了较大的优势。
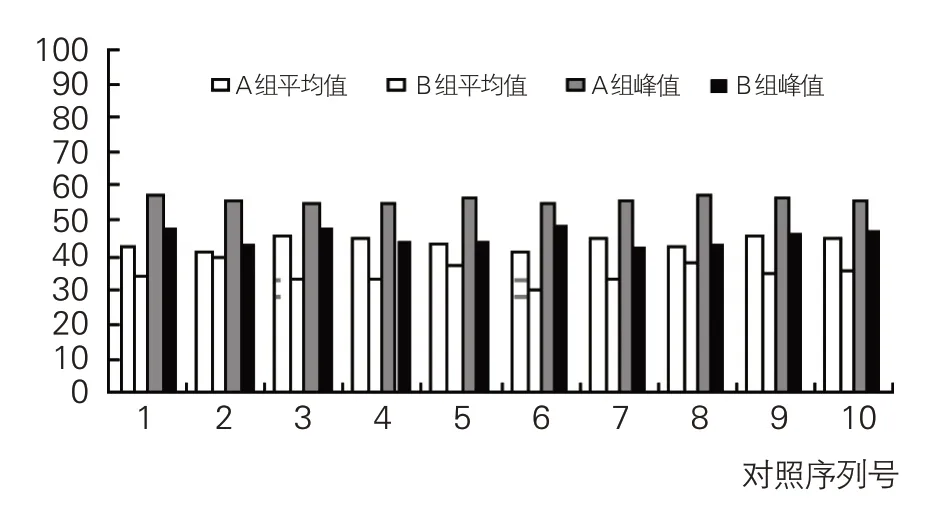
图3 游客(阅读)覆盖度对比
阅读推荐准确度指标的计算方法是:阅读推荐准确度=某区域中推荐给游客并且被游客接受的阅读资源数/该区域中被推荐的阅读资源总数(以%计量)。如图4所示,A实验组(基于TRMTF模型)在10个监测周期中的平均阅读推荐精度、峰值阅读推荐精度,超过了B 实验组的对应指标。这一对比说明TRMTF模型能够较好地挖掘游客阅读需求与旅游阅读场景(信息资源)的特征,并实现高精度的双向匹配,从而大大地提高了旅游阅读推荐的精度。

图4 阅读推荐精确度对比
3.2 旅游阅读推荐服务实例
TRMTF模型的旅游阅读推荐服务微观实例见图5,呈现了随机抽取的一名虚拟游客(编号:TE-0057)的移动轨迹与推荐阅读信息的变迁。下文概述具体阅读推荐过程。
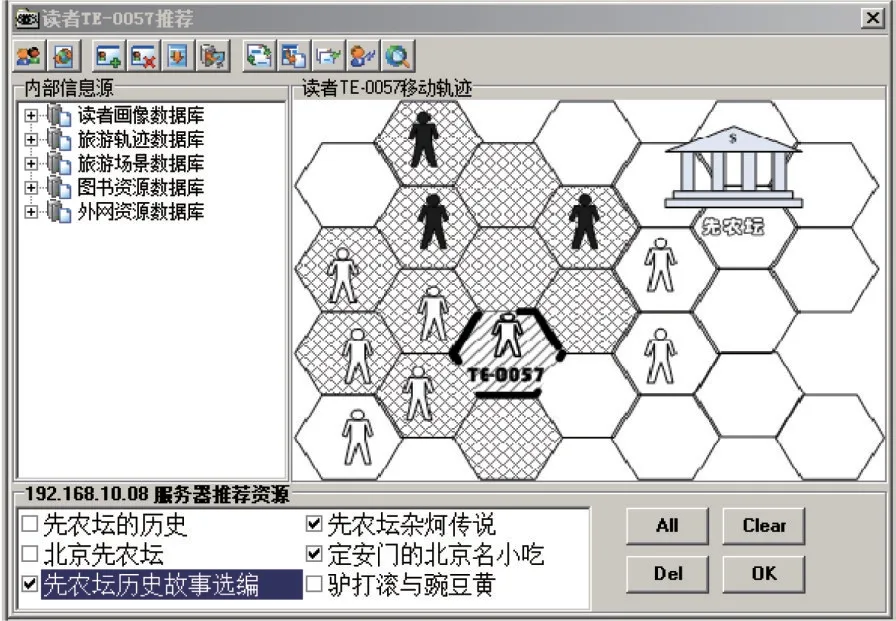
图5 旅游阅读推荐实例
Step1:读者(虚拟游客)的移动轨迹初始化,为节省计算资源,从读者的画像中生成其初始状态,其初始状态中包含阅读推荐特征词(古迹、传统、美食)。
Step2:读者移动轨迹节点启动更新,不断根据读者的场景视图变动情况,完成个体场景、自然场景、社交场景、兴趣场景与行为场景明细组等信息的汇总,生成并更新轨迹节点中的信息。由于读者(虚拟游客)TE-0057的社交信息中出现了“博物馆”“遗址”等信息,并在小吃店等场景中滞留时间较长,其轨迹节点得到了更新,其中的阅读推荐特征词“古迹”与“美食”被加强。
Step3:虚拟游客客户端一旦发现轨道节点携带者进入下一个场景时,将告知该场景中的旅游阅读推荐服务器,根据其提供的轨道节点信息,为其生成一个局部的轨道融合视图,信息合并结果,添加了“风味小吃”阅读特征词。
Step4:旅游阅读推荐服务器从客户端中获取所需的轨道信息,并将其与存储在服务器中的阅读资源(本次实验采用的是图书馆提供的区域环境、景点典故、网络游记等信息)进行匹配,以“古迹”“美食”“风味小吃”等关键词匹配结果为依据,提供个性化旅游阅读推荐服务。
4 结语
本文针对现有旅游阅读推荐算法与模型的不足,提出了一种基于移动轨道融合的旅游阅读推荐解决方案。TRMTF模型在实验中体现了较高的处理效能与性价比,具有一定的实用价值。限于目前游客端生成游客与场景信息的全面性与准确性,研究尚有不足之处,需要在轨道信息自动持续供给、阅读轨道节点近似合成等方面进一步深入研究。
