大数据Hadoop框架核心技术对比与实现
2021-03-23张国华王自然周婷婷
张国华,叶 苗,王自然,周婷婷
(南京师范大学泰州学院信息工程学院,江苏泰州 225300)
0 引言
Hadoop[1]是一个软件框架模型,主要用于以高效和可扩展的方式对大数据进行分布式信息处理,具有可靠性高、容错能力强、搭建成本低、跨平台等特点。它在处理半结构化,非结构化的数据方面优势明显,目前得到了广泛应用,社会对于这方面的技术人才需求量巨大,因其概念繁多,原理复杂,掌握其核心技术的人才较少。为将Hadoop生态系统理顺,本文从整体框架(见图1)分析,在整个生态系统中最为核心的两个技术,一个是HDFS[2]实现的基础数据的分布式存储,它利用集群存储数据的能力,扩展了计算机的存储能力。这个技术对比单机版的文件系统,例如Windows的文件系统FAT32,NTFS等就能区分其区别。其次是实现分布式并行编程模型MapReduce[3],它是利用廉价的计算机集群的综合处理能力来处理HDFS上的数据,相对于传统并行计算框架,无须昂贵的服务器就可批处理非实时的海量数据。

图1 Hadoop生态系统
仔细分析图1 及查阅相关文献,不难发现涉及对底层HDFS 数据处理的技术主要有MapReduce、Spark[4]、Hive、Pig等。为研究上述数据处理技术的区别及优势。本文以最为经典的分布式程序WordCount为例,设计了不同技术方法下的实验,对比其适用场景及优势,帮助学生迅速理解并掌握相关技术原理及方法。
1 技术原理与对比
1.1 MapReduce
MapReduce 是一种分布式并行编程模型,是Hadoop 生态系统中的最为核心和最早出现的计算模型,MapReduce借助集群的力量解决大型数据处理问题,其基本理念是“计算向数据靠拢”,采用分而治之的办法,首先数据分割Split,接着由集群中的计算节点进行本地Map 处理数据,Shuffle 分类数据,再Reduce汇总结果,该种模型可轻松解决TB 级别数据处理。基本流程如下图2 所示。
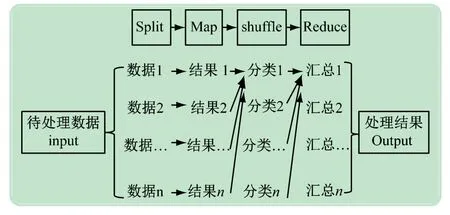
图2 MapReduce工作流程
这种技术也存在以下问题:①频繁访问HDFS,造成执行速度相对较慢;②过于低层化且笨重,所有的数据处理均需要编写Map 和Reduce 函数,技术复杂且耗费时间,也并不是所有的数据逻辑均可编写成这两个关键性函数;③在实时数据处理方面相对于传统技术无优势。为解决上述问题,出现了第2 代的计算技术代表Spark。
1.2 Spark
Spark技术并不是完全摒弃MapReduce 技术,而是对于MapReduce 技术的优化,具体优化体现在:①计算性能[5],Spark 充分利用服务器内存,减少频繁磁盘I/O读写来提升性能;②应用程序非常灵活,更容易实现。Spark核心代码是非常轻量级的Scala 文件[6],同时它也可以在各种编程语言中使用,包括目前流行的Java 和Python 语言,也可在Shell中进行交互式查询,更加精炼,易于掌握;③具备很强的处理实时数据能力。Spark通过Spark Streaming 技术进行数据的实时处理,包含了很多功能强大的应用程序接口,用户可以快速开发相关应用程序。对于数据处理,无论是MapReduce还是Spark 都离不开Map 和Reduce 的思想束缚,因此Hadoop生态系统中出现了更容易掌握类似于轻量级脚本语言[7]的技术Pig,及类似于通用关系型数据库语言Sql的技术Hive。
1.3 Hive
Hive是Hadoop 生态系统中的数据仓库工具,可以把数据文件抽象成数据表,并能提供类似传统关系型数据库结构化查询语言功能的专用语言HIVESQL(简称HQL),底层将HQL 语句转换为对应逻辑的MapReduce任务进行运行。主要适用场景为数据报表、频繁数据分析等领域,由于HQL 与SQL 类似,促使其成为Hadoop与其他智能工具进行结合的理想点,具备传统数据库基础知识即可快速掌握。
1.4 Pig
Pig[8]是比Hive 更加轻量级技术,可不涉及数据表,在大数据领域信息处理具备更加灵活、通用等特性,其核心主要采用了非常简洁的Pig Latin 脚本语言来转换数据流嵌入到较大程序中,适用于数据管道、机器学习等领域。
2 实验环境搭建与数据准备
WordCount程序[9]是分布式程序中的最经典和最简单的案例,类似于单机入门级程序HelloWord,主要是统计HDFS上出现单词的个数(区分单词是根据单词间空格),依次介绍在MapReduce、Spark、Hive、Pig的具体实现,并且易于还原,直观感受技术细节和区别,帮助深刻领悟技术特点和优势。
2.1 实验环境搭建
Hadoop有单机、伪分布式、完全分布式3 种运行模式,单机模式无集群的思维,无太大研究意义,不选择,完全分布式方式实现较为烦琐暂不采用而伪分布式能够使用一台计算机模拟集群工作,具备分布式思维且易于还原实现,且流程基本等同完全分布式系统,本文使用伪分布式完成以下实验,Hadoop 伪分布式及相关软件快速搭建步骤如下:
步骤1Windows 操作系统下安装虚拟机VirtualBox-5.2.16。
步骤2在虚拟机中导入互联网提供的(安装配置好Hadoop相关软件)Ubuntu 版操作系统的镜像文件。(下载URL:http://dblab.xmu.edu.cn/blog/),如有软件报错,根据虚拟机下方警告提示点击更换硬件配置即可。
步骤3跨操作系统数据存储解决办法,在虚拟机VirtualBox中通过设置选择USB设备,插入U盘,点击图3 红圈内添加对应品牌外部存储器至虚拟机中,可实现不同操作系统下文件的存储(见图3)。

图3 虚拟机中共享外部存储器
步骤4网络使用问题解决方法,在虚拟机VirtualBox中通过设置网络,选择桥接网络并全部允许,见图4 红圈,即可在Windows 和Ubuntu 操作系统中同时上网。
图4 虚拟机中网络配置
2.2 数据准备
在Ubuntu系统[10]随机生成100 个含有单词的txt文件,为了便于实现,采用了复制文件方式进行,并上传至HDFS中。具体实验步骤如下:
步骤1通过start-dfs.sh命令来启动整个hadoop集群(JPS查看集群启动结果)。
步骤2通过input 命令将本地系统的文件复制到集群HDFS 文件系统,将所有数据放入HDFS Myinput目录中。
步骤3通过URL 查看数据准备结果(http://localhost:50070)。
Hadoop软件安装配置复杂,很多初学者仅仅因为自己安装配置无法完成,购买相关大数据实验设备昂贵,因而放弃学习,本文通过上述方法,无须额外软硬件资本,即可完成基础实验平台搭建及数据准备。
3 实验核心代码与结果
以下实验均在伪分布式[11]下实现,使用单核Intel core i5-2450M CPU,内存8GB,SSD 硬盘,其中内存4GB分配给虚拟机。
3.1 WordCount—MapReduce版本
(1)核心代码。

(2)实验步骤与结果。将核心代码Mywordcount.java编译打包成Mywordcount.jar包。进入相关目录通过执行./bin/Hadoop/jar Mywordcount.jar Myinput Myoutput。在Myoutput文件夹中会出现统计结果为两个文件,最后通过dfs -cat Myoutput/*命令显示词频,如图5所示结果,分别标出了词频次数和对应的单词,此实验如果重复执行MapReduce,应注意初始化名称节点并删除临时文件夹,否则统计结果无法覆盖。MapReduce编写的代码量较长,时间复杂度也较高。通过实验过程和结果证明了本文1.1所述的特点和问题。

图5 MapReduce执行结果
3.2 WordCount—Spark版本
Spark实现的方式可以有多种,例如Scala 语言,Spark本地类库,JAVA 语言等,本文采用了Scala 语言,统计与3.1 相同的数据集。
(1)核心代码。

(2)实验步骤与结果。创建一个SparkConf 对象[12],设置处理数据的地址等主要配置信息,接着创建SparkContext 对象,它是Spark 所有功能的入口,无论采用何种方式均需实现,最后启动HDFS 和相关服务,编写执行核心代码,实验结果类似图5,时间复杂度降低。通过实验过程和结果证明了本文1.2 所述的特点和问题。
3.3 WordCount—Hive版本
(1)核心代码。

(2)实验步骤与结果。在Hive[12]中创建一个临时表Mytable,其次通过执行shell命令load data inpath'/1.txt'overwrite into table Mytable将数据导入到表中,最后通过执行Hivesql命令即可完成统计,统计类似图5。通过实验过程和结果证明了本文1.3 所述的特点和问题。
3.4 WordCount—Pig版本
(1)核心代码

(2)实验步骤与结果。该实验直接使用简洁的脚本语言Pig Latin[13],主要步骤为数据加载,区分单词,单词分组统计等,无论是书写代码的难度、通用性还是灵活性都大大提升。实验结果类似图5,通过实验过程和结果证明了本文1.4 所述的特点和问题。
3.5 实验结果对比
通过对上述4 个实验实现,学生对比实验步骤和核心代码,可清楚了解分布式并行计算的MapReduce的工作原理及问题,但其Map 和Reduce 函数较难编写和理解,通过Spark 优化了MapReduce 实时数据处理等问题,而Hive 使用了类似传统关系型数据库Sql的Hivesql语言[14]来解决分布式数据库HIVE 表中数据处理问题,有数据库基础的学生易于适应和掌握,最后的脚本语言Pig Latin 通过脚本能自动生成底层MapReduce程序,并且无需考虑函数参数限制,具备更强的通用型[15],大大降低了程序开发难度。
4 结语
通过上述4 个对比实验,使得学生理解分布式并行处理技术的核心框架,循序渐进掌握Hadoop核心处理技术,理顺大数据关键技术之间的关系,通过对经典分布式程序WordCount案例的技术对比,直观体会;领悟技术优化过程、适用场景,希望通过对比试验不仅能给学生带来一些技术和原理上的开拓性思考,而且也能给教师培养创新且务实的大数据人才提供一些启示。
