基于划分图像内容分级的语义分割算法*
2021-03-24罗子明冯开平罗立宏
罗子明 冯开平 罗立宏
(广东工业大学计算机学院,广东广州 510006)
0 引言
近年来,由于语义分割在医学图像处理和自动驾驶方面具有广阔的应用前景,越来越多的研究人员将目光放在语义分割上。语义分割结合了图像分类、目标检测和图像分割,通过一定的方法将图像分割成具有一定语义含义的区域块,并识别出每个区域块的语义类别,实现从底层到高层的语义推理过程,最终得到一幅具有逐像素语义标注的分割图像。基于卷积神经网络的语义分割方法与传统的语义分割方法最大不同是,神经网络可以自动学习图像的特征,进行端到端的分类学习,大大提升语义分割的精确度。
本文的主要贡献如下:(1)本文将语义分割的任务,即将输入图像全部像素进行分类的任务按照分类难度划分成不同的子任务,分别训练端对端的U-net神经网络,解决了单一U-net在语义分割难度等级高的类的精度不高的问题。(2)本文通过集成神经网络来输出最终的语义分割结果,在集成神经网络上使用了多种卷积核相结合的方法,使算法在图片特征提取的过程中保持较大的感受野,减少空间特征信息的丢失。
1 研究基础
经典的语义分割算法有全卷积神经网络(Fully Convolutional Networks)[1],它包含卷积层和用于恢复空间信息的上采样层,另外一种是基于编码解码器的卷积神经网络,经典的构架为SegNet。
总的来说,当语义分割任务要区分的类的数目增多或被区分的物体在不同的图片中有不一样的特征的时候,语义分割的精度就会下降。学者们尝试了许多方法来解决这个问题,提高语义分割算法的精度。其中Bengio等人提出的循环学习的方法[2]是在训练神经网络的时候按语义分割难度区分各类,从简单类到困难类逐步训练。而深层级联方法[3]则是使用级联的IRNet,其方法主要是根据不同的难度等级逐步根据上一步的结果对图像进行分割。这些成果验证了在具有类别划分的数据集上将语义分割任务划分成各个子任务是可行的。
本研究在上述研究的基础上按照各类别分割的难度将语义分割任务拆分成多个分类子任务。本研究按以下两点判别类别的难度等级:(1)该类别的像素点数目占总的像素数目的百分比;(2)该类别的物体的特征是否会随着图片的不同而发生较大的改变。
本研究为各个难度等级分别训练神经网络,从这些网络中获取概率图并输入给集成网络,通过集成网络输出最终的语义分割结果。本研究使用的CamVid[4]数据集包含11个类,根据每个类的像素点的多少将这11个类分成容易、中等、困难三个难度等级。4个像素点最多的类划分为简单,3个像素点最少的类划分为困难,剩下的4个类划分为中等。
2 算法架构
如图1算法架构示意图所示,本方法主要分为两大部分,为每个不同难度等级训练一个神经网络和训练一个集成神经网络,将从各个子任务的神经网络中获取的概率图输入到集成网络中。
2.1 各难度等级网络训练
本研究将图像的全类别划分成不同的难度等级。通常若某个类别的像素点多,那么该类别就容易划分出来,反之,若某个类别的像素点少,那么就不容易划分出来。因此,本研究根据不同类别的像素点的多少来划分其分割难度。
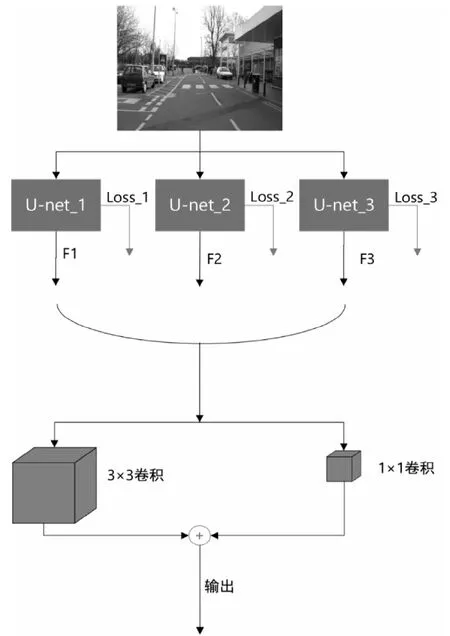
图1 算法架构图Fig.1 Algorithm architecture diagram
图2 是CamVid数据集中的一幅图片,本研究将CamVid数据集的11个类划分成三个难度等级:4个像素点最多的类划分为简单,3个像素点最少的类划分为困难,剩下的4个类划分为中等。
本研究使用U-n e t 作为各个难度等级的分类器。在U-n e t 中使用交叉熵损失函数。如图1 算法架构所示Unet_1,U-net_2和U-net_3的输出表示为F1,F2和F3,F表示经过映射的概率图。U-net_1,U-net_2和U-net_3分别对应三个不同的难度等级。
2.2 集成网络
如图3所示的架构处理上一步各个难度等级的U-net输出的概率图,将级联的概率图F1,F2和F3输入到集成网络中,在集成网络中使用两种卷积核(1×1,3×3)。1×1卷积表示各个像素点的概率加权和;3×3 卷积表示局部区域的概率加权和。通过softmax获得输出概率,集成网络的损失函数也是交叉熵损失函数。
2.3 网络训练
本研究在训练神经网络的时候根据图片各类别像素点的多少来确定各个U-net所占的全总,类别权重的计算公式:

式中Wc表示某类别的权重,fm表示中位频率,fc表示该类别的频率。
在训练网络时,总的损失函数定义:
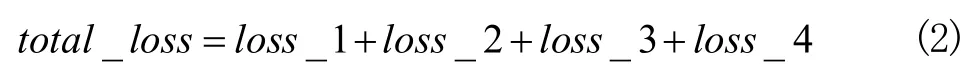
总的损失为各个神经网络损失的和。表1展示了各个网络架构、难度分级、类别权重和损失函数的对应关系。
3 实验设置与实验结果
实验部分将本研究提出的方法与传统的不对类按难度划分的方法进行对比,使用交并比(IoU)作为性能对比的指标。IoU的计算公式:

其中TP,FP,FN分别表示真阳性,假阳性和假阴性计数。
3.1 实验设置

图2 难度等级分类示意图Fig.2 Schematic diagram of difficulty level classification
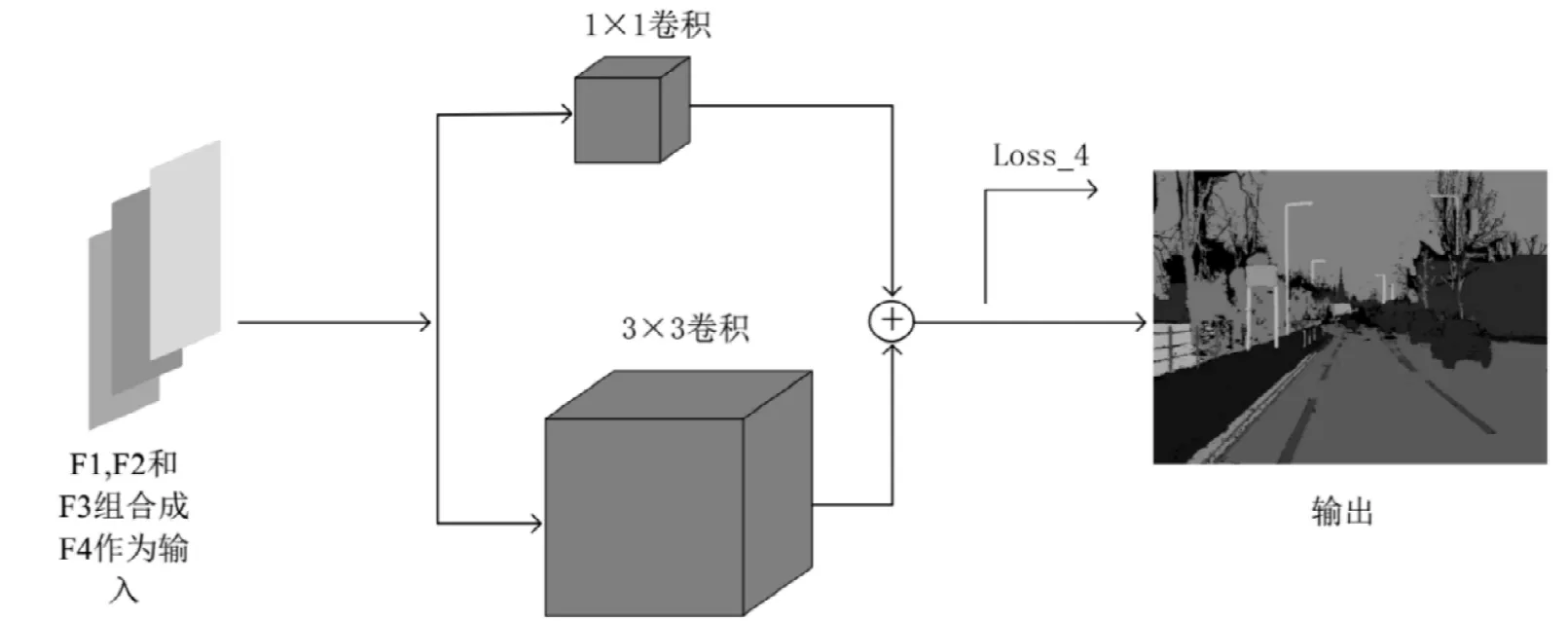
图3 级联网络示意图Fig.3 Schematic diagram of cascade network;

图4 在CamVid 数据集上的实验结果Fig.4 Experimental results on CamVid data set
本实验使用CamVid数据集,该数据集包含11个类,701张照片(其中367张图片作为训练集,101张图片作为验证集,233张图片作为测试集),图片尺寸为360×480像素。本实验设置批处理尺寸大小为4,学习率设置为0.001。
本研究使用的方法将数据集全部11个类按照各类像素点的多少分成了多个难度等级。将难度等级分为两级(容易,困难)和三级(容易,中等,困难)。(1)在难度等级两级的情况下:将天空、建筑、道路、树木、车辆划分为容易这一等级;将灯柱、人行道、指示牌、行人、自行车手划分为困难等级。(2)在难度等级三级的情况下:将天空、建筑、道路、树木划分为容易等级;将人行道、指示牌、围栏和车划分为中等等级;将灯柱、行人和自行车手划分为困难等级。
3.2 实验结果
图4为CamVid数据集上的实验结果对比,从上到下四组图片分别是原图,实测值,使用本实验方法的分割结果和使用U-net的分割结果。
表1 展示了传统的方法与本研究的方法在I o U 上的精准度对比。其中第一行是没有划分难度等级使用单一U-net的方法在各个类别上的IoU,第二,三行分别是划分了两个难度等级和三个难度等级的各个类别的IoU。如表1 所示,本研究使用的改进方法与不划分难度等级的传统方法对比在各类平均IoU上有了2%的提升。尤其是在围栏、人行道、自行车手这三类上有超过5 % 的提升,这些类都被划分为中等难度或者困难难度,这说明本研究的方法对于一些较难检测的类的语义分割精度有提升作用。

表1 CamVid 数据集实验结果对比Tab.1 Comparison of experimental results of camvid data set
4 结论
本研究提出了一种通过划分不同难度等级提高语义分割精度的方法,首先将语义分割的任务划分成多个按不同难度等级进行语义分割的子任务,提高了各子任务的神经网络对自身困难等级的语义特征的提取能力,提高了神经网络的性能。其次,通过级联的集成网络加权各个子任务神经网络的特征输出,输出语义分割结果。最后在C a m V i d 数据集上进行实验证实了本研究方法的有效性。
下一步的研究可以分两个方向:(1)本研究使用的神经网络架构为U-net,但是在不同的难度等级上可以使用不同深度的神经网络,具体来说就是对难度等级为容易的类使用浅层的网络,对难度等级为困难的类使用更深层的神经网络。(2)在计算各层网络的权重的时候可以使用更强的拟合算法来代替加权平均。
