基于递归双对抗网络模型的人脸表情生成
2021-03-30郭迎春闫帅帅刘依
郭迎春 闫帅帅 刘依

摘要 针对目前表情生成网络中存在的人脸表情失真、不同帧间图像明暗差异明显的问题,提出一种基于递归双对抗网络模型的人脸表情生成框架。首先通过提取深度人脸特征并生成表情特征图,将其作为监督信号,生成人脸表情种子图像;然后使用生成的种子图像和原始目标人脸一起作为输入,生成特征保持图像,作为当前帧的输出,同时该特征保持图像也作为下一帧种子图像生成的输入;最后,将种子图像生成网络和特征保持图像生成网络递归进行下一帧图像的生成,多次递归得到与原始输入表情一致的特征保持人脸表情视频序列。在CK+和MMI数据库上的实验结果表明,提出的方法能够生成清晰自然的人脸表情视频帧,且在目标人脸形状和驱动的表情特征图像有较大形状差异时具有鲁棒性。
关 键 词 生成对抗;深度学习;表情动画;表情生成;双模型
中图分类号 TP391 文献标志码 A
Abstract Aiming at the problem of facial distortion of animated video generated in current facial expression generation network and large differences of light between different frames, a recursive facial expression synthesis framework based on dual network model is proposed. Firstly, deep facial features are extracted to construct facial feature maps, which are used as supervisory signals to generate seed images of facial expressions. Then, the generated seed images together with the original target faces are used as the input information to generate feature-preserving images as the output of the current frame, and also the output feature-preserving image is used as the input of the next seed image generation. Finally the next frame image is generated recursively to synthesize the facial expression sequence which features consistent with the original input expression. Experimental results on CK+ and MMI database show that the proposed method can generate clear and naturai seed image and feature-preserving image, and it is robust when there is a large difference between the shape of the target face and the shape of the driven facial expression image.
Key words GAN; deep neural network; facial animation; expression generation; dual model
0 引言
人脸表情生成是指将人脸表情从源对象迁移到目标对象,新合成的目标对象人脸图像保持不变,但是其表情与源对象一致,这种技术在影视动画、视频游戏、社交娱乐等领域的应用非常广泛[1-2]。随着面部表情迁移技术的发展,虚拟现实、情感互动、人工智能等领域的应用日益广泛,人脸表情生成引起了大量计算机图形学和计算机视觉领域的相关人员的研究兴趣。
过去几十年来研究人员提出了大量的人脸表情生成的方法,现有的方法可以根据像素的操作分为两大类,分别是基于图形学的方法和基于图像的方法[3]。基于图形学的方法通常使用一个参数模型,将源对象图像参数化到模型参数中,使用模型进行表情图像的生成。如:使用RGB-D深度摄像机进行人脸捕捉和追踪及人脸特征点定位、3D重建[4-5]来进行人脸表情的生成。人脸表情的获取和自动化建模在人脸表情生成中占有重要地位。Ekman等[6]将人脸分为不同的表情动作单元(Action Unit, AU),将不同的AU进行组合形成固定的表情合成模版,这就是经典的面部编解码系统(Facial Action Coding System, FACS)。其后Eisert[7]提出通过建立参数模型编码,使用68个表情动作参数(Facial Action Parameters, FAPs)定义人脸不同的参数,改变这些参数的大小可以产生不同的表情。 Bickel等[8]使用不同颜色的标记点对表演者面部进行标记,使用相机阵列分别采集不同尺度的表情数据。Cao等[9]通过定义一个三维参数可变形模型(3D morphable models,3DMM) [10] ,对普通摄像头捕捉到的人脸进行表情参数回归,再对三维模型進行变形和渲染,从而得到人脸表情图像。由于这些方法大多使用参数模型进行拟合,需要复杂的模型和参数设计,通常不具备泛化性,而且极少开源。通过基于二维图像拟合三维模型的相关技术[9]的出现在一定程度上解决了传统方法需要过于笨重设备的问题[11-12],但同样存在模型复杂、实现困难的问题。
[ψ1]网络结构如图3所示,对于人脸表情特征图像[B],使用多个卷积和池化层提取深度特征,表情特征图像提取器用于提取输入人脸的表情信息,在图像重建中作为监督信息,相对来说其所包含信息量较少,为了降低网络的参数量,提高系统运行速度,应适当缩减其特征提取器的深度。
对于目标人脸图像[S]的特征提取器,由于人脸目标图像在生成人脸表情动画中提供了纹理和个体特征,因此人脸目标图像特征提取和特征解码需要对人脸的细节进行更多保留,增加人脸图像[S]的编码器网络深度,提取图像中更高层级的特征;使用跳跃连接,将低级图像纹理特征进行保留,人脸特征图像和目标人脸分别同时进行特征跨层连接,最终在解码器阶段融合更多信息,提高图像精细度。
如图4所示,在[ψ2]中使用了对等的两个输入,其一为[ψ1]输出的种子图像[O1],另一输入为原始的目标人脸图像[S],因此在[ψ2]中使用了两个相同结构的特征提取器,但不共享参数。在解码阶段,添加更多地跳跃连接。另外,[ψ2]判别器中使用分类能力更强的VGG网络,增强型的判别器使得[ψ2]能够分辨生成图像和真实图像间更加微小的区别。由于更强的判别器导致生成网络更加难以训练,因此训练[ψ2]时,将部分[ψ1]网络参数在[ψ2]中共享。
1.3.2 递归生成视频帧
在基于深度学习的人脸表情相关文献中没有考虑生成视频中不同帧之间的一致性[3,15,17-18,23],大多数仅仅针对单张图形进行生成,虽然静态的图像生成已经达到了十分精细逼真的效果,但是一旦进行视频的相关生成,就会暴露出生成不同图像帧的明暗差异大的问题,即有些帧比较亮,有些帧比较暗,存在分布不均匀的问题,导致在视频播放的时候会出现闪烁、视频真实性下降。本文提出的递归生成方法,利用种子图像生成网络获得表情种子图像,再使用特征保持网络进行特征保持图像的生成,然后,使用生成的特征保持图像作为新一帧的输入进行递归生成。最终使所有的视频帧颜色、亮度和纹理更加统一,生成的视频更加真实自然。
使用两个网络对人脸进行分别生成,首先由[ψ1]进行人脸的种子图像生成,然后使用[ψ2]对生成的图像进一步优化递归生成,获得人脸特征保持的输出图像。在递归生成时,设输入的驱动图像帧序列为[B],其对应的第[i]帧驱动图像为[bi],目标人脸图像为[S],如图5所示,为递归生成的流程。由[ψ1]进行人脸表情的种子[O11]图像生成。[O11]将作为[ψ2]的输入,同时,目标人脸[S]也将作为[ψ2]的输入,获得第一帧人脸的特征保持图像[O12]并进行输出;接着进行第二帧人脸边界序列[B2]的输入,将第一帧最终输出的特征保持图像[O12]和第二帧对应的人脸特征图像[B2]作为[ψ1]输入,进行第二帧种子图像[O21]的生成,然后由[O21]和目标图像[S]的进行第二帧特征保持图像[O22]生成,作为第二帧的输出。以此循环,递归生成所有表情帧的输出如式(1)和式(2)所示:
2 实验结果与分析
2.1 数据集和模型训练
网络的训练和测试均使用CK+和MMI数据集,二者均提供人物表情的视频数据。本文选取图像数据集分别来自CK+和MMI数据集视频中获取的图像帧。其中CK+数据集包括123个人,593个图像序列,每个图像序列的最后一帧都有动作单元的标签,而在这593个图像序列中,有327个序列有表情的表情标签;MMI数据集包含超过2 900个视频和75個人的高分辨率静止图像。其完全注释了视频中的所有人物的表情动作单元(AU),并且在视频帧级别上进行部分编码。
2.1.1 预处理
本文使用的数据集包括了丰富的场景,数据集为视频的形式。因此截取视频帧并生成对应数量不定的视频帧图像。使用Dlib机器学习库对每一张图像中的人脸进行检测和裁切,并提取每张人脸中68个特征点,将其转化为人脸特征图像。如图6所示,对于数据库中的一个表情视频片段,将其截取为仅含人脸部位的图像,然后获取特征点,并构造表情特征图像。
2.1.2 训练细节
在CK+数据集中,随机选取80个人的全部视频数据进行训练,组成超过200 000对训练数据。对[ψ1]和ψ2分别进行了训练,在对[ψ1]的训练中,选取大小为64的batch size,迭代训练200 000次。训练[ψ2]使用了同样的数据,batch size大小设定为64,迭代训练100 000次。在使用MMI数据集时,使用在CK+数据集上训练得到的模型参数进行微调,使用随机的50个人的全部视频数据进行训练。测试集中使用CK+数据集剩余的43个人的全部视频数据和MMI数据集剩余的25个人的全部视频数据。
由于传统生成对抗损失函数中使用对数函数和JS距离,容易导致训练过程中的梯度消失的问题,文献[24]中通过使用不带动量的优化器训练,并对更新后的权重强制截断到一定范围内,以满足其中提到的lipschitz连续性条件,并且使用不带动量的优化如RMSprop,并将权重截断到[-0.01,0.01]之间,避免梯度消失问题,本文使用相同的策略。
2.2 图像生成效果
为了验证本文方法的人脸表情生成效果,这里与目前主流的基于生成对抗的人脸表情生成方法进行了比较,主要的对比方法有CycleGAN、GeneGAN和GeometryGAN。对于CycleGAN,本文依据作者的文献实现其代码进行实验。如图7所示,最上面一行为输入的原始人脸表情图像,对其进行表情图像的生成。本文使用了4种方法进行验证,分别为CycleGAN、GeneGAN、GeometryGAN及本文提出的对抗方法。从图中可以看到,CycleGAN和GeneGAN生成的图像模糊不清,并且出现人物失真和变形的问题,这是由于没有使用特征归一化或者特征转换器进行特征的重组。相比GeometryGAN,本文方法生成的人脸表情图像更加清晰,达到最好的效果。
2.3 人臉特征图比较
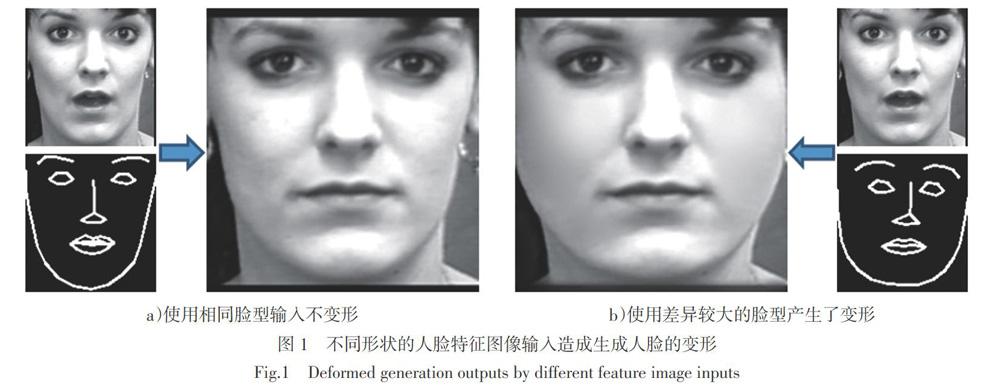
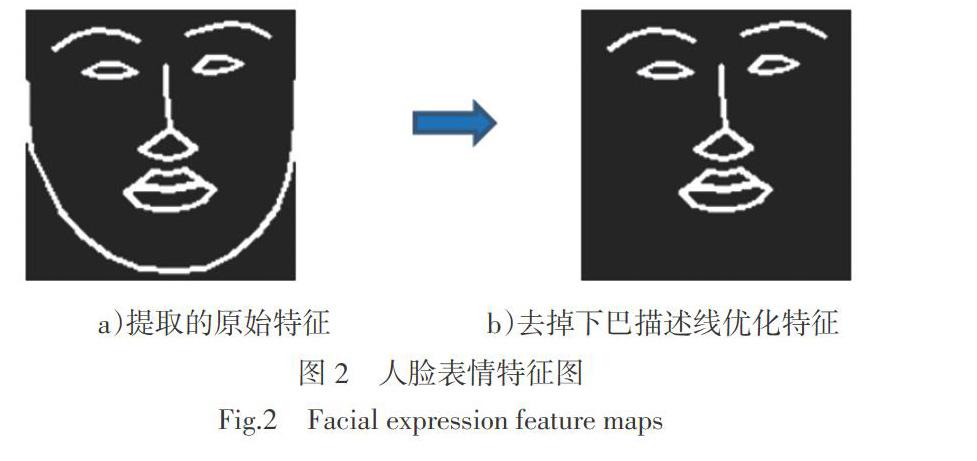
如图8所示,图8a)~d)分别为两个不同脸型的人脸使用对方的人脸特征图像生成的人脸表情帧。图8a)和图8b)为使用带有下巴包围框的特征图像作为监督信息生成的人脸表情图,图8c)和8d)为不带有下巴边界框的特征图像作为监督信息生成的人脸表情图像,从图中可以出,本文提出的方法能够达到在人脸图像生成时保持原始输入人脸特征的效果,且本文方法构造简单,易于理解。在网络训练过程中也发现,由于减少了冗余信息,不使用带有下巴包围线的特征图能够使模型更快地收敛。
2.4 表情图像帧生成效果
本文提出的方法能够生成真实性高的人脸表情视频帧,在使用英伟达GTX1080Ti显卡的主机上能够实时生成人脸表情图像。本文对生成的视频帧进行了充分的验证,首先是表情的迁移。使用了未包含在视频训练数据集中的数据,提取表情特征图,然后使用表情特征图驱动目标人脸生成人脸表情图像帧。如图9所示,对生成的视频帧的连续性进行了实验,测试输出完整流畅的视频帧。对不同的人脸,包括彩色和黑白的人脸进行生成,对不同脸型的人使用同一个人脸表情特征图进行生成,生成了的图像具有较高的真实性。
3 结论
本文提出基于深度学习的递归生成人脸表情动画方法,使用两个生成网络递归生成人脸表情图像帧。首先通过对抗网络生成含有驱动人脸表情信息的种子图像,将其用于生成输入人脸的特征保持帧。在表情动画中,通过将前序帧的输出作为下一帧的输入进行递归生成,能够生成平滑过渡的图像帧。在每个网络中,特征提取层和重建层使用跳跃连接。实验证明本文提出的方法能够生成精确的、平滑的人脸表情动画,解决了传统方法模型复杂、操作困难等问题,同时使用简单的表情特征优化方法,提高了系统运行效率。未来,在对应的图像上使用声音作为一个附加,使用生成网络完成对图像帧和语音的同时生成,使用声音和图像进行相互促进,提升生成图像的精度。
参考文献:
[1] 蒲倩. 人脸表情迁移与分析方法研究[D]. 西安:西安电子科技大学,2014.
[2] 万贤美,金小刚. 真实感3D人脸表情合成技术研究进展[J]. 计算机辅助设计与图形学学报,2014,26(2):167-178.
[3] SONG L X,LU Z H,HE R,et al. Geometry guided adversarial facial expression synthesis[C]//2018 ACM Multimedia Conference on Multimedia Conference - MM '18. New York:ACM Press,2018:627-635.
[4] BEELER T,BRADLEY D,ZIMMER H,et al. Improved reconstruction of deforming surfaces by cancelling ambient occlusion[J]. European Conference on Computer Vision,2012,2012:30-43. .
[5] BRADLEY D,HEIDRICH W,POPA T,et al. High resolution passive facial performance capture[J]. ACM Transactions on Graphics,2010,29(4):1-10.
[6] EKMAN P,FRIESEN W V,O'SULLIVAN M,et al. Universals and cultural differences in the judgments of facial expressions of emotion[J]. Journal of Personality and Social Psychology,1987,53(4):712-717.
[7] EISERT P. MPEG-4 facial animation in video analysis and synthesis[J]. International Journal of Imaging Systems and Technology,2003,13(5):245-256.
[8] BICKEL B,BOTSCH M,ANGST R,et al. Multi-scale capture of facial geometry and motion[J]. ACM Transactions on Graphics,2007,26(3):33.
[9] CAO C,WENG Y L,LIN S,et al. 3D shape regression for real-time facial animation[J]. ACM Transactions on Graphics,2013,32(4):1.
[10] BLANZ V,VETTER T. A morphable model for the synthesis of 3D faces[C]//Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques-SIGGRAPH '99. New York:ACM Press,1999:187-194.
[11] CAO C,WU H Z,WENG Y L,et al. Real-time facial animation with image-based dynamic avatars[J]. ACM Transactions on Graphics,2016,35(4):1-12.
[12] WENG Y L,CAO C,HOU Q M,et al. Real-time facial animation on mobile devices[J]. Graphical Models,2014,76(3):172-179.
[13] GOODFELLOW I J,POUGET-ABADIE J,MIRZA M,et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems,2014:2672-2680.
[14] LU Y,TAI Y W,TANG C K. Conditional cyclegan for attribute guided face image generation[EB/OL]. 2017:arXiv preprint arXiv:1705. 09966 [cs. CV]. https://arxiv. org/abs/1705. 09966.
[15] DING H,SRICHARAN K,CHELLAPPA R. ExprGAN:facial expression editing with controllable expression intensity[EB/OL]. 2017:arXiv:1709. 03842[cs. CV]. https://arxiv. org/abs/1709. 03842.
[16] LIU Z L,SONG G X,CAI J F,et al. Conditional adversarial synthesis of 3D facial action units[J]. Neurocomputing,2019,355:200-208.
[17] WU W,ZHANG Y X,LI C,et al. ReenactGAN:learning to reenact faces via boundary transfer[J]. Computer Vision-ECCV 2018,2018:622-638.
[18] QIAO F C,YAO N M,JIAO Z R,et al. Geometry-contrastive GAN for facial expression transfer[EB/OL]. 2018:arXiv:1802. 01822[cs. CV]. https://arxiv. org/abs/1802. 01822.
[19] PANDZIC I S,FORCHHEIMER R. MPEG-4 facial animation:the standard,implementation and applications[M]. John Wiley & Sons,2003.
[20] KING D E. Dlib-ml:A Machine Learning Toolkit[J]. Journal of Machine Learning Research,2009,10:1755-1758.
[21] RONNEBERGER O,FISCHER P,BROX T. U-net:convolutional networks for biomedical image segmentation[J]. Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015,2015:234-241.
[22] MA L,JIA X,SUN Q,et al. Pose guided person image generation[C]//Advances in Neural Information Processing Systems,2017:406-416.
[23] ZHOU S C,XIAO T H,YANG Y,et al. Genegan:learning object transfiguration and object subspace from unpaired data[C]// Procedings of the British Machine Vision Conference 2017. London,UK:British Machine Vision Association,2017.
[24] ARJOVSKY M,CHINTALA S,BOTTOU L. Wasserstein gan[J/OL]. 2017:arXiv preprint arXiv:. 07875[cs. CV]. https://arxiv. org/pdf/1701. 07875. pdf.
