基于烟丝近红外光谱的卷烟品牌识别方法
2021-03-24谢有超彭黔荣阮艺斌张辞海付阳洋
谢有超,彭黔荣*,,杨 敏,阮艺斌,张辞海,胡 芸,陈 毅,付阳洋
1. 贵州大学化学与化工学院,贵阳市花溪区甲秀南路 550025 2. 贵州大学药学院,贵阳市花溪区甲秀南路 550025 3. 贵州中烟工业有限责任公司技术中心,贵阳市小河经济技术开发区开发大道96 号 550009
配方和调香决定了各卷烟品牌独特的香气和风味[1]。不同卷烟品牌的化学成分、零售价格以及潜在有害成分水平有所不同,同一牌号卷烟也可能由于批次不同而产生差异[2]。每种卷烟品牌都具有固定消费人群,其对卷烟变化十分敏感,如果卷烟的香气和风味波动较大,则会对卷烟销售产生影响。当前对不同卷烟品牌的区分仍以感官评吸为主[3],但该方法存在主观性强且难以实现在线监控等问题。近红外光谱技术以其快速、无损、高效等特点在石油化工[4]、医药[5]和食品[6]等领域已广泛应用,在烟草理化指标定量分析[7-8]、烟叶分级[9]和烟叶溯源[10]等方面也有较多研究。其中,Tan 等[11]对比了近红外光谱结合多类别支持向量机(BSVM)、K 最邻近法(KNN)和簇类的独立软模式法(SIMCA)3 种分类算法对卷烟品牌的判别效果,结果表明BSVM 算法明显优于KNN 和SIMCA,尤其在训练集样本数较少时优势显著。Omar 等[12]采用标准正态变量变换对光谱数据进行预处理后,再进行主成分分析,建立了偏最小二乘判别分析模型,实现了对3 种卷烟品牌的识别。Yang 等[13]采用稀疏表达分类算法(SRC)、支持向量机(SVM)和线性判别分析法(LDA)构建了能够对9 种卷烟品牌定性判别的模型,对比发现SRC 模型不需进行主成分分析就可减少数据维度,具有较高鉴别能力。但目前缺少对卷烟光谱数据的深入研究,导致建模变量多、计算量大,且总体判别准确率低于95%。为此,利用烟丝的近红外光谱数据,通过选择最优的光谱数据预处理方法和降维方法,基于支持向量机(SVM)和线性判别分析法(LDA)分别建立卷烟品牌识别模型并对比验证,旨在为卷烟配方维护和真假烟识别提供技术支持。
1 材料与方法
1.1 材料
采用2019—2020 年贵州中烟工业有限责任公司生产的10 种不同卷烟品牌,编号为A~J。利用Kennard-Stone 算法[14]从329 个样品中选择222 个样品作为训练集,剩余的107 个样品作为测试集,见表1。
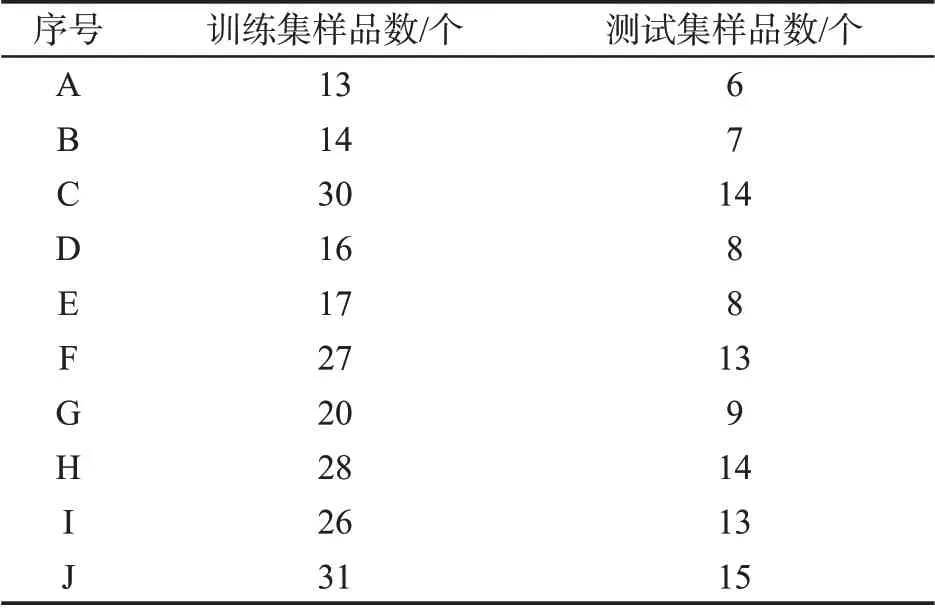
表1 10 种卷烟品牌样品集的划分Tab.1 Sample numbers in sample sets of cut filler of 10 cigarette brands
参照标准YC/T 31—1996[15]的方法除去卷烟包装纸,将烟丝样品经40 ℃烘箱干燥2 h 左右,直至用手可以轻轻捏碎;再冷却至室温,采用烟草粉碎机进行粉碎,粉碎后的烟丝粉末过0.25 mm(60 目)筛后装入密封袋中备用。
1.2 仪器
Thermo Antaris Ⅱ型傅里叶近红外分析仪(美国Thermo Scientific 公司);FED-240 型干燥箱(德国Binder 公司);YC-400B-03 型烟草粉碎机(成都英特瑞公司)。
1.3 方法
1.3.1 光谱采集
扫描前近红外分析仪开机预热30 min,设定扫描波长范围10 000~4 000 cm-1,分辨率为8 cm-1,扫描次数64 次。保持温湿度恒定,将烟丝粉末装入石英杯中,用压块自然落下压实,每个样品采集2次,取平均值。
1.3.2 模式识别方法
模式识别又称模式分类,本研究中基于线性判别分析(LDA)和支持向量机(SVM)分别建立模式识别方法,用于评估不同数据预处理方法和降维方法的优劣。其中,LDA 是一种有监督的判别方法,原变量经投影后可以使类内方差最小、类间方差最大,从而实现对类与类的区分[16]。LDA对于小样本光谱数据的预测能力不高,在高维数据计算过程中容易产生协方差矩阵奇异,因此需要结合降维方法进行特征提取。分析发现,不同潜变量个数会得到不同的判别正确率。为确定LDA 模型的最佳潜变量个数,经不同降维方法提取9~16 个潜变量作为LDA 模型的输入值,并采用训练集的RA(Recognition Accuracy)值作为评价指标选择最佳潜变量个数。
SVM 是一种以结构风险最小化为基础的模式识别方法,其基本思想来源于线性判别的最优分类面,在小样本数据集分类中具有显著优势[17]。SVM 可以将高维空间的内积运算转化为低维输入空间的核函数计算,解决了在高维空间计算中存在的“维数灾难”问题。但不同核函数建立的SVM 模型的预测能力不同,为取得最佳识别效果,采用训练集的RA 值作为评价指标并选择最佳核函数。
1.3.3 光谱数据预处理方法的选择
光谱数据除含有样品自身化学信息外,还含有其他信息和噪声,例如电噪声、样品背景和散光等[18]。本研究中比较了标准正态变量变换(SNV)、多元散射校正(MSC)、基线校正(Baseline)、去势(De-trending)、均值方差化(Autoscaling)、线性函数归一化(Rangescaling)、一 阶导数(first derivative)、连续小波变换(CWT)、SNV+first derivative、MSC + first derivative、SNV + CWT 和MSC+CWT 等12 种光谱数据预处理方法,结合1.3.2 节中确定的两种模式识别方法,采用RA 值作为评价标准选择最有效的光谱数据预处理方法。
1.3.4 数据降维方法的选择
数据降维是指通过将原始特征空间进行变换,将高维空间中的数据点映射到低维空间中,既可减少冗余信息造成的误差,也可考察光谱数据内部的结构特征[19]。为寻找最适宜的降维方法,在对光谱数据进行预处理后,分别采用线性降维主成分分析(PCA)、非线性提取方法局部嵌入(LLE)、局部切空间排列(LTSA)、核主成分分析(KPCA)、随机邻近嵌入(SPE)、Sammon 映射(Sammon mapping)、概率主成分分析(PPCA)和扩展映射(Diffusion mapping)等方法进行数据降维。结合1.3.2 节和1.3.3 节中确定的两种模式识别方法和光谱数据预处理方法,采用RA 值作为评价标准选择最有效的降维方法。
1.3.5 模型评价
采用RA 值作为评价指标考察模型的优劣,即正确判断的样品数占全部样品数的百分比[20]。
1.4 数据处理
使用Matlab R2019a(The Math Works, USA)和The Unscrambler X 10.3(CAMO Software AS,NORWAY)软件进行数据分析。
2 结果与分析
2.1 近红外光谱数据的采集
图1 为10 种卷烟品牌329 个样品的近红外光谱图。可见,各卷烟品牌的近红外光谱图无太大差异,吸收峰形和位置较为相似,无法从直观上进行区分,需要对光谱数据进行预处理。
图1 不同卷烟品牌近红外光谱图Fig.1 NIR spectra of different cigarette brands
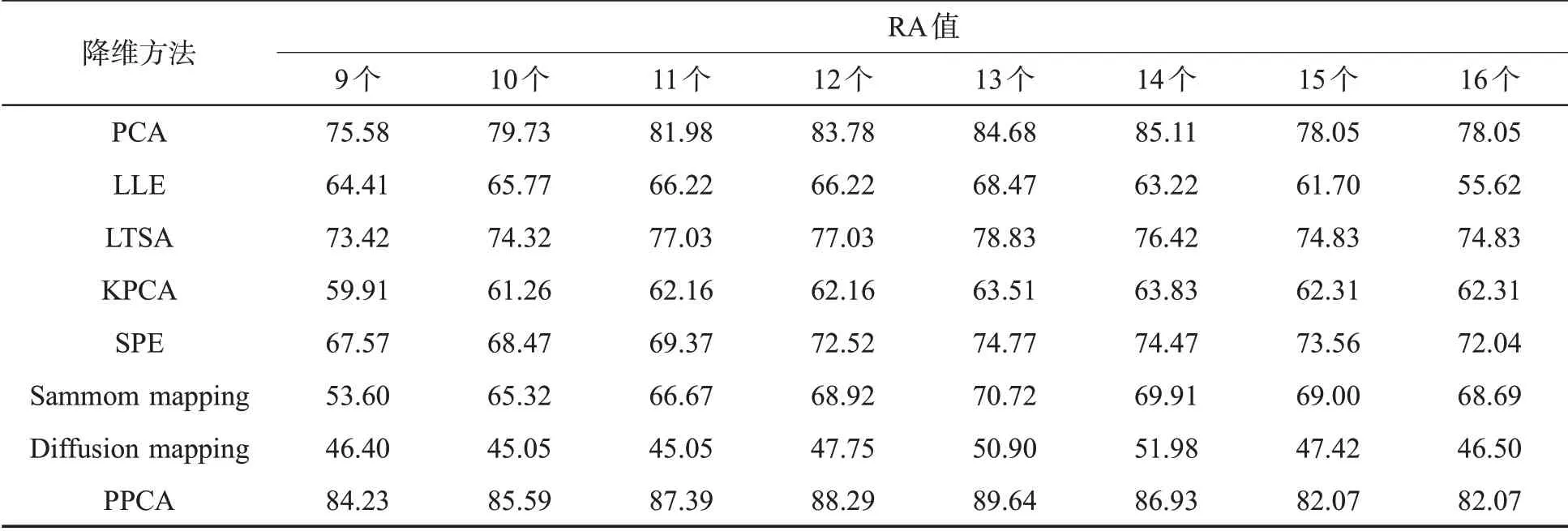
表2 不同降维方法不同潜变量个数下LDA 模型的RA 值Tab.2 RA values of LDA models under different dimension reduction methods and different number of latent variables(%)
2.2 模式识别方法中关键参数的确定
为确定LDA 模型的最佳潜变量个数,经不同降维方法提取到9~16 个潜变量作为LDA 模型的输入值,其训练集的RA 值见表2。可见,随着潜变量个数增加,不同降维方法下LDA 模型的判别能力均呈先上升后下降趋势。其中,采用LLE、LTSA、SPE、Sammom mapping 和PPCA 降维方法在提取13 个潜变量时LDA 模型的RA 值最大。而基 于PCA、KPCA 和Diffusion mapping 方 法 降 维时,选择13 个和14 个潜变量所建模型的判别能力接近。因此,在建立LDA 模型时,提取13 个潜变量作为模型的输入变量,可减少冗余信息,且能得到重要的分类信息。
不同降维方法和4 种核函数下SVM 模型的10种卷烟品牌训练集的RA 值见表3。可见,利用8种降维方法分别提取13 个潜变量后,采用Linear核函数建立的SVM 模型的RA 值最高。因此,选择Linear 作为SVM 模型的核函数进行内积计算。
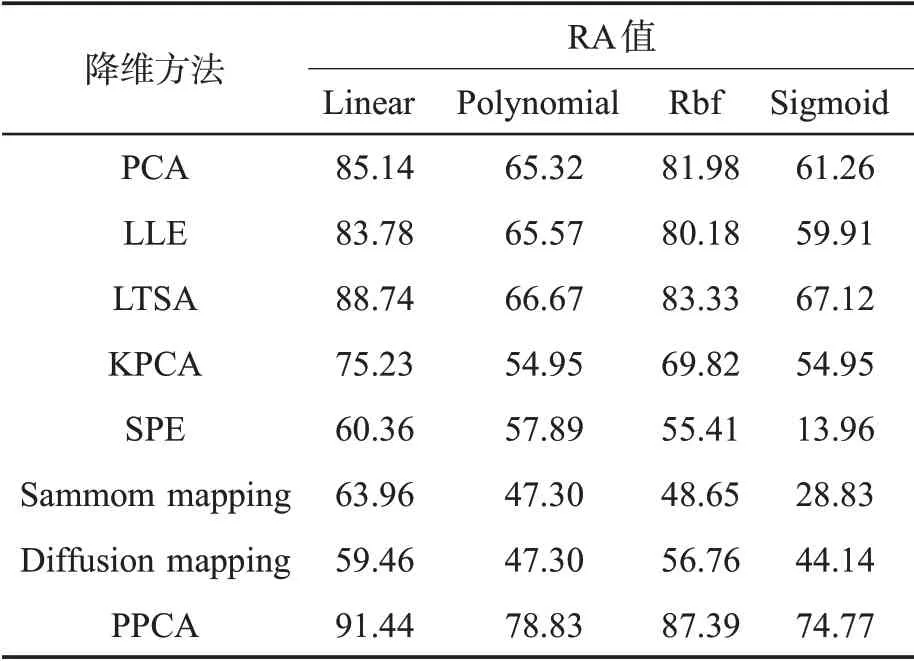
表3 不同降维方法不同核函数下SVM 模型的RA 值Tab.3 RA values of SVM models under different dimension reduction methods and different kernel functions (%)
2.3 近红外光谱数据预处理方法的确定
采用12 种光谱数据预处理方法变换后的光谱图见图2。其中,图2a 和图2b 消除了固体颗粒大小产生的散射影响;图2d 和图2g 消除了光谱中的基线漂移;图2c 和图2j 消除了噪声和背景;图2e和图2f 是近红外光谱数据预处理最常用的方法,用于增强光谱数据之间的差异;图2h、图2i、图2k和图2l 是光谱数据预处理方法的联合应用,可从多角度滤除与光谱数据无关的信息。由于仪器、样品特征以及测量环境、条件的变化,需要通过模型评价选择最佳光谱数据预处理方法。
基于本研究中确定的SVM 和LDA 模式识别方法,对比12 种光谱数据预处理方法的RA 值,见表4。可见,对于SVM 模型,采用CWT 预处理方法的测试集RA 值最高(92.53%);对于LDA 模型,采用Baseline、CWT 和MSC+CWT 这3 种预处理方法的测试集RA 值最高(93.46%)。因此,选择CWT 作为识别模型的光谱数据预处理方法,这可能与CWT 能更好地消除光谱数据中的背景干扰和基线漂移有关。
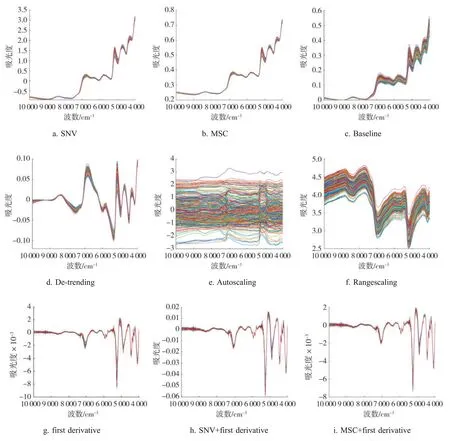

图2 经12 种光谱数据预处理方法变换后的光谱图Fig.2 Spectra transformed by twelve pre-processing methods
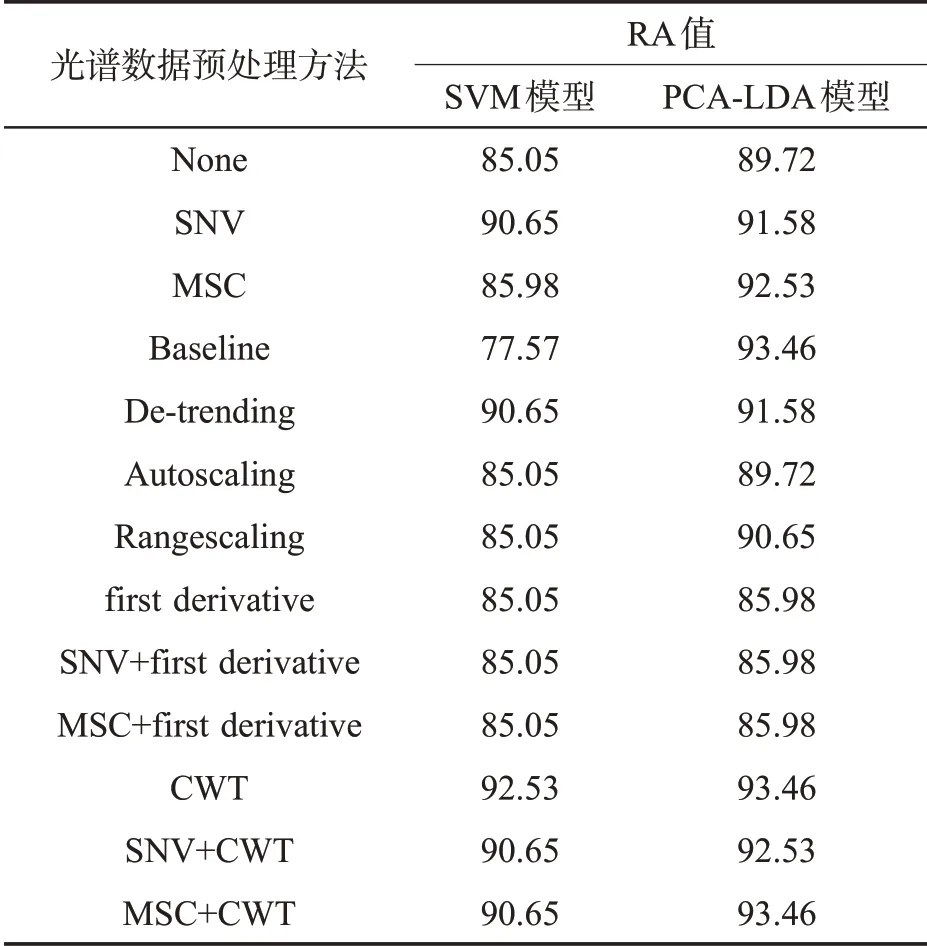
表4 不同光谱数据预处理方法下不同识别模型的RA 值Tab.4 RA values of different recognition models under different spectral data pre-processing methods (%)
2.4 降维方法的确定
为进一步提高模型的识别精度,采用LLE、LTSA 和KPCA 等7 种非线性降维方法,对经过CWT 预处理后的训练集数据进行处理,再分别采用优化后的SVM 和LDA 建模,其测试集的RA 值见表5。可见,不同识别方法下基于PPCA 降维方法的RA 值均为最高,SVM 和LDA 模型的RA 值分别为97.20%和96.26%。
综上可知,采用CWT 进行近红外光谱数据预处理,PPCA 方法进行数据降维,Linear 作为核函数,基于SVM 方法建立的识别模型得到的RA 值最佳。

表5 不同非线性降维方法下不同识别模型的RA 值Tab.5 RA values of different recognition models under different nonlinear dimension reduction methods(%)
3 结论
基于卷烟烟丝的近红外光谱数据,结合机器学习技术,以贵州中烟工业有限责任公司生产的10 种卷烟品牌为对象,建立了一种卷烟品牌识别模型。通过交叉验证,确定了最佳光谱数据预处理方法、潜变量个数、核函数、降维方法等关键参数。利用采集的卷烟样品数据进行验证,结果表明:采用CWT 进行近红外光谱数据预处理,PPCA方法进行数据降维,选择Linear 作为核函数,基于SVM 方法建立的识别模型的RA 值达到97.20%,表明可以根据烟丝光谱数据实现对卷烟品牌的准确识别。
