基于组合模型的短时交通流预测方法
2021-04-07徐先峰赵龙龙
徐先峰, 夏 振, 赵龙龙
(长安大学 电子与控制工程学院,陕西 西安 710064)
智能交通系统(Intelligent Transportation System,ITS)中的交通流预测是实现现代交通规划、交通管理和交通控制的重要因素。交通流预测是分析道路交通状况、挖掘交通模式、预测道路交通趋势的过程。它不仅可以为交通管理者提前感知交通拥堵、限制车流提供科学依据,而且可以为人们选择合适的出行路线、提高出行效率提供参考与保障[1]。然而,由于交通流量具有复杂的空时相关性,如何让预测更加准确与高效,成为了相关从业者和学者们共同关注的话题。
对短时交通流预测的研究模型通常大致可分为两类,即参数模型和非参数模型。自回归积分滑动平均(Autoregressive Integrated Moving Average,ARIMA)模型[2]和卡尔曼滤波模型[3]是两种典型的参数模型。由于这些模型依赖于平稳性假设,不能反映交通数据的非线性和不确定性特征,无法准确预测交通流量。非参数模型包括支持向量机回归(Support Vector Regression,SVR)模型[4]、贝叶斯模型[5]和深度学习模型[6-7]等。其中,深度学习模型因其强大的学习能力而受到了更为广泛的关注。Zhang等[8]将门控循环单元(Gated Recurrent Unit,GRU)模型应用于交通流预测以提高预测精度。GRU是循环神经网络(Recurrent Neural Network,RNN)的一种变体,能够有效地利用自循环机制来学习时间相关性,从而实现较好的预测效果[9]。但是它只考虑了交通流的动态变化而忽略了其空间相关性。为了更好地刻画空间特征,一些研究[10-11]引入卷积神经网络(Convolutional Neural Network,CNN)进行空间建模。然而,CNN本质上适用于图像、规则网格等欧氏空间[12],对复杂拓扑结构的交通网络具有一定的局限性,无法从本质上刻画空间相关性。近年来,随着图卷积网络(Graph Convolutional Network,GCN)的发展[13],它为解决上述问题提供了一个很好的思路。Jin等[14]提出了一种核加权图卷积网络(Kernel-Weighted Graph Convolutional Network,KW-GCN)模型来学习交通网络中节点的线性组合权重,文献[15]在现有GCN的基础上采用了生成性对抗框架。虽然这些基于GCN的模型能够很好地处理交通网络图结构数据,却无法兼顾交通数据的动态时间特征。
为了充分发挥GCN局部学习特征、全局利用交通路网结构信息的能力,以及GRU在处理对交通序列长时间依赖问题方面的优势,本文构建了一种基于GCN和GRU的组合模型(GCN-GRU)预测方法,首先使用GCN进行复杂拓扑结构的学习及其空间特征的提取,然后利用GRU学习并处理交通数据的动态变化规律以捕捉时间特征,从而得到完整的交通流数据的空时特性。将该模型用于高速公路的交通流预测,实验结果表明,所提出的GCN-GRU组合预测模型具有较低的预测误差和较高的预测精度。
1 短时交通流预测模型及互相关函数
1.1 GCN-GRU组合模型
GCN-GRU组合模型的总体结构及模型元胞具体结构如图1所示。组合模型的输入为经过预处理的历史时间序列数据,图卷积层用于交通流数据的空间特征提取,GRU层通过单元间的信息传输获得动态变化,以获取时间特征。最后,GRU的输出通过全连接层来产生最终的预测结果。
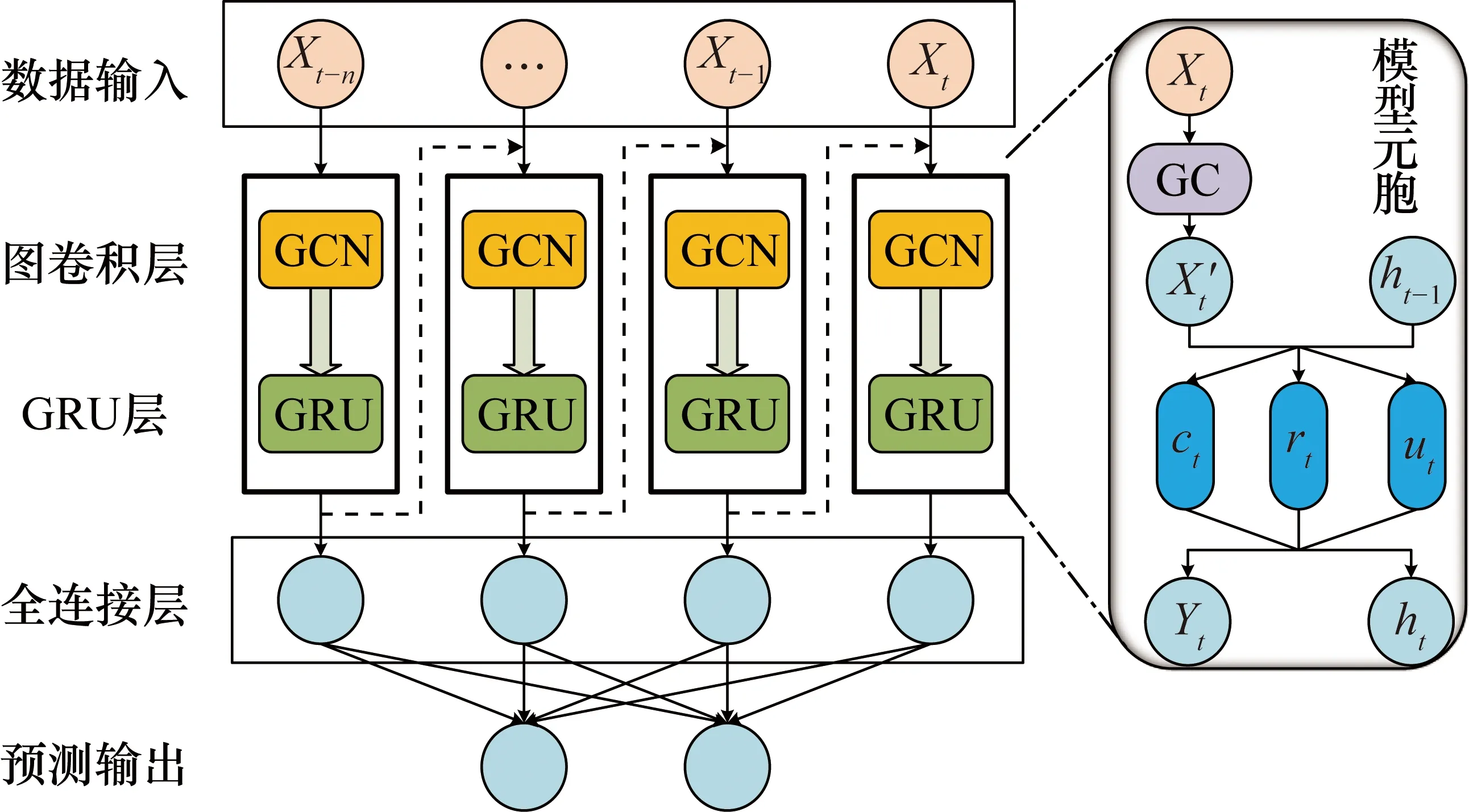
图1 GCN-GRU组合模型的总体结构及模型元胞
在模型元胞结构中,ht-1为t-1时刻的输出;GC为图卷积过程;ut,rt分别为在t时刻的更新门和复位门;ct为t时刻存储的记忆内容;ht为t时刻的输出。具体计算过程如下。
ut=σ(Wu[f(X,A),ht-1]+bu)
(1)
rt=σ(Wr[f(X,A),ht-1]+br)
(2)
ct=σ(Wc[f(X,A),(rt*ht-1)]+bc)
(3)
ht=ut*ht-1+(1-ut)*ct
(4)
式中,W和b为训练过程中的权重和偏差;f(X,A)为图卷积过程;σ(·)为激活函数。
下面,分别描述组合模型的图卷积层部分和门控循环单元层部分。
1.2 图卷积层
获取复杂的空间相关性是交通预测中的关键问题。传统的CNN可以获得局部空间特征,但它只能用于欧氏空间,如图像、规则网格等。高速公路网是以图形而不是二维网格的形式存在的,这意味着CNN模型不能反映高速公路网复杂的拓扑结构,因而不能准确地捕捉空间相关性,而GCN可处理任意图结构数据,图卷积是利用定义在傅里叶域中对角化的线性算子来等价代替经典卷积算子实现的一种卷积操作。
如图2所示,假定节点1为中心道路,GCN模型可以得到中心道路与其周围道路之间的拓扑关系,得到空间相关性。
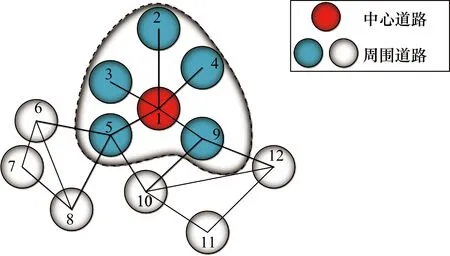
图2 中心道路与周围道路的拓扑关系示例
(5)
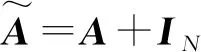
GCN结构如图3所示。两层GCN模型可以表示为
(6)
式中,W0,W1分别为第一层和第二层的权重矩阵;σ(),ReLU()为激活函数。
1.3 GRU层
获取时间相关性是交通预测中的另一个关键问题。传统的循环神经网络由于梯度消失和梯度爆炸等缺陷而在预测方面存在局限性。LSTM(Long Short-Term Memory,长短期记忆网络)模型和GRU模型是循环神经网络的变体,它们都使用门控机制来记忆尽可能多的长期信息。然而,LSTM由于结构复杂导致训练时间较长,而GRU模型结构相对简单、参数较少,训练速度较快。因此,选择GRU模型来从交通流量数据中获得时间相关性。
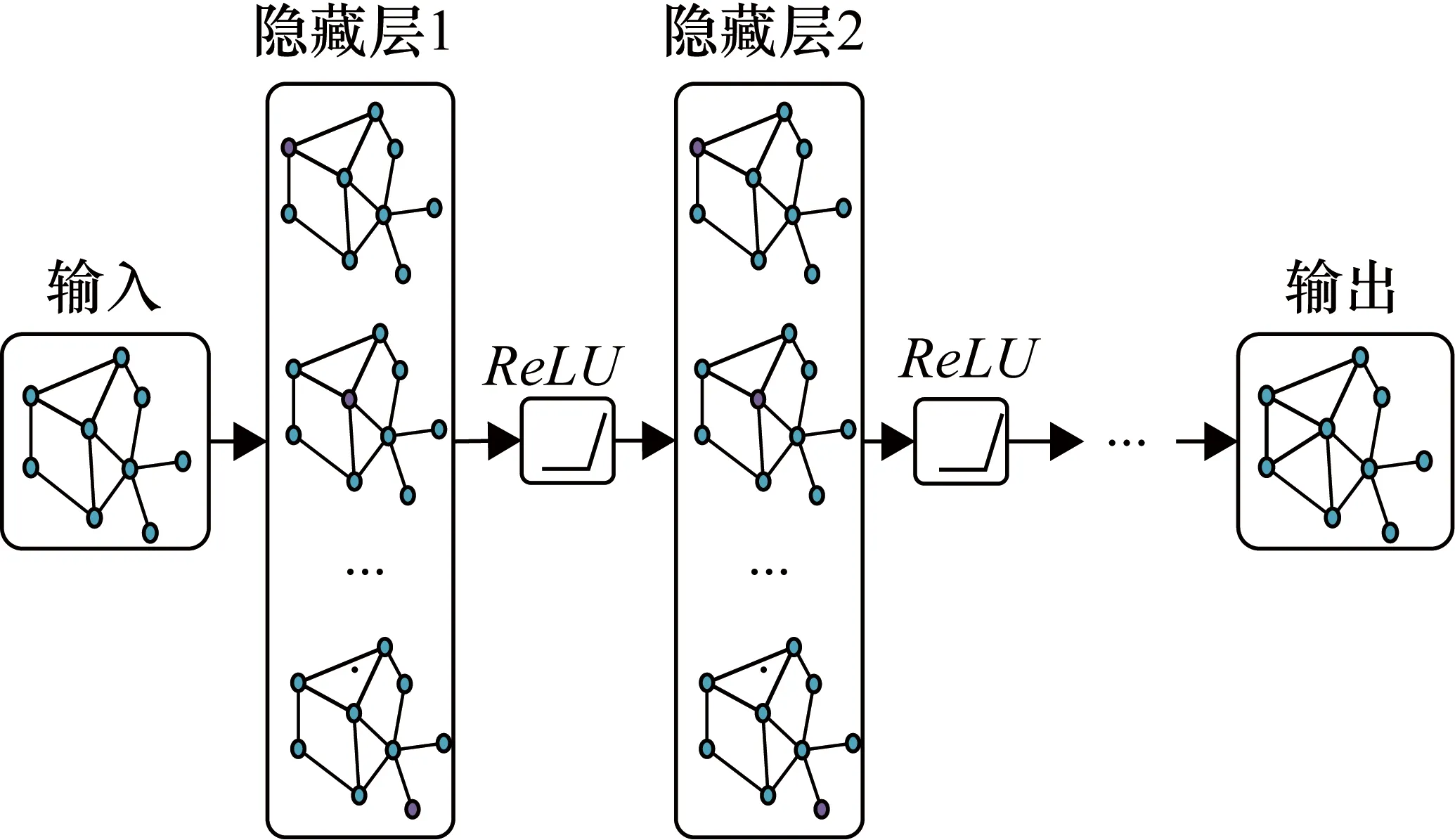
图3 GCN结构示意图
GRU结构如图4所示。其中,ht-1为t-1时刻的隐藏状态;xt为t时刻的交通信息;rt为复位门,用于控制忽略前一时刻状态信息的程度;ut为更新门,用于控制前一时刻状态信息进入当前状态的程度;ct为t时刻存储的记忆内容;ht为t时刻的输出状态。GRU以t-1时刻的隐藏状态和当前的交通信息作为输入,得到t时刻的交通状态。该模型在捕捉当前时刻交通信息的同时,仍保留了历史交通信息的变化趋势,具有捕捉时间相关性的能力。
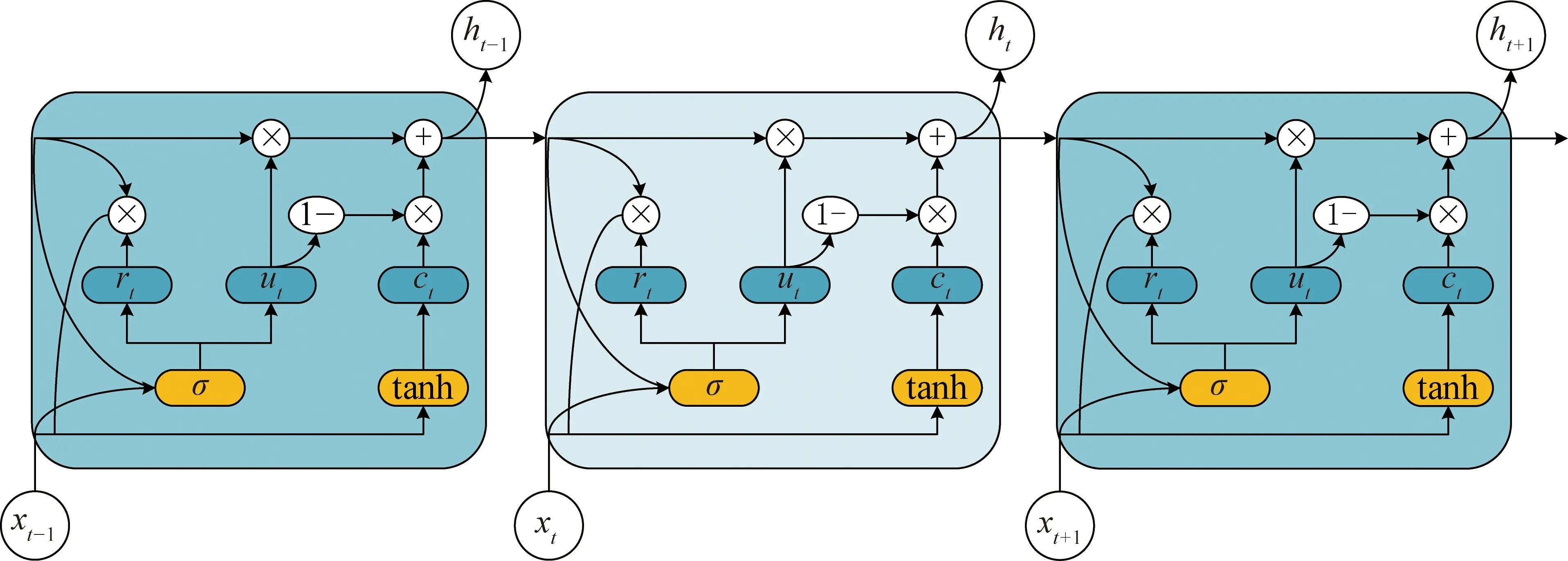
图4 GRU结构
1.4 互相关函数
由于相邻路段之间的交通流状态相互影响,上下游路段的交通状况对目标路段有着不同程度的影响。因此,交通流的变化具有一定的空时特征。考虑到周围路段交通流对预测路段存在着滞后影响,利用互相关函数(Cross-Correlation Function)在不同的滞后值下寻找存在于不同路段交通数据序列中的延迟的空时关系,从而筛选出与目标预测路段相关性较强的路段,便于后续的空时特征分析。假设时间序列可以表示为
(7)
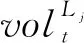
(8)
它们在滞后φ处的互相关性定义如下:
(9)
γu,z(φ)=E[(ut-μu)(zt+φ-μz)]
(10)
(11)
(12)
式中,γu,z(φ)为滞后φ下时间序列U与时间序列Z的协方差;μu,μz分别为U和Z的平均值;σu,σz分别为U和Z的标准偏差。
在这个定义中,互相关函数可以看作是滞后φ的函数,最大化互相关函数的滞后值定义如下:
ψLv=argmax(ccfu,z(ψLv)),v∈[1,N]
(13)
式中,ψLv为使得周围路段与预测路段的互相关性最大化的滞后值,它描述周围路段对预测路段的最大影响时间范围,其可用于空间邻域的有效选择。考虑预测路段Lj及其预测时间间隔Δt,当最大化互相关函数的滞后值在给定时间间隔内时,认为周围路段影响预测路段;不在此时间间隔内的路段将被排除。形式定义如下:
RLj←{Lv|∀0≤|ψLv|≤Δt,v∈[1,N]}
(14)
式中,RLj为第j条路段的空间邻域集。所有满足0≤|ψLv|≤Δt的路段都被归入RLj来选择Lj的空间邻域。
2 实验仿真与结果分析
2.1 空间探测点选取
本文所使用的是美国交通研究数据实验室(Transportation Research Data Laboratory,TRDL)提供的高速公路探测器收集的交通数据,采样时间间隔为15 min。由于工作日与周末所体现出来的交通流数据特性相差较大,为了充分利用交通流数据的规律性,选用其中2016年1月4日到3月29日共60个工作日的交通流量数据作为实验数据集,其中数据集的80%用作训练集,剩下的20%用作测试集。
图5为选取的TH5号高速公路部分探测点的分布情况,待选探测点编号分别为1559、1560、1561、1562、1563、1565、1566、1567、1568、1575、1576、1577、1578、1579、1581、1582和1583,其中预测点编号为1579。
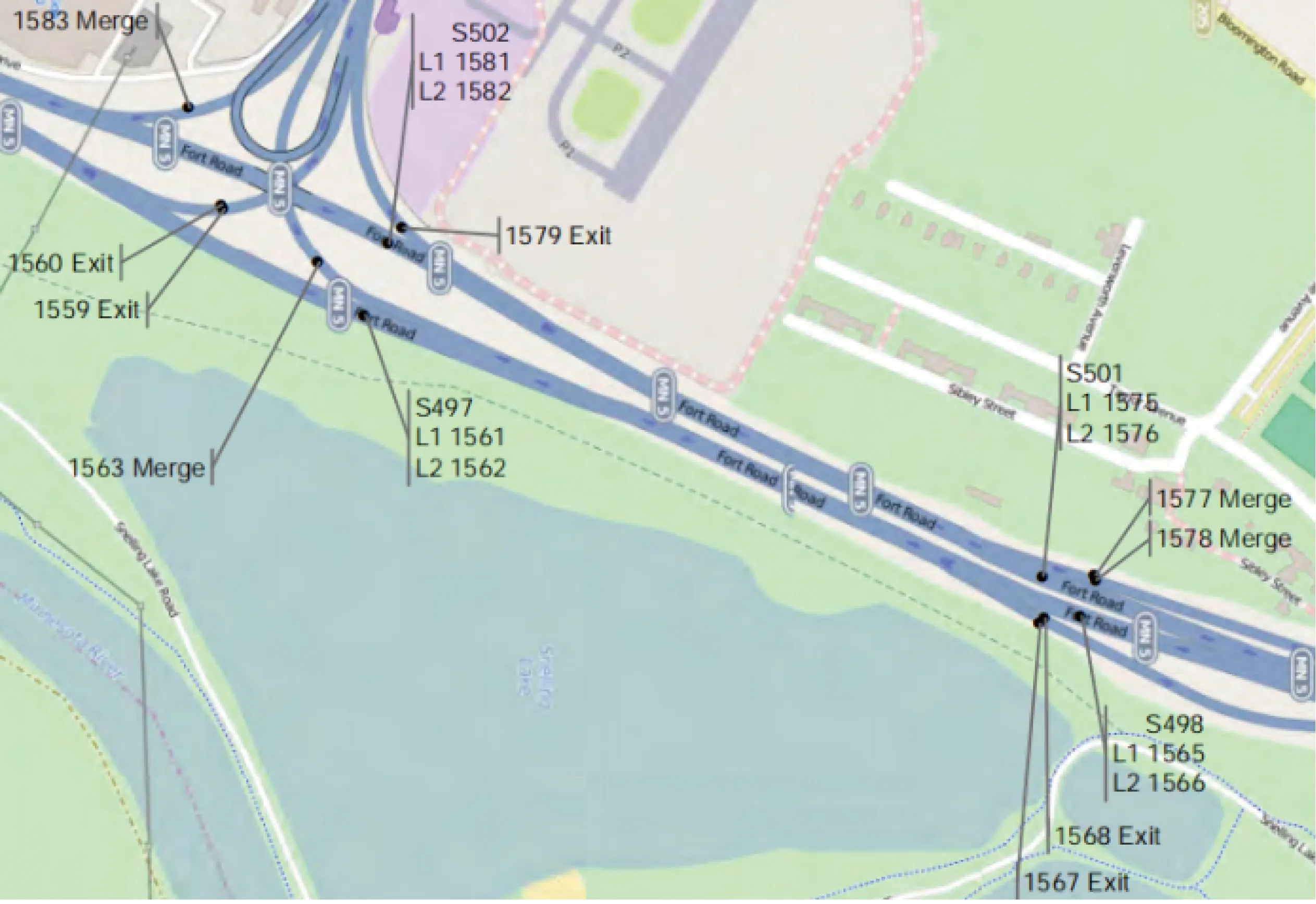
图5 部分探测点的空间分布
由于交通数据样本时间间隔为15 min,设置45 min的预测间隔则Δt=4。基于此,所有滞后应满足条件0≤|ψLv|≤4,然后计算1579与其他探测点之间的互相关性。图6为其中一个探测点1581与预测点1579的互相关性情况。
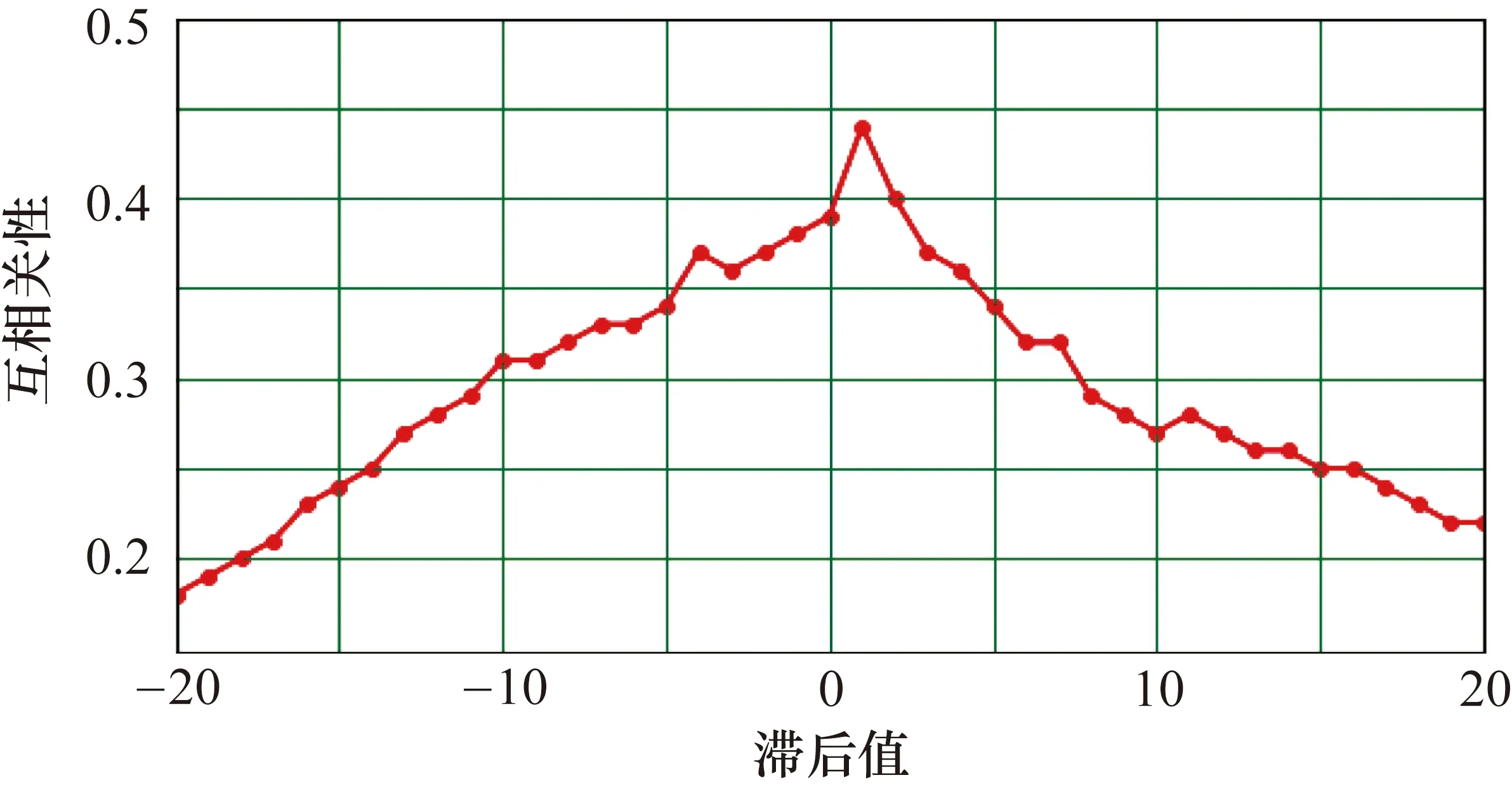
图6 探测点1581与预测点的互相关性
由图6可知,当滞后值为1时互相关性最大,同时满足0≤|ψLv|≤4,故认为1581是1579的相邻探测点。
同理,1559、1560、1563、1575、1576、1577、1578、1582和1583被认为是1579的相邻探测点,它们使互相关性最大的滞后值如表1所示,1561、1562、1565、1566、1567和1568不符合条件而被排除。
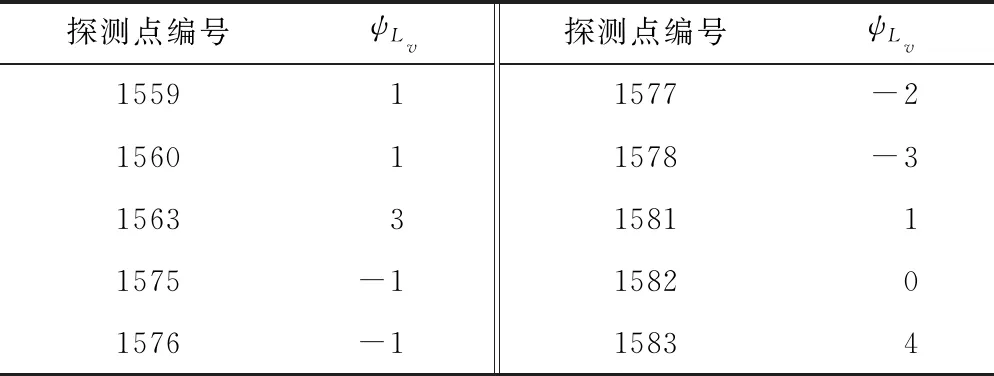
表1 探测点使互相关性最大的滞后值统计
实验数据包括两部分:① 邻接矩阵,它描述周围探测点对预测点的交通状况造成的影响程度即路段之间的空间关系,矩阵中的值表示路段之间的互相关性;② 特征矩阵,它描述了每个探测点上交通流量随时间的变化,每一列代表一个路段,每一行是不同时段的交通流量。
2.2 评价指标
为了更好地分析实验结果、评估模型的预测性能,采用均方根误差(Root Mean Squared Error,RMSE)、决定系数R2(Coefficient of Determination)和平均绝对误差(Mean Absolute Error,MAE)3个性能指标来评估实际交通信息和预测结果之间的差异。
(15)
(16)
(17)
2.3 模型参数设计
设置GCN-GRU模型的学习率为0.001,批次(batch)大小为64,epoch大小为100,模型元胞内含有两层图卷积层。隐藏神经元数是模型的一个重要参数,不同的隐藏神经元数会对预测精度产生较大影响。因此需要使用不同的隐藏神经元数进行对比实验,通过比较预测性能来选择最佳值。图7为不同隐藏神经元数下预测性能的比较结果。可以看出,当隐藏神经元数增加时,预测精度先增大后减小,这主要是因为当隐藏神经元大于一定程度时,模型复杂度和计算难度极大增加,从而降低了预测精度。当隐藏神经元数在100附近时预测性能最佳。因此,本文将模型的隐藏神经元数设置为100。
另外,该模型选择了修正线性单元(Rectified Linear Unit,ReLU)作为激活函数,它能在避免梯度消失问题的同时有效提高神经网络的计算速度,使用Adam优化器进行训练以实现学习率的自适应调整。
2.4 实验结果分析与比较
实验平台的主要配置为:Intel E5 2620 V4,32 GB DDR3 RAM,Intel 500 GB SSD,NVIDIA GTX 1080Ti,基于谷歌的TensorFlow的深度学习框架Keras,在PyCharm开发环境中完成交通流预测模型的搭建和训练,利用前45 min的历史交通流数据来预测后15 min的交通数据。将GCN-GRU组合模型的性能与ARIMA模型[2]、SVR模型[4]、堆栈自动编码器(Stacked Autoencoder,SAEs)模型[6]以及GRU模型[8]等基准方法进行比较。其中,ARIMA模型是比较早的用于交通流预测的一种方法,也是目前公认的交通预测框架中典型的参数化方法之一。模型的自回归项系数设置为0,差分阶数为1,移动平均项系数为1;SVR以统计学习为理论基础,是一种为了克服参数模型的缺点而提出的非参数模型。该模型参考文献[4],采用径向基函数作为核函数,惩罚参数设置为0.001;SAEs模型是一种比较著名的能较好地学习交通流特性的深度学习模型。参照文献[6]的思路,模型设置了4层隐藏层,每个隐藏层中隐藏单元的数量为150;GRU网络设置为2层,每层隐藏单元数设置为64。
图8展示了一天时间里的GCN-GRU组合模型、ARIMA模型、SVR模型、SAEs模型和GRU模型的预测效果。

图7 不同隐藏神经元数下预测性能的比较
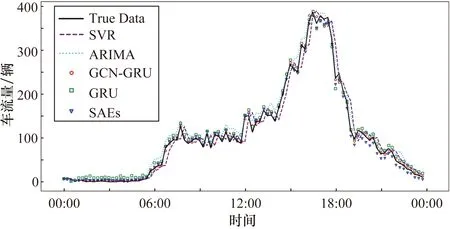
图8 各模型的预测结果对比
使用前45 min的历史数据来预测后15 min的交通流数据,故预测时间为15 min。从图8中可以直观地看出,GCN-GRU组合模型的预测值与实际交通数据最为接近,能很好地从交通数据中获取空时特征,组合模型的训练时间为117 s。表2为不同预测模型的性能指标对比。
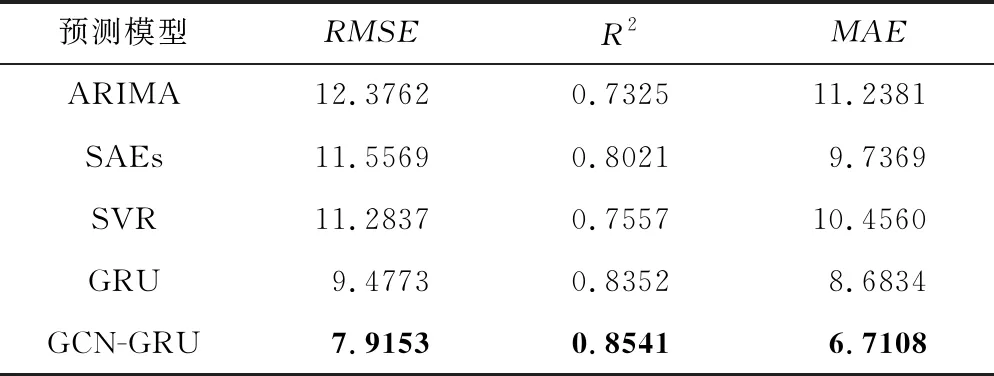
表2 GCN-GRU组合模型与其他预测模型的性能指标对比
从表2中可以定量地发现,相较于SAEs模型,GRU模型和GCN-GRU模型的RMSE分别降低了18%和31.5%,R2分别提高了4.1%和6.5%;而相比于ARIMA模型,GRU模型和GCN-GRU模型的RMSE分别降低了23.4%和36%,R2分别提高了14%和16.6%。这是因为GCN-GRU模型和GRU模型强调了时间特征建模的重要性,而GRU正是具备学习并处理交通数据的动态变化规律以捕捉时间特征的优势,从而比ARIMA模型、SAEs模型和SVR模型等方法具有更高的预测精度以及更好的拟合程度。而相比于GRU模型,GCN-GRU组合模型的RMSE、MAE分别降低了16.5%和22.7%,原因在于组合模型中的GCN对复杂拓扑结构的学习及其空间特征的提取能力,而这是GRU模型所不具有的。表2中的对比结果证明了GCN-GRU模型在交通流预测中的有效性。
3 结束语
为了充分挖掘交通流数据的空时特性以实现短时交通流预测,本文结合GCN与GRU的特点,提出了基于GCN-GRU的组合预测模型。利用美国交通研究数据实验室提供的高速公路探测器收集的交通数据对该模型性能进行评估,并与ARIMA模型、SAEs模型、SVR模型和GRU模型等方法进行比较,实验结果表明,GCN-GRU组合模型能有效提升预测精度,预测结果能很好地贴合实际交通流数据,是一种有效的交通流预测模型。后续的研究中将考虑优化GCN与GRU,以进一步提高模型的预测准确性。
