文本对抗样本生成系统的设计与实现*
2021-03-24徐慧萱魏轩张娅婷张雪珥王伊婷
徐慧萱 魏轩 张娅婷 张雪珥 王伊婷
(北方工业大学信息学院,北京 100144)
0 引言
随着人们已经习惯通过网络阅读信息并依据信息内容做出主观判断,因此谣言散布者等恶意非法者为达到使这些不法的或不良的信息充斥网络并充分扩散的目的,为了躲避内容监测采取单词替换、拆字等方式。针对这种不法或不良内容信息,由于对这类不良内容检测超出了人力成本,即超出了纯以人工方式进行监测的模式,因此多采用基于深度学习理论研发对不法/不良内容的检测识别以期阻止这些不法/不良内容的传播。而要为实现准确的检测并阻止不良信息的传播,需要可信的训练样本数据集。随着内容安全领域的不断攻防博弈,2 0 1 4年,Szegedy提出了“对抗样本”概念[1]。对抗样本是一类人为构造的样本,通过对原始的样本数据添加针对性的微小扰动,其不会影响人类的阅读感官,但是其会使深度学习模型产生错误的判断,最终对非法内容数据/不良内容数据产生错误的检测识别。这种对抗攻击最初应用在图像领域的人工智能对抗博弈[2],随着研究的加深,这种对抗场景近年也转入了文本对抗领域,且当前文本领域的研究多集中于英语语句内容的人工智能监测对抗。
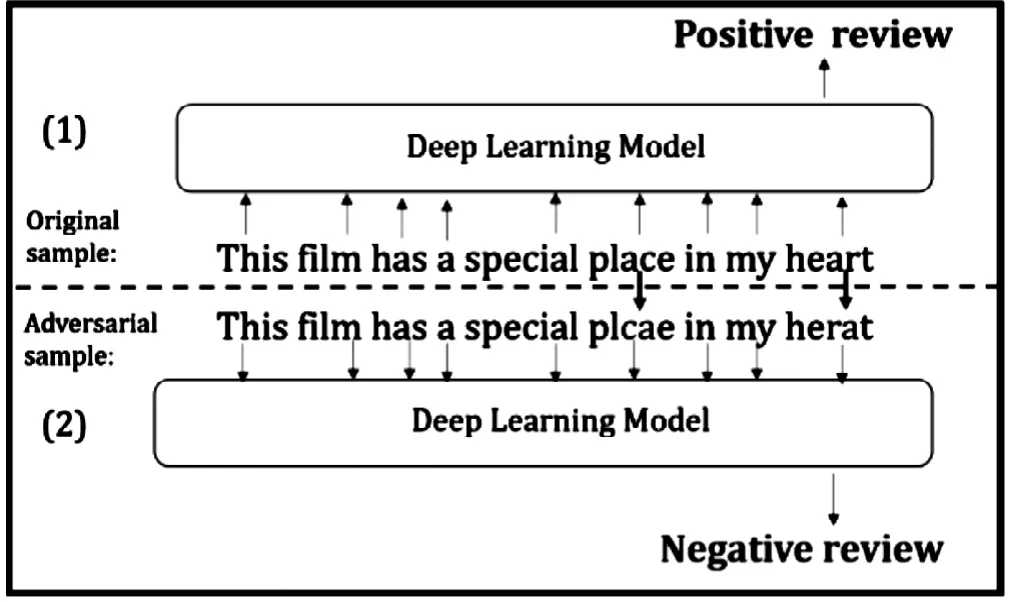
图1 文本领域的情感词对抗攻击Fig.1 Emotional words against attack in Text Domain
本文以英文的语义文本情感分类为基础,通过构造对抗样本数据集,实现了文本情感属性的转变。这种转变使得被测试文本由正面情感属性变成了负面情感属性,或者使得被测试文本由负面情感属性变成了正面情感属性,为后续的不良文字扰动的检测研究提供了训练和测试数据支撑。
1 字符扰动样本构建方法
1.1 文本扰动情感词对抗
文本领域的情感词对抗攻击示例如图1[3]所示,其中:(1)为原始样本;(2)为对抗样本。将原始样本中的部分单词的字符位置发生变换,具体为两处位置变化:place中的a与c位置互换,heart中的a和r位置互换。变换后的语句上从整体看不影响人类的阅读感官,即人们也能够通过粗读理解该语句的含义,但是从基于深度学习的人工智能检测模型上看,深度学习模型将原始样本判为正面评论,而将对抗样本误判为负面评论。这种评论结论的误判可能导致对不法或不良内容的文本的忽略,造成其脱离监管并造成传播结果。
1.2 对抗样本构建方法
首先,基于负面关键词库从文本检索并定位出负面的单词,特别是重点关注其中的辱骂词(例如:shit、whore、fuck、gawky等)和恶意评价词(例如:terrible、bad、regret、brutal等)。同时,为了尽可能地实现对文本中负面词的覆盖,避免负面关键词库的不完备,因此利用word2vec统计语句中的高频词,以人工的模式确定高频词的正负情感词属性定性。并将定性结论为负面属性的单词补充进入负面关键词库中。
然后,对文本中出现的负面情感单词进行合理处理,涉及的手段有:
(1)仅改变单词中的某些字母顺序。为了不影响人们的阅读感官,在本系统中,我们采用随机更改单词中除首字母之外的两个相邻字符的顺序。
(2)在负面情感单词中插入随机字符,可以是多点插入,也可以是单点插入。同样,为了不影响人们的阅读感官,在本系统中,我们采用随机单点插入,即仅插入一个字母,且选用的插入字母以“-”“+”或空格为主。例如:thoughout→thou ghout或thoughout→though-out。
(3)对负面情感单词用同义词、闭包词等进行替换。前提条件是该同义词或闭包词不在目标检测识别模型的负面关键字库中。为此,我们建立了一个同义词数据库。例如:songs→performances,唱歌是表演的一种具体形式,后者是前者的闭包词。人们可以在文本的上下文环境中自动将表演映射到具体的唱歌形式中。
(4)删除单词中的某一字符。实施的前提条件是不影响人们的阅读感官。
最后,通过以上步骤的处理后将形成对抗样本训练集合,为后续的训练提供数据支撑基础。
2 系统设计
2.1 系统模块
在我们当前完成的版本中,对抗样本生成系统结构如图2所示。

图2 对抗样本生成系统Fig.2 A confrontation sample generation system
通过策略选择模块,随机选择对原始文本中负面情感词的处理模式,分成随机位置互换模式、随机字符选择模式、随机删除模式和同义词替换模式。这4 种模式分别对应上图中的相应功能模块。在我们的原型系统中:(1)在随机位置互换模块中仅仅对单词中间的字符进行随机互换;(2)在随机字符插入模块中,我们目前仅随机插入空格和“+”号且仅插入1个位置;(3)随机字符删除模块,我们仅删除除首字母之外的一个字符。通过在策略选择模块中赋予其较小的因子,使得该模块的调用概率小于其他3个模块;(4)同义词替换模块。涉及的同义词数据库汇中,目前仅仅存储我们手动添加的一些同义词。
2.2 对抗样本生成算法
我们的对抗样本生成算法描述如图3 所示。
首先,从目标文本区依次读取原始文本数据,以空格、逗号、句号等分隔符作为单词的分割依据,对分割得到的单词做检索判断,其是否是负面单词。
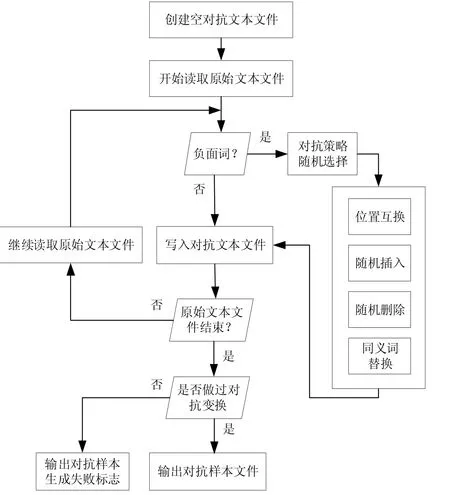
图3 对抗样本生成算法Fig.3 Algorithm for generating countermeasure samples

表1 样本生成有效性实验测试Tab.1 Experimental test of sample generation effectiveness
然后,如果是负面单词,则将启动对抗策略随机选择位置互换、随机插入、随机删除、同义词替换四种处理方法之一对检索到的负面词进行处置。由于是原型系统,我们当前对位置互换、插入和删除操作仅仅处理单词内的1个字符;对于替换操作,我们仅仅随机选用同义词库中已经设定好的有限同义词汇之一。反之,如果不是负面词,则继续读取下一个单词。
然后,重复以上两个步骤,直至原始文本文件处理完毕。
最后,根据对抗样本处理标识判断输出的对抗样本的有效性。如果标识为1,表示原始文本的内容进行了对抗处理,得到的对抗样本文件生成完毕;如果标识为0,表示在原始文本中没有找到负面词,此时生成的对抗样本文件和原始对抗样本是一样的,即:没有生成对抗样本。
3 实验
我们使用IM DB 数据集进行系统功能测试。该数据集拥有50000条关于电影的积极影评和消极影评,每条数据的长度是200个单词左右。我们用25000条数据作为情感分析模型的训练集,另外25000条数据作为测试集。样本生成有效性实验结果如表1所示,将原始的负面情感的文本分类成为了正面的情感文本。表明我们设计的对抗样本生成系统是有效的。
4 结语
本文讨论了文本对抗样本的生成方法,并据此实现了一个原型系统。以I M D B 数据集中的负面影评数据作为原始文本测试对象,实验测试结果表明了原型系统的有效性。
