基于Scrapy框架的分布式网络爬虫系统设计与实现
2021-04-03周毅李威何金程蕾柳璐
周毅 李威 何金 程蕾 柳璐


摘 要:针对传统单机网络爬虫抓取效率低、稳定性差、数据量少等问题,文章利用Scrapy框架结合Redis技术,对传统网络爬虫框架进行改进和优化,设计出了分布式非结构化的网络爬虫系统,使采集到的信息能以非结构化形式存储于MongoDB数据库内,实现对数据信息的实时、有效处理分析。经过实际应用测试,证明基于Scrapy框架的分布式非结构化网络爬虫系统相较于传统单机系统具有更高的效率。
关键词:分布式;Scrapy框架;网络爬虫
中图分类号:TP311 文献标识码:A文章编号:2096-4706(2021)19-0043-04
Design and Implementation of Distributed Web Crawler System Based
On Scrapy Framework
ZHOU Yi, LI Wei, HE Jin, CHENG Lei, LIU Lu
(Information and Communication Branch of State Grid Liaoning Electric Power Supply Co., Ltd., Shenyang 110055, China)
Abstract:Aiming at the problems of low capture efficiency, poor stability and small amount of data on traditional single-machine web crawler, this paper uses Scrapy framework and Redis technology to improve and optimize the traditional web crawler framework, and designs a distributed and unstructured web crawler system, which enables the collected information to be stored in the MongoDB database in an unstructured form, so as to achieve real-time and effective processing and analysis of data information. After practical application test, it is proved that the distributed and unstructured web crawler system based on Scrapy framework has higher efficiency than the traditional single-machine system.
Keywords: distributed; Scripy framework; Web crawler
0 引 言
隨着大数据时代的到来,人们对数据的需求与日俱增。为了对万维网上的数据进行特定的搜索,各种搜索引擎也是层出不穷,搜索引擎在数据搜集中站着越来越重要的地位,但正是因为信息的高速发展,用户对信息的搜索也是越来越严苛,如今的搜索引擎也越来越难以满足用户的需求[1]。因此,互联网数据的搜集成为当代科技必不可少的技术之一,网络爬虫技术应运而生。网络爬虫技术能够实现互联网信息的自动化搜集,并将相关信息存入数据库内部。但传统单机网络爬虫抓取效率低、稳定性差、数据量少,不能满足大数据时代下的数据需求;针对开源爬虫方面,虽然已研发出Nutch、Larbin等网络爬虫项目,但普遍存在运行效率低、稳定性差、不支持中文等问题。因此本文提出基于Scrapy框架的分布式网络爬虫系统。
1 相关原理与技术
1.1 网络爬虫
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或Web信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分[2]。网络爬虫通常从一个预先设定好的URL集合开始运行,首先将所有URL有序或随机地放入到一个有序的待爬行队列里;然后按照队列顺序,从队列中取出URL并对URL地址发起网络请求,得到网页内容,分析页面内容;再提取新的URL按先后顺序存入待爬行队列中,循环整个过程,直到待爬行队列为空或满足预设的爬行终止条件。该过程称为网络爬行(Web Crawling),网络爬虫根据设计需求和技术实现,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)[3]。在实际使用场景中,通常是几种爬虫技术相结合实现的。为了提高爬行效率,通常会采取多点并行的设计架构,但需要在爬行过程中解决重复性(并行运行过程中,可能会产生重复URL)、爬行质量(并行运行过程中,每次爬取动作可能只获取部分页面,导致抓取到的数据不完善)。网络爬虫有很多使用场景,搜索引擎用通过网络爬虫来建立网页索引,实现网络资源的快速搜索;在进行网站维护时,网络爬虫用于检查网站链接是否有效、源码是否篡改等。
1.2 网络爬虫框架Scrapy
Scrapy框架是一个用于结构化、模式化提取网络资源的应用框架。最初是为了抓取网站数据而设计的,也可以用于在获取API接口的数据(各类网站数据接口等)或者构造通用网络爬虫系统。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试[4]。Scrapy框架通过Twisted异步网络库来处理网络通讯,实现网络爬虫的异步化。
Scrapy框架主要包括以下组件:Scrapy Engine(引擎);Spider Middlewares(蜘蛛中间件);Spiders(蜘蛛);Scheduler(Middlewares调度中间件);Scheduler(调度器);Downloader Middlewares(下载器中间件);Downloader(下载器);Item Pipeline(项目管道)。
1.3 Xpath页面解析
Xpath全称XMLpathLanguage,即XML路径语言,它是一种用来确定XML文档中某部分位置的语言,也适用于HTML文档的定位和搜索。在分析网页内容时,主要有三种提取网页数据的方式:正则表达式、BeautifulSoup库和Xpath。Xpath页面解析主要有以下特点:提供了简洁明了的路径选择表达式,高效实现对字符串、时间等字段的匹配能力;Xpath的路径选择表达式能实现网页内容的序列化处理,能够迅速定位网页的标签节点;Xpath比BeautifulSoup运行效率高、比正则表达式使用方便。因此本文使用Xpath对页面进行解析。
1.4 Scrapy-Redis技术
Redis是一种使用c语言编写的,支持网络,可基于内存亦可持久化的日执行并提供多种语言的Nosql数据库。在Scrapy-Redis中存放了待爬取的request对象以及已被获取的request对象指纹,基于Redis 缓存数据库,我们可以实现分布式的增量式爬虫。当获取到一个request对象时,首先将该对象生成指纹,与缓存数据库中的指纹相比较,若存在相同的指纹,表示该request对象已经被另外一台服务器请求过,不需要再次存入缓存数据库中,如不存在相同的指纹,则将该request对象放入数据库中并且生成指纹存入数据库中,这样就可以通过redis实现多台服务器的分布式爬虫。当一台服务器停止爬虫再重新开始爬虫时,由于之前的request对象已经存入缓存数据库中,再重新爬虫时,从redis中读取request对象时,仍然从上次停止的地方开始爬取,这就实现了断点续爬的功能,也就是增量式的爬虫[5]。
2 系统设计与实现
基于Scrapy框架的分布式网络爬虫系统架构分为数据层和业务层:数据层采用Scrapy爬虫框架,负责信息数据的获取和爬虫系统调度的工作。通过继承并重写Spiders类,实现定制化爬虫功能。数据层最终将数据存入MongoDB集群中,为业务层提供数据源。业务层采用Node.js框架技术,用Server类实现服务器收发请求功能,并提供正向和逆向的Ajax交互[6]。
2.1 数据层设计与实现
数据层,负责网络爬虫的调度及数据的获取、清洗和融合。数据层分为七部分:调度器、调度器中间件、下载器、下载器中间件、解析器、解析器中间件和存储管道。Scrapy引擎,用来处理整个系统的数据流处理,触发事务;解析器中间件,介于Scrapy引擎和解析器之间的钩子框架,主要工作是处理Spider的响应输入和请求输出,包括漏洞信息的清洗工作。数据层继承Spider类,并重写parse(response)方法,在各个子类中可以选择抓取数据的模式和日期,抓取数据的模式分为循环抓取、定时抓取和范围抓取。
调度器中间件,介于Scrapy引擎和调度器之间的中间件,从Scrapy引擎发送到调度的请求和响应;调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回,本文通过使用Scrapy-Redis存储调度redis的访问请求,实现分布式任务调度和爬取功能,网页调度功能由重写Scrapy引擎的Spider类实现,系统从调度器中取出一个链接(URL)用于接下来的抓取;调度器把URL封装成一个请求(Request)传给下载器;下载器把资源下载下来,并封装成应答包(Response);爬虫解析Response;解析出实体(Item),则交给实体管道进行进一步的处理;解析出的是链接(URL),则把URL交给调度器等待抓取。下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应,数据层继承DownloaderMiddleware类,并重写process_request(request,spider)方法,分别设计了RotateUserAgentMiddleware类(提供随机的伪装User-Agent头)、CookiesMiddleware类(负责cookies追踪和维护)和HttpProxyMiddleware类(提供IP代理接口),其具体设计如图1所示。
2.2 业务层设计与实现
业务层是本系统的关键所在,本系统的所有业务逻辑功能和相关算法皆在本层实现,具体设计如图2所示。使用业务层的优势在于可以降低表示层和数据层的功能复杂度,使表示层专注于请求响应,使数据层专注于数据操作,这样不仅使系统结构清晰,而且可以最大程度上实现系统松耦合,便于业务功能的扩展和屏蔽接口具体实现细节,能够增强系统的扩展性和稳定性。
2.3 网页判重模块设计与实现
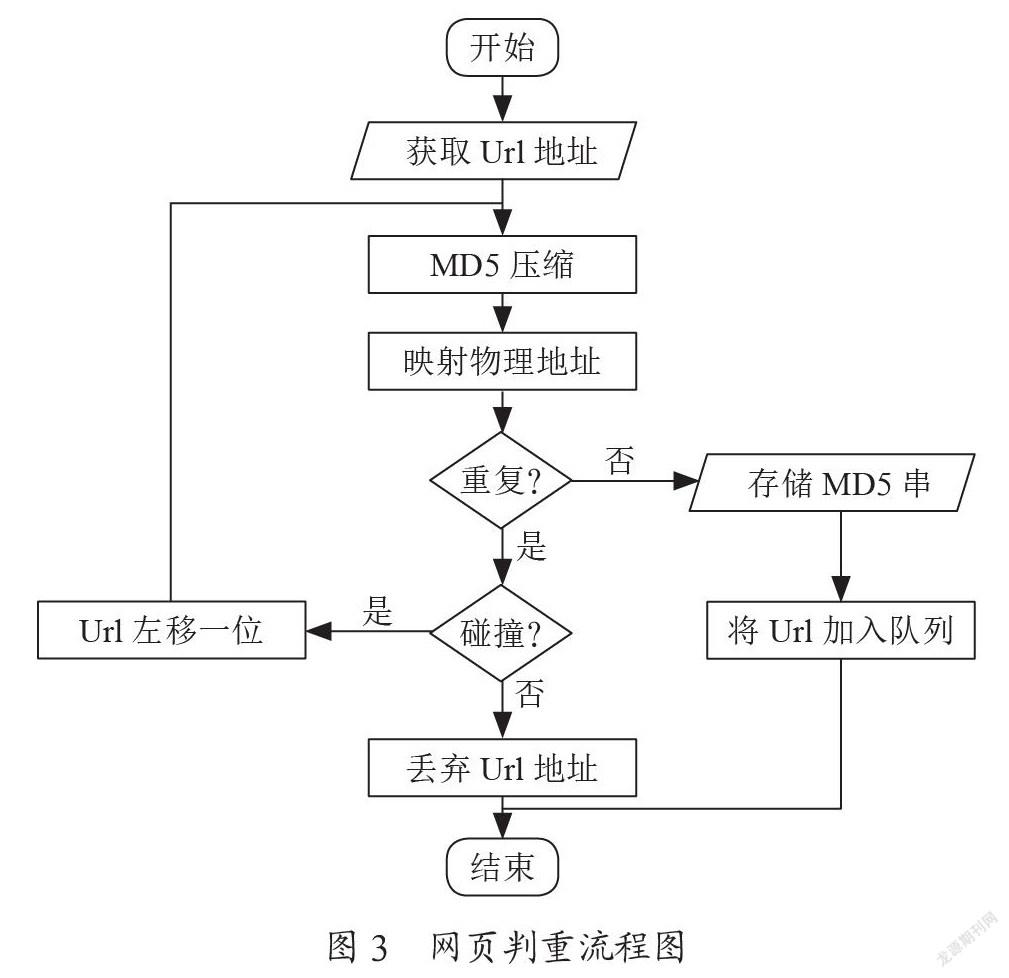
在网络爬虫运行过程中,可能存在同一页面被多次下载的情况,不仅会延长运行时间,还会为增加系统负荷。本文通过控制URL下载队列中的URL唯一性,解决爬取URL的重复性问题。首先在系统中建立一个全局变量,用于监测是否某一URL曾被访问过;然后在爬取过程中探测当前待爬取URL是否在全局变量中,即可完成URL的判重工作。本文建立一个URL去重池,在下载过程中,在去重池里的URL有且仅有一次爬取动作。
本文采用基于Hash算法的MD5压缩映射存储,实现URL去重池的功能。爬取过程中,MD5算法能够将任意位数的字符串压缩为128位整数,并映射為物理地址,且MD5进行Hash映射碰撞的概率非常小,几乎可以忽略不计,可以实现URL去重池的唯一性。在爬虫每一次爬取过程中,将在MD5存储时发生碰撞的URL左移一位,对URL进行重复MD5处理。网页判重流程图如图3所示。
本系统使用Scrapy框架中的Spider类,网络爬虫模块类继承Spider类,并实现start_request()方法,dont_filter参数设为False。本模块首先获取Url地址,接着采用MD5[45]压缩算法将Url地址压缩成长度为128位整数并映射成物理地址;随后判断整数是否重复:若不重复,则将MD5串存入去重库中并将Url地址加入请求队列中;若重复,则判断是否发生碰撞(MD5串相同的情况下,Url地址不同,称为发生碰撞。),若产生未产生碰撞,则丢弃Url地址;否则将Url地址左移一位重新進行MD5压缩并比较是否重复,直至结束。
2.4 网页下载模块设计与实现
网页下载模块在网页判重模块之后,本系统使用Scrapy框架中的下载器中间件(处理Scrapy引擎与下载器之间的请求及响应),继承DownloaderMiddleware类,并重写process_request(request,spider)方法。本系统先从请求队列RequestQueue中提取Url地址,然后交给下载器中间件下载网页内容;若下载过程中出错,则调用RotateUserAgentMiddleware类(提供随机的伪装User-Agent头)、CookiesMiddleware类(负责cookies追踪和维护)和HttpProxyMiddleware类(提供IP代理接口),重新下载网页内容,重复此过程3次;若最终仍下载失败,则将Url地址和MD5字符串存入失败队列FailQueue中,等待存入数据库中。网页下载流程图如图4所示。
3 实验结果
3.1 实验数据
为验证本文研究的基于Scrapy框架的分布式网络爬虫系统的高效率和稳定性,以hao123为测试页面,设置对照验证试验,其中本文研究的网络爬虫系统为实验组,传统单机网络爬虫系统为对照组。在实验组中通过将url.py文件产生的url队列存入至redis数据库队列内,再使用scrapy crawl命令执行分布式爬取,最后将数据存入MongoDB中;而对照组采用传统的Nutch网络爬虫进行数据抓取,分别测试实验组以及对照组在不同的网页数抓取过程中成功下载保存的网页数量,网页抓取统计结果如表1所示。
3.2 实验结果
根据上表1所示,对照组在进行网页抓取时,网页丢失数量较多、抓取时间较长,实验组的网页抓取成功率和运行效率明显提升,访问时间明显降低,证明本文研究的基于Scrapy框架的分布式网络爬虫系统具有优越性,可被广泛应用推广。
4 结 论
通过设计基于Scrapy框架的分布式网络爬虫系统,改进并优化了传统Scrapy框架,拓展了Scrapy框架的分布式能力,实现网络爬虫的分布式抓取和数据的非结构化存储,经实验结果发现基,基于Scrapy框架的分布式网络爬虫系统相较传统单机网络爬虫系统,提升了网络爬虫的抓取效率和运行稳定性。
参考文献:
[1] 米切尔.Python网络数据采集 [M].南京:东南大学出版社,2018.
[2] YU J K,LI M R,ZHANG D Y. A Distributed Web Crawler Model based on Cloud Computing [C]//The 2nd Information Technology and Mechatronics Engineering Conference (ITOEC 2016).2016:276-279.
[3] 刘顺程,岳思颖.大数据时代下基于Python的网络信息爬取技术 [J].电子技术与软件工程,2017(21):160.
[4] 施威,夏斌.基于Scrapy的商品评价获取系统设计 [J].微型机与应用,2017,36(19):12-15.
[5] 刘硕.精通scrapy网络爬虫 [M].北京:清华大学出版社,2017.
[6] 徐海啸,董飒,李翔,等.分布式网络爬虫框架Crawlzilla [J].电子技术与软件工程,2017(18):25-26.
作者简介:周毅(1992—),男,汉族,辽宁鞍山人,中级工程师,硕士研究生,研究方向:信息通信;李威(1980—),男,汉族,辽宁鞍山人,高级工程师,硕士研究生,研究方向:信息通信;何金(1983—),男,汉族,辽宁阜新人,高级工程师,本科,研究方向:信息通信;程蕾(1990—),女,汉族,辽宁凌源人,中级工程师,硕士研究生,研究方向:信息通信;柳璐(1992—),女,汉族,辽宁东港人,中级工程师,硕士研究生,研究方向:信息通信。
