基于GF-1号影像的南方水稻种植信息提取
2021-03-26李志鹏
林 娜,陈 宏,李志鹏,赵 健*
(1.福建省农业科学院数字农业研究所,福建 福州 350003)
我国作为水稻生产与消费大国之一,水稻信息提取与产量预测一直是学界与国家关注的重点[1]。我国南方是水稻种植与制种的主要区域,区域内地形复杂,多为丘陵和中低山地带,且作物种植结构多样,地块破碎程度严重。虽然多时相、多源遥感数据能提升作物的提取精度,但由于南方天气多云多雨,可利用的卫星数据很少,因此研究如何充分利用影像的多种特征构建合适的分类模型,从而获得较高的地物信息提取精度具有重要意义。
国内外学者在利用遥感技术提取水稻田信息方面开展了大量研究,取得了较好的成果[2-5]。由于常规的监督与非监督分类方法在作物识别方面有一定的局限性,因此众多学者纷纷从决策树分类、支持向量机、人工神经网络、面向对象[6-8]等其他领域引进分类技术,其中面向对象的分类方法在保持地物完整性上具有较大优势,且在分类过程中能充分利用影像对象的光谱、位置、形状、纹理等信息进行地物识别[9]。随机森林分类方法是基于机器学习的算法,具有分析复杂地物分类特征的优势和高度灵活性,借助自助抽样技术和节点随机分裂技术来构建多棵决策树,以投票的方式确定归属分类结果[10-11]。近年来,有些学者在随机森林分类方法中加入了面向对象技术,并在影像分类提取应用中开展研究,如孙杰[12]等基于城区机载LiDAR数据,提出了一种随机森林结合面向对象的特征选择与分类方法,对目标对象的几何、光谱、纹理等特征进行相关性评估与筛选,最后确定合适的特征进行城区地物分类;雷小雨[13]等利用两个时相的Landsat 8 OLI数据构建差值特征,再通过面向对象与随机森林分类相结合的方法提取了较高精度的水稻种植面积;张雯[14]等利用一种面向对象与随机森林相结合的方法对月球地貌进行了分类研究,分类结果基本吻合月貌实际情况,总体分类精度可达84.2%,Kappa系数为0.71。多项研究表明,面向对象与随机森林相结合的方法比传统单一分类方法的计算结果更准确,运行速度更快。
在目前南方水稻信息遥感提取的研究中,对于影像数据源充分的前提下遥感分类最优方法、最高精度的研究较多,而对于基于有限时相的中高分辨率国产影像的作物提取研究相对较少,对于面向对象随机森林遥感提取模型的研究也较少。本文旨在验证随机森林与面向对象相结合的分类方法用于国产高分卫星在单一时相上提取水稻田信息的识别效果,并深入分析了随机森林中的特征优选策略,评价了其分类性能,以期推进新方法在准确快速监测南方地区其他农情信息中的应用。
1 实验区域与数据来源
本文选取的研究区位于三明市建宁县溪口镇,地理位置为116°46′1″~116°48′59″E、26°51′55.07″~26°54′9″N,面积为20.59 km2。三明市建宁县是我国最大的杂交水稻制种基地县,县域内以丘陵和中低山为主,光照充足,水资源丰富,农业灾害少,有利于建设和发展水稻制种产业。
本文采用的实验数据为2015年9月17日GF-1 PMS2多光谱与全色遥感影像。该时段研究区天气少雨少云,影像质量较好,且晚制水稻处于灌浆期,在影像上呈现植被光谱特性和纹理差异性。数据预处理包括辐射定标、大气校正和正射校正,再采用Nearest Neighbor Diffusion Pan Sharpening算法进行多光谱与全色影像数据融合,最终获得空间分辨率为2 m的研究区遥感影像。
2 研究方法
本文以面向对象的随机森林分类算法为分类器,根据高分影像的光谱、植被指数、纹理、几何特征构建研究区遥感识别特征空间;再利用特征优选算法对特征空间中的所有特征进行优化选择;最后利用分类器对优选特征空间子集进行分类,达到高精度识别和提取研究区水稻信息的目的。本文技术路线如图1所示。
2.1 分类方法与实现
2.1.1 理论基础
随机森林算法是由Breiman L[15]于2001年提出的一种由多棵CART决策树构成的集成学习算法,具有精度高、运算速度快的优点。随机森林算法通过Boot-strap自助重采样法(随机有放回地选择样本)不断生成训练样本(约为原始数据的2/3)和测试样本(约为原始数据的1/3),再利用完全分裂的方式随机生成多棵CART决策树组成随机森林,且每棵决策树之间是相互独立的,最终结果由投票得到。然而,传统的随机森林算法是基于单像元进行运算的,分类结果较破碎,而面向对象的分类方法是基于高度同质化的影像对象,能有效保持地物的完整性,若能结合二者优势,将有利于提高复杂环境下影像的分类精度。
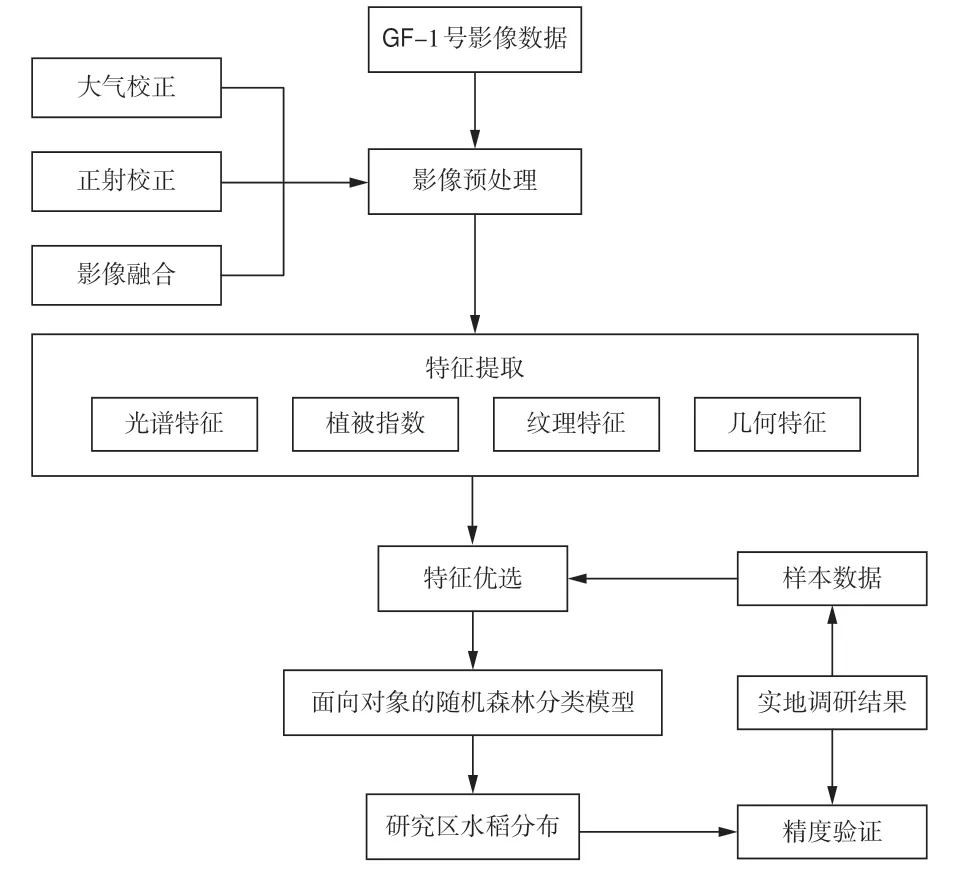
图1 技术路线图
2.1.2 影像分割
本文采用多尺度分割的方法进行影像分割实验。该方法采用自下而上的方式合并相邻像素以及较小对象,再进行分割,能最大限度地保证影像对象之间异质性最小、对象内部像元之间同质性最大[16-17]。考虑到水稻呈现明显的植被光谱特征以及种植集中、连片性好、地形平坦等区域特征,经过多次尝试发现,光谱参数为0.8、紧致度参数为0.6时,能得到相对较好的分割效果。在此基础上,本文设置了4种尺度参数(50、80、100、130)进行比较实验。结果表明,尺度参数为80时,分割效果较好,大部分对象斑块只包含一种地物类型。部分研究区分割对比结果如图2所示。

图2 不同分割尺度的效果对比
2.1.3 样本选取
基于研究区区域特征和水稻提取的需要,本文确定了水稻、林地、其他植被、裸露土地、水体和建筑用地6种主要地物类型。地物本底调查数据是基于高分辨率影像,采用目视方法解译地块边界,并结合地面调查对地块属性进行确认的方式获取,主要作为分割精度参考、分类的训练样本以及地物空间提取结果的精度验证样本。本文共选择具有代表性、典型性的样本区域136个,每个样区布设一个20 m×20 m的采集样方,其中水稻样区62个,形成样本集。
2.1.4 特征提取
综合考虑研究区地物的影像特点以及水稻种植分布特点等,本文选取光谱、植被指数、纹理和几何4种特征,其中光谱特征包括4个原始波段的均值、标准差、比率、亮度和最大差异;植被指数是区分不同植被最常用且有效的方法之一,本文采用比值植被指数(RVI)、差值植被指数(DVI)、归一化植被指数(NDVI)、土壤调节植被指数(SAVI)4种常见的植被指数;表征地物纹理信息的特征主要为灰度共生矩阵和灰度差分矢量;表达地物形状的特征包括长宽比、紧凑度、密度、形状指数和圆滑度,如表1所示。

表1 特征空间统计
2.1.5 随机森林分类
在训练样本数量一定的情况下,影响随机森林分类精度的参数主要为组成森林的最大决策树个数以及特征个数。针对最大决策树个数设置的研究表明,根据大数定理,当最大决策树数增加时模型泛化误差收敛,不用担心过训练的情况[18],因此本文将最大决策树个数设置为100。最大特征个数即每个节点处候选特征的个数,可根据袋外数(OOB)误差率进行调整[19]。为了确定随机森林的最优最大特征个数,将最大特征个数设为变量,以分析最大特征个数的变化对分类模型性能的影响,OOB误差率变化如图3所示。当最大特征个数为6时,OOB误差率最小,此时随机森林模型的精度最高。
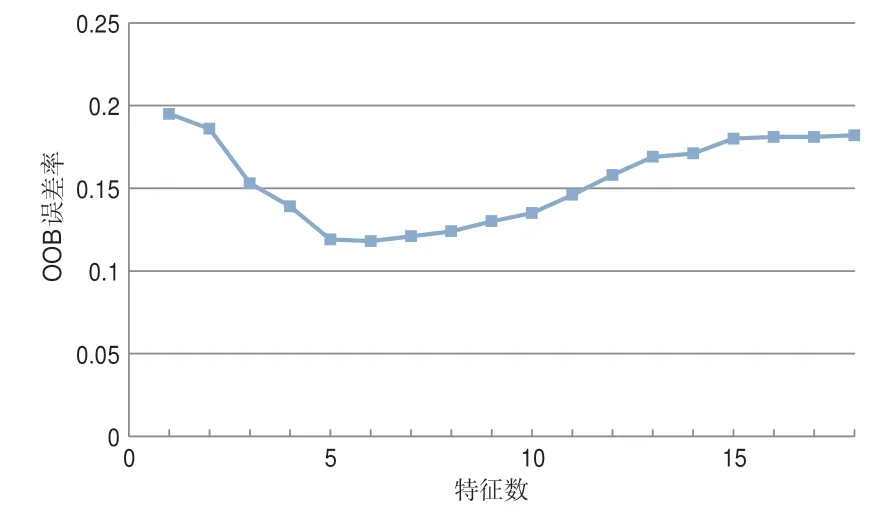
图3 OOB误差率随特征个数变化的趋势
2.2 特征优选方法
每种特征对影像分类都有不同程度的贡献率,但部分特征之间会呈现较大的相关性,若将大量的特征应用于分类器,则会增大计算量、降低分类精度和效率。本文采用特征空间优化(FSO)算法对提取的35个特征进行特征优选,并将最终确定的特征子空间应用于随机森林分类器中。FSO算法基于训练样本的各特征数值,结合特征组合分析,计算不同类别训练样本间的最大、平均、最小距离。分离距离随特征个数的变化情况如图4所示。选取重要性靠前的18个特征属性(Ratio_RED、Mean_NIR、GLCM_Homogeneity、Shape Index、Standard Deviation_NIR、Density、RVI、DVI、Roundness、GLDV_Ang.2nd moment、NDVI、SAVI、GLCM_Correlation、Compactness、Brightness、GLDV_Entropy、Ratio_NIR、GLCM_Entropy)构成特征空间组合(图5),此时的分离距离最大。

图4 分离距离随特征个数变化的趋势
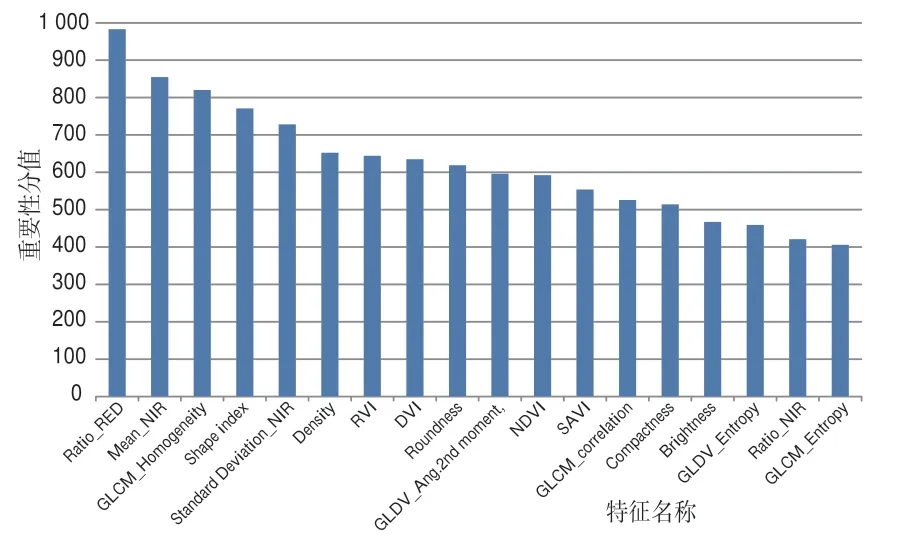
图5 优选特征重要性得分
3 研究结果与分析
3.1 特征优选分析
本文设计了4组实验方案,以验证基于优化后特征子空间的分类方法的有效性。实验A采用原始光谱特征;实验B采用光谱特征+植被指数特征;实验C采用全部特征集合,即光谱特征+植被指数特征+纹理特征+几何特征;实验D采用优化后特征子空间集合。部分研究区分类实验结果如图6所示。将各组提取结果与原始影像图进行对比可知:实验A、B均有部分林地错分为水稻田,实验C有部分水稻田错分为其他植被,而实验D分类结果较准确,错分和漏分现象少于其他3组实验。
3.2 结果分析与精度验证
为了反映基于面向对象的随机森林分类模型的分类效果,本文采用随机验证的方式,将分类结果与研究区调研结果以及高分辨率影像进行对比,得到研究区分类结果的混淆矩阵,获取分类总体精度、Kappa系数和水稻信息提取精度。精度评价结果如表2所示。

图6 分类实验效果对比

表2 精度评价
由精度分析结果可知,在研究区内实验D的总体分类能力最高,总体精度达到87 %,Kappa系数高于0.85,说明基于优化后特征子空间的分类方法具有较好的分类效果。通过4组实验的精度对比发现,分类精度结果实验D>实验C>实验B>实验A,说明只采用光谱特征进行分类具有一定的局限性;在实验B中加入植被指数特征、在实验C中又加入纹理与几何特征后,分类总体精度与Kappa系数均有所提高,说明不同类型特征对分类过程存在一定程度的优势互补作用,提高了分类精度;实验D基于特征优选,分类能力进一步提升,说明特征优选方法能消除部分特征之间的信息冗余,充分提高了不同类型特征对分类过程的贡献率。研究区水稻种植信息提取结果如图7所示,其水稻提取精度高达90.7%,满足提取精度要求。
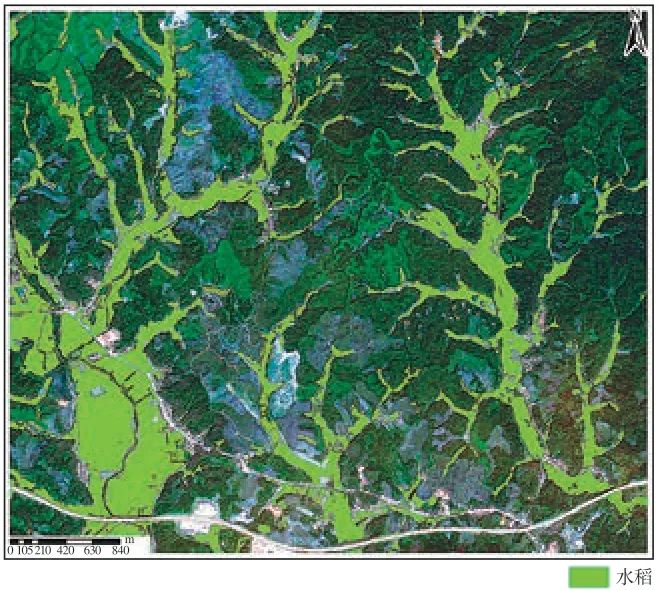
图7 研究区水稻种植信息提取结果
4 结 语
针对目前南方复杂地区水稻信息遥感提取研究中存在的分类特征和模型参数选择具有盲目性、单一时相分类精度不高的问题,本文基于GF-1号影像,首先通过特征优化方法对光谱特征、植被指数特征、纹理特征、几何特征进行优选,从而调整面向对象分割参数和随机森林分类模型参数,得到最优分类模型;再利用面向对象的随机森林分类算法实现了研究区水稻信息的高精度自动识别。该方法对于国产高分卫星影像在南方地区地物提取中的应用具有参考价值。
1)基于面向对象的随机森林分类算法在南方复杂地区水稻遥感提取应用中能得到较高的精度。
2)基于特征优选算法的分类模型计算特征少、实现简便,在保证水稻信息提取能力的同时,能有效降低数据处理量,提升水稻识别效率。
3)利用本文方法提取的水稻田信息会受水稻生长发育期的影响,分析分类结果发现,错误分类的水稻田较多受水稻生育期差异影响,后续可进行水稻不同生育期影像分类提取研究,进一步提高本文方法辨识水稻地块的准确率。
