基于大数据的网络防火墙策略研究
2021-03-24王万龙孙尚
王万龙 孙尚
(中国人民解放军66061 部队,北京 100144)
0 引言
在网络发达的现今,为了防范信息系统遭受入侵或攻击,会使用各种网络安全系统,如防火墙以及入侵侦测系统建构防卫系统,然而以现今的技术及实际状况,防卫系统仍需要管理者紧密的配合才能正确的阻断攻击。然而,仅有防火墙并无法拥有保护的功能,还需搭配防火墙政策规则(Policy rule)的设置,将网络划分成不同的区域,而不同区域的网络沟通,则以政策规则表(Policy rule table)为依据,以达到管制网络封包进出的目的[1-2]。防火墙系统虽能告知管理者相关的攻击报警,但管理者仍必须手动更新规则来完成对防火墙的配置,这样的操作往往存在不全面和不及时的问题。
本研究主要目的在于如何通过分析防火墙日志记录来优化防火墙政策规则表,近年来,虽然有不少研究尝试从数量庞大的网络日志中找出目前所需要的政策规则,运用关联规则挖掘技术产生新的防火墙政策规则。然而,仅运用关联规则挖掘技术将面临两个问题:(1)网络封包的存取常会随着时间而变动,倘若关联规则未能随着网络封包存取的变化而适当调整,将无法有效阻挡攻击。(2)运用关联规则挖掘技术产生的新关联规则可能与现有规则差异非常大,若这些规则都必须套用于正在运作的防火墙规则表上,将耗费更多的时间去核对与验证规则是否有遗漏,这些反复调整规则或验证的步骤,都将成为信息安全管理人员的另一种负担。为了解决上述问题,本研究尝试整合关联规则挖掘及改变挖掘(Change mining)技术,提出Change-based association rule mining(CBARM)方法,从而动态的根据历史记录来完成防火墙规则的调整,这样就可以更好的完成对网络攻击的防护。
1 基于数据挖掘的网络入侵防御策略
本研究所提出CBARM方法流程如图1所示,主要可以分为四个步骤,依序为:数据前处理、关联规则挖掘、改变挖掘及防火墙政策规则评估。以下将详细说明各个步骤的流程与任务。
1.1 数据前处理
本研究从防火墙日志记录中获取出所需分析的数据字段,分别是:日期(Date)、时间(Time)、通讯协议(Protocol)、来源地址(Source IP Address)、源通讯端口(Source Port)、目的地址(Destination IP Address)、目的通讯端口(Destination Port)及状态(Status)等八项属性数据。本研究将防火墙日志记录文件存放于远端F T P 服务器上,并以Comma-Separated Values(CSV)纯文字格式文件储存数据。除此之外,由于防火墙系统储存的时间是以笔数来做储存,所以无法将每日数据汇整成一个文件,所以借由数据前处理先将每份CSV文件汇整至数据库存放,接着汇出一周的日志记录由当周第一天(星期日)0时0分0秒开始至当周最后一天(星期六)23时59分59秒的文件(如图2所示),并汇整每周的防火墙日志记录,以利后续关联规则挖掘的进行。因此,数据前处理步骤中,本研究先通过自动汇出的功能,将防火墙日志记录储存在文件服务器或数据库上,再将原始数据整理成为关联规则挖掘所需的数据格式[3]。
1.2 关联规则与防火墙政策规则的整合评估
关联规则与防火墙政策规则的整合评估流程如图2所示。首选根据原来的规则表和关联规则进行整合和比较,这样就可以获取到新的规则表,如果进来的网络包符合这个规则就接受该包,否则就拒绝该包[4-5]。
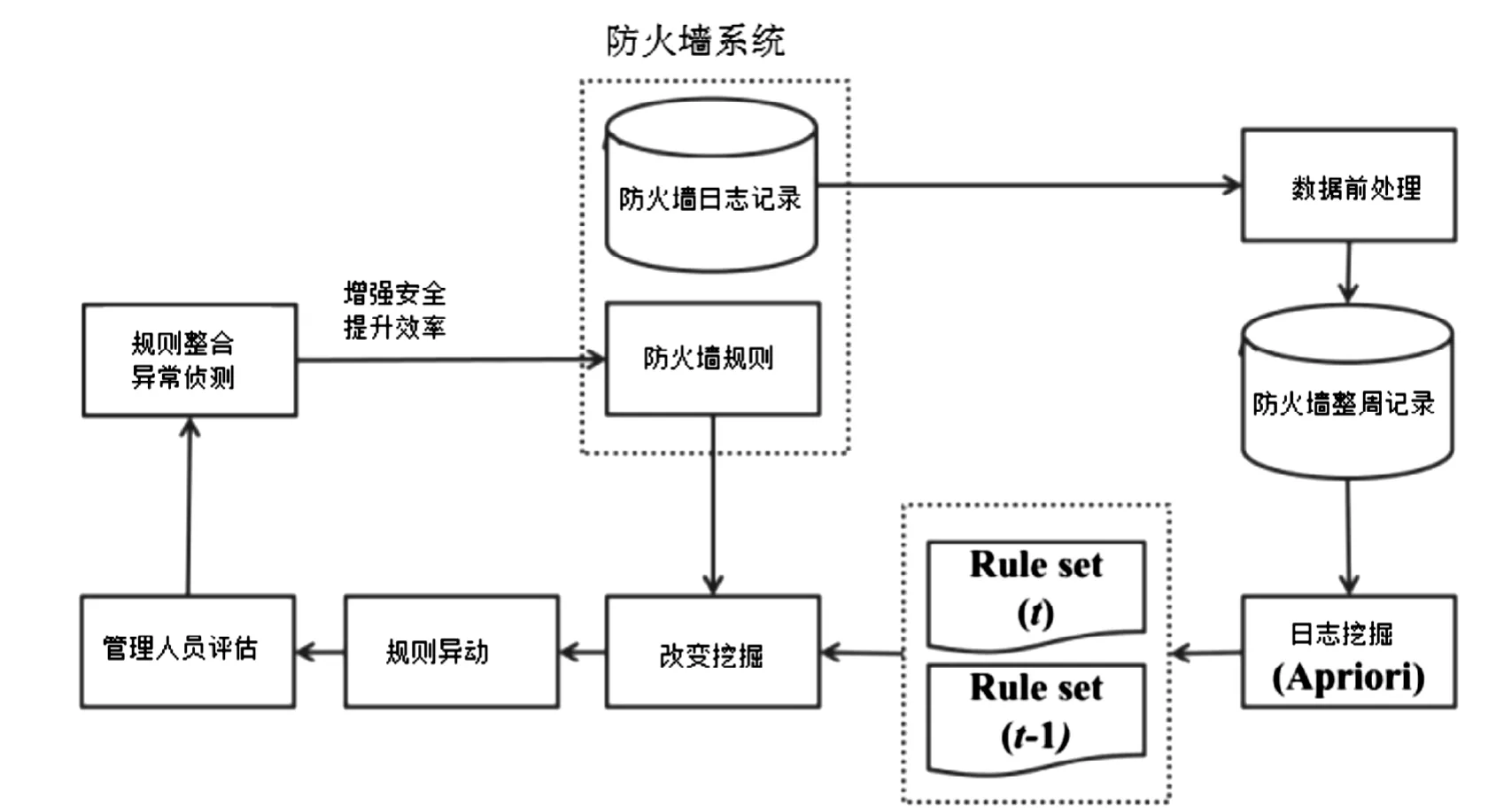
图1 CBARM 流程图Fig.1 CBARM flow chart
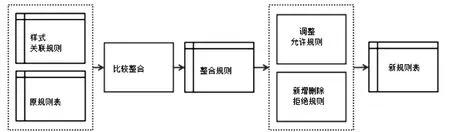
图2 防火墙政策规则整合流程图Fig.2 Firewall policy rules integration flow chart
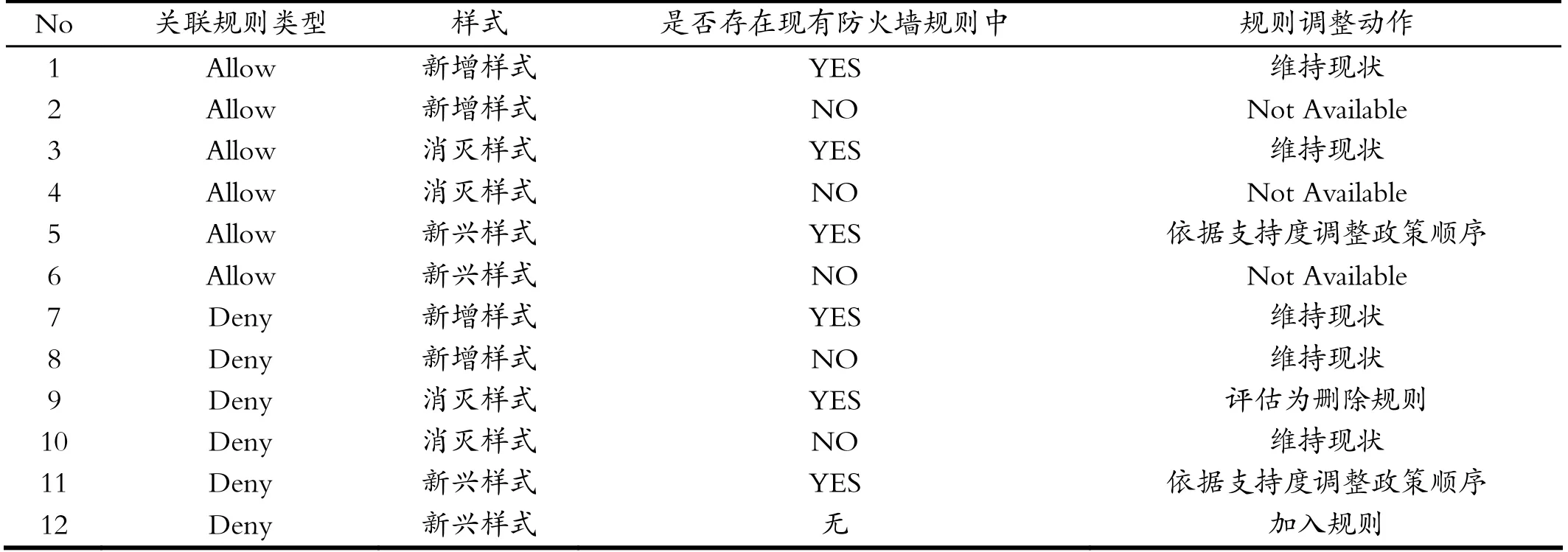
表1 各种类型规则的执行动作Tab.1 Execution actions of various types of rules
本研究的防火墙政策调整动作原则如表1所示,此表描述了最近两周通过关联规则获取的防火墙规则表与现有的防火墙规则表进行整合的相关调整动作。
本研究以范例说明防火墙政策规则整合流程。假设原始防火墙规则共有3项规则,如表2所示。经由关联规则挖掘及改变挖掘所得到的规则共有2项规则,如表3所示。表3中的第一项规则{如果X=(Src_IP=1 40.10.20.3,Dst_IP=218.89.56.4,Dst_Port=139),则Y=(Status=Deny);支持度=0.1,信心度=90%}。假设有1000个封包,{支持度=0.1}代表100 0个封包中,有100个封包符合{X=(Src_IP=140.10.20.3,Dst_IP=218.89.56.4,Dst_Port=139)且Y=(Status=Deny)}等项目,其比例为0.1(100/1000);而{信心度=90%}代表有100个封包符合{X=(Src_IP=140.10.20.3,Dst_IP=218.89.56.4, Dst_Port=139)}的前提下,而且这100个封包中有90个封包也同时符合{Y=(Status=Deny)}的情况,其比例为90%(90/100)。运用于防火墙日志,其管理上的意涵为:支持度(support)越高代表所有封包数据集中同时符合{X}与{Y}的比例越高。而信心度(confidence)越高代表封包符合{X}的情形下,也同时出现{Y}的比例越高,即{Y}经常伴随着{X}出现。

表2 原始防火墙规则表Tab.2 Original firewall rules

表3 改变挖掘得到的规则Tab.3 Rules obtained by changing mining

表4 经调整后的防火墙规则表Tab.4 Adjusted firewall rules
经调整后的防火墙规表4 所示。表4 中的第一项规则{Src_IP=140.10.20.3,Dst_IP=218.89.56.4,Dst_Port=139→Status=Deny},其规则类型属于拒绝、规则样式属于新兴样式、不存在原始防火墙规则表中,故防火墙政策调整动作为加入规则。而第二项规则类型{Src_IP=192.168.10.5,Dst_IP=140.89.1.4,Dst_Port=443→Status=Allow},其规则样式属于新兴样式、已存在原始防火墙规则表中,因为规则的支持度提高,故防火墙政策调整动作为依据支持度调整政策顺序,并将该规则向前调整顺序。由上述的范例得知:规则排列的顺序应优先考虑支持度,而支持度相同则再比较信心度。
2 总结
近年来,许多研究尝试通过关联规则技术从数量庞大的网络日志中找出目前所需要的政策规则,然而,过去的研究只考虑单一时间区间的关联规则,却忽略了在不同时间区间关联规则的变化趋势将可能显著影响防火墙效率,若将单一时间区间的关联规则全部套用于正在运作的防火墙规则表上,将耗费更多的时间去核对与验证规则是否有遗漏,同时亦会增加比对次数,造成防火墙效率低落。本研究根据C B A R M 方法,从而动态的根据历史记录来完成防火墙规则的调整,从而可以动态调整防火墙规则,实现更好的网络安全防护。
