基于区块链的精准扶贫数据保护方案
2021-03-24张利华王欣怡白甲义张赣哲
张利华,黄 阳,王欣怡,白甲义,曹 宇,张赣哲
1.华东交通大学软件学院,江西南昌330013
2.华东交通大学电气与自动化工程学院,江西南昌330013
精准扶贫作为政府的第1 民生工程,是决胜全面小康的一场攻坚战。2014年以来,精准扶贫工作在政策上愈发完善,在方式上愈发创新。扶贫数据作为扶贫事业中积累的独特资源,如何将其精准记录并加以有效整合是影响这场攻坚战成败与否的重要因素。
在“互联网+”大背景的烘托下,人们大规模地运用数字化手段对扶贫数据进行处理,虽然具有简便快捷的优势但也存在以下问题:1)数据缺乏结构化,不利于分析;2)数据经数字化处理后增加了被篡改的风险;3)缺乏安全高效的共享渠道,导致各个扶贫工作的权威机构仍处于孤岛状态;4)数据的可追溯性不强,无法明确相关责任;5)解决数据处理过程中隐私保护问题的方案还不够完善;6)中心化的数据库存在深层次的安全隐患等。
作为一项创新性的技术,区块链本质上是一个分布式的数据库,具有去中心化、防篡改、公开透明等特性[1]。结合星际文件系统(inter-planetary file system,IPFS)、数字签名、安全多方计算(secure multi-party computation,SMPC)等技术理论,研究了一种基于区块链的精准扶贫数据保护方案,具体思路如下:
1)各个管理扶贫数据机构组成联盟链,并作为权威节点担负管理维护的职责,同时联盟链上的数据以快照信息的形式与公有链锚定。
2)扶贫数据以数字档案的形式存在,只有经本人授权才能解密。源数据通过链下的私有IPFS 集群加密存储,而数字档案的摘要信息则存储在链上,两者配合实现数据的新增、更新、验证、溯源和共享等功能。
3)联盟链采用的是基于节点综合性能的Raft 共识算法,将各节点的性能、可靠性、地区影响力等因素作为综合性能来解决存储和数据处理效率的问题。
1 相关工作
目前,在精准扶贫数据的处理和保护方面已有很多相关成果。文献[2] 利用大数据技术对各地脱贫攻坚工作中产生的数据进行挖掘分析,以数据呈现、联合分析等方式实现精准扶贫的可视化。文献[3] 基于Hadoop 架构的精准扶贫大数据系统设计方案,利用FP-Growth(frequent pattern-growth)算法实现精准扶贫数据的深入挖掘。
区块链作为新兴技术,在众多领域都发挥着关键作用。在数据保护与共享领域,文献[4]基于区块链构建了去中心化的医疗数据访问管理系统,使患者对数据有自主分享的权利。文献[5] 利用IPFS 和智能合约对物联网设备数据进行储存管理,虽然实现了数据保护,但采用的是公有链和公有IPFS 集群,不但成本较高而且存在一定的安全隐患。文献[6] 提出了基于区块链的医疗数据共享模型,却依旧没有解决数据中心化存储的问题。
在隐私保护领域,文献[7] 利用采集基站搭建联盟链,保障了数据安全存储,但受制于资源、架构,物联网技术而难以兼容其他安全技术。文献[8] 提出一种基于区块链的数据网关架构并引入了SMPC,使第3 方用户能在不侵犯患者隐私的情况下计算并存储数据。文献[9] 同样将区块链与物联网相结合,在增强物联网联系的同时提供了安全的技术保障。文献[10] 利用智能合约设置不同场景下的不同访问权限,实现了数据动态共享,保障了用户的隐私安全。文献[11] 结合区块链和数据脱敏技术提出了一种电子病历安全共享模型,凭借部分数据的准确性解决了隐私保护问题。
在数据溯源领域,文献[12-13] 分别利用区块链技术搭建了数据溯源框架,但更强调对用户ID 的隐私保护。文献[14] 结合区块链技术和IC 芯片卡提出一套防伪方案,但并未解决防伪信息泄露问题。文献[15] 借助区块链与大数据技术提出了基于区块链的射频识别(radio frequency identification,RFID)大数据溯源模型,在RFID 溯源的各个环节建立区块链账本以实现大数据的安全管理,但同样忽略了数据的隐私保护问题。文献[16] 将区块链技术引入精准扶贫数据保护,开发了基于区块链的精准扶贫系统,但更多的是侧重于系统的设计。为此,本文在数据层面上引入区块链技术,从而达到数据保护的目的。
2 整体架构
2.1 系统模型
如图1所示,精准扶贫数据保护方案的系统模型由以下四部分构成:

图1 系统框架Figure 1 System framework
1)权威验证机构(authoritative certification authority,ACA),如政务部门、学校、医院、银行等之间构成的联盟链,采用改进后的基于节点综合性能的Raft 共识算法,通过智能合约存储权威机构数字身份和档案的摘要信息。ACA 享有档案保护、管理、共享、获取等服务。
2)RESTful Operate 是去中心化应用(decentralization application,DAPP)程序,本身不存储任何档案数据和身份信息,而是通过Web 为精准扶贫数据保护系统提供智能合约和调用接口。
3)公有链采用基于权益证明(proof of stake,PoS)共识算法,以定期锚定数据快照的方式为联盟链上的数据提供保护。
4)私有IPFS 集群存储了加密档案的原始信息,采用分布式哈希表、比特流等技术保障了数据的安全性。
2.2 智能合约体系
智能合约是一种允许在第3 方不参与的情况下以代码方式形成、验证或执行合同的计算机协议[17],它支持多样化的实际应用,能满足链上数据不可更改的需求[18]。本方案的合约体系分为两大部分,如图2所示。其一是公有链中区块数据验证合约(block data verify contract,BDVC),用于存储数据快照并定期比对;其二是联盟链中的区块数据保护合约(block data protection contract,BDPC),包括身份控制合约(identity controller contract,ICC)、数据管理合约(date manage contract,DMC)。
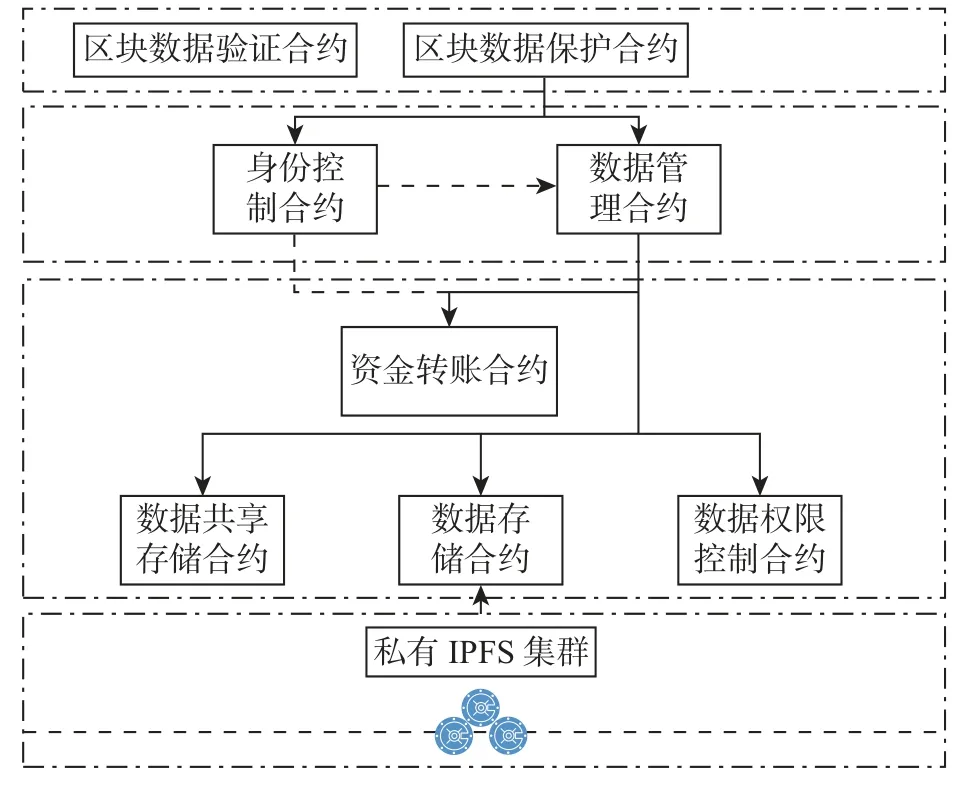
图2 智能合约框架Figure 2 Framework of smart contract
ICC 作为全局合约管理所有ACA 的数字身份标识(authoritative certification authority-ID,ACA-ID)、对应的公钥(PubKey)及对应的钱包账户。创建ICC 的同时也一起创建DMC与ACA 的数字身份。
DMC 用于实现扶贫档案的保护、验证、恢复、共享和钱包等功能,包括数据存储合约(data storage contract,DSC)、数据共享存储合约(data sharing storage contract,DSSC)、数字身份授权合约(data identity authority contract,DIAC)和资金转账合约(fund transfer contract,FTC)。
DIAC 合约用来验证ACA 的身份;DSC 合约则用于存储档案的属性信息,如数字档案对象的IPFS 地址等;DSSC 合约用于存储权威机构间分享的档案信息,包括档案标识(document-ID,Doc-ID)、ACA-ID 和分享时间等。FTC 是基于SMPC 来搭建的,可以解决敏感的资金问题,由合约ICC 和DMC 调用。
3 方法设计
精准扶贫数据保护是通过公有链、联盟链、IPFS 私有集群来完成的,其中数据以档案的形式保存。ACA 利用智能合约将数据的摘要信息等存储在链上的DSC 合约中,而完整的源数据则存储于链下的私有IPFS 集群,数据档案对象是JSON 形式的档案信息组织结构。本文利用联盟链的信息定期与公有链快照信息比对的方式来保证数据的完整性。
本文方案包括以下功能:数据新增与更新、数据共享、数据验证、账户资金重构。
3.1 数据新增与更新
数据档案新增步骤如下:
步骤1贫困用户(以下简称用户)首次访问ACA 会生成一对随机的密钥key,此密钥由用户自己保存。
步骤2ACA 通过RESTful Operate 向IPFS 集群发送请求,获得一个空的存储地址
步骤3提取档案Files 属性,将档案编号Doc-ID、版本号、创建时间、操作管理员、及档案Files 哈希值一起合并生成Filesattrs。
步骤4ACA 用密钥key 对档案Files 进行加密,与步骤3 中生成的Filesattrs一起生成档案对象DOCJSON,DOCJSON 经过二次加密储存到步骤2 生成的IPFS 地址中。
步骤5ACA 利用身份标识ACA-ID、档案对象哈希值、Filesattrs的私钥进行签名,通过RESTful Operate 发送至合约DMC 处理。
步骤6DMC 合约收到新增档案请求后,调用ICC 合约中的公钥信息和ACA-ID,然后DIAC 用公钥对签名进行解密,得到ACA-ID、、Filesattrs。比对ACA-ID 和DOCJSON 的哈希值,若身份检查通过,则在合约中存储Filesattrs,并完成Doc-ID、Filesattrs映射。
算法1Saving of Data

档案更新操作步骤与新增类似,不同之处在于:贫困户不用在ACA 重新生成key,而是根据Doc-ID 通过智能合约取出DOCJSON,并以用户提供的key 解密后更新档案。
3.2 数据共享
档案的共享步骤如下:
步骤1权威机构A(ACA-A) 以私钥SK-A 对待分享档案编号Doc-ID、身份标识ACAID-A、目标机构ACA-ID-B 等信息进行签名,并通过RESTful Operate 发送到合约。
步骤2DSSC 合约收到请求后,先用DIAC 对合约ICC 中ACA-A 的公钥信息和ACA-ID-A 的签名进行比对,比对无误后将ACA-ID-B 添加至Doc-ID 对应的分享列表。
步骤3权威机构B(ACA-B) 同样利用私钥SK-B 对档案编号(Doc-ID) 和标识(ACAID-B) 等信息进行签名,通过智能合约进行身份检查。若检查通过,则返回档案属性,抽取相关地址对应的哈希值。
步骤4ACA-B 从IPFS 集群中获取加密的档案对象,并通过用户对象提供的密钥key进行解密,获得信息。
算法2Sharing of Data

3.3 数据验证
数据验证分为两部分:首先是公有链根据链上快照信息对联盟链的数据进行验证,其次是联盟链对IPFS 集群中的数据进行验证。
ACA 对身份标识ACA-ID 和目标数据的档案编号Doc-ID 等信息进行签名,RESTful Operate 收到请求后调用公有链合约BDVC,获取最新的区块快照信息进行当前联盟链数据比对,若不一致则返回联盟链的数据异常。若一致,则继续将签名发送给智能合约DSC,合约收到请求后调用DISC 对ACA 的身份进行验证,然后通过Doc-ID 找到存储在链上的档案属性Filesattrs,抽取其中的通过从IPFS 中获取DOCJSONCiphertext,通过用户的密钥key 解密得到DOCJSONPlaintext,并与比对,若不一致则返回IPFS 数据异常。
在数据验证过程中,若出现数据异常情况,则可以根据不同情况回溯。当联盟链数据异常时,可以通过信息的比对来定位出异常区块的高度,并重新创建区块;当IPFS 数据异常时,可以通过Filesattrs回溯到正确的版本。从安全性和花销方面考虑,除了由所有的ACA 组织的集体验证外,每一次对数据更新前都要验证历史版本,并将验证结果写入Filesattrs,方便数据的回溯。
算法3Validation of Data

3.4 账户资金重构
资金转账合约是基于SMPC 搭建的。权威验证机构如银行、基金,可给每一份贫困账户进行资金转账,由权威机构直接创建交易。以官方账户Alice 向对象账户Bob 转账为例,假设Bob 账户余额为Bob.Val,账户Alice 给账户Bob 的转账金额为X,具体转账过程如下。
首先在FTC 引入了一个可信方Dealer[19],它在执行过程中只是扮演验证和通知的角色,而不会参与合约的计算,故不影响智能合约的公平性。执行过程经历4 个阶段:1)初始化,先验证双方身份,再征集节点,最后创建环境;2)秘密共享,官方账户Alice 的动作是转账金额X,对象账户Bob 的动作是收款,即X+Bob.Val;3)计算节点进行计算;4)两个账户对秘密进行重构。合约算法如下。
算法4Fund transfer contract(SMPC)


4 共识机制
联盟链采用改进后的Raft 一致性算法作为共识机制。首先对于Raft 共识算法来说,全节点的选举意味着部分中心化,具有比其他共识机制更好的数据处理能力;其次联盟链由各地区、各类不同功能的权威机构组成,节点忠诚性问题的概率比发生故障的概率小得多,可见故障节点出现的概率远大于作恶节点出现的概率。Raft 容忍故障节点的能力为(N −1)/2,其中N为集群中总的节点数量,可以满足实际需求。
共识机制的主要思路是以节点的存储证明和时空证作为共识算法,以节点的地区影响力等因素作为标准,通过比对综合性能选举出全节点。
4.1 存储证明、复制证明及时空证明
存储证明、复制证明和时空证明是整个共识机制的核心要点。存储证明是矿工对于自身存储空间的证明,是获得权利的前提;复制证明(proof of replication,PoRep)是权益证明PoS 的一个实际形式,用以证明数据可由矿工独立保存;时空证明(proofs of spacetime,PoSt)则是矿工在一定时间内持续地生成复制证明和接受挑战、验证的过程。
4.1.1 存储证明
存储证明是每个存储矿工为网络提供的有效存储空间占比,且任意一个节点都可查阅并且验证其他所有节点的存储算力。存储算力可以定义为

式中,n为全部网络矿工数量,ptj为t时刻矿工的挖矿能力。
这样定义存储算力主要考虑了以下几个特点:
1)存储率计算透明,矿工存储率和全网存储率是公开的,且任何时刻都可通过区块链查看。
2)可验证性,矿工在特定时间段内需要生成存储证明,以便验证存储算力的合法性。
3)灵活性,矿工不但能简便地提交存储算力,而且能随时以提高自身存储空间的方式增加自身算力。
4.1.2 复制证明
证明者P受到网络委托,存储n个数据D的独立备份;当检验者V向P提出挑战时,P需要向V证明确实存储了一个备份。这就是PoRep 一次验证的过程。
存储证明共识机制的角色和过程可以抽象成挑战者、证明者、检验者。它们可以是矿工、用户或者任何网络内的其他角色。涉及的定义如下:
1)挑战
系统对矿工发起提问,可能是一个问题或者一系列问题。若矿工能正确答复,则挑战成功,否则失败。
2)证明者
证明者一般指矿工,向系统提供能完成挑战的证明。
3)验证者
向矿工发起挑战,从而检测矿工是否完成了数据存储任务。
4)数据
用户向矿工提交的需要存储或者矿工已经存储的数据。
5)验证
矿工完成挑战时的回答。
4.1.3 时空证明PoSt
每间隔一定的区块高度,矿工需要提交一次存储证明来验证合法性,这需要网络的大部分存储算力。每一个新区块生成,都会更新当前分配表,包括新的存储任务、删除的过期任务等。存储时空证明容量Mtj即t时刻矿工的挖矿能力,只需查询并验证分配表中的记录即可。
如图3所示,挑战者在PoRep 循环重复执行i轮,输入一个随机挑战参数c,通过循环次数i生成一个新的挑战;以此找到一条能够到达默克尔根的默克尔路径,并生成当前时刻的证明;再由上一轮生成的证明去生成新的挑战,进而生成当前的矿工证明,反复迭代t次,将这个过程生成的证明序列全部交给检验者。经过时间T后将最后一次结果作为PoSt 的证明,接受反向验证。
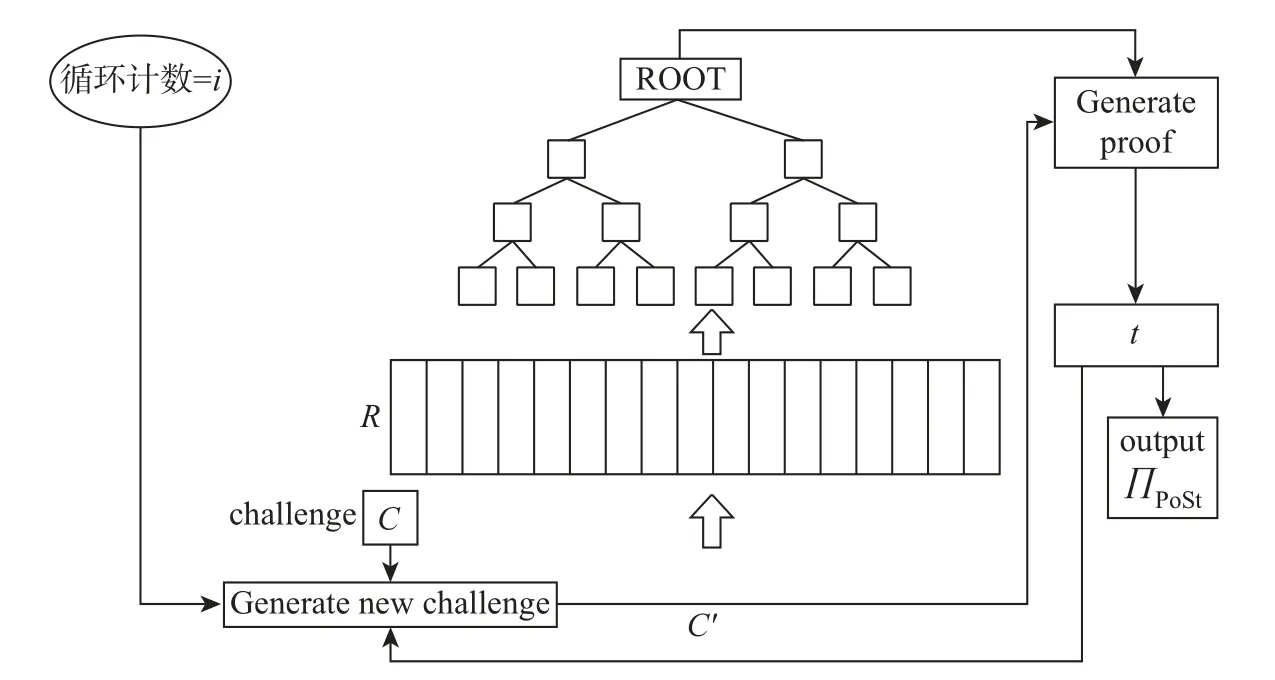
图3 时空证明流程图Figure 3 Flow chart of spatiotemporal proof
PoSt 实际上是在一段时间内间隔生成的一系列PoRep 的证明。针对PoSt 和PoRep 的实现过程基本相似,但在证明生成环节中是不同的。生成证明并非一次结束,而是需要反复迭代的。
4.2 全节点选举
全节点就是领导节点。根据网络分片的原理将区块链网络划分为若干分片,并在每个分片中选取一个全节点,让其担任该分片内领导的角色。以往的方案存在负载均衡性和节点可靠性问题。
1)负载均衡性
让所有的节点按照一定时间间隔轮流充当全节点,则所有节点都处于同一地位,就不存在恶意篡取全节点的弊端,但没有考虑到各节点在硬件性能、存储能力、稳定性、可信度方面的差别,造成存储负载不均衡的问题。
2)节点可靠性
在实际方案中,综合性能高的节点可能存在可靠性不足的问题。这种节点可能不为系统提供存储能力,甚至恶意充当女巫节点来破坏系统,以致降低系统的存储效率。
除此之外,在实际应用场景中还应将节点的地区影响力作为加权标准。综上所述,全节点的选择要考虑三方面:节点性能、可靠性以及地区影响力,只有这样才能让系统的存储性能达到最优。
4.2.1 节点性能计算
节点性能(node performance)由存储容量(storage)、CPU 性能、GPU 性能、磁盘I/O速率、内存大小、带宽速率这些因素共同决定。本方案根据实际工程方案中的加权求和对节点性能进行计算

式中:P(Nodei) 表示节点的性能;S为节点的存储量;Ci表示CPU 的性能;Gi表示GPU的性能;Di为磁盘IO 的读取数据的速率;Mi为内存大小;Bi为网络的带宽;ki为加权值,即对节点性能的影响因子。
4.2.2 节点可靠性计算
当本方案中所有节点为系统提供存储算力时,系统都会给出节点的可靠性评价Ei,且Ei ∈[0,1]。随着时间的推移,可靠性评价会随着时间而衰减。
参考实际工程可将时间对可靠性的影响表示为T(Ei)=e−|tnow−tm|。其中,T(Ei) 表示时间衰减程度,tnow为当前时间,tm为系统对节点的评价时间。这样节点i的可靠性可表示为
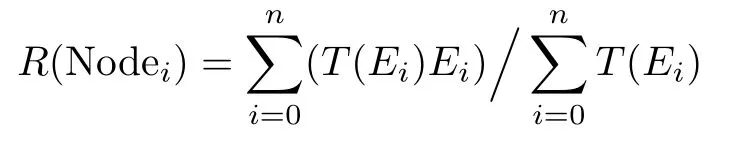
4.2.3 节点综合性能计算
在本方案中,全节点的综合性能既要考虑节点性能又要考虑节点的可靠性,则综合性能的公式为
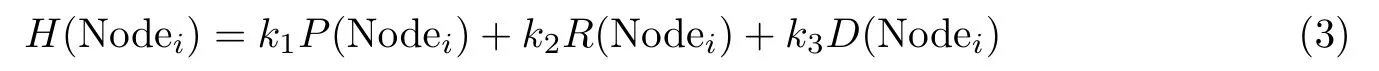
式中,H(Nodei) 表示节点的综合性能,k1、k2、k3分别表示节点性能、可靠性、地区影响力对综合性能的影响因子。本文将分片内的节点进行综合性能的排行,选择出综合性能值最高的节点作为分片内的全节点。在实际项目中,可能会出现综合性能值相同的节点,此时将可靠性值最高的节点选为领导节点。
基于节点综合性能的Raft 共识机制将分片中节点综合性能的算力进行排行,根据算力的排行次序选出领导节点和候选人节点。领导节点为所处分片中其他节点安排存储等资源,候选人节点则作为领导节点的备份节点。当领导节点突然掉线或者遇到一些突发情况而不再工作时,候选人节点立即成为新的领导节点。
4.2.4 共识机制的实现
在共识机制中,所有节点提供自己的存储算力。存储算力越大的节点被作为记账节点的概率越大。矿工需要持续生成时空证明,以便确保他们存储了文件的备份。每一个存储证明也是产生下一个区块的选票。
系统在每一个固定的时间段从全体矿工中竞选出领导节点,每个时段选出的领导节点最好是一个。若没有选出领导节点,则添加一个空的区块;若有多个领导节点则出现分支,但这不影响区块链主链的交易。最佳的情况是每次刚好有一个领导节点产生,实际上为了减少分支情况的出现,可以通过修改网络参数尽可能满足只出现一个领导节点的要求。
竞选出的领导节点负责新区块的创建,并且广播给全网其他参与者。参与者通过对新区块提交签名的方式来证明新的区块就此产生。网络参与者通过存储证明生成选票,则竞选算法和验证算法如下。
每位矿工必须符合的标准为

式中:T为这一区块的选票;表示此时的矿工存储算力;L为Hash 函数得到的结果,sig 为矿工的数字签名。如果上述验证通过,则矿工节点生成πit=sig(t,ticket)。一个节点的算力越大,竞选成功的概率也越大。竞选成功的概率近似于该节点存储算力占全网总存储算力的比例。
网络节点每接受一个新的区块就开始验证,具体步骤如下:
步骤1验证签名的合法性,πit是否由矿工签名;
步骤2检查Pti是否为t时刻矿工的存储算力;
步骤3检查对应存储算力下的密码学问题是否通过。
根据存储算力的共识机制具有以下几个特性:
1)公平性
每位参与者在每次选举时都只有一次机会,且竞选成功率与其存储算力所占的比例基本一致,在期望上成功率与存储效率是对等的,对网络贡献越多的节点越有可能选为记账节点。
2)不可伪造性
验证信息由矿工私钥签名,其他人无法伪造。
3)可验证性
被选出的领导节点的时空证明会提交给其他节点验证,以确保签名一致和存储证明一致,并且任何节点都能验证这一过程。
5 测试及分析
5.1 性能分析
精准扶贫数据保护方案构建的系统是基于区块链技术实现的去中心化应用,采用开源的以太坊平台和用于辅助存储应用中的大文本数据系统IPFS 共同搭建在一台主机上,主机的硬件配置为16 GB 内存、i5 处理器和500 GB 硬盘。使用虚拟化软件创建出5 台内存为2 GB的虚拟机并配有64 位的Ubuntu 14.04.1 操作系统,用于搭建以太坊网络和IPFS 网络。
5.1.1 数据存证测试
系统使用Postman 工具对链上数据进行存证测试[20]。Postman 工具可以模拟客户端发送任意HTTP 网络请求,接收服务端的正常响应并显示出返回的完整数据。
使用Postman 发送HTTP 请求到后台服务器,并接受后台响应的JSON 格式的数据。若响应的数据中包含了区块链上链产生的特征哈希值,并且可以使用该值查询到原先上链的完整数据,即可证明系统的存证功能测试通过。
首先将需要上传的扶贫数据封装成JSON 格式的数据,在测试工具中填写对应服务器的IP、端口、路径和请求方式。使用工具发送请求后获得后台响应结果,如图4所示。

图4 发送请求后台响应结果Figure 4 Background response result of sending request
扶贫数据已作为一笔交易成功添加到区块中,并且系统能够返回交易对应的具体编号ID作为其存在区块链的特征属性值,进而获取详细信息,如图5所示。

图5 详细信息后台响应结果Figure 5 Background response result of detailed information
5.1.2 区块链的性能测试
使用压力测试工具JMeter 来测试区块链的性能[20]。JMeter 建立多线程组并给出目标时间t0,每个线程在t0时间内单独发送一次请求,从而模拟多用户同时在线对服务器接口调用的并发场景。每秒产生的并发量对于调用功能接口会产生相当大的负载量,用此工具可以得出每秒的平均交易事务量(transaction per second,TPS)STPS,进一步分析系统底层区块链的性能。
选取5 组不同数量级的压力测试,即1 000、2 000、3 000、4 000、5 000,并将t0设置为1 s。从5 组不同数量级的测试中可以选取3 000 次的测试结果作为本次系统的最优测试情况,所对应的上链接口测试总结报告详情如表1所示。

表1 3 000 线程数的上链接口压力测试表Table 1 Pressure test table for 3 000 threads
分析以上结果可以得出:3 000 次用户并行请求对接口调用成功率为100%,每秒平均吞吐量STPS可达307.6 tps,最高吞吐量为583.2 tps,具体的TPS 测试报告如图6所示。

图6 线程组数为3 000 的数据上链接口的TPS 测试报告Figure 6 TPS test report of data link interface with 3 000 thread groups
综上所述,本文所提出的精准扶贫数据保护方案构建的系统能够满足数据链上存证功能的要求,并在接口承载压力一定的情况下所表现出的TPS 满足系统需求。
5.2 安全性评估
方案的安全性可以从数据保密性、完整性、可追溯等方面分析。在保密性方面,若以SM4作为加密算法将数据加密,则敌手攻破贫困户密钥获取的经济收益远低于成本。因此,方案的安全性评估主要从数据的完整性和可追溯性方面加以分析。
本文方案以联盟链与公有链结合的方式定期存储联盟链区块快照信息,实现了对联盟链上数据的保护和溯源,这样对数据的完整性和可追溯性的分析应从区块数据篡改方面入手。
假设攻击者试图篡改最新区块前第h个区块的数据,选择以分叉的方式替代区块,则需要重新计算并生成从第h区块到当前高度的所有区块,并且广播全网[21]。假设当前公有链中诚实节点的算力为p,在当前计算难度下的区块哈希值含有g个前缀二进制0,恶意节点算力为q,则在没有大量节点进出的情况下计算难度基本保持不变。假设没有新的节点进入或者退出,则每秒诚实节点产生新区块的概率为ω=p/2g,恶意节点产生新区块的概率为µ=q/2g。当前区块高度差为h0,那么在第秒时每秒高度差hi的变化有3 种可能的结果[22],分别为X1、X2、X3。其中:X1代表恶意节点没有生成区块而诚实节点生成区块,X2代表恶意节点生成区块而诚实节点没有生成区块,X3代表两者都没有产生区块。
3 种事件所代表的概率可以表示为

当hi+1=−1 时,说明恶意节点追上诚实节点,数据被篡改。假设在T秒内会出现t种结果,则每种结果出现的次数用随机变量m和n表示。其中X1出现的次数为n,X2出现的次数为m。要想成功篡改数据,X2至少为n+h+1。设j代表m与至少发生次数的差值,则m=n+h+1+j,X3为t −m −n。高度差hi+1的变化概率符合多项式分布[21],其中n ∈[0,(t −h −1)/2],j ∈[0,t −2n −h −1]。
在T秒内,恶意节点追上诚实节点的概率为

故恶意节点成功的概率会随着h的增大而减小。在扶贫数据保护的实际应用场景中,篡改等操作往往与数据录入日期相差久远,因此高度h的数量级是巨大的,可见恶意节点成功概率几乎为0。
6 结 语
本文基于IPFS、数字签名和SMPC 等技术提出了一种基于区块链的精准扶贫数据保护方案,有效地保证了数据的保密性和完整性,并提供了一定的溯源能力。在实际工作过程中,可根据追溯版本号明确责任,但在贫困户更加细粒度的隐私保护问题和链下数据的容灾备份方面依然有所欠缺,尚需进一步研究。
