大数据挖掘中的数据分类算法综述
2021-03-24尹廷钧李灵慧周蕊
尹廷钧 李灵慧 周蕊
(战略支援部队信息工程大学,河南郑州 450002)
0 引言
数据分类算法是大数据挖掘的核心内容,其主要作用是通过对海量无序数据进行大量运算,提取价值的知识和信息,分析出各类信息的特征,为研究者进一步预测某一趋势提供数据基础。随着数据挖掘技术的广泛应用,数据分类算法不断涌现并逐步优化完善,其中经典的分类算法有决策树分类算法、朴素贝叶斯算法、支持向量机分类算法、人工神经网络分类算法等。
1 大数据的特点及意义
大数据作为一种抽象的概念,简单来说就是对海量数据信息进行挖掘整合,这些数据类型多样、数据量巨大、价值密度低、增长速度快,只有对这些其进行合理的数据挖掘和数据分析才能发掘其背后的应用价值。伴随着各行业生产发展,每天都会有大量的数据产生,通过大数据技术,这些信息在潜移默化中影响着人们当前的生活乃至某一行业的发展。大数据的数据类型种类繁杂,数据容量巨大,可以分为结构化的数据信息和非结构化的数据信息以及半结构化数据信息,如图片、声音、视频等,这些生成的大量数据信息其单条信息价值很低,传统的分析工具需要大量时间效率很低,必须辅以能够对其快速处理的大数据技术。大数据能够帮助其更好挖掘出数据价值意义所在,对行业当前发展的现状进行分析,从而能够更好的预测到未来发展趋势,给日后管理工作开展提供依据。
2 大数据挖掘中的分类问题
大数据挖掘技术主要是从海量信息数据中按照某一指定的属性对数据信息进行采集、划分,逐步获取并积累一些有效信息的过程。数据挖掘技术作为大数据时代网络信息技术发展的产物,主要涉及人工智能、数据库、统计学等,所涉及研究内容比较多,其中比较重要的一个研究分支就是分类。数据分类是进行数据解析并取得正确分析结果的基础。数据的分类过程一般包含两步,第一步是通过一个已知类标号的数据训练集来构造模型,这一步常被称作训练阶段,可以理解为训练一种分类器;第二步是用该模型对某未知类标号的对象进行分类。由该过程我们可以知道,分类模型不仅要拟合已知数据集,更重要的是要能准确预测未知对象。不同的分类算法有着适用于不同的应用场景,分类算法的差异会模拟出不同分类器,将会直接影响到分类的精准性,最终影响数据分析。因此对规模系统比较复杂或数据信息量比较大的数据实施深度分类,对分类算法进行合理的选择,都对任务完成产生重要的影响。当前国内和国外的计算机数据学领域在大数据挖掘技术中与之有关的分类算法研究主要汇集在下面两方面:一类是把传统化分类算法直接应用在实际的案例中,或者把传统的算法做出简单的组合,再将其应用在实际的案例中。另一类是把利用新技术新思想对传统的分类算法进行改进升级。如何在实际应用种选择合适的分类算法,下面对几种经典分类算法进行描述分析,总结出各种算法的特点、优势、缺点供大家参考。
3 数据挖掘中常用分类算法分析
当前在大数据分析和数据挖掘阶段经典的分类算法主要有为决策树、朴素贝叶斯、支持向量机(SVM)、神经网络分类算法等。
3.1 决策树分类算法
决策树(decision tree)分类算法是归纳学习算法中的一种,主要是指从一系列无规则、无顺序的样本数据信息中推理出“树”型结构来进行预测的分类规则。决策树分类算法能以直观的方式展现整个决策过程中的不同时期决策类的问题和关键点。决策树由根节点(root node)、内部节点(internal node)、叶子节点(leaf node)及连接节点的有向边构成。根节点是唯一的,表示待分类的样本集合;内部节点表示特征属性;叶子节点表示分类结果。算法决策过程从根节点开始,根据待分类集合中相应的属性值,由上而下选择分支到达相应节点,重复此步骤直到到达叶子节点,叶子节点存放的类别作为分类结果。例如某人到银行申请贷款,银行根据申请人年收入、房产情况、婚姻情况等条件进行判断划分,从而是否批准其贷款申请。这个过程我们可以采取决策树的形式进行表达,如图1所示。

图1 决策树分类算法流程示例Fig.1 Flow example of decision tree classification algorithm
目前决策树算法种类比较多,典型算法有ID3、C4.5、CART算法等,其中C4.5是对ID3的优化改进。与其他类型分类的算法进行对比分析,决策树算法主要有下面的优点:第一,决策树算法逻辑清晰、层次分明、直观,其分类规则便于人们的理解和实现,是一个相对友好的分类算法。第二,决策树算法分类精度高,采用决策树分类算法在数据的挖掘过程中,每个节点对应一个分类规则,可以准确将每个数据分类到叶节点。第二,决策树算法运行高效,用时较少。除此之外,决策树的分类算法在应用阶段虽然说有着诸多的优点,但也会出现过度拟合等问题。在生成决策树时,当完全依照训练集时,如果训练集中有噪音样本,在对训练集进行拟合的同时也会对噪音拟合,从而使分类模型过于复杂,分支过多,有些分支时属于训练样本自身特有的,不具有代表性,从而在测试阶段出现过度拟合的情况,导致模型的准确性低[1]。我们需要根据选择的分类算法进行属性离散化或预排序,尽可能的实现分类和学习。避免发生类别较多或较少,造成过度拟合的情况等情况影响预测精度。基于其决策树优劣分析,专家学者对其进行改进,在形成决策树和建设决策树的过程中,通常采用剪枝的方式来减少噪声对分类的影响。如果特征数量很多,需要在建立决策树后基于全局考虑对没有足够分类能力的特征进行剪枝,减少模型的复杂度,使决策树具备更好的泛化能力。剪枝有两种方法:一种称为事先剪枝法,即在构造树的过程时提前停止。比如提前设置决策树最大深度或者对样本集中某以特征属性预先设定约束条件等。另一种称为事后剪枝法,即整个树生成之后判断某些分支是否需要变为节点而进行修剪[2]。剪枝要适度,既要避免出现过拟合,也要避免出现欠拟合的情况。
3.2 朴素贝叶斯算法
朴素贝叶斯算法属于监督学习中的常用算法,这个算法的操作和原理都是比较简单的,主要是基于著名的贝叶斯公式:

通过先验概率与条件概率解决后验概率的问题[3]。假设样本数据集的各特征属性之间是相互独立的,当条件独立性假设成立时,已知训练样本中的分类概率P(y1)、P(y2)…P(yn),通过计算已知分类的特征属性的概率P(x1,x2...xn|y1),P(x1,x2...xn|y2)...P(x1,x2...xn|yn),进而预测具备待特征属性数据的分类,即比较P(y1|x1,x2...xn)、P(y2|x1,x2...xn)…P(yn|x1,x2...xn)其中概率最大的作为该对象的分类。公式最终可变成:
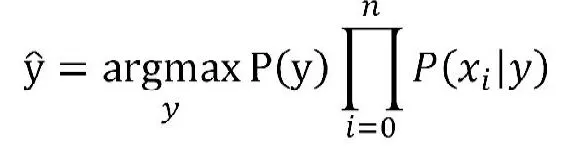
朴素贝叶斯分类算法操作特点主要有下面几点:第一,朴素贝叶斯算法逻辑思想十分简单,有着较强的可操作性和可行性。第二,朴素贝叶斯算法较为稳定,不会因数据自身呈现的特点不同而对分类结果产生较大影响。第三,朴素贝叶斯数据之间独立性越强,其分类结果越准确。但我们需要注意的是该分类算法需要基于条件独立性假设的前提,这是一个理想状态,在实际应用中数据属性间会存在联系,从而降低了分类准确性,因此该方法往往在效果上难以达到理论上的最大值。可以通过扩大样本训练集来获得类别总体的概率分布和各类样本的概率分布函数。另外在分类器测试阶段,如果测试样本中出现了训练集中没有的特征属性,那么不管如何计算所有类别的概率都会是0,这时候需要进行平滑处理每个样本值加1,计算概率时在分子加1,分母加N*1,这种方式我们成为称为普拉斯平滑处理,实际的使用时可以用lambda(1≥lambda≥0)来代替简单加1。另外一个我们可能遇到的问题是在求乘积时,由于概率小于1,小于1的两数相乘结果会更更小,甚至在四舍五入后直接变为0 出现下溢的情况,这时候需要对乘积结果取自然对数以解决此类问题。
3.3 基于神经网络的分类
神经网络是指人工神经网络,以网络拓扑知识为基础模拟人脑的结构及功能形成一种有效运算模型,主要包含输入层、隐藏层、输出层三部分。神经网络是由大量节点相互连接构成,每个节点代表一种特定输出函数,每两个节点间的连接都代表通过该连接信号的加权值,即权重。每层节点对输入信息的加权求和并进行非线性变换后输出,其输出值作为下一层的输入值,以此类推直到最后分类节点[4]。常见的神经网络类别有单层神经网络、两层神经网络、多层神经网络、卷积神经网络、循环神经网络。神经网络学习阶段通过调整各连接权重来实现最终输出值与真实值逐渐接近,最终达到准确模型。神经网络训练完毕后对输入信息进行动态响应进而从输出端得到分类结果。神经网络分类算法较多的,B P 神经网络、R B F神经网络、自组织特征映射神经网络、学习矢量化神经网络,目前使用较广泛的是BP神经网络。神经网络分类算法主要特点有:第一,神经网络具备很强的学习能力。第二,由于权值的作用,神经网络在有噪声的环境具有更好的鲁棒性。第三,人工神经网络分类算法对未经训练的数据也具有较好的预测分类能力。第四,因为人工神经网络是非线性模型,能够适应各种复杂的数据关系。同时人工神经网络分类算法缺陷也比较突出,主要是神经网络自身的建立问题。建设出一个比较完整的神经网络,学习过程较长,而且激活函数、优化函数、损失函数的选择与组合也会影响最终模型的准确性,工作难度也比较大。有学者提出在提取神经规则之前对网络进行剪枝以删除对分类准确性影响程度可忽略不计的神元和链枝,从而简化神经网络。其次与决策树分类算法相比神经网络可解释性差,对于非技术用户可能是较困难的事情。
3.4 基于统计学习理论的支持向量机分类算法
支持向量机(Support Vector Machines,SVM)是一种两分类模型,其目标是寻找一个满足分类条件的最优超平面,使得其能将两类样本分开,并且与两类样本的分类间隔最大。SVM是针对两分类问题提出的,而在实际应用中多类分类问题更为普遍。对于非线性分类问题,首先选择合适的核函数将样本空间映射到能线性可分的高维空间,然后利用最大化间隔的方法获取间隔最大的分割线,得出支持向量,最后利用分割线和支持向量对新的样本进行分类预测[5]。典型的算法有选块算法、分解算法、模糊支持向量机算法等。SVM算法的优点有:第一SVM算法对特征相关性不敏感,不需要特征独立性。第二SVM可以处理非线性数据集,可以用于处理文本分类、图像检测、人脸识别等问题。SVM算法缺点主要有:第一算SVM算法较为复杂,核函数参数选择困难。第二当样本数据较大时,需要较长的训练时间,效率较低。
4 结语
总的来说,经过系统化研究数据挖掘分类算法的方式,有助于我们了解掌握决策树分类算法、朴素贝叶斯分类算法、支持向量机分类算法、神经网络分类算法优缺点、适用场景,有针对性的进行缺点的优化改进。当然现阶段分类算法种类很多,需要我们不断总结研究。
