目标检测算法综述
2021-03-26袁慧敏张绪红
袁慧敏,张绪红
(广东技术师范大学 自动化学院,广东 广州 510000)
1.引言
当今社会,图像处理已成为广泛的探索领域,主要包含以下几个方面:图像的数字化处理、图像的标准变换、图像的效果增强、恢复、分割、特征的识别等等[1]。本文主要讨论图像识别的相关内容,图像识别是指计算机视觉、自然语言处理以及AI的三大热点方向。目标检测和识别就是物体的检测识别。首先,检测是视觉感知的第一步,它可以在图像中搜索出某一目标,而目标识别可以理解为是图像的分类,用来确定在图像块中找到目标的具体类别。
计算机视觉的一个重要任务是目标检测,主要用于在数字图像中检测特定类别的视觉,判断图像中有没有来自给定类别(如植物,动物,交通工具等等)的对象实例,目标检测是复杂或高级视觉任务的基础,如图像分割、目标跟踪、事件检测和活动识别[2]。广泛应用于物体表面的缺陷检测、人脸检测、行人检测等领域。当今时代,深度学习技术的发展渐渐成为主流,人们广泛关注于基于卷积神经网络的目标检测算法,出现了很多结构简单,运行效率高的网络模型,使得这些算法能得到大规模应用,然而对于目标检测的难点,国内外的研究者们提出了很多解决方案并做了大量尝试。比如,Itti等人构建了选择性注意机制来提取图像中的显著区域[3];Viola和Jones等提出级联检测器框架并成功应用于人脸检测[4];Navneet 等人则提出Hog和SVM结合使用的思想,Hog被用来进行图像特征提取,线性SVM被用作分类器,从而实现行人检测[5,6];Felzenszwalb等人提出一种基于部件的检测方法DPM,对目标的形变具有很强的鲁棒性[7-9]。不过在经历了许多年的研究发展之后,最先进的目标检测系统已与多种不同的技术组合在了一起,例如多尺度检测,上下文启动,边界框回归等[7]。
本文第二节对目标检测流程进行了介绍,第三节主要针对目标检测算法的种类及其结构进行介绍,最后一节提出了对算法的展望。
2.目标检测的基本流程
目标检测主要涵盖了两个主要部分,目标位置确定和目标分类任务,它使用图像处理方法,机器学习和其他多方向知识从图像中定位感兴趣对象[10],其中待检测区域候选框的特征提取和候选区域的特征识别是检测过程中的难点,目标检测流程的具体思路如图1所示,大致分为三个主要步骤,分别是图像的区域选择、图像的特征提取和图像分类,接着就是对图像进行边框回归,对获得的结果进行优化,最后完成目标检测。首先,对图像中可能的目标位置提议,提出一些可能包含目标的候选区域,然后使用适当的元素模型来获取元素的表示,最后一步是使用形如支持向量机一样的图像分类器来判断特定的目标类型有没有包含再每个区域当中,并通过一些后处理操作,例如NMS,边界位置回归等[11]进行完善。

图1 目标检测的基本流程
3.目标检测算法
3.1 算法的种类
一般认为,目标检测的发展历程大致经历了两个关键的时期,我们把这两个时期称之为是基于传统方法的目标检测时期和基于深度学习的目标检测时期[12],图2向我们展示了目标检测算法的分类。

图2 目标检测算法种类
本小节中我们主要讨论的是与深度学习相关的目标检测算法,主要分为两类,一阶段和两阶段。前者首先通过算法生成一系列候选框作为样本,然后通过卷积神经网络对样本进行分类,比如R-CNN算法、Fast R-CNN算法、Faster R-CNN算法等。后者则省去了生成候选帧的步骤,直接将目标帧的定位问题转化为回归问题进行下一步的处理。
3.2 R-CNN算法
R-CNN算法是Ross等人在2014年提出的基于区域的卷积神经网络方法,已成为基于区域提议的典型识别方案,全名是Region-cnn,它的伟大之处在于它是第一个将深度学习方法应用于目标检测中的算法[14]。以前,大多数传统的目标检测方法都是基于图像识别,通常是通过在图像上使用一一列举的方式来选择对象所有可能的区域范围,并且可以通过使用图像识别方法来提取和分类这些区域框的特征,在获得所有成功分类的区域后,通过非极大值抑制(NMS)输出结果。

图4 Fast R-CNN结构
快速R-CNN的网络结构如图4所示,它的输入主要由两部分组成,首先将想要处理的图像送入到卷积神经网络当中;其次是形成一组建议区域,我们把这组区域称之为候选区域。
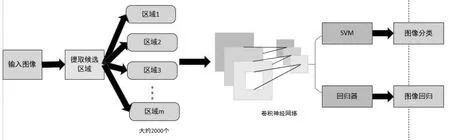
图3 R-CNN结构
R-CNN[15]背后的思想很简单,依然参考了传统的目标检测算法的思想,先进行候选区域的提取,提取完成之后再对每个候选框提取显著的特征,再进行分类以及后续处理等等。具体如图3所示,在提取特征这一步,算法通过选择性搜索方法[18]提取一组对象候选框,大约生成两千个候选区域,然后每个提议被重新调整为一个特定大小的图像,再送到一个在ImageNet上训练的卷积网络模型中以提取特征。这里所讲的卷积网络模型架构我们有两个可选方案,第一是选择经典的Alexnet网络[16];第二选择VGG16网络[17],VGG网络模型具有卷积核小、跨度小且网络精度高的优点,不足是计算量太大。可以根据需要进行选取,选好网络模型后使用线性支持向量机分类器预测每个区域内对象的存在并识别对象类别。
3.3 Fast R-CNN算法
Fast R-CNN的提出者Girshick由于受到R-CNN和SPPNet的启发,在2015年提出了Fast R-CNN 目标检测算法,首次实现了端到端(end-to-end)训练,该算法采用了很多的创新技术来同时提高训练和测试速度以及检测精度,与R-CNN相比,经过非常深入的Fast R-CNN训练的VGG16网络使得存储空间也大大减少,而且相对于R-CNN运行的速度也有较快提升,因此被称为Fast R-CNN,也即快速R-CNN。该算法要处理的第一步是要获取卷积特征图,但是因为提取出的候选区域数量较多,系统必须要对其筛选出感兴趣的区域(ROI)。RoI池化层是空间金字塔池化层(SSP)的特殊情况,它可以从特征图的映射当中提取一个固定长度的特征向量。这些固定长度的特征向量都会被输送到全连接(FC)层序列中,这个全连接层在同一层被分成两个输出层,其中一个输出层的作用是进行图像的分类,对目标关于K个对象类(包括全部“背景”类)输出每一个感兴趣区域(ROI)的概率分布,也就是产生softmax概率估计,分类的损失函数如(1):

另一个输出层是为K个对象中的每一个类别输出4个实数的值(bbox回归),说你是函数如式(3):
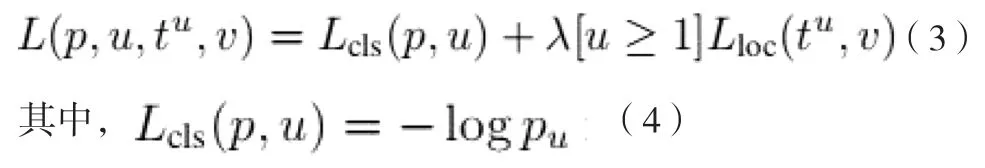
每四个值编码每一个K类的精确边界框位置,整个网络结构的端到端训练是利用多任务损失来进行的[18]。
3.4 Faster R-CNN算法
2015年,Kaiming He, Ross Girshick等人提出了著名的Faster R-CNN算法,这种方法至今仍是精确度最高的算法之一,它相比于以前众多算法的一个创新点就是该算法利用了一个小型的区域提议网络(RPN,Region Proposal Network)取代了之前传统的选择性搜索算法(SS)[19,20],这个新的提议网络大量减少了提议框的数量,从而提高了图像的处理速度。更快 R-CNN算法的总体结构大致由两个模块所组成,第1个模块是构建出区域的深度全卷积网络,第2个模块是利用该区域的快速R-CNN检测器。更快的R-CNN是第一个端到端的,也是第一个接近实时的深度学习检测器。具体的结构如图5所示:
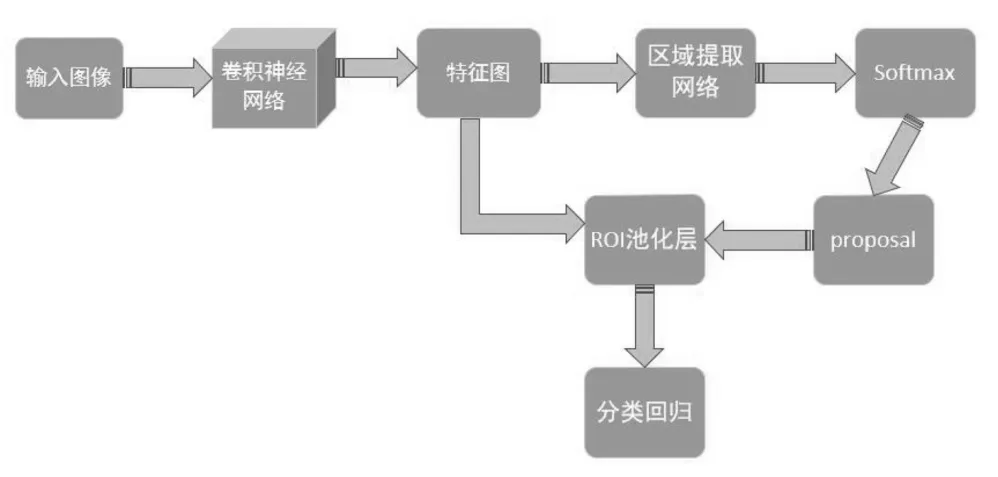
图5 Faster R-CNN结构图
首先,先将自己要测试的目标图像进行输入,输入到一个卷积神经网络当中目的是想要提取图像的各种特征,之后利用小型的区域提议网络RPN来产生许多个锚盒,对这些锚盒进行筛选之后再使用Softmax分类器来对它们进行分类判断是属于前景还是属于后景,我们可以把这称为是一个两分类的问题,与此同时另一条分支是通过边界框回归来修正锚盒,再把建议窗口映射到卷积网络的最后一层特征图上,通过感兴趣区域池化层生成固定尺寸的特征图,最后再利用Softmax Loss(探测分类概率)和Smooth L1 Loss(探测边框回归)对分类概率和边框回归进行联合训练[21]。
3.5 SSD算法
SSD算法是Single Shot MultiBox Detector的缩写,中文名是单点多盒检测器,是Szegedy等人在2016年提出。该算法将边界框的输出空间离散化为默认框,这些默认框在每个特征图的位置上具有不同的大小和高宽比。在预测期间,该网络为每个默认框产生该框属于每种物体类别的分数,同时调整边界框使得它更能匹配物体的形状。另外,为了自然地处理大小不同的目标,该网络把多层不同分辨率的特征图都结合在一起。
SSD算法是一个基于深度卷积神经网络的检测器,无需重采样像素或者假设框的特征,跟那些需要这些步骤的方法达到了同样的精度。这使得该网络在速度上有很大的提升,而且有很高的检测准确率。
图6是SSD算法的网络结构,该方法基于一个前向卷积网络,产生一个固定大小的边界框集合和在这些边界框里各目标类别出现的分数,随后采用一个非极大值抑制步骤产生最后的检测结果。基础网络使用了VGG16的网络结构,然后通过对基础网络的改进,增加了几个不同大小的卷积层来进行不同尺度特征图的提取,在提取不同特征图的方法上主要通过下采样的方式进行尺寸的变化[22]。所谓的预测网络还包括prior box层的提取过程,也等同于R-CNN中的锚盒。提取过程以特征图的每个单位点为中心,通过等比法求出其在原始图像中的位置,并以该点为中心提取各种边界框,每一个prior box都会分别预测相应的类别概率和坐标值。每个特征图中的点都会对应不同的prior box。
3.6 比较
通过以上介绍,我们了解了不同算法的网络结构,下面针对这几种算法的运算速度、训练精度、不足等进行一个比较,具体内容如表1所示。
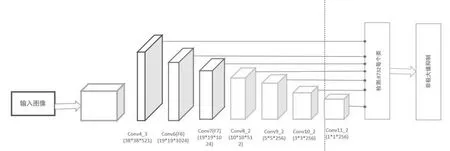
图6 SSD结构
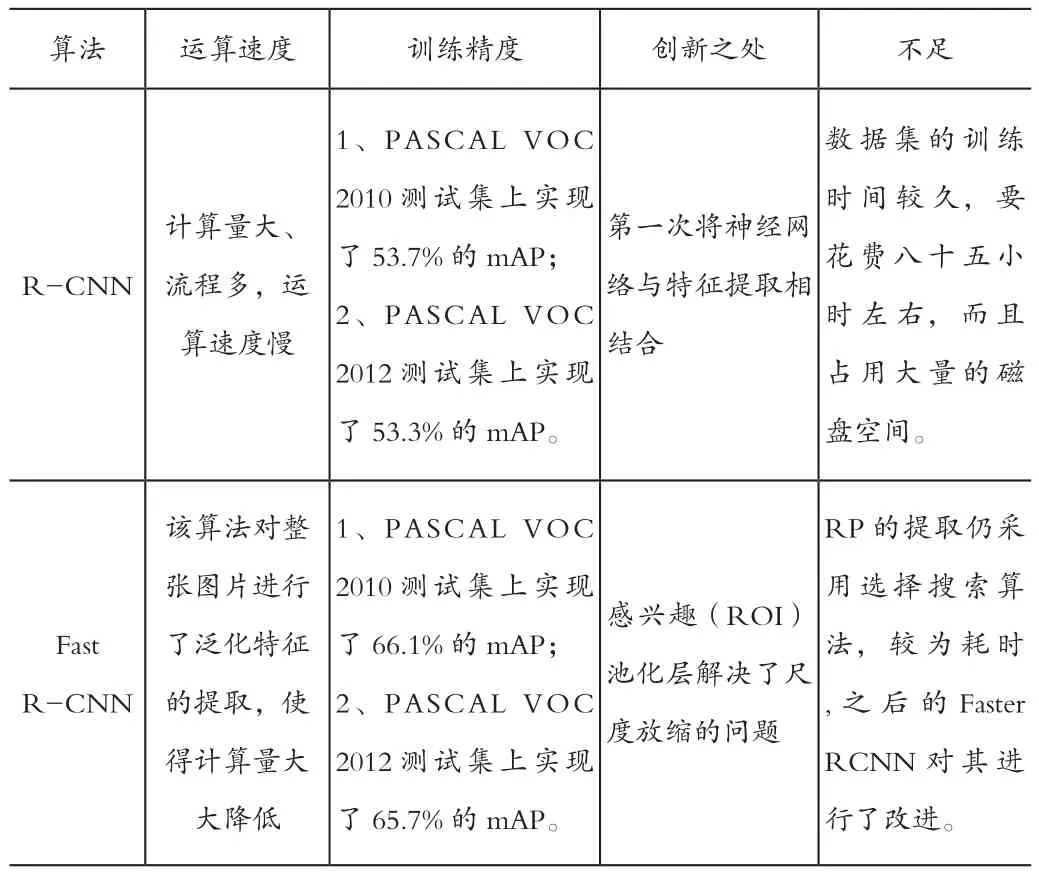
表1 算法比较

Faster R-CNN计算量较大,速度较慢1、PASCAL VOC 2007测试集上实现了 69.9% 的 mAP;2、PASCAL VOC 2012测试集上实现了67%的mAP。1、实现端到端的目标检测框架;2、 采 用RPN网络加快了建议框的生成速度。无法达到实时检测目标的效果,获取区域提议,再对每个提议进行分类的计算量还是比较大。SSD运行速度快,训练的精度超过Faster R-CNN 1、PASCAL VOC 2007的SSD300中07测试集上实现了68%的mAP;2、PASCAL VOC 2012的SSD300中07++12测试集上实 现 了72.4%的mAP。消除了提议生成和随后的像素或特征重采样阶段,并将所有计算封装在一个单一的网络中。1、需人工设置默认值的初始尺度和长宽比的值;2、网络中每一层 特征使用的默认值大小和形状都不一样。
4.展望
本文系统的阐述了近这几年来目标检测领域的研究进展,随着强大计算设备的不断升级,基于深度学习的目标检测技术得到了迅速发展,是目前目标检测领域的一项里程碑。目标检测至今仍然是计算机视觉领域中人们感兴趣的话题,虽然单级和二级的目标检测算法都取得了令人满意的效果,但是每个算法还是各有所长,很难有一个算法既可以实现精度的要求又能满足速度的加快,也就是说每个算法之间都是互补的,各有利弊。其次,对于是否广泛的应用于真实场景下还有一段距离,目前技术来看实时性还不够强,所以目标检测这一基本任务仍然是非常具有挑战性的课题,有很大的发展空间。
