基于数据挖掘的火电厂风机故障预警研究
2021-04-08潘召涛
潘召涛
(霍州煤电集团吕梁山煤电有限公司方山发电厂, 山西 吕梁 033102)
引言
风机的持续稳定运转对提高火电厂机组工作效率非常关键,其工作的稳定性直接影响火电厂的经济和安全。由于火电厂风机工作环境相对恶劣,经长时间大负荷运行,容易产生各种故障,而大部分火电厂对风机仍然采取巡检、定期维护、停运检修的故障预防和处理方法,这对火电厂的运行效率产生一定的影响。本文提出利用数据挖掘技术在风机故障对机组运行造成影响之前,提早发出预警,使风机管理人员及时做出维修方案,避免事故造成重大经济损失。使用数据挖掘技术首先要有完整的数据源,对数据进行集成、选取和处理,然后挖掘其中内在的关联规则,以此改善风机故障的预警方法,使其在故障发生前短时间内发出报警,对风机的管理起到优化效果。
1 风机特性及常见故障
火电厂中常用的风机主要包括引风机、冷却风机、密风机、送风机、吸潮风机、一次风机等,其中由于一次风机运行条件较差,需要连续地在烟尘浓密的环境中进行大功率输出,具有很高的故障率,进行故障维修平均每年需要两次以上,每次维修都会导致整个机组减负荷运行甚至造成非计划停机。从维修记录和现场经验总结,风机的常见故障主要包括传动机构损坏、叶片磨损、动叶卡涩、噪音过大、突发降速、喘振、轴承振动和轴承温度高等[1]。
2 基于数据挖掘的风机故障预警时间确定
KDD 是一种数据挖掘技术,其过程是根据一些特定的度量方法和阈值提取有意义的交互和迭代式多阶段过程,主要包括数据准备、数据挖掘、结果表达三个步骤,如图1 所示。

图1 数据挖掘技术流程
本文以某火电厂机组系统中的一次风机故障报警优化过程作为研究对象,该风机已经运行4 年,各种运行参数和检修过程记录完整,比较适合作为数据挖掘技术的研究内容。该一次风机共安装检测点31个,其中入口调节档板开度1 个、电机前后轴承振动4 个、出口压力 2 个、风机前后轴承振动 4 个、A 相电流1 个、风机前后轴承温度6 个、电机前后轴承温度2 个、出口温度1 个、电动机定子线圈温度6 个、风机变频装置输出电流1 个、电机润滑系统3 个。4 年记录的运行参数和检修数据量达到千万条之多[2]。
2.1 数据准备
数据准备过程由数据集成、数据选取和数据处理三个步骤完成。数据集成是将多个数据渠道获取的信息进行合并处理;数据选取是将所需要处理的有效数据范围从整体数据中提取出来,缩小工作量,提高工作效率;数据处理是将原始数据中不准确或遗漏的信息使用其他的数据处理方法进行处理,以满足挖掘算法的需求,这也可以弥补数据挖掘技术的局限性。
2.1.1 数据集成和选取
需要选取一次风机无故障运转状态下的历史数据信息和另一组故障记录及其记录时间点前后的历史数据。因此,选取一次风机无故障历史记录信息的时间为2018 年9 月至2019 年4 月,选取故障信息点及其前后的历史信息记录从2019 年7 月至2019年9 月。对选取的数据进行初步统计,各个参数的数据量从4 000~14 000 不等。首先需要进行数据清洗,从记录中找到严重偏离正常范围的数据或者遗漏和乱码的数据,对这些数据进行清除。在保证足够数据量的基础上去掉一些数据量少、遗失信息过多的测点,数据清洗后保留测点20 个,这些保留的测点全部为数字型物理参数量,包括振动、温度、开度、电流、压力等[3]。
2.1.2 数据处理
由于各测点对应的参数不同,所以采集周期和采集数量不同,导致在同一个时间段内每个测点对应的数据时间间隔不一样,这不符合数据挖掘技术处理要求。因此,需要给每组测点的数据设置一个时间码,由设定的时间码,对时间一致性差的数据进行插值处理,这样处理后的数据就可以做到同一个时间段内各测点的数据数量相同,完成数据的一致性。对选取时间段内一次风机各测点数据插值处理后,重新得到280 000 组数据。这样庞大的数据量,通过数据挖掘技术是难以处理和完成的[4]。而对于数据挖掘不需要保证时间上连续,只需保证数据对时间上的一致性即可。所以等间隔提取非故障状态下的1 000组数据和故障点前后5 000 组数据用来研究即可。
2.2 数据挖掘
描述和预测是数据挖掘的两个重要因素,描述是找出隐藏在数据中的相关信息,预测是在使用已知数据建立模型的基础上判断新数据的发展方向。首先要对数据进行关联分析,挖掘关联规则,数据间的关联表现出的是属性及其数值频繁的在给定数据集中体现出的条件。关联规则的形式可以表现为:

式中:A、B 对应事件属性,关联规则X⇒Y 可解释为“数据库中的记录满足条件X,那么也很有可能满足Y”。例如,如果放任风机轴承振动增大,则也极有可能导致电流增大,这种判断使用关联规则表示如下:

可以解释为,这条关联规则的信任度为80%,支持率为3%,即风机轴承振动增大同时电流也增大的可能性为80%,且这样的事件发生的概率为3%。数据挖掘过程就是利用建立的关联规则,从中找出各个测点之间不能被直接发现的内在隐藏关系,因此,为了使挖掘出的关联能够更加准确地表达各个测点之间的内在联系,最小信任度minConf 和最小支持率minSup 的选取是一个非常关键的问题,在这个过程中需要使用“匹配率”这个指标,同时使用多组实际数据,从中挖掘出最佳的minSup 与minConf,每组数据对规则库的匹配率定义为mr则:
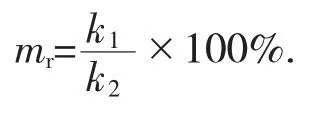
式中:k1为所有符合关联规则的数据总和;k2为只符合规则前件而不符合规则后件的规则数。mr越大越能够更正确地表达出系统的稳定性,各测点属性状态更趋于平稳[5]。
2.3 结果表达
将挖掘出的规则进行整理形成规则库,选取故障点时间前后5 000 组数据来验证规则库的有效性。采用滑动窗口统计法进行验证,这种方法可以避免不确定因素干扰导致数据偏离有效范围而发生误报警。将窗口宽度设置为20,即把20 个测点数据的匹配率取均值。在验证过程中,将匹配率的下限预警值设定为47%,则表示匹配率低于47%时,系统将进入不稳定状态,验证结果如图2 所示。

图2 匹配率验证结果
图2 中预警点就是匹配率首次降低至47%时的时间点,与原超限报警时的时间点相比提早了7 530 s,即2.5 h,从而起到了预警的效果,对一次风机的故障报警系统具有明显的优化作用。
3 结语
通过数据挖掘技术对一次风机故障预警系统进行优化,使用关联规则可以反映各测点之间的内在关系,故障的形成要通过一个转变过程,各测点之间的匹配关系逐渐被打破,测点之间的匹配度降低,当低于预警匹配率时,系统提早发出报警,并且报警时间点可以控制在一个良好的时间段内,与原超限报警相比,不会因事后报警而造成生产上的影响,也不会过早发出预警而增加维修作业的工作量,对风机故障的预警系统起到了良好的优化作用。
