基于神经网络和混沌特征选择的短期负荷预测方法
2021-03-31袁保平徐毅夏轶炜朱学珍吴文涛周飞
袁保平, 徐毅, 夏轶炜, 朱学珍, 吴文涛, 周飞
(国网安徽省电力公司休宁县供电公司, 安徽 黄山 245400)
0 引言
短期负荷预测(Short-Term Load Forecasting,STLF)在传统电力系统的运行中发挥着关键作用,STLF是电力系统经济可靠运行的有效工具,许多运行决策都取决于负荷预测[1],因此,负荷预测在竞争激烈的电力市场中发挥着至关重要的作用[2]。提高STLF的准确性可以提高电力系统计划和调度的合理性,并降低电力系统的运营成本。
负荷预测算法包括传统方法和现代智能方法[3],基于数理统计的传统方法,包括回归分析方法、卡尔曼滤波方法、综合自回归移动平均法(Autoregressive Integrated Moving Average Model,ARIMA)[4]、Box-Jenkins模型、状态空间模型和指数法。这些方法具有技术成熟和算法简单的优点,但是它们都是基于线性分析的,无法准确预测非线性载荷序列。对于时间序列的非线性问题,现代智能预测方法能表现出更好的性能。而且,它们不需要任何复杂的数学公式和输入与输出之间的定量关联。在定义不明确的流程时(例如加载时间序列)[5],智能算法在STLF中具有广泛应用。智能算法包括基于人工神经网络(Artificial Neural Network,ANN)的方法。人工神经网络能较好地学习训练数据,但是在测试阶段可能会存在很大的预测误差。电力负荷预测领域仍然需要更准确的负荷预测方法,尤其是需要有效的特征选择和输入/输出映射算法。虽然基于知识的专家系统方法,能从获取的相关信息中提取程序,但是,该模型的训练过程非常耗时[6-7]。
文中提出了一种基于混沌特征选择算法和混合神经进化算法的预测方法。采用Taken嵌入定理下的相空间重构理论来设计输入向量,采用相关分析则用于确定特征与目标值的相关性。为了优化可调参数,采用了交叉验证技术。该方法的预测引擎是多层感知层(Neural Network,NN),具有差分进化(Differential Evolutionary,DE)学习算法。文中提出方法可有效选择STLF特征参数,通过实际数据进行测试,该方法具有较高的准确度。
1 特征选择方法
文中采用混沌理论进行电力系统短期负荷预测,通过混沌理论实现相空间重构,它是搜寻动态光滑空间的过程,并且在吸引子的轨道上没有相交或重叠的空间。Taken的嵌入定理提出了一个假设,在该假设下可以将混沌时间序列重构为具有两个条件的M维向量:嵌入维数和时间延迟[8]。混沌时间序列是介于规则系统和随机系统之间的一种,混沌理论主要用于检查初始条件极为敏感的动力学系统,例如系统噪声和误差,初始条件的任何细微变化都可能出现不成比例的结果。
给定一个混沌时间序列{x(t)},t=1,2,…,n(加载时间序列),选择嵌入维M和延迟时间相空间,如式(1)。
X1=[x(1),x(1+t0),…,x(1+(M-1)t0)]
X2=[x(2),x(2+t0),…,x(2+(M-1)t0)]
⋮
XL=[x(L),x(L+t0),…,x(L+(M-1)t0)]
(1)
其中,L=N-(M-1)t0表示重构相空间的长度;N表示样本个体的数量;Xt表示构造相空间中的点或矢量。
STLF准确的关键问题之一是输入向量的设计[9]。提出的特征选择技术的主要思想是将混沌时间序列重构为长度为L的M维相位空间用于重构相空间,并选择与目标高度相关的候选输入子集作为特征参数。在式(1)中,假设X1为目标,X2,X3,…,XL为分别对应一个小时,两个小时和L小时的输入变量。相关分析用于衡量候选者的相关性,两个随机变量之间的相关系数(例如corr(V,W)),如式(2)。
(2)
其中,E表示期望值算子;cov表示协方差。仅当两个标准差均为有限且两个都不为零时,才定义为相关。Cauchy-Schwarz不等式的推论是相关系数的绝对值不能超过1。相关是对称的,相关系数的绝对值介于0和1之间,表示变量之间的线性相关程度。
提出的特征选择方法具有3个可调参数:嵌入尺寸、延迟时间和具有最高相关性的选定输入数量。本文引入了一种交叉验证技术,验证集的选择对于交叉验证技术具有潜在的影响。预测日的前一天被视为验证集,而预测日之前的39天被视为训练集。为了微调可调参数,本文使用了步进程序。第一步,假定所选输入的数量恒定,并以嵌入维数和延迟时间的不同值执行训练阶段,并选择最小的验证设置误差作为最佳点。然后,假定相空间重构参数为常数,并且对所选输入的数量执行上一步以找到最佳点。
2 预测算法
人工神经网络(Artificial neural networks,ANN)是一种计算机数据处理系统,用于模拟人脑的性能,该系统由数十亿个相互连接的神经元细胞组成。因此,多层感知器(Multi-layered perceptron,MLP)网络能够在数值上逼近任何连续函数的精度。人工神经网络的架构具有多层感知(Multi-layered perceptron,MLP)结构以及DE学习算法[10]。
LM(Levenberg-Marquardt)方法训练神经网络的速度比GDBP(gradient descent back propagation)算法快10至100倍,当它具有足够数量的神经元时,在Kolmogous定理中,MLP可通过隐藏层来解决,因此,本文在结构NN中的MLP中使用了隐藏层。
DE是一种基于人口的搜索算法,它是一种相对较新的算法,旨在优化问题。DE的初始种群在解空间中随机生成,然后进行评估。选择了三个父集,他们产生了一个子集,从而产生了下一代候选者。每个世代的候选人都称为个体。DE通过将两个亲本之间的加权差异向量与第三亲本相加来生成单个后代(而不是遗传算法中的两个)。从形式上讲,拟议的DE从一代到下一代的演进是基于以下关系生成的,如式(3)。
Xi,g+1=Xbest,g+R×(Xr1,g+Xr2,g),i=1,…,NG
(3)
其中,R表示Storn和Price提出的控制参数,用于放大控制差分变化;NG表示第G代子集下解的维数N。为了广泛地搜索各个方向上的解空间,在(0,1)的范围内随机选择控制参数。
3 MLP-NN和DE的组合
为了提高ANN在提取输入/输出映射函数中的学习能力,将ANN与随机搜索技术(即DE)相结合。尽管LM是计算效率高的学习算法,但它会沿特定方向(例如最陡的下降方向)搜索解空间,因此,这些学习算法可能会产生局部最小值。在训练阶段产生局部最小值时,将添加DE以解决该问题。通过这个过程建模,逐步优化问题,DE继续进行ANN的训练阶段。首先通过LM学习算法对ANN进行训练;然后,将获得的权重和偏差值传输到DE,DE技术及其增强的探索能力可以广泛地搜索各个方向上的解空间。因此,DE试图在LM学习算法之后进一步最小化ANN的验证误差。DE中的个体是ANN的权重和偏差,目标函数是ANN的映射误差。DE通过最佳调整权重和偏差来最小化ANN的验证误差。为了将获得的LM学习算法转移到DE,首先将其设置为获得的LM的权重和偏差,然后随机选择初始群体。初始化之后,DE的个体将反复移动并搜索解空间,直到满足DE的停止条件为止。在此,如果两次迭代之间的性能差异在五个连续的迭代中没有违反预定义的值,则终止其搜索过程。然后,将DE的最佳个体的分量(权重和偏差向量)返回到NN,这被视为NN的最终权重。至此,培训过程完成。
预测日之前40天的电力负荷数据(结果40×24 =960)被视为训练样本。分别选择总样本的80%,10%和10%作为训练,验证和测试集。训练样本的附近部分相对于训练目标具有更大的相关性,因此,在附近选择作为验证集与预测范围,具有更大的相似性。另一方面,训练样本的大部分具有较小的相关性,无法正确呈现预测误差。
对于提前24小时(提前一天)的预测,可以使用迭代预测或直接预测。在直接预测,输出节点的数量等于预测输出的长度(提前24天)。在这种方法中,未来值直接从预测器输出中获取;另一方面,如果使用具有一个输出的单个预测器,则使用迭代预测方法。在迭代预测方法中,迭代将预测值用作下一个预测器的输入,而未来值则从预测器的输出中迭代获取。
4 数值结果
文中提出了两种预测:提前1小时(H-A)和提前1天(D-A)预测,这两种预测都用于实际电力系统中的STLF。H-A和D-A中,STLF通常分别对实时和正向电力市场有用。采用替换输入变量中的预测值,可以通过递归过程达到D-A负荷预测。该方法将负荷的预测变量用作下一小时输入样本的L(h-1)。重复此循环,预测至第二天的负载,然后在一天结束时更新负载数据。
某电力市场2006年11月12日执行混沌特征选择的结果[11],如图1、图2所示。

图1 交叉验证技术的样本结果(不同延迟时间和嵌入尺寸)

图2 交叉验证技术的样本结果(相关特征样本数量不同)
该图的垂直轴以平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)表示验证误差。在该图中,假设选定的相关特征的数量是固定的,嵌入尺寸(m)和延迟时间(t0)可以变化以找到最佳的相空间参数。如图1,最佳结果(较少的MAPE)出现在m=37,且t0=5的情况下。在第二阶段,选择的相关特征的数量发生了变化,求出最佳的结果。图2给出了选择特征数量的最佳点,通过测试和结果获得了NN隐藏层的神经元数量。
图1和图2中,预测准确度以MAPE表示。MAPE的定义,如式(4)。
(4)
其中,N表示预测范围;L(k)表示小时k的负载,包括实际值和预测值。
预测器学习算法的NN和DE部分验证误差的趋势,如图3、图4所示。

图3 预测器学习算法NN部分验证误差趋势
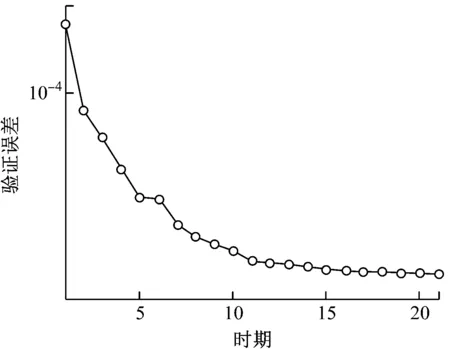
图4 预测器学习算法DE部分验证误差趋势
在图3中,验证误差在16个时期内大幅减少。同样在图4中,通过使用DE,验证误差减少了21个时期。如图4,预报器DE部分的验证误差从1.73×10-4开始,是预报器NN部分的终止点,如图3所示。DE的最大迭代次数为100,DE的种群大小为50,DE的停止标准为4.0×10-7。这表示,如果在五个连续的迭代中两次迭代的训练误差之间的差小于4.0×10-7,则训练过程完成。
为了评估所提出的STLF方法的准确性,该电力市场选取了对应2018年度四个季节的4天,并且分为提前1天和提前1小时研究了两种预测方法。这4天是2月11日,8月11日,6月13日和11月12日,功能选择方法也在这4天中进行,如图5所示。
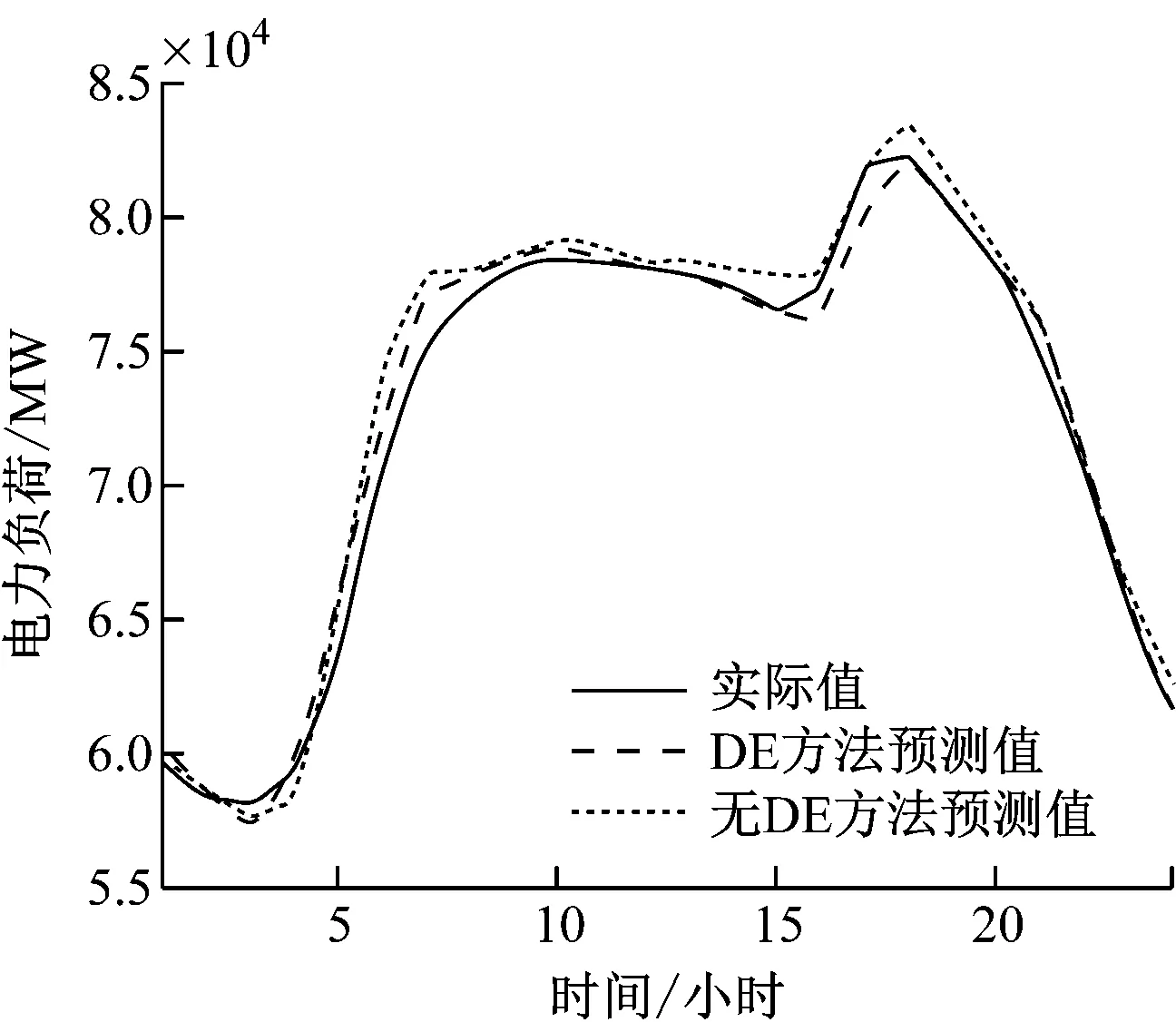
图5 电力市场负荷实际值、DE方法预测值比较
图5显示了2006年11月12日有无DE的实际负载,预测曲线。
H-A预测和D-A预测曲线,如图6所示。
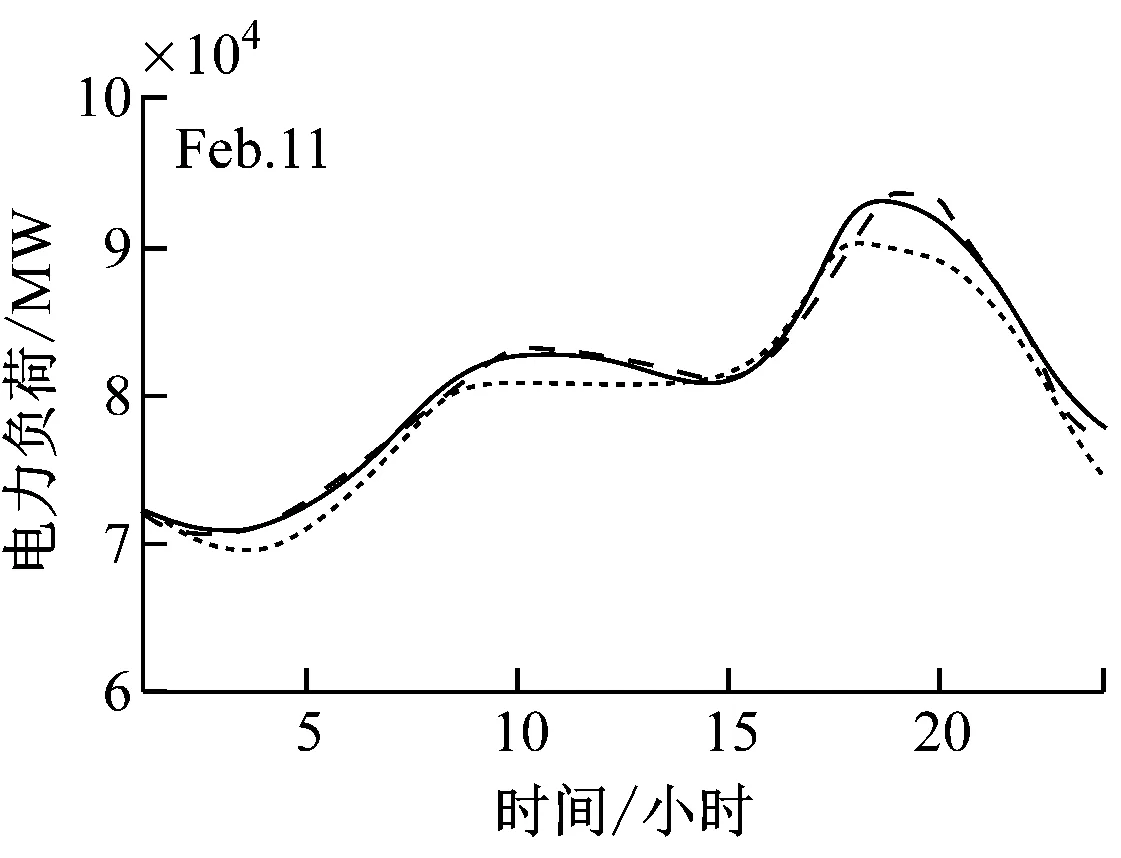
图6给出了方法(NN+DE)在四个测试日内的实际载荷。
此外,为了说明所提出的STLF算法的效率,该电力市场的2018年四个季节对应的4个星期。四个测试周分别为2月11日至2月17日,6月8日至6月14日,8月9日至8月15日以及11月6日至11月12日。2月11日至2月17日的实际和预测负荷,如图7所示。

图7 电力市场2月11日至17日的H-A预测负荷和实际负荷
在此图中,蓝色实线曲线是实际负载,红色虚线是预测负载。图7预测曲线准确地遵循了一周中所有小时的实际负荷。
5 总结
文中提出了一种基于神经网络和混沌智能特征选择的预测方法,混沌特征选择基于重构的相空间定理,相关分析用于测量与目标值相关的候选输入。并采用一种具有混合LM和差分进化DE的学习算法多层感知层NN作为预测引擎。为了微调混沌特征选择的可调参数,引入了一种交叉验证技术。
所提出的方法进行了实例测试,结果表明,在未实施进化算法的情况下,电力市场4个测试日的MAPE平均值为2.62。通过将PSO用于ANN的训练过程,该值减小到2.07。通过将DE用于ANN的训练过程(即所提出的方法),MAPE的平均值降至1.72。为了说明该方法的有效性,将结果与最新技术进行了比较。该方法对市场2018年7月的预测误差为1.84,小于以前的技术,充分揭示了预测的准确性,通过调整可调参数,该方法可以推广应用在其他电力系统。
