一种基于深度强化学习的SDN路由算法
2021-03-30丁怀宝
丁怀宝


摘 要: 为解决软件定义网络(SDN)中的流量工程(TE)问题,提出了一种深度强化学习路由(DRL-Routing)算法.该算法使用较全面的网络信息来表示状态,并使用一对多的网络配置来进行路由选择,奖励函数可以调整往返路径的网络吞吐量. 仿真结果表明,DRL-Routing可以获得更高的奖励,并且经过适当的训练后,能使各交换机之间获得更优的路由策略,从而增大了网络吞吐量,降低了网络延迟和数据丢包率.
关键词: 软件定义网络(SDN); 流量工程(TE); 奖励函数; 深度强化学习路由(DRL-Routing)
中图分类号: TP 312 文献标志码: A 文章编号: 1000-5137(2021)01-0128-05
Abstract: In this paper,a deep reinforcement learning routing (DRL-Routing) algorithm was proposed to solve the traffic engineering (TE) problem in software defined networking (SDN). The algorithm proposed made use of more comprehensive network information to represent the state,and adopted one-to-many network configuration for routing selection. Besides,the reward function was able to adjust the network traffic of the round-trip path. The simulation results showed that DRL-Routing could obtain higher rewards. After proper training,the agent could learn a more excellent routing strategy between the switches,which increased network traffic and reduced network delay and data packet loss rate.
Key words: software defined network(SDN); traffic engineering(TE); reward function; deep reinforcement learning routing(DRL-routing)
0 引言
随着Internet的不断发展,网络中的数据流量日益激增.尽管通过增加链路带宽和提高交换设备处理速度,可以暂时缓解网络流量增长的压力,但是这些并不能从根本上解决流量工程(TE)[1]中的吞吐量和延迟等方面问题.
传统路由配置中经常采用OSPF[2](Open Shortest Path First,开放式最短路径优先)算法和LL[3](Least Loaded,最小负载)路由算法,但这些算法无法满足如今越来越复杂和动态的网络,无法在具有动态流量分布的网络中找到最佳路由路径.
软件定义网络(SDN)[4]架构在数据收集、资源管理和路由优化等方面提供了许多新的解决方案.SDN控制器对整个网络进行集中控制,网络管理员可以根据自主定义的路由规则控制网络的转发流量,充当网络操作系统的角色.
本文作者提出一种深度强化学习路由(DRL-Routing)算法,以解决SDN的吞吐量和延迟等方面的问题.该方法可以调整从优化路径往返双向网络的吞吐量,有效减少网络拥塞的情况.
1 强化学习
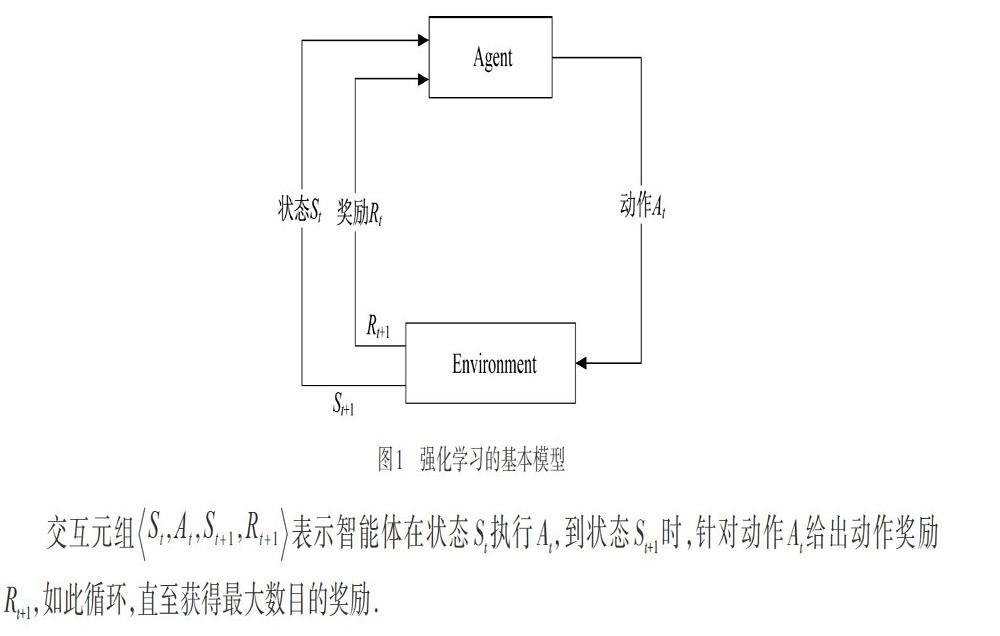
图1是强化学习[5]的基本模型.该模型中,只有兩个实体,即智能体(Agent)和环境(Environment).智能体在当前环境状态St执行一个动作At,环境从状态St转变到状态St+1,同时环境针对当前动作给出一个动作奖励Rt+1,智能体使用状态St+1和当前奖励Rt+1计算下一个动作At+1,然后算法如此循环,最终的目的是在整个决策流程中获得最大的奖励.
交互元组表示智能体在状态St执行At,到状态St+1时,针对动作At给出动作奖励Rt+1,如此循环,直至获得最大数目的奖励.
2 DRL-Routing概述
2.1 总体架构
DRL-Routing嵌入到典型的SDN架构中,该架构的应用层中包含:OpenFlow网络发现应用程序和 DRL-Routing应用程序.OpenFlow网络发现应用程序使用链路层发现协议(LLDP)[6]发现网络的数据平面拓扑结构.DRL-Routing应用程序包含两个主要功能模块.
1) 网络监控模块(NMM).该模块可以获取网络中的信息,包括:链路延迟、吞吐量、端口速度等,利用这些信息标识网络状态并计算奖励.大部分网络信息由控制器检索得到.
2) 动作转换器模块(ATM).该模块将智能体选择的动作转换为一组OpenFlow消息,以更新交换机的流表.在请求更新路径时,由路径上最后一台交换机将OpenFlow消息发送到第一台交换机,删除旧路径在交换机中的相应规则.
2.2 参数描述
DRL-Routing模型中的缓存中的元组表达式为M=,其中:S是状态集,集合了第t个时间段(Δt)内所有网络信息;A是动作集;R是奖励函数;T是动作转换概率;γ∈[0,1]是衰减因子.
4 实验分析
4.1 仿真环境
使用Mininet[8]平台建立包含一组虚拟主机、交换机和链接的环境,使用Ryu[9]作为OpenFlow控制器来管理网络,并使用Iperf[10]生成流量,检测DRL-Routing路由算法在Fat-tree,NSFNet和ARPANet三种网络拓扑上的性能.
4.2 算法执行
通过调用PDA函数对智能体进行训练,以经验驱动的方式尝试不同的取值,优化往返双向的网络吞吐量,当=1 s时,DRL-Routing算法在所有度量方面提供了最好的性能.经过训练之后的智能体已学习了路由知识,可以用于具体网络拓扑的实施.
4.3 实验结果
将DRL-Routing算法与传统的开放式最短路径优先(OSPF)算法、最小负载(LL)路由算法进行了比较,如表1所示.由表1可知:
1) DRL-Routing算法获得的奖励更高.例如,在ARPANet拓扑上,采用DRL-Routing算法获得的奖励之和为80.37,而采用OSPF和LL算法获得的奖励之和分别为45.02和31.50.
2) 在三种拓扑结构上,DRL-Routing算法的文件传输时间相对较少.例如,在NSFNet拓扑上,采用DRL-Routing算法,40 GB的文件平均传输时间为22.68 s,而OSPF和LL算法的文件传输时间分别为56.70 s和48.00 s,这是因为OSPF和LL算法都基于贪婪方法,不适用于流量不断变化的网络.
3) DRL-Routing算法在所有网络拓扑中均获得了较高的利用率.例如,在NSFNet上,采用DRL-Routing算法,平均利用率为0.44,而采用OSPF和LL算法,平均利用率分别为0.23和0.27.
5 结论
本文作者介绍了DRL-Routing算法的相关理论与运行机制,并将其运用于Fat-tree,NSFNet和ARPANet网络拓扑结构中.实验表明:DRL-Routing算法在三种常用网络拓扑结构上均获得了较高的奖励;可以较大程度地缩短文件的传输时间,显著改善用户体验;减少网络中被重传的数据包数量,大大减少拥塞路径的出现.
参考文献:
[1] AGARWAL S,KODIALAM M,LAKSHMAN T V.Traffic engineering in software defined networks [C]//IEEE INFOCOM.Turin:IEEE,2013:2211-2219.
[2] 张春青,张宏科.OSPF动态路由协议中的路由计算 [J].北方交通大学学报,2003(3):100-103.
ZHANG C Q,ZHANG H K.Routing calculation of OSPF dynamic routing protocol[J].Journal of Northern Jiaotong University,2003(3):100-103.
[3] LI L,SOMANI A K.Dynamic wavelength routing using congestion and neighborhood information [J].IEEE/ACM Transactions on Networking,1999,7(5):779-786.
[4] ZUO Q Y,CHEN M,ZHAO G S,et al.Research on OpenFlow-based SDN technologies [J].Journal of Software,2013,24(5):1078-1097.
[5] SUTTON R S,BARTO A G.Reinforcement learning:an introduction [J].IEEE Transactions on Neural Networks,1998,9(5):1054.
[6] 曾干.基于链路层发现协议(LLDP)的物理网络拓扑发现 [J].电脑知识与技术,2006(20):45-46,48.
ZENG G.The physical network topology discovery based on LLDP protocol [J].Computer Knowledge and Technology,2006(20):45-46,48.
[7] WANG Z,FREITAS N D,LANCTOT M.Dueling network architectures for deep reinforcement learning [C]//Proceedings of the 33rd International Conference on Machine Learning.New York:ACM,2016:1995-2003.
[8] 杨俊东,尹强,张硕.基于Mininet的SDN仿真与性能分析 [J].信息通信,2017(3):189-191.
YANG J D,YIN Q,ZHANG S.Simulation and performance analysis of SDN based on Mininet [J].Information & Communications,2017(3):189-191.
[9] ISLAM M T,ISLAM N,REFAT M A.Node to node performance evaluation through RYU SDN controller [J].Wireless Personal Communications,2020,112(1):1-16.
[10] ASADOLLAHI S,GOSWAMI B.Experimenting with scalability of floodlight controller in software defined networks[C]// International Conference on Electrical,Electronics,Communication,Computer,and Optimization Techniques.Mysuru:IEEE,2017:288-292.
(責任编辑:包震宇)
