松耦合图卷积文本分类网络
2021-03-22徐林莉
肖 驰,徐林莉
(中国科学技术大学 计算机科学与技术学院,合肥 230027)
1 引 言
随着信息技术的快速发展,互联网上文本信息资源不断累积,如何快速、有效地处理这些文本信息资源是当前研究的重要问题.文本分类技术被认为是解决这一问题的重要技术手段.作为自然语言处理的基础性技术,文本分类已经被广泛应用于垃圾邮件判别[1]、新闻筛选[2]和舆情分析[3]等任务中.
早期的文本分类模型大多基于机器学习方法,该类模型通常使用词频(TF)或者词频-逆文档频率指数(TF-IDF)等作为特征,采用朴素贝叶斯(Naive Bayes)、支持向量机(SVM)等机器学习方法作为分类函数.这类基于机器学习的模型存在特征稀疏、模型表达能力不足等问题.随着深度学习的发展,神经网络模型因其出色的特征提取能力而被广泛应用到文本分类任务当中.Kim等[4]提出基于卷积神经网络(CNN)的分类模型,该模型使用卷积和池化操作提取文本局部语义信息,并将最后一层网络的结果作为全文特征进行分类.Liu等[5]使用长短期记忆网络(LSTM)对语句的序列信息进行建模,并将网络最后一个隐层状态作为文本表示.然而上述神经网络模型只能捕捉局部语义信息,无法对单词的全局共现关系进行建模[6].
近年来,图神经网络(Graph Neural Network,GNN)因其处理不规则图结构的出色能力而受到广泛关注.Defferrard等[7]首先将图卷积网络引入到文本分类任务中,Yao等[8]在此基础上提出图卷积文本分类模型Text-GCN.Text-GCN模型将语料库中的训练文本、测试文本和单词都作为节点组织到同一张网络中,然后利用图卷积网络[9]提取节点特征并对文本节点进行分类.该方法在多个开源数据集上取得了当前最好分类效果.
上述基于图卷积网络的分类模型采用紧耦合方式处理文本分类问题,这种紧耦合方式在实际使用中会导致以下两个问题.首先,该模型将文本和单词都作为同一张图中的节点进行构图,这导致图的尺寸会随着文本数量和词表大小而变化.通常,语料库的词表大小较为稳定,而文本数目变化较大.当语料库中文本数目变大时,图的尺寸随之变大.相应地,模型会消耗大量内存并可能导致内存错误.此外,紧耦合方式降低了模型的灵活性,给模型使用者带来不便.譬如,上述模型将训练文本、测试文本和单词组织到图中后,图的大小和结构随之固定.当出现新的测试文本时,图的结构不能随之做出修改,也就是说,该模型无法动态地处理新来样本.紧耦合方式导致的上述问题限制了图卷积文本分类模型的使用场景,严重制约了该模型在实际项目中的应用.
为解决上述问题,本文提出了一种松耦合图卷积文本分类网络模型(Loosely Coupled Graph Convolutional Neural Network,LCGCN).不同于紧耦合方法将语料库组织成一张网络,该模型将语料库分解成核心网络和文本-单词网络两个部分.核心网络的节点由单词和标签构成,反映单词和单词、标签和单词之间的关系.文本-单词网络由文本和单词构成,反映文本和单词之间的关系.实际运行时,模型先在核心网络上运行图卷积操作,提取单词和标签的向量表示.然后,模型通过文本-单词网络和第一步提取的单词表示相乘得到文本的向量表示,最后将文本向量表示输入到分类器中进行分类.通过上述步骤,该模型完成了对原始紧耦合模型的解耦操作,从而使得模型具备松耦合的特性.具体来说,本文具有以下创新点:
1)针对紧耦合方式导致的问题,本文提出松耦合图卷积文本分类网络模型.该模型能够在保证分类效果的基础上,极大地减少内存开销并且能够动态地处理新样本;
2)模型将标签信息引入到核心网络中,通过图卷积操作捕捉单词和标签之间的关系,进一步提升分类效果;
3)我们在多个公开数据集进行实验,与其他文本分类方法的对比结果显示了我们模型的有效性.
2 相关工作
2.1 文本分类
文本分类任务是自然语言处理领域内的基础性任务,它一直是学术界和工业界的重要研究问题.现有的文本分类模型可以分为基于机器学习的方法和基于深度学习的方法两大类.基于机器学习的方法大都使用手工构造的特征,利用机器学习模型作为分类函数.Trstenjak 等[10]使用词频-逆文档频率作为文本特征,使用最近邻方法(KNN)方法作为分类函数.但是词频-逆文档频率是一种表层特征,它无法揭示单词的潜在联系.为了捕捉文档中单词间的潜在语义结构信息,Shima等[11]使用潜在语义索引方法(LSI)来提取文本的低维向量特征,并使用支持向量机(SVM)来指导提取过程.基于深度学习的文本分类模型大多借助神经网络强大的特征提取能力自动地学习文本特征并进行分类.Kim等[4]使用CNN提取文本局部语义特征,Liu等[5]使用LSTM对文本进行建模.Zhou等[12]结合LSTM和CNN中最大池化操作(Max Pooling)的优势,提出BLSTM-2DCNN.这些神经网络擅长于捕捉连续局部文本片段的语义信息,但是无法较好地对单词全局关系和长距离语义信息建模[6].不同于上述神经网络,本文提出的方法借助于图卷积网络对单词的全局信息进行建模和特征提取.
2.2 图神经网络
传统神经网络模型在处理欧几里得结构数据时展现出出色的特征提取能力,但是这类模型无法应用到非欧几里得结构的数据上,如化学分子[13]、引用网络等.处理非欧几里得结构数据的难点在于数据的不规则性.譬如,一个不规则网络中的节点没有先后顺序,每个节点的邻居个数也不尽相同,这些问题导致模型无法在网络上运行传统的卷积操作.为了将深度学习应用到非欧几里得结构数据上,许多研究人员开始探索图神经网络模型[14,15].Niepert等[13]从将不规则图结构数据转化为规则结构数据的角度,提出针对任意图结构的图规范化框架,该模型在多个化学化合物分类数据集上取得了当时最好效果.Yu等[16]提出时空图卷积模型(STGCN)来解决交通领域的时间序列预测问题.Yao等[8]将文本和单词当作节点组织到同一张网络中,并使用图卷积网络提取节点特征进行分类.相比于传统的神经网络,图神经网络具有处理复杂网络结构、捕捉全局语义特征等优点,因而受到越来越多的关注.不同于上述将图卷积网络应用到文本分类任务中的工作,我们希望设计一种松耦合的、使用灵活的图卷积文本分类模型.
3 松耦合图卷积文本分类网络
本小节中,我们先介绍图卷积网络模型的基本内容,然后展示松耦合图卷积文本分类网络的设计思路和构图步骤,最后我们介绍分类模型的整体框架和运行细节.
3.1 问题描述
给定文本语料库的标签集合L={l1,l2,…,lL},词表集合V={v1,v2,…,vV},文本集合X={D1,D2,…,DN},单标签文本分类的任务就是给文本集合中的每篇文本Di={wi1,wi2,…}分配一个最有可能的标签yi,其中文本的单词wij∈V,预测标签yi∈L.
3.2 图卷积网络
卷积神经网络适用于处理欧几里得结构(Euclidean Structure)的数据,如形状规则的图片,因此卷积神经网络在计算机视觉领域取得了较大成功.对于非欧几里得结构数据,如图结构数据,传统的卷积神经网络难以使用卷积操作提取特征.为了处理非欧几里得数据,研究人员提出图卷积神经网络模型(GCN).GCN的出发点是利用图中其他节点的状态来更新自身状态,从而学习到图中节点的关系.假设给定输入数据X,图G的邻接矩阵A,图卷积模型通过公式进行卷积操作,更新节点特征向量
(1)

3.3 松耦合图卷积文本分类网络模型
在先前的研究中,Yao等[8]将文本和单词作为节点组织到同一张网络中,然后对该网络进行图卷积操作,从而得到训练文本、测试文本和单词的特征表示.这是一种紧耦合的处理方式,该方式使得模型不够灵活.在本小节中,我们提出一种松耦合的图卷积文本分类网络LCGCN.
松耦合模型的出发点是将分类模型的核心特征提取部分和一般计算部分分解开来,实现高内聚、低耦合的特性.单词是文本的基本构成要素,单词的语义直接影响了文本的含义.我们认为单词的特征提取是松耦合图卷积网络的核心部分,因此语料库中的单词被组织到核心网络中进行学习.在实际生活中单词通常会和特定的标签相关联.譬如,当我们讨论“足球”这个词汇时,我们更容易联想到“运动”这个标签,而不会想到“金融”.从这个例子,我们可以发现单词的含义与标签有着直接的联系.因此,标签也被作为节点整合到核心网络中,与单词一起进行特征提取.另一方面,文本是由一组单词序列构成,文本的语义表示可以通过单词的语义表示计算得到.因而,文本的语义计算属于一般计算部分,文本与单词的关系被组织成另外一张网络.
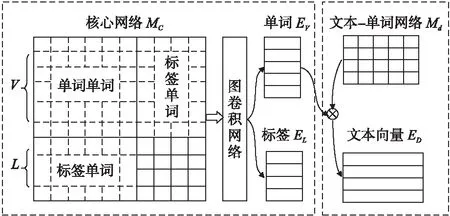
图1 松耦合图卷积文本分类网络Fig.1 Loosely coupled graph convolutional neural network
按照上述分析,松耦合图卷积文本分类模型将语料库组织成两张网络:文本-单词网络Md∈Rn×V和核心网络Mc∈R(V+L)×(V+L).如图1所示,核心网络包含单词和标签两类节点,单词与单词节点之间边的权重反映单词与单词之间的共现关系,标签与单词节点之间边的权重体现标签与单词之间的语义相关关系.在实际建模中,单词与单词之间的权重使用两个单词之间的点互信息(PMI)来计算,该指标反映了两个单词之间的相关关系.点互信息值越大,说明两个单词语义上越相关,反之,两个单词的相关性越小.标签与单词之间边的权重使用公式(2)计算:
(2)
其中p(j|i)表示单词j在给定标签i的文本中出现的频率,p(j)表示单词j在整个语料库中出现的频率.当单词在某个标签的文本中出现的频率越大,在整个语料库中出现的频率越小,说明单词与该标签的相关程度就越高.文本-单词网络中文本与单词之间边的权重使用单词的TF-IDF值来表示.
如图1所示,松耦合图卷积模型先在核心网络Mc上使用公式进行图卷积操作以提取单词特征向量EV∈RV×d和标签特征向量EL∈RL×d.接着,模型使用文本-单词矩阵Md和单词特征向量EV相乘得到文本的向量表示ED∈Rn×d.通过上述两个连续步骤,该方法将提取单词特征向量和构建文本向量表示的过程分解开来.在实际运行时,只有核心网络会参与到图卷积运算中,文本-单词网络在后续步骤中用来计算文本向量.因此,模型的内存消耗大部分来自于核心网络的卷积计算,它不会随着文本数量增多而变大.另一方面,当出现新的测试样本时,模型只需要构建新测试文本的文本-单词网络并计算文本向量表示,然后将计算得到的文本向量输入到分类器中进行分类.通过上述方法,模型能够根据实际应用需求,便捷地处理新来测试样本.
3.4 模型框架
图2展示了分类模型的整体框架,该框架分为核心网络特征提取、分类和匹配3个子模块.

图2 模型整体框架Fig.2 Frameword of the model

(3)

(4)
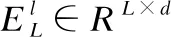
(5)

(6)

4 实 验
4.1 实验数据集
为了验证模型有效性,我们在5个开源数据集上做了文本分类实验,包括 20-Newsgroups(1)http://qwone.com/~jason/20Newsgroups/、Ohsumed(2)http://disi.unitn.it/moschitti/corpora.htm、R52(3)https://www.cs.umb.edu/~smimarog/textmining/datasets/、R8和 Movie Review(MR)(4)https://github.com/mnqu/PTE/tree/master/data/mr.实验数据集的划分和处理方式参考Yao等[8]的实验设置,数据集详细信息表1所示.

表1 文本分类数据集统计信息Table 1 Details of text classification datasets
4.2 对比方法
实验中,我们选取了基于CNN、RNN和GCN 3类神经网络的方法作为对比实验,相关方法介绍如下:
·CNN Kim等[4]提出使用CNN对文本中单词的向量矩阵进行卷积操作从而提取文本向量并进行分类;
·LSTM Liu等[5]使用LSTM网络对文本序列信息建模,并使用网络的最后一个隐层状态作为文本的特征表示进行分类;
·Text-GCN Yao等[8]使用紧耦合的方式将语料库中的训练文本、测试文本和单词组织到同一张网络中,然后使用图卷积神经网络提取节点特征并对测试文本节点分类,该模型取得了当前最好效果;
·Text-level 该模型由Huang等[18]提出,用以解决Text-GCN消耗内存过大等问题.模型对单篇文本进行构图,然后使用图卷积网络学习文本特征并进行分类.
4.3 实验结果
表2展示了各模型在实验数据集上的分类准确率,带星号部分表示模型使用预训练词向量作为初始化词向量,各对比模型的实验结果来源于文献[8,18].
从表2中我们可以发现,相比于CNN、LSTM等传统神经网络模型,基于图卷积网络的分类模型都表现出良好的分类性能.譬如,在Ohsumed数据集上,基于图卷积网络的模型有大约10个百分点的提升.这些结果说明GCN网络能够给文本分类任务带来有效提升.这可能是因为GCN模型能够对单词的全局共现关系进行建模,通过图卷积操作后,模型能够为每个节点学习到准确的向量表示.我们还注意到,在使用预训练词向量的情况下,LCGCN模型比Text-GCN模型平均提升了约1个百分点.提升主要来自两部分:1)模型在核心网络和匹配模块中引入了标签信息,使得整个模型具备更强的表达能力;2)模型采用拼接多层特征的方法缓解图卷积网络的过度平滑问题.我们还注意到在Ohsumed数据集上,LCGCN模型的分类结果比Text-level模型略差,但是依然排在第2位.这可能是因为Ohsumed数据集单词词表相对较大而训练数据相对较少,这导致LCGCN模型的泛化性能受限.

表2 模型分类准确率Table 2 Test accuracy of models
4.4 网络尺寸对比
图3展示了Text-GCN和LCGCN模型中网络节点的个数.从图中可以看出,LCGCN模型的网络尺寸明显小于Text-GCN模型的网络尺寸,且当语料库中文本数目越多时,网络尺寸减小越明显.Text-GCN将语料库中的训练文本、测试文本和单词都当作图中的节点进行构图,网络尺寸会随着文本数量和单词词表大小而变化.LCGCN通过松耦合方式将语料库组织成两张网络,其中核心网络的尺寸只与单词词表大小和标签个数有关.因此,LCGCN模型中网络的尺寸能够控制在合适的范围内,从而避免消耗过多内存.

图3 网络尺寸对比Fig.3 Comparison of network size
4.5 松耦合图卷积网络的拓展能力
松耦合图卷积网络将特征提取步骤分解成核心特征提取和一般计算两个步骤,从而使得模型具备高内聚、低耦合的特性.该特性使得模型具备良好的移植拓展能力.为了展示松耦合图卷积模型的灵活性,本实验将LCGCN网络移植到LSTM模型上.具体地说,我们将LCGCN模型的核心特征提取模块插入到LSTM模型之前.每步迭代时,LCGCN网络将提取得到的单词向量作为LSTM模型中单词的初始向量,然后使用LSTM网络对文本序列进行建模分类.

表3 LSTM性能对比Table 3 Comparison of LSTM
表3展示了各模型在3个数据集上的分类准确率.从表中可以发现,加入LCGCN模块的LSTM模型能够在模型原有基础上提升文本分类性能.譬如,在R52数据集上,我们模型的分类准确率比LSTM模型高8个百分点,比使用预训练词向量初始化的LSTM方法高3个百分点.这说明LCGCN网络学习得到的单词向量表示较好地捕捉了单词的语义信息.该实验显示,LCGCN模型只需要通过简单的修改便可以与传统神经网络相结合,并且能够在原始模型的基础上带来性能提升.
5 结论和展望
本文提出了一种松耦合图卷积文本分类网络模型.该模型能够在保持分类性能的基础上,极大地减少原始图卷积网络的内存开销.另一方面,由于松耦合的特性,该模型能够根据实际需求动态地处理新来样本.此外,该模型还具备良好的移植能力,它能够与其他神经网络相结合提升原始模型的效果.在接下来的工作中,我们希望将图卷积神经网络应用到多标签分类任务中.
