基于生成对抗模仿学习的人机辅助决策系统
2021-03-31杨高光
杨高光
(上海交通大学 电子信息与电气工程学院, 上海 200240)
0 引言
在核电主控室的人机界面操作环境中,人为因素失误已成为引发工业事故的主要因素[1]。许多经验表明,提升工业自动化水平是提升生产力、降低人员失误的有效手段。同时,人机界面辅助决策系统可以降低对专家的依赖水平,缓解人才需求难题。
在辅助决策系统上,传统方法主要关注两方面研究:一方面通过调整系统展示宏观架构;另一方面利用计算机技术将现有的操作规程或者电厂组成架构数字化和可视化。如为指挥中心提供紧急事故情况下的气象、应急响应动作模拟信息、电厂状态判断信息[2];通过建立故障树为操作员提供可视化系统故障传播途径[3]。无论是调整信息展示架构,还是数字化和可视化操作规程,都没有降低对于界面操作专家的依赖。本文主要关注于通过计算机技术学习专家操作策略,从而降低对于人机界面操作专家的依赖度。相比传统辅助决策系统,利用计算机学习专家操作策略,一方面可以提高工业自动化水平,降低工业生产对于人力资源的需求,提升生产效率。同时,计算机辅助决策系统在经过实际验证后可作为智慧决策系统,符合时代发展趋势;另外,实际生产中对于人类专家的培养往往消耗巨大成本,计算机辅助决策系统可降低对专家的依赖水平。本文通过基于Mujoco的仿真环境进行实验,验证了生成对抗模仿学习可以利用少量数据学得专家操作策略。文中首先介绍了将人机界面操作看作马尔可夫决策过程的理论基础,然后依次从数据采集、策略表示和对操作策略的学习优化方面介绍了系统模型从理论到学习的过程。最后,在Mujoco仿真环境验证了基于生成对抗模仿学习[4]来学习人机界面辅助决策系统的有效性。
1 系统构建
人机界面辅助决策系统主要包括5个部分,如图1所示。

图1 人机界面辅助决策系统框图
将专家在界面上的操作作为示范数据,训练神经网络模型,学习专家在界面上的操作策略,利用学得的模型来为界面上的操作给出建议:提高人员操作的可靠性;降低人为因素失误发生概率。
1.1 问题理论描述
专家在界面上的操作过程可以看作是一个马尔可夫决策过程,其中界面上显示的数据用状态s表示,所有状态构成一个状态空间s∈S。专家在看到状态s采取的动作用a表示,所有动作组成一个动作空间A,则a∈A假设初始时刻为0,对应的状态和动作记为s0,a0。专家在时刻t看到状态st并且采取动作at后由系统模型P(st+1|st,at)得到下一个状态st+1。假设专家的操作策略表示为πE,即at=πE(st)。假设专家完成一项任务需要的时间长度为T,那么专家每次进行操作所遇到的状态动作序列可以表示为τ={(s0,a0),(s1,a1},…,(sT,aT)}。其中,τ称为专家的操作轨迹或者示范轨迹。虽然这是一次完整的状态动作操作序列,但是这并不能表示这是专家的操作策略。因此,我们用多个专家的示范轨迹来表示专家的示范数据:τdemo={τ0,τ1,…,τm-1},其中m表示示范样本数据集大小。
1.2 训练数据采集
由于专家可以从界面的各种符号标记与大脑中记忆的相应符号的含义,以及现场工艺流程的模块连接方式相对应,因此人类专家可以通过界面上窗口相应位置的符号、文字标识、对应的状态数字或者图形来获取当前现场状态。但是计算机只能识别数字信息,不能够识别界面上的标识,也不了解现场工艺流程。由于计算机和人类专家的这种认知差异,我们在利用计算机进行模仿学习时即不再是这种状态读取方式。受DeepMind星际争霸启发,我们将所有界面展开成一个界面,即将服务器端传入界面的所有状态数据作为当前状态,所有界面的控制指令作为当前的动作集,如图2所示。
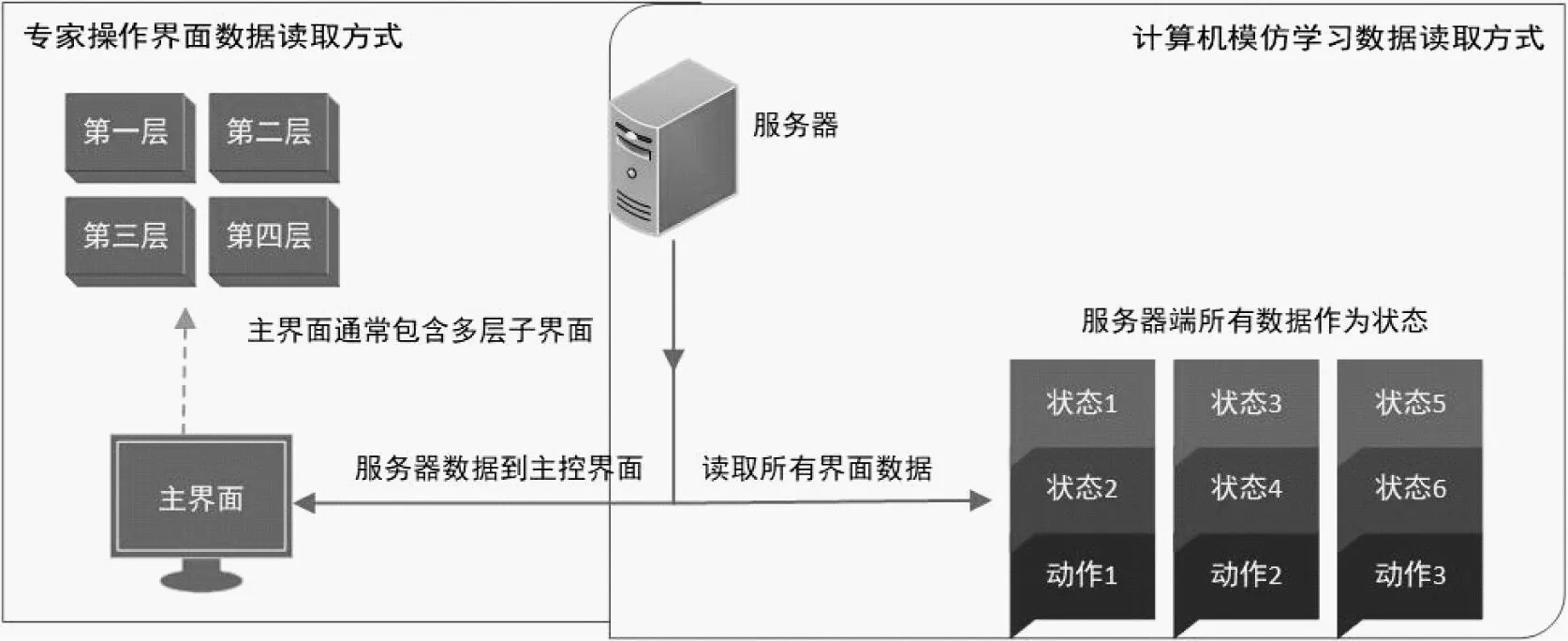
图2 专家界面数据读取和模仿学习数据读取
常规界面显示由于幅面限制,只能将数据分类在多层界面多个子界面显示,而计算机模仿学习由于不需要在界面显示状态数据,可以每次读取全部状态数据。
1.3 模型结构与优化
a.行为克隆
行为克隆(Behavioral Cloning,BC)算法是一种利用专家示范数据学习从环境状态到专家动作映射关系的一种模仿学习方法。虽然BC算法较为简单,但是却对示范数据需求较大。BC算法是一种有监督学习方法,利用线性规划或者神经网络等方法学习从环境状态到专家示范动作之间的关联。其常用的网络结构部分,如图3所示。

图3 GAIL模型结构
以环境状态s为输入,将示范动作a看作是环境状态的函数,如式(1)。
(1)
式中,wij表示权重系数;si表示环境状态变量单元。相对于生成对抗模仿学习,这种模仿学习方式需要利用大量的示范数据拟合权重系数。(对BC算法的介绍,并且简要说明BC和GAIL算法的区别。关于两种算法的区别在实验分析部分会结合实验数据进一步说明)
b.生成对抗模仿学习
训练模型,如图3所示。生成对抗网络(GAIL)的网络结构主要包含两部分:生成网络πθ和判别网络Dψ,两者均采用全连接网络。其中,生成网络为目标学习专家策略网络,用来生成学习策略:ag=πθ(sd);Dψ判别当前策略为专家策略πE还是生成策略πθ。梯度上升用来增强对πθ和πE的分辨能力;梯度下降用来降低πθ和πE的误差。πθ的因果熵为H(π),其中,πθ生成学习策略ag=πθ(sd)来对分辨网络进行欺骗,提升分辨网络分辨能力的同时也提升生成网络生成欺骗策略的能力。利用这个不断博弈的过程使得生成网络逐渐生成和专家策略一致的策略。当ag=ad时,πθ=πE。
专家的示范数据必然只是操作策略空间中的部分状态动作,往往不能够包含全部特征。这时,学习过程中必然会面临当前状态不属于示范状态空间的情况。文献[6]表明,当前状态不属于状态分布策略空间时,采取均匀概率分布策略,即对所有动作采取相同动作概率,可以收获最大信息熵。因此,以判别网络的信息熵更新πθ和πE,最大最小化判别网络和生成网络,可以使得学得的πθ对τdemonstration中没有的示范数据按照均匀概率分布处理如下。
πθ=πθ-π[ψlog(Dψ(s,a))]+πE[ψlog(1-Dψ(s,a))]
πE=πE+π[ψlog(Dψ(s,a))]+πE[ψlog(1-Dψ(s,a))]
以减小和专家界面操作策略的误差。
2 仿真实验
Hopper控制界面,如图4所示。

图4 Hopper控制界面
本实验基于Mujoco平台构建的仿真模型作为界面控制对象,对比验证了GAIL和BC两种算法在低维(跳跃机器人,Hopper。状态空间11维,动作空间3维)和高维(类人机器人,Humanoid。状态空间376维,动作空间17维)控制环境下进行模仿学习的表现。(实验数据包含两部分,低维环境实验和高维环境实验)基于信赖区间最优化方法(Trust Region Policy Optimization,TRPO)[5]算法在Openaigym平台下学得的模型作为专家,从而为模仿学习提供示范数据。专家以在有限步骤内获得累计最大化奖励为目标,通过界面控制机器人运动。每次示范取最大步骤限制为1 000步,使得专家在界面上进行1到50次示范。(实验数据样本)将不同数量的专家示范数据用于GAIL和BC算法的模仿学习训练,并且以专家每次示范的平均奖励来对学得的模型进行评价。(模型的评估标准)其中,GAIL和BC算法的网络模型均采用100个单元的双层全连接网络,以tanh作为激活函数。两种算法分别在两种操作任务和不同训练样本下学习的模型表现,如图5所示。

图5 不同算法对应不同训练样本下学得模型的精度曲线(不同训练样本的结果)
从图5可以看出,当使用单次操作示范数据来训练时,BC算法在简单和复杂操作任务中所学得模型与专家模型的相似度表现均不到30%;而GAIL算法在复杂任务中使用单次示范数据时学得的模型与专家模型的相似度表现虽然只有91%,但是在简单操作任务中学得模型与专家模型的相似度可达96%。当有10次专家示范数据时,BC和Gail算法的模型都趋于稳定。从利用10到50次示范数据训练效果看,BC算法在复杂任务中模仿学习的表现明显不如简单操作任务。而GAIL算法无论是在简单操作任务还是在复杂操作任务中,都能够达到99%的专家操作效果。由此可见,相比直接利用专家误差进行学习,将判别网络和生成网络结合,通过不断自我对抗的学习方法不仅能够学得更加接近专家操作策略的模型,还能够应对复杂环境。(不同训练数据样本的结果对比分析,GAIL和BC算法的区别)
3 总结
笔者提出了用生成对抗模仿学习的方法来构建人机界面辅助决策系统的方法。生成对抗模仿学习可以通过最大熵优化,以及生成网络和分辨网络的博弈降低对示范数据的依赖,从而可以仅利用少量专家示范数据来学得专家操作策略的分布函数。仿真结果表明:该方法具有数据利用率高、数据需求量小、学习精度高和学习模型稳定等特点。
