无人车驾驶场景下的多目标车辆与行人跟踪算法
2021-03-21顾立鹏孙韶媛刘训华宋奇奇
顾立鹏,孙韶媛,李 想,刘训华,宋奇奇
(东华大学 信息科学与技术学院,上海 201620)
1 引 言
多目标跟踪(Multi-Object Tracking,MOT)是计算机视觉领域的一个研究热点,在自动驾驶、机器人续航、视频监控与行为分析等领域发挥着重要的作用[1].相比于单目标跟踪,多目标跟踪主要是在输入的视频中定位多个目标,维持它们的ID不变,并形成各自的轨迹,因此更复杂、更具挑战.近10年来,随着深度神经网络的迅速发展,基于检测的多目标跟踪算法受到了广泛的关注.这类方法主要将多目标跟踪问题分为两个步骤:第1步,使用目标检测网络检测出给定视频序列中每一帧存在的感兴趣的目标;第2步,使用数据关联算法将检测到的目标随着时间推移,分配各自的ID,并生成各自的轨迹[2].
尽管已经过多年的研究,多目标跟踪算法的性能仍还远未达到人类的水平.当前该问题面临的挑战主要包括:未知的目标类别及数量;目标之间频繁的遮挡;目标的漏检或误检等[1].针对上述问题,目前的解决方法大多集中在以下几个方面:优化提升目标检测网络性能、设计更具表现力的目标特征模型、设计更高效的数据关联算法[3].对于优化提升目标检测器性能,Zhou[4]等人提出了CenterNet网络,利用关键点估计来确定潜在目标的中心点,并回归出宽高尺寸、偏移量等目标,具有整体网络计算开销小、精度高且速度快等优点.Shang-Hua Gao[5]等人提出了Res2Net模块,其可被便捷地嵌入到现有的目标检测网络中,在不增加网络整体计算开销的基础上,提升目标检测网络的性能.针对设计更具表现力的目标特征模型,Bo Li[6]等人提出的SiamRPN网络,通过将孪生网络和区域推荐网络结合到一起实现对初始帧的给定目标的跟踪,前者用来提取目标在上一帧的区域和在当前帧的两倍区域的卷积特征,后者用来推理出该目标在当前帧的状态.针对优化数据关联算法,Leal-Taixé[7]等人使用孪生网络提取局部时空域特征,再根据两个检测到目标的时空域特征的响应之间的几何距离,得到两个检测到目标之间的关联概率,最后用匈牙利算法对相邻帧检测到的目标进行关联.
受上述启发,为了解决无人车驾驶场景下的多目标跟踪所面临的各种问题,本文从优化目标检测器和数据关联算法两个方面,提出了一种无人驾驶场景下的多目标车辆与行人跟踪算法:1)提出了Res2Net_plus模块,具体是在Res2Net模块中嵌入了1×1卷积和SE-Net模块,以融合空间信息和通道信息,提升网络对目标区域特征的提取能力;2)用CenterNet网络作为目标检测器,并用Res2Net_plus模块替代网络原有的残差单元,以进一步提升CenterNet网络对无人车驾驶场景下车辆和行人的检测精度;3)受SiamRPN网络启发,将其网络一分为二,孪生网络部分设计为关联概率网络,进行基于外观特征的关联概率度量,而区域推荐网络部分设计为辅助跟踪器,来对历史帧中的漏检或消失又出现的目标进行持续跟踪,并将可靠的跟踪结果合并到存在的轨迹中;4)设计了一种基于目标外观特征和位置信息融合的匹配策略,具体是孪生网络对检测到目标所在区域的外观特征进行提取,作为主要的匹配依据.同时,目标的位置信息作为辅助匹配依据,用于剔除外观相似但在两帧中所处的位置较远的虚假匹配关系.在KITTI跟踪基准数据集上的实验结果表明,与已有的方法对比,本文方法具有竞争力,尤其对于因目标检测器的漏检或目标的消失又出现所导致的跟踪轨迹不连续或目标ID频繁切换的问题有很大的改善作用.
2 多目标跟踪框架
本文提出的无人车驾驶场景下的多目标检测算法由目标检测网络、关联概率网络和数据关联模块3部分组成,算法整体框图如图1所示.其中,①为输入视频序列;②为目标检测网络检测每帧的车辆与行人;③为提取目标外观和位置信息,并经过关联概率网络,得到关联概率矩阵;④为经过数据关联模块,得到车辆与行人跟踪结果(目标的ID和包围框坐标).

图1 算法整体框图Fig.1 Algorithm block diagram
2.1 目标检测网络
目标检测网络对基于检测的多目标跟踪器的整体性能有着至关重要的影响,这是因为目标检测网络的误检或漏检将造成目标ID的频繁切换或目标轨迹的断开等问题[8].因此,一个兼顾精度和速度的目标检测网络对多目标跟踪算法十分重要.
2.1.1 CenterNet网络
本文选取了CenterNet网络作为多目标跟踪的目标检测器.不同于基于锚框的检测网络,CenterNet网络将目标检测问题巧妙地转换成关键点估计问题,利用关键点估计来确定目标的中心点,同时在中心点处回归出该目标的其他属性,如宽高尺寸、中心点的偏移量等.这使得该网络在整体计算开销相对较小的情况下,拥有很好地提取并利用目标内部的信息的能力,实现了潜在目标的检测,因此具有其精度高且速度快的优点,尤其对于无人车驾驶场景下数量多且有频繁遮挡的车辆与行人具有很好的检测能力,网络结构图如图2所示.
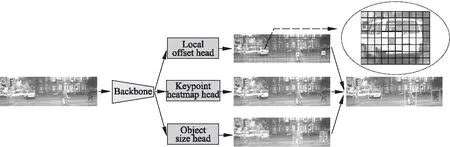
图2 CenterNet网络结构图Fig.2 Network structure of CenterNet
在图2中,右上角虚线圈内网格中的黑点是对该图片内的车辆进行偏移量估计的放大图,以实现对车辆位置的修正,对其精确定位.本文中所使用的Backbone为带有动态卷积的DLA_34网络,该网络是通过多级跳跃连接的,并以多次迭代的方式融合浅层与深层的信息,以获得更具表现力的特征.在Backbone的输出端增加了Keypoint heat head、Object size head和Local offset head,分别回归输入图像中潜在目标的关键点、宽高尺寸和中心点的偏移量,从而可以精准地检测到视频序列中的车辆与行人.
2.1.2 Res2Net_plus模块
由于无人车驾驶场景下存在很多较小的目标或行人和车辆之间相互遮挡的情况,为了提高CenterNet网络对小目标和遮挡目标的检测效果,本文提出了Res2Net_plus模块.Res2Net_plus模块通过结合Octave Conv[9]和SE-Net[10]的思想对原始ResNet(Bottleneck)模块进行改进.Octave Conv的核心思想是将原始特征图按不同频率进行分解,对含有不同频率信息的特征图分开操作,从而可以加速卷积的计算和提高任务的性能.而SE-Net的思想是引入了注意力的机制,用一个权重来表示输入特征图的通道在后续阶段的重要程度,以实现特征图的空间信息和通道信息的融合.
受此启发,本文在Res2Net模块中的以层级残差式风格连接3×3卷积前端分别加上一组1×1的卷积,以获得含有不同频率信息的特征图,如图3(b)中①号虚线框所示.同时,在Res2Net模块中嵌入SE-Net,以融合特征通道间的关系,进一步提升网络的空间特征表现力,得到更加有表现力的多尺度特征,如图3(b)中②号虚线框所示.Res2Net模块和Res2Net_plus结构如图3所示.

图3 Res2Net和Res2Net_plus模块结构Fig.3 Module structure of Res2Net and Res2Net_plus
在图3中,假设经过头部第一个1×1卷积后的尺寸为H×W×C的特征图为U′,原来的Res2Net模块仅仅简单的将1×1卷积后的特征图按通道等分成4份,而Res2Net_plus是将1×1的卷积后的特征图分别经过4个1×1×(C/4)的卷积,生成4个H×W×(C/4)特征图送入后续卷积层,以获得含有不同频率信息但通道数减为原来4倍的特征图.同时,嵌入的SE-Net模块则是对经过尾部最后一个1×1卷积输出的尺寸为H×W×C的特征图U″先后进行Squeeze操作、Excitation操作及Scale操作,以实现特征图的空间信息和通道信息的融合.其中,Squeese操作是使用全局池化,将大小为H×W×C的输入特征图转为1×1×C的特征描述,计算方法如公式(1).Excitation操作是将得到的1×1×C的特征描述经过两个全连接层和一个Sigmoid激活函数,得到1×1×C的通道间的权重s.Scale操作是按通道将获得1×1×C的权重s与原始输出的H×W×C的特征图U″通过简单的乘法进行融合,得到H×W×C的特征图U‴,计算方法如公式(2).
(1)
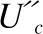
(2)

2.2 关联概率网络
外观特征是目标检测领域中一种具有很好区分性的属性.尤其是在目标之间相互遮挡或存在许多外观相似的目标时,外观特征可以被使用来对目标进行检测、识别和区分.
在早期的研究中,一些人工制作的特征常常被使用来表征物体的外观特征.随着深度神经网络的发展,基于深度神经网络提取的物体的外观特征被广泛地使用在目标检测、跟踪等领域.本文利用基于嵌入了CIR单元(cropping-inside residual units)的CIResNet_22为主干网络的孪生网络提取目标的外观特征,并分别将其两两直接进行卷积计算如公式(3)所示,得到关联概率值,值越高目标越相似,具体网络结构如图4所示.
k=U1*U2
(3)
其中,U1和U2为两个不同目标经过CIResNet_22提取的尺寸一样的特征图,*表示卷积计算操作,k为一个标量,值越高,表示两个目标越相似,反之,则差异越大.
该关联概率网络的输入是目标检测网络对视频序列每帧检测到的目标的二维包围框的左上角和右下角坐标,(x1,y1)和(x2,y2).然后根据二维包围框的坐标将每帧检测到的目标裁剪出来,把尺寸调整为127×127,送入CIResNet_22网络中,来提取每帧中检测到的每个目标的外观特征,其尺寸为6×6×256.假设上一帧和当前帧分别代表第t帧和第t+1帧,且分别检测到目标的数量为Nt和Nt+1.然后,将第t帧的Nt个特征图与第t+1帧的Nt+1个特征图两两直接进行卷积计算,可以得到尺寸为Nt×Nt+1的关联概率矩阵,例如图4右上角虚线圈内所示.

图4 关联概率网络结构图Fig.4 Structure diagram of association probability network
2.3 数据关联模块
数据关联也是基于检测跟踪的多目标跟踪方法中十分关键的一步,这直接决定了所检测到的目标之间匹配的效率与最终跟踪效果.本文设计了一种级联形式的数据关联方法,首先采用匈牙利算法来完成相邻帧之间检测到的目标的初步匹配,后续两步工作由基于区域推荐网络[11]的辅助跟踪器完成,以进一步提升目标跟踪能力.
2.3.1 数据关联
数据关联一共分3步进行,工作流程如图5所示.

图5 数据关联模块工作流程图Fig.5 Workflow of data association module
第1次匹配:充分利用目标的外观特征,得到相邻帧的目标的初步匹配关系.以 “集合Dt和Dt+1” 为输入,通过关联概率网络计算得到相邻帧的关联概率矩阵.然后,使用匈牙利算法[12]得到相邻两帧所检测到的目标的初步匹配关系.接着,将满足下述条件1和条件4的当前帧的目标合并到存在的轨迹中;反之,则将上一帧和当前帧的未匹配上的目标分别放入“集合Ut”和“集合Ut+1”.
第2次匹配:利用基于区域推荐网络的辅助跟踪器对漏检的目标进行持续跟踪.以“集合Ut”为输入,使用辅助跟踪器对上一帧未匹配上的目标进行持续跟踪,得到当前帧的位置状态和跟踪得分.接着,将满足条件2、条件3和条件5的跟踪结果合并到存在的轨迹中;反之,则认为该目标已消失,将其放入“集合U30”.设置一个最大连续跟踪帧数Nmax,当超过连续Nmax帧时,该漏检的目标还未出现,则不再对此进行跟踪.
第3次匹配:利用辅助跟踪器对前30帧已经消失的目标进行推理判断是否在当前帧再次出现.以“集合Ut+1和U30”为输入,使用辅助跟踪器对前30帧未匹配上的目标进行持续跟踪,推理出在当前帧的状态.接着,将满足下述条件2、条件3和条件5的跟踪结果合并到存在的轨迹中,并将其从“集合U30”中删除.最后,当前帧未匹配上的目标为新出现的目标,为其创建新的轨迹.
其中,条件1为关联概率大于阈值30;条件2为跟踪得分大于阈值0.9;条件3为预测得到的目标包围框距离图片边界大于15像素值;条件4为两个目标的包围框的IoU值大于阈值0.01;条件5为预测得到的目标包围框与历史帧中该目标的包围框的IoU值大于阈值0.01.
2.3.2 辅助跟踪器
C组自然分娩产妇所占比例高于A、B组,B组高于A组(P<0.05);C组阴道助产及剖宫产产妇所占比例低于A、B组,B组低于A组(P<0.05),见表4。
本文中所使用的辅助跟踪器是基于区域推荐网络设计的,主要目的是改善因目标检测网络的漏检导致目标ID频繁切换或轨迹断开的问题,具体网络结构如图6所示.
其中,辅助跟踪器中使用的主干网络和前面关联概率网络的主干网络一样,都是使用CIResNet_22网络,且共享权重.辅助跟踪器输入由两部分组成,分别为未匹配上的目标集合(包括特征图、ID和包围框的坐标)和当前帧的图片.其中,未匹配的目标的特征图作为模板帧的特征图,尺寸为6×6×256.而检测帧的特征图的提取通过两个步骤:首先,以未匹配的目标的中心点在当前帧图片中裁剪出同样中心点的两倍区域;然后用CIResNet_22网络提取出尺寸为22×22×256的特征图;接着,模板帧和检测帧的特征图复制双份,分别送入区域推荐网络的分类分支和回归分支中进行后续操作.其中,分类分支,用于区分目标的前景和背景;回归分支,用于对目标的候选区域进行微调.

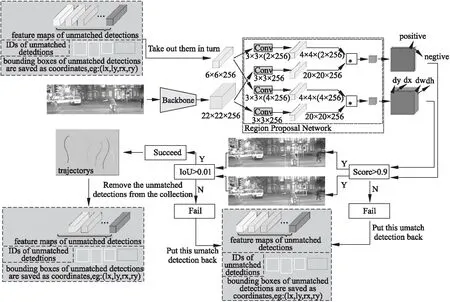
图6 辅助跟踪器结构图Fig.6 Structure diagram of auxiliary tracker

(4)
(5)
3 实验与结果分析
3.1 实验配置与数据集
本实验是使用Pytorch 0.4.1框架实现的,实验配置如表1所示.

表1 实验配置Table 1 Experimental configuration
数据集使用了公开的KITTI目标检测基准数据集和KITTI目标跟踪基准数据集,其中,目标检测数据集主要是对汽车和行人的检测,其训练集和测试集分别有7481和7518张图片,而目标跟踪数据集主要是对汽车与行人的跟踪,其训练集和测试集分别有21和29个视频序列.在本实验中,将KITTI目标检测基准数据集原有标注的8个不同的类别合并为两个类别,具体是将Car、Van和Truck这3类合并为Car类,将Pedestrian、Person_sitting和Cyclist这3类合并为Pedestrian类,且仅保留Car和Pedestrian类.同时,也将KITTI目标跟踪基准数据集原有标注的Pedestrian和Person类合并为Pedestrian,将Van和Car合并为Car类,且仅保留Car、Pedestrian和Cyclist类.同时,将KITTI目标检测基准数据集的训练集按8∶1∶1划分为训练集、验证集和测试集,用于对目标检测网络的训练和评估.另外,考虑到目标检测数据集和目标跟踪数据集有部分图片是重合的,为了公平起见,首先将目标跟踪数据集的训练集中21个视频序列分别按7∶3的比例切分成训练集和验证集,分别用来重新训练目标检测网络和验证本文提出的多目标跟踪算法.接着,将目标跟踪数据集的训练集全部用来重新训练目标检测网络,用于在该目标跟踪数据集的测试集上评估本文所提出的多目标跟踪算法.
3.2 训练过程
3.2.1 Centernet网络训练过程
首先,本文为了评估CenterNet网络,先使用KITTI目标检测基准数据集.然后,为了评估多目标跟踪算法,使用KITTI目标跟踪数据集重新训练CenterNet网络,训练过程都是未加载预训练模型,优化器都为Adam,初始的学习率都为1.25×10-4.在按比例划分好的目标检测数据集的训练集和目标跟踪数据集的训练集上的两次训练过程都是一样的,输入分辨率为512×512,训练140个epoch,batch为8,并分别在第90和120的epoch处,使学习率分别下降10倍.而在目标跟踪数据集的全部训练集上先后训练3次,第1次未加载预训练模型,第2、3次均以上次训练出来的模型为预训练模型来加载训练.首先以512×512的输入分辨率,训练230个epoch,分别在第90和120的epoch处,使学习率分别下降10倍.接着,以384×1280的输入分辨率,训练140个epoch,分别在第90和120的epoch处,使学习率分别下降10倍.最后,以384×1280的输入分辨率,训练40个epoch,分别在第10和15的epoch处,使学习率分别下降10倍.
3.2.2 关联概率网络和区域推荐网络训练过程
由于关联概率网络和基于区域推荐网络的辅助跟踪器是受SiamRPN网络启发而设计的,且其权重共享,因此关联概率网络和区域推荐网络的权重可由以CIResNet_22为主干网络的SiamRPN网络训练得到.首先,SiamRPN网络加载在ImageNet数据集上训练得到的预训练模型.接着,在使用裁剪程序处理后的VID和Youtu-BB数据集上训练,训练50个epoch.裁剪程序为从历史帧中裁剪出目标模板区域,并将其尺寸变为127×127,且以历史帧的目标的中心点在当前帧图片中裁剪出同样中心点的两倍区域,并将其尺寸变为255×255,以组成成对的图片用于网络的训练.
3.3 评价指标
评估多目标跟踪算法采用的指标如表2所示,其中,MOTA和MOTP对多目标跟踪算法总体性能进行评估,而Mostly Tracked(MT),Mostly Lost(ML)、ID-Switch(IDS)和Fragmentations(FRAG)对跟踪器在给目标分配正确的ID的效率进行评估.另外,本文也做了关于目标检测网络性能的实验评估,其指标如表3所示.

表2 多目标跟踪算法的指标Table 2 Metrics used for multiple object tracking

表3 目标检测算法的指标Table 3 Metrics used for object detection
3.4 实验结果及分析
图7为KITTI跟踪基准数据集的测试集中视频序列1中连续的4帧视频序列的目标检测与跟踪的结果.从图7中可以看出,在第3和第4帧中,目标检测器因汽车有部分遮挡,所以没有检测到这辆汽车,但是辅助跟踪器却能很好地跟踪这辆有部分遮挡的汽车,其ID为7,没有发生改变.图8为KITTI跟踪基准数据集的测试集中视频序列0中连续的4帧的目标跟踪的结果.从图8中可以看出,本文算法在拥挤的停车环境中仍然能对车辆进行很好的跟踪.

图7 KITTI跟踪基准测试集中序列1中连续4帧视 频序列的检测与跟踪对比结果Fig.7 Comparison results of detection and tracking of four consecutive video sequences in video sequence 1 of KITTI tracking benchmark test set
为了验证本文提出的Res2Net_plus模块对CerterNet网络的影响,本文将Res2Net_plus模块拆分成Res2Net、1×1和SE-Net 3部分,在KITTI目标检测数据集上进行了对比实验,结果如表4所示.另外,为了验证所提出的关联概率网络、辅助跟踪器对整体多目标算法性能的影响,本文在KITTI跟踪基准数据集中包含21个视频序列的训练集上进行了对比实验,结果如表5所示.最后,为了与已有的多目标跟踪算法进行比较,本文还在KITTI目标跟踪数据集中包含28个视频序列的测试集上进行与其他多目标跟踪算法的对比实验,结果分别如表6和表7所示.

图8 KITTI跟踪基准测试集中序列0中连续4帧 视频序列的跟踪的结果Fig.8 Video sequence tracking results of four consecutive frames in video sequence 0 of KITTI tracking benchmark test set
从表4中可以看出,Res2Net、1×1和SE-Net模块可使CenterNet网络的各项指标均有提升,表明了所提出的Res2Net_plus模块可提升CenterNet网络对无人车驾驶场景下车辆和行人的检测精度.
从表5中可以看出,相较于仅使用目标的位置信息(相邻帧目标的IoU值),关联概率网络和辅助跟踪器均可以提高多目标跟踪算法对车辆目标的跟踪能力.另外,基于区域推荐网络的辅助跟踪器也可以一定程度上提高多目标算法的性能,尤其是IDS和FRAG这两个指标都有明显的提升.
从表6和表7中可以看出,本文所提出的无人车驾驶场景下的多目标跟踪算法对于车辆与行人这两类,在大部分指标上都领先其他几个多目标跟踪算法.尤其,本文提出的多目标跟踪算法在MOTP和FRAG这两个指标均领先其他算法许多,这也表明了所提出的多目标跟踪算法在无人车驾驶场景下具有很好的竞争力.

表4 在KITTI检测基准数据集(训练集中划分出来的748张图片)上试验Res2Net_plus模块对CerterNet网络的影响Table 4 Effects of Res2Net_plus module for CenterNet on the KITTI detecting benchmark dataset (748 pictures divided from the training set)

表5 在KITTI跟踪基准数据集(21个视频序列的训练集中划分出来的验证集)上试验各模块对多目标跟踪算法的影响Table 5 Effects of each module for the multi-object tracking algorithm on the KITTI tracking benchmark dataset (the verification set divided by 21 video sequences of training set)

表6 在KITTI跟踪基准数据集的测试集上与其他多目标跟踪算法对比实验结果(‘Car’类)Table 6 Comparison of experimental results with other multi-object tracking algorithm on test set of KITTI tracking benchmark dataset(′Car′class)

表7 在KITTI目标跟踪数据集的测试集上与其他多目标跟踪算法对比实验结果(‘Pedestrian’类)Table 7 Comparison of experimental results with other multi-object tracking algorithm on test set of KITTI tracking benchmark dataset(′Pedestrian′class)
4 结 论
本文提出多目标算法在无人车驾驶场景下对车辆与行人具有很好的跟踪能力.实验结果表明,提出的Res2Net_plus模块可以有效提高目标检测器对车辆与行人的检测精度,关联概率网络也能很好地构建目标的特征表达模型,从而显著提高多目标跟踪算法对目标的跟踪能力.另外,辅助跟踪器也可以有效对漏检的目标进行持续跟踪,这样可以很好地改善因目标部分遮挡、目标检测器失效造成的目标漏检所导致的目标ID频繁切换或跟踪轨迹断开等问题,尤其可以从IDS和FRAG这两个指标看出.但从实验结果可以看出,相较于其他的算法,对车辆的跟踪,本文提出的算法的MOTA和MT、ML这3个指标还不是很具有竞争力,还有提升的空间,后续的研究将进一步解决好对相互拥挤且外观相近的目标跟踪能力较弱的问题.
