铁路货运客户价值综合评价方法研究与设计
2021-04-07史永乐周发明
史永乐,陈 兵,周发明
(1.中国铁路广州局集团有限公司 信息技术所,广州 510088;2.中国铁路广州局集团有限公司 货运部,广州 510088)
随着我国铁路建设的不断发展,特别是客运专线的陆续建成投入运营,人们的出行条件和服务得到了极大改善,铁路货运能力也逐年提高。与此同时,随着高速公路的快速发展,铁路货运市场面临的竞争越来越激烈,营销压力也越来越大,亟需在货运营销方面不断创新。企业要生存和发展,就必须认清形势,找准并锁定目标客户,通过个性化的定制服务,更好地满足客户需求,最大限度地开辟市场,创造更大的效益[1]。如何对客户价值进行综合评价是货运营销工作人员经常面对的问题,根据经典的客户生命周期理论,铁路大客户的生命周期按阶段可分为考察期、形成期、稳定期和退化期[2]。因此,部分目标客户,如果给予足够的关注和培育,可为铁路创造更大的价值。
本次客户价值综合评价分别从主观和客观的角度,采用科学的分析方法构建客户价值评估模型,使用Python 语言对数据进行计算并确定各因素权重,再对客户进行综合评价,通过对中国铁路广州局集团有限公司(简称:广州局集团公司)货票实际数据进行验证,评估模型的应用效果。
1 客户价值评价现状
装车数、发送量、运费是对货运客户价值进行评价的3 个重要指标,也是铁路企业统计、考核时常用的3 个指标。各铁路局集团公司货运客户数量不等,主要发送品类不同,如果仅仅使用一个指标对客户进行评价,结果是不科学、不全面的。表1是广州局集团公司某时期装车数前20 名客户货票数据统计结果(已经隐去客户真实名称。本文中数据计算时包含所有客户,表格中只取前20 名。下同)。
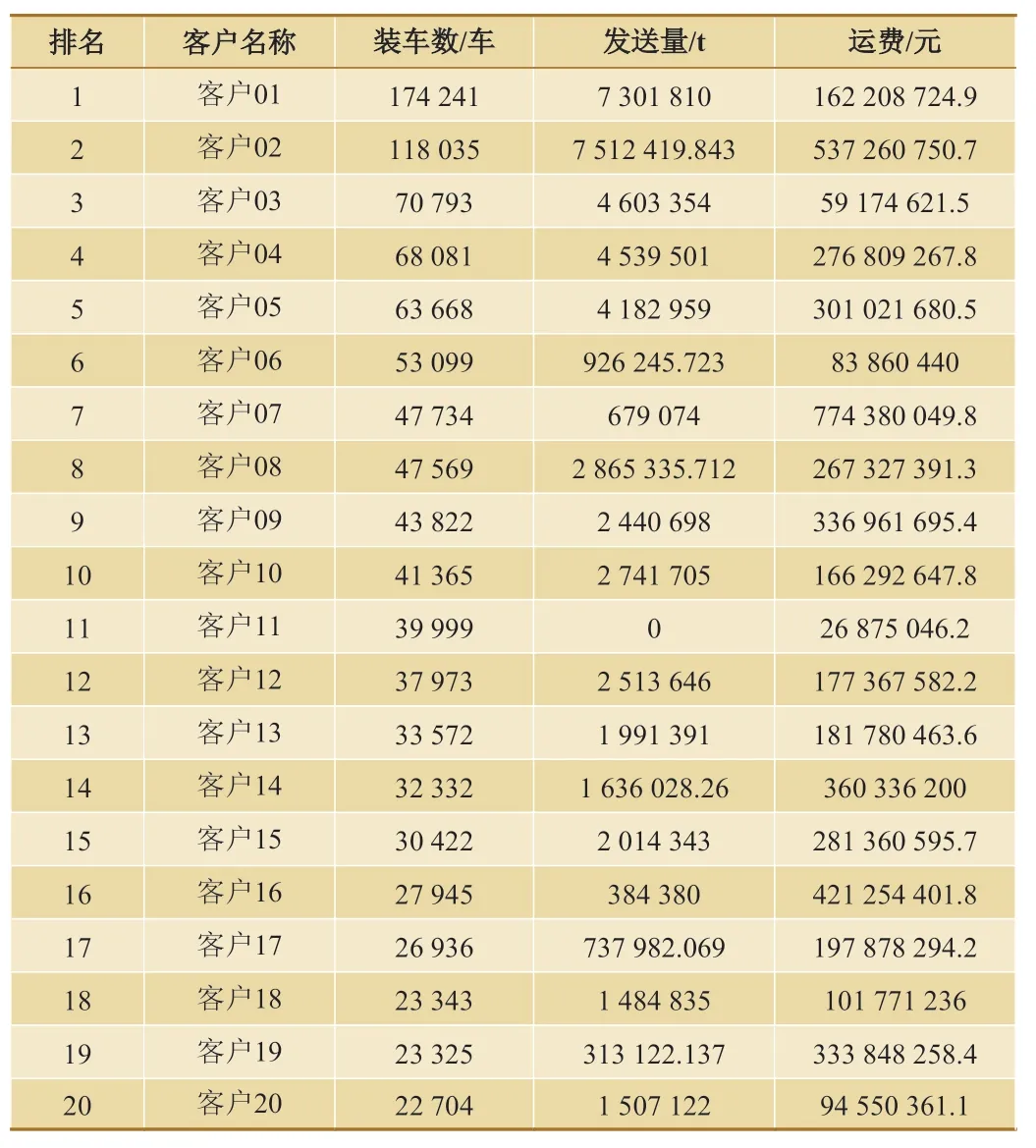
表1 广州局集团公司某时期装车数前20 名客户
从表1 中可以看出,装车数最多的是客户01,其发送量为7 301 810 t,运费为162 208 724.9 元。从表1中还可以看出该客户虽然装车数最多,但是其发送量和运费都不是最多的。
2 综合评价方法
由于装车数、发送量、运费3 个指标中的任何单一指标都不能实现对客户科学、全面的评价,因此,需要同时考虑所有指标,这就是综合评价方法。综合评价的应用十分广泛,适用于各个领域。综合评价的步骤,如图1 所示。

图1 综合评价步骤
2.1 确定评价指标
评价指标就是指决策者比较关心的一些因素或维度。以铁路货运客户为例,铁路企业比较关心的是装车数、发送量、运费。当然还可以增加其他指标,比如吨公里收入、协议兑现率等。选取评价指标时,应尽量选取无显著关联性且又能反应铁路货运业务绩效的指标。如果选择有显著关联性的指标,最终的评价结果可能达不到决策者的预期。比如,选择了装车数、发送量、运费3 个无显著关联性指标后,再增加关联性指标“吨收入”指标,由于吨收入=运费/发送量,因此,最终的评价结果中发送量、运费2 个指标占据的权重会比较高,会导致评价结果结构性失衡,达不到决策者的预期。
2.2 指标数据标准化
在多指标综合评价体系中,不同的指标通常具有不同的量纲和数量级,当各个指标间的水平相差很大时,如果直接使用原始数据进行分析,数值较高的指标在综合评价中所起的作用会很大从而削弱数值较低指标的作用。因此,为了保证综合评价结果的可靠性,需要对原始数据进行标准化处理。数据标准化就是去除数据的单位限制,将其转化为无量纲的纯数值,再将其按比例缩放,使之落入一个指定的小区间,便于不同单位或数量级的指标能够进行比较和加权。数据标准化的方法很多,最典型的是对数据进行归一化处理,即将数据统一映射到[0,1]区间。常见的数据归一化方法有min-max 标准化法、arct 反正切函数转换、z-score 标准化法,本文使用min-max 标准化法。
min-max 标准化,也叫离差标准化,是对原始数据进行线性变换,使结果落到[0,1]区间。假设有n个客户m个指标,具体做法是使用客户各个指标的实际数据构造原始矩阵A。

其中,ai j为第i个客户第j个指标的数值。
线性归一化处理后得到矩阵A'。

根据上述算法对广州局集团公司某时期货票数据统计结果的装车数、发送量、运费进行归一化处理,并取装车数前20 名客户,如表2 所示。
2.3 确定指标权重
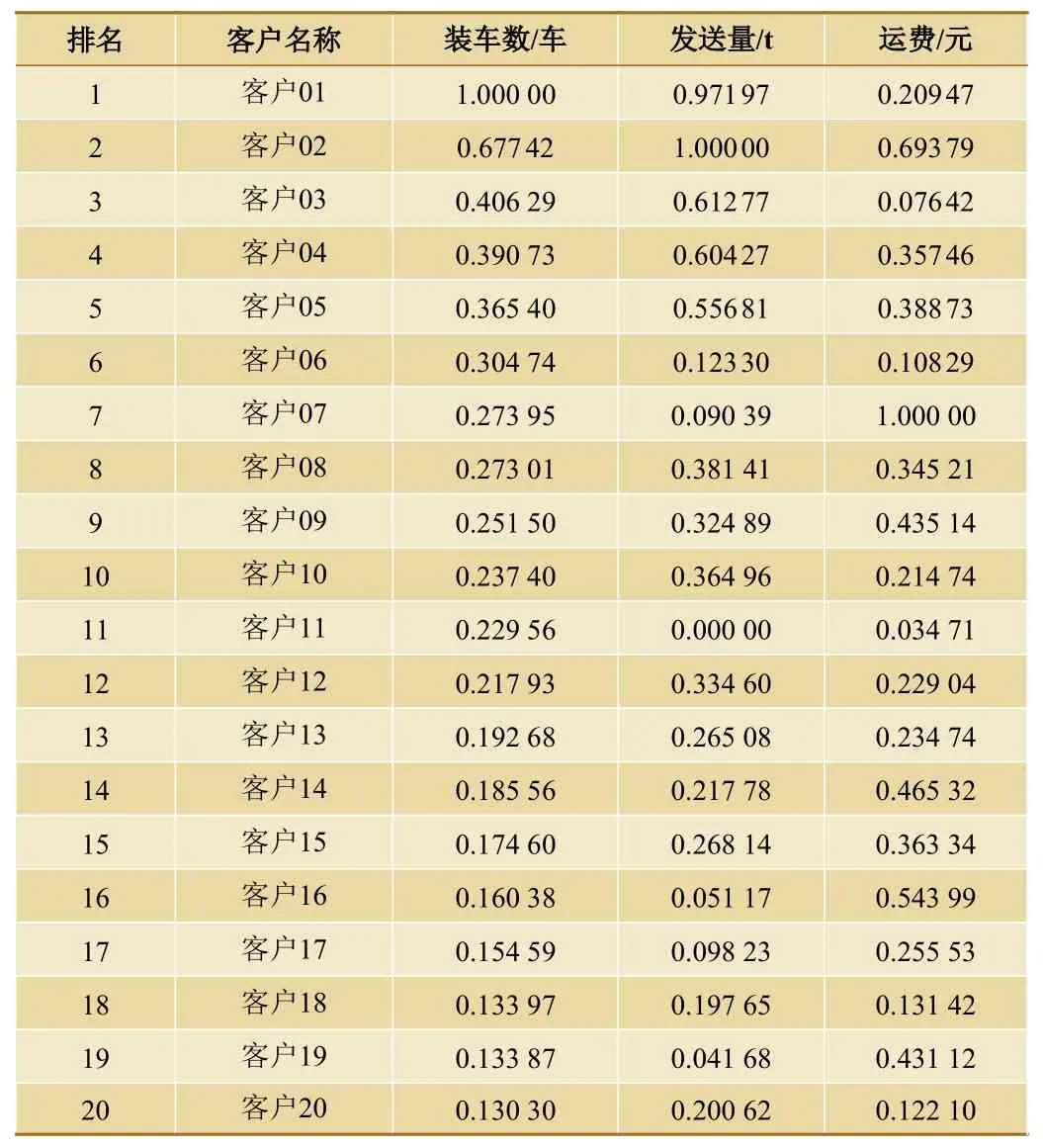
表2 广州局集团公司某时期装车数前20 名客户归一化后的数据
对指标数据进行归一化处理后,下一步就是确定各个指标的权重。在多指标综合评价中,科学合理分配权重是评估的关键,其方法分为主观赋权评估法和客观赋权评估法2 类。
2.3.1 主观评估法
2.3.1.1 直接确定权重
由决策者直接给出具体的权重值,比如装车数所占权重33.3%、发送量所占权重33.3%、运费所占权重33.3%,就表示3 个指标权重相同、同等重要。或者装车数所占权重30%、发送量所占权重30%、运费所占权重40%,就表示运费相比装车数、发送量权重更高。
2.3.1.2 层次分析法
层次分析法(AHP 法)是一种定性与定量相结合适用于多指标复杂问题的确定权重方法。该方法将定性分析与定量计算相结合,由决策者根据经验判断各指标之间的重要程度,并合理地给出每个标准的权数,利用权数求出各方案的优劣次序[3]。层次分析法确定指标权重的基本思路如下。
(1)采用两两比较法建立判断矩阵。即将参与比较的2 个指标的重要程度,赋予1~9 的标度值,并写成判断矩阵(1 表示2 个指标同等重要,3 表示一个指标比另一个指标稍微重要,数字越大则表示越重要)[4]。以装车数、发送量、运费3 个指标为例,假设装车数与发送量相比其重要程度是3(稍微重要),装车数与运费相比其重要程度是2(介于同等和稍微重要之间),运费与发送量相比其重要程度是2(介于同等和稍微重要之间),如果反过来比较则取其倒数,可以写出判断矩阵,如表3 所示。
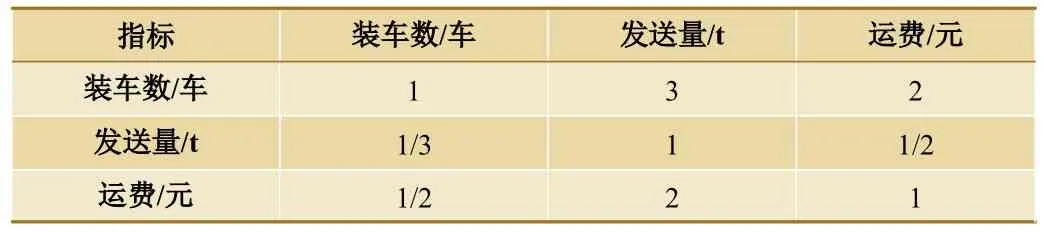
表3 装车数、发送量、运费判断矩阵
如果用矩阵来表示上述判断矩阵,则可表示为:
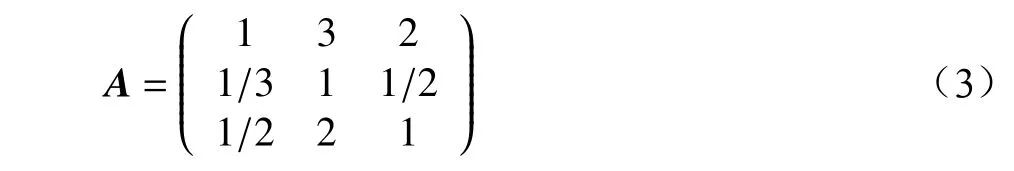
(2)计算判断矩阵的最大特征根及对应的特征向量。最大特征值用于判断矩阵一致性检验,当通过一致性检验,可对特征向量进行数学处理,从而得出指标权重[5]。按照以上思路,计算出所有指标两两比较的判断矩阵最大特征根与特征向量,最终得出各级指标的权重系数。
使用Python 语言编写矩阵计算模块,通过计算上述矩阵,可得最大特征根λ=3.009 19,特征向量w=(1.623 819,0.491 762,0.893 609)T。
为了进行判断矩阵的一致性检验,需计算一致性指标CI:
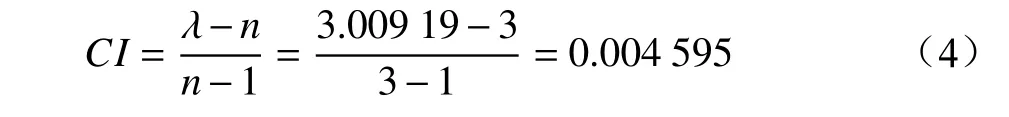
查询随机一致性指标RI表可知,当n=3时,RI=0.52,则随机一致性比率CR为:
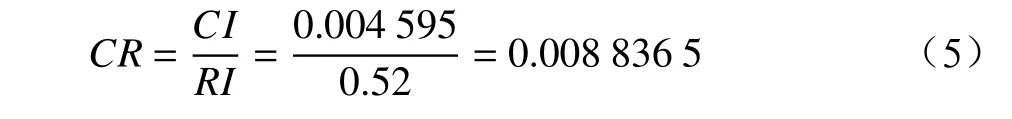
由于CR<0.1,因此认为矩阵A的不一致性在允许范围内[6],根据权重计算公式,可得各因素权重,如表4 所示。
至此,利用层次分析法,根据对装车数、发送量、运费3 个指标重要性的假设,得到了3 个指标具体的权重值。
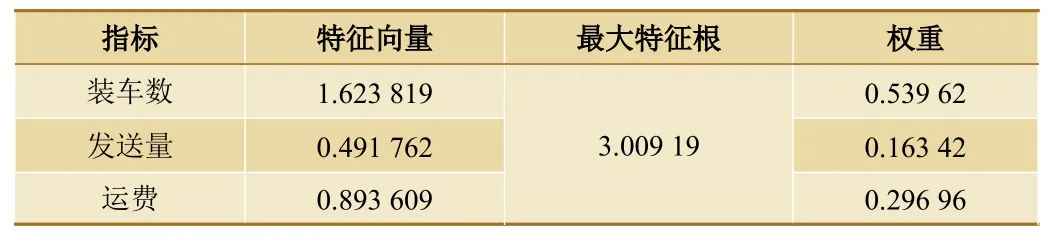
表4 层次分析法确定的各指标权重
层次分析法为定量计算多个指标的权重值提供了一种简洁实用的建模方法,对我们的思维过程进行了加工整理,提供了一套科学的计算方法。但是,层次分析法也有其局限性,主要表现在:(1)它在很大程度上依赖于人们的经验,受主观因素的影响很大,无法排除因决策者个人喜好造成的结果误差;(2)当指标过多时,两两比较可能难以准确确定各个指标的重要程度。
2.3.2 客观评估法
客观评估法主要包括变异系数法和熵值法,下面分别对这两种方法进行介绍。
2.3.2.1 变异系数法
变异系数又称为标准差率(Coefficient of Variation),变异系数法是直接使用各指标的原始数据通过计算得到指标权重的方法,不涉及人为因素,因此是一种客观的确定权重的方法[7]。
(1)求出各个指标的变异系数。由于各个指标的量纲一般都不同,不宜直接比较其差别程度,需要使用各个指标的变异系数衡量它们的差异程度。假设有n个客户m个指标,第i个客户(i=1,2,3,···,n)的第j项指标(j=1,2,3,···,m)的数值为ai j,计算各个指标的变异系数。
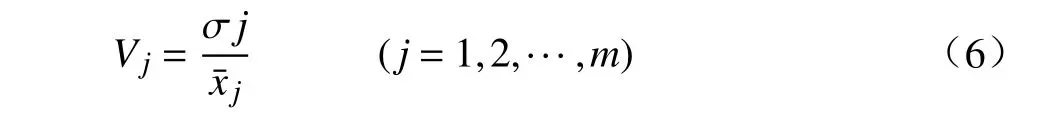
其中,Vj为第j项指标的变异系数,也称为标准差系数。
σj为第j项指标的标准差:
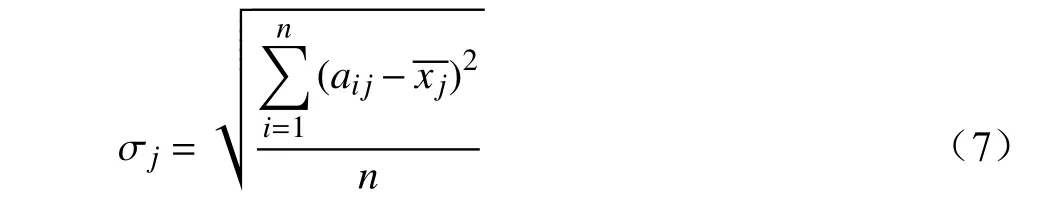
为第j项指标的平均数:

(2)计算各个指标的权重。

根据上述步骤,广州局集团公司2019 年货票数据统计结果装车数前20 名的客户装车数、发送量、运费计算出的权重结果,如表5 所示。

表5 变异系数法确定的各指标权重
2.3.2.2 熵值法
在信息论中,熵是对不确定性的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性越大,熵也越大。根据熵的特性,通过计算熵值判断一个事件的随机性及无序程度,也可以用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大[8]。假设有n个客户m个指标,具体实现过程如下。
(1)根据客户指标构造数据矩阵。
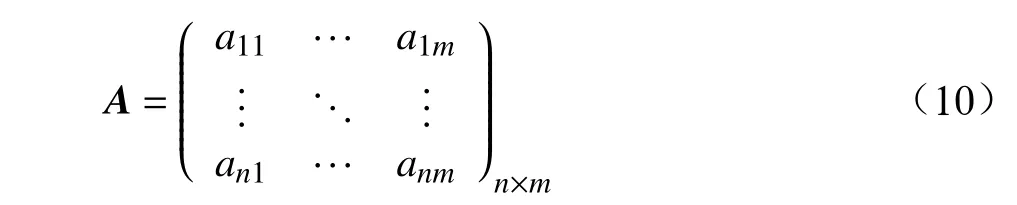
其中,ai j为第i个客户第j个指标的数值。
(2)对原始数据进行处理。由于熵值法计算采用的是各个方案某一指标占同一指标值总和的比值,因此不存在量纲的影响,不需要进行标准化处理。但是,为了避免求熵值时对数的无意义,需要进行数据平移。

其中,为第i个客户第j个指标的平移后的数值。
(3)计算第j项指标下第i个客户占该指标的比重Pij。

(4)计算第j项指标的熵值。

(5)计算第j项指标的差异系数。

熵值ej越小,差异系数gj就越大,表示该指标对于研究对象所起的作用越大。
(6)计算第j项指标的权重。

根据上述步骤,广州局集团公司2019 年货票数据统计结果装车数前20 名的客户装车数、发送量、运费计算出的权重结果,如表6 所示。

表6 熵值法确定的各指标权重
2.4 计算结果
前面已经对原始数据进行了归一化处理,又根据层次分析法、变异系数法、熵值法计算出了装车数、发送量、运费的权重,再进一步计算便可得到层次分析法、变异系数法、熵值法确定权重后客户的综合分数和排名。其中,大部分客户的排名与根据装车数所做的原始排名相比都发生了变化,有的客户排名下降达到10 多个名次,也有客户排名上升了9 个名次。
3 结果分析
通过分析看出,决策者对指标的关注程度不同,得到的客户排名就不同。层次分析法是由用户或专家根据经验确定指标的重要程度并按重要程度赋值,计算出权重和综合得分进行排名,是一种主观的综合评价方法,最终结果主观因素较大。变异系统法和熵值法对原始数据进行加工处理,计算出各个指标的权重,计算出综合得分,是一种客观的综合评价方法。在系统设计时,通过Python 语言将3 种方法都加以实现,由用户根据需要进行选择。根据目前铁路行业统计工作实际,选择层次分析法的用户较多。3 种综合评价方法的特点总结,如表7 所示。
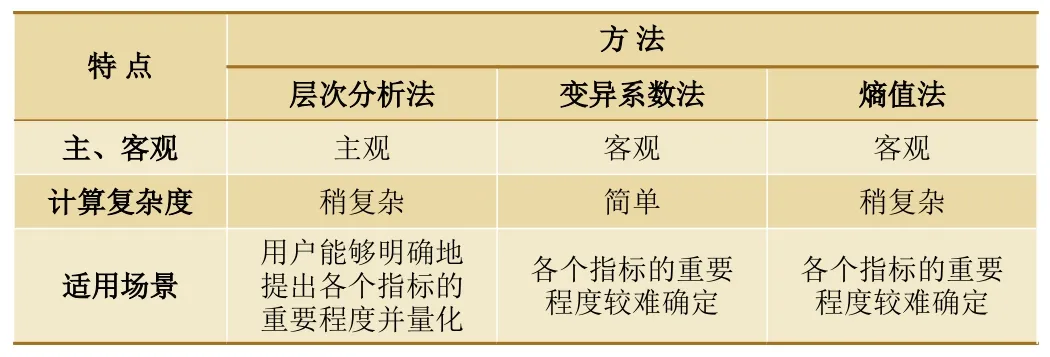
表7 3 种综合评价方法的特点
4 结束语
根据测算,获取一位新客户的成本是留住一位老客户的5~6 倍[9]。因此,对货运客户进行分类和综合评价,再对排名明显下降的客户制定行之有效的挽留方案和营销策略,这是货运客户关系管理的有效手段。本文提出了一种主观综合评价方法和两种客观综合评价方法,分析了3 种综合评价方法的适用场景,并通过大数据处理技术对客户原始数据进行计算分析,得出了综合评分结果,对于铁路货运营销工作从经验支撑转向数据支撑、客户评价从单一指标评价到综合评价转变具有一定的借鉴意义[10]。
