一种基于音频分割的音频分类算法*
2021-03-21杨贵安邵玉斌杜庆治
杨贵安,邵玉斌,龙 华,杜庆治
(昆明理工大学,云南 昆明 650500)
0 引言
在如今信息爆炸的时代,互联网、广播和视频中充斥着大量的音频信息,语音和音乐是音频数据中最重要的两类。在音频检索、语音识别、语音文字转换以及新闻摘要抄录等领域中都需要音频分类这项预处理技术以提高整体工作效率,降低错误率。
音频分类的关键在于音频特征选取,现有技术通常在频域和时域内寻找区分度明显的特征用于音频分类。例如文献[1]选取过零率和频谱作为特征,文献[2]选取二号逆Mel滤波器(Energy Variance of Inverse Mel Filter No.2,EVIMF2)的能量方差作为特征,两篇文献中分类准确率最高为文献[1]的99.3%,但两篇文献均以1秒作为分类单元,对精度小于1秒的音频类型变化片段难以进行准确划分。文献[3]选取过零率(Zero-Crossing Rate,ZCR)的平均值和标准差等7维数据作为特征,文献[4]选取短时能量和短时平均过零率等117维数据作为特征,两篇文献在特征提取部分计算量较大,对音频最终分类效率造成影响。文献[7]、文献[8]、文献[9]均以单一语音和音乐的混合音频作为分类对象。文献[7]对数梅尔能量、调制频谱等特征进行非线性映射和组合用于混合音频的分割及分类,在特征计算上将耗费较多时间和资源。文献[8]采用较新的深度置信网络算法对混合音频进行分割及分类,但以实验结果来看最终分类准确率93.94%有待提高。文献[9]将一维音频信号处理和二维图像信号处理结合起来提取多个特征用于音频分类,其最终分类准确率95.68%仍然不是最佳效果。
因此,本文提出一种基于音频分割的音频分类算法,对待分类音频先进行分割再进行分类。在分割阶段,结合能熵比和文献[1]中提到的幅度均方根(Root Mean Square,RMS)实现音频分割,音频分割目的是检测出所有音频类型变化点,而基于能熵比的音频分割中以8 ms为帧移逐帧进行计算,所以对音频类型变化点的检测能精确到8 ms。音频分割对单一音频不存在过分割现象,因此不会对单一音频分类结果产生影响,对混合音频而言可能存在过分割现象,此问题在同类型的相邻音频段合并时得到解决。文中用统计方法证明了选取幅度的峰态系数和平均基频作为分类特征的可行性,因此在分类阶段,对分割所得音频段提取幅度的峰态系数和平均基频两个特征,并利用高斯混合模型作为后端分类器进行分类,将同类型的相邻音频段合并便得到最终分类结果。仅提取二维特征的先分割再分类算法不仅提高了分类效率,还获得了良好的分类效果。
1 音频分割
音频分割需要两个步骤,第一步基于能熵比特征进行分割,第二步基于幅值均方根特征进行分割。将第一步中满足阈值条件的结果与第二步的结果进行组合形成新的音频段,即音频分割结果。
1.1 基于能熵比的音频分割
说话人在讲话间隙会出现停顿,所以语音信号存在大量静音段,而音乐本身呈现的连续性较好,音乐信号一般不存在静音段,因此两类音频信号的能熵比在时间轴上高于设定能熵比阈值的点的密集程度会有所区别,如图1(b)所示为能熵比高于0.05的点,利用此特点对音频进行分割。
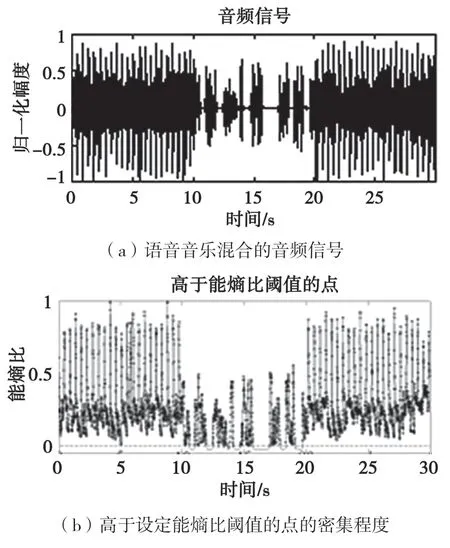

图1 基于能熵比的音频分割
待分割音频以32 ms为帧长,8 ms为帧移进行分帧,一帧信号数据的能熵比(Energy entropy ratio,Er)计算如下:
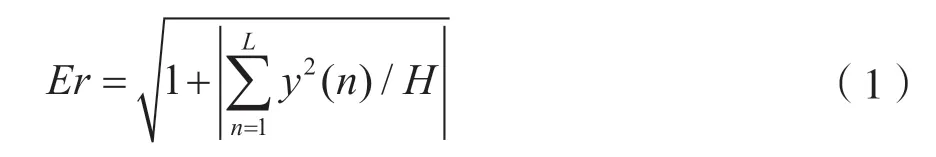
式中,y(n)为一帧信号中第n个采样点所对应的幅度,n=1,2,3,…,L,L为帧长,H为一帧音频信号的谱熵值。
一段音频内帧信号的能熵比(Er)大于0.05的其中两帧为第r帧和第s帧,其中r<s,若s-r大于1,则第r帧处为一个分割点。分割结果如图1(c)所示,可以看出音乐信号的分割较为准确,而语音信号被分割为非静音段和静音段,即对语音信号进行了过度分割,此问题在基于幅度均方根的音频分割中将得到较好的解决。
1.2 基于幅度均方根的音频分割
待分隔音频以20 ms为帧长,零帧移进行分帧,50帧即1 s作为一个单元,幅度均方根(RMS)计算如下:

对于每一个单元而言,不同参数的广义x2分布很好地拟合了语音和音乐信号的幅度均方根统计直方图[5]。两个单元之间的相似度表示如下:
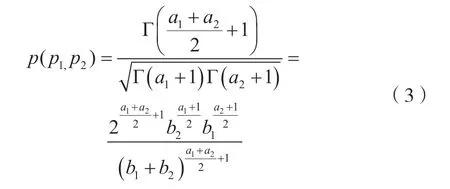
式中:


式中,σi和μi为第i个单元信号幅度均方根的均值和标准差。
对于第i个单元,其相邻两个单元的音频类型是否发生变化由单元之间相似度的距离来决定,距离计算如下:

若相邻单元的音频类型发生变化,其相似度距离D(i)较大,反之D(i)较小。
由于音频信号活动是时变的,因此对D(i)进行局部标准化[5],计算如下:

式中,V(i)为当前单元距离D(i)与前后相邻两单元距离的均值之差,即

DM(i)为与当前单元前后相邻两单元距离的最大值,即

音频信号的归一化距离如图2(a)所示。在所有小于1的Dn中寻找出最大值并求其二分之一作为阈值,大于阈值的Dn所对应的时间点即为音频的分割点。分割结果如图2(b)所示,语音信号的分割较为完整,但是对音频信号的分割不够准确。

图2 基于幅值均方根的音频分割
因此需要结合两种分割方法的优点,使得分割点尽可能精确。将基于能熵比的音频分割结果中帧数大于T1或帧数减去T2再除于T2取整不为0的音频段与基于幅度均方根的音频分割结果进行组合,T1、T2的计算如下:

式中,fs为音频的采样率,I为基于能熵比的音频分割中分帧时所设帧移。

式中,v为基于能熵比的音频分割结果中所有音频段的帧数。
音频分割的目的是检测出所有音频类型的变化点,而基于能熵比的音频分割中以8 ms为帧移逐帧进行计算,所以对音频类型变化点的检测能精确到8 ms。整个音频分割过程如图3所示,将两种分割方法分割所得音频段的起始点和终止点升序排列并两两组合形成新的音频段作为音频分割结果。音频分割结果如图4所示,语音/音乐信号内部仍存在分割点,此类分割点在音频段分类后进行同类型的相邻音频段合并时可消除。
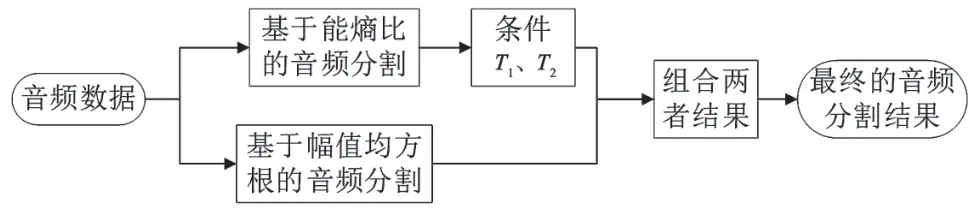
图3 音频分割过程
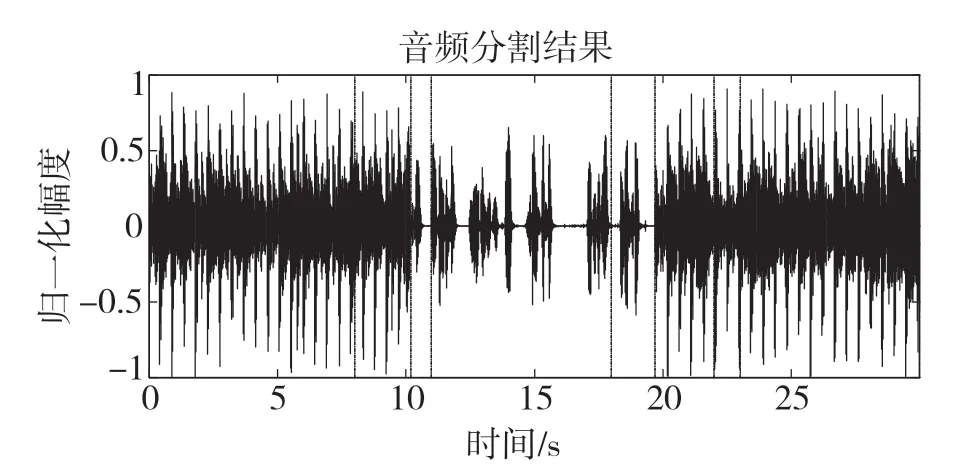
图4 音频分割结果
2 音频特征选取
选取区分度明显的音频特征用于音频分类既可以降低所提取特征的维度,又能保证分类的准确率。本文选取幅度的峰态系数和平均基频作为分类特征。
2.1 幅度的峰态系数
观察语音和音乐信号的波形可以发现两者有较大差别,因此波形的统计特征可以用其幅度的概率密度函数来描述,而峰态系数是表征概率密度分布曲线在平均值处峰值高低的特征数,一段音频信号幅度的峰态系数K计算如下:

式中,N为音频信号采样点数,xj为音频信号第j个采样点所对应的幅度。
图5为采样率8 kHz,时长10 s,单声道的150段音乐信号(包括各种风格的歌唱声、乐器音等)和150段语音信号(包括男女混合音、男音、女音)幅度的峰态系数统计图。统计结果表明,音乐信号幅度的峰态系数大部分集中在5附近,而语音信号幅度的峰态系数大部分集中在10附近,这是因为音乐信号波形更连续,其幅度范围广泛,概率密度分布曲线平缓,所以峰态系数较小,而语音信号波形较离散,其幅度更集中于某一个值,概率密度分布曲线陡峭,所以峰态系数较大。
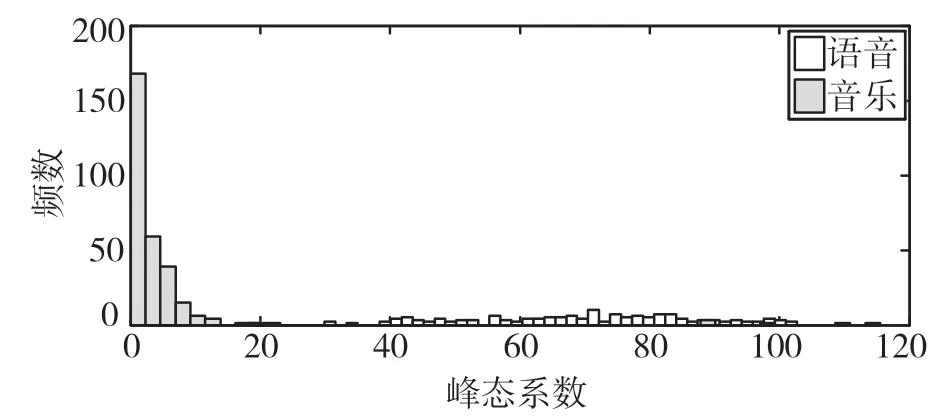
图5 音频信号幅度的峰态系数统计直方图
2.2 平均基频
基音频率是语音信号的一个重要属性,可以作为区分语音和音乐信号的一个特征,因此对基频进行进一步统计分析。本文采用传统的倒谱法计算基音频率,对每一段音频的基音频率求均值并进行统计。图6所示是对各150段音乐信号和语音信号的平均基频进行统计的结果,可以看出语音信号的平均基频主要分布在100~200 Hz,而音乐信号的平均基频主要分布在200~350 Hz。

图6 音频信号平均基频统计直方图
对分割所得音频段提取幅度的峰态系数和平均基频两个特征,并利用高斯混合模型作为后端分类器进行分类,将同类型的相邻音频段合并便得到最终分类结果。最终分类结果如图7所示,字母“M”代表音频段类型为音乐,字母“S”代表音频段类型为语音。

图7 音频最终分类结果
3 语音/音乐分割与分类实验及分析
以MATLAB为平台进行算法实验,实验所使用的音频包括单一语音、音乐音频及其两者的混合音频,音乐含有经典、蓝调、流行和爵士等七种风格,语音来自中国之声和清华大学王东教授的语音数据集,所有音频均为采样率8 kHz、16位精度的单声道Wave文件。
实验使用时长3秒的单一语音和单一音乐音频各150段训练高斯混合模型,对300段待识别音频进行识别测试,300段音频包含时长为10 s、5 s、3 s、2 s和1 s的单一音乐和单一语音音频各30段。音频分类准确率计算如下:

分类结果如表1所示。

表1 单一音频分类结果
分类结果表明上述所提取的两个特征用于音频分类是非常有效的。
实验使用15段5 s和60 s单一语音和音乐的混合音频进行分割和分类测试。分类时,若分割时间与人工标注的时间相差超过0.5 s,就认为分割时间和标准时间之间的音频段是错误分类[6]。分类精度定义为:

分类结果如表2所示。分类后,同类型的相邻音频段进行合并便得到最终分类结果。

表2 混合音频分类结果
将漏检和多检(譬如实际只有一个分割点,却被检测为多个分割点)定义为检测错误,结果如表3所示。

表3 混合音频分割结果
通过表2和表3的实验结果数据可以看出,针对单一语音和音乐的混合音频而言,本文结合两种不同分割方法的优点进行音频分割的方式效果理想,正是由于对音频分割点(音频变化点)的计算较为准确,因此对混合音频的分类效果和对单一音频的分类效果能达成一致,准确率仍能达到98.61%。分类的准确性降低了同类音频合并时出错的概率,因此对过分割点的消除也更为准确,最终混合音频分割准确率达到98.24%。与年份较近的文献[7-9]相比较,本文提出的音频分割和分类算法在保证准确率的前提下,仅提取二维特征,大大降低了运算量,能更好满足实时性要求,且从实验结果来看,最终分类的准确率比文献[8]提高了4.67%,比文献[9]提高了2.93%,准确率平均提高3.80%。综合实际情况分析,本文所提出的音频分割和分类算法计算量小、效果稳定、整体结构易于实现,具有一定的实际应用价值。
4 结语
本文提出了一种基于音频分割的音频分类算法。首先结合基于能熵比特征和基于幅度均方根特征的两种分割方法对待分类音频进行分割,对分割所得音频段提取幅度的峰态系数和平均基频两个特征,并利用高斯混合模型作为后端分类器进行分类,将同类型的相邻音频段合并便得到最终分类结果。与现有分类算法相比,本文提出的算法对单一语音和音乐的混合音频进行分类更为适用。本文算法具有很高的分割准确率,仅提取二维特征便得到较高的分类准确率,既减小了特征计算、建模等时间代价,又提高了对单一语音、音乐音频及其混合音频进行分类的效率和准确率,算法效果稳定、整体结构易于实现,该语音/音乐分割与分类算法具有一定可行性和实用性。在后续工作中,考虑使用更多音频样本测试本文算法的分类准确率。
