基于语义分割网络的高分遥感影像城市建成区提取方法研究与对比分析
2021-03-19刘钊赵桐廖斐凡李帅李海洋
刘钊,赵桐,廖斐凡,李帅,李海洋
(清华大学土木工程系交通工程与地球空间信息研究所,北京 100084)
0 引言
近年来,中国的城市化进程突飞猛进,而现实城市发展进程的指标之一就是城市建成区。根据国家质量技术监督局和国家建设部共同发布的《城市规划基本术语标准》,建成区定义为: 城市行政区内实际已成片开发建设、市政公用设施和公共设施基本具备的区域[1]。城市建成区是反映城市综合经济实力和城市化水平的重要指标。获取历年以来城市建成区数据,对于城市的建设和管理企业的决策等具有重要的意义。
城市建成区的提取是近年来遥感应用领域研究的热点内容。传统的研究方法主要包括都市化指数(urban index, UI)[2]、归一化建筑指数(normalized difference built-up index, NDBI)[3]、归一化植被指数(normalized difference vegetation index, NDVI)[4]等方法。这些指数不仅可以单独运用,也可相互结合综合运用[5],能够得到更好的效果。传统方法由于是通过地物的光谱特征提取关键信息,经常出现同谱异物或者同物异谱的现象,从而使该类方法很不稳定,在识别地物时容易存在较大误差。
机器学习方法中,随机森林法[6]、支持向量机法[7]以及无监督的聚类方法[8]同样可以完成建成区的识别。Gong等[9]应用哨兵2号影像采用随机森林算法,在Google Earth Engine平台上达到了72.6%的高精度。机器学习的算法优点在于算法简单,运行速度快。但算法简单带来的缺陷就是层次太浅,无法处理复杂的分类问题,以及面对大数据量的问题时,预测的精度会受到限制。所以,传统机器学习算法并不是当今热点问题的最优解。
深度学习算法很好地解决了传统机器学习算法中层次浅的问题,成为了当今的研究热点。卷积神经网络[10]则是深度学习中应用最广泛的分支,目前已被大量用在城市建成区的识别之中。现代意义上的卷积神经网络起源于2012年的AlexNet[11]网络,该网络相比于以往的神经网络拥有更深的层次和新的激活函数ReLU,从而加快了训练速度。卷积神经网络在图像分类上取得了高精度后,随即被应用到其他问题,例如图像语义分割以及图像实例分割。其中图像语义分割类似于图像分类,不同点在于语义分割是针对每一个像素的分割问题。
近几年的研究和应用中涌现出了很多优秀的语义分割网络,每年图像分割竞赛的语义分割网络精度也在逐年提升。很多国内外学者应用语义分割网络进行遥感影像建成区的识别,并取得了理想的结果。杨建宇等[12]运用SegNet[13]语义分割网络在WorldView影像上进行霸州地区农村用地的提取,并得到了很高的分类精度; 苏健民等[14]将U-Net[15]语义分割网络应用在CCF卫星影像数据集上,取得了90%的测试准确率; Chen等[16]基于空洞卷积[17]的理论提出了Deeplab v3模型结构,将准确率进一步提升; 王俊强等[18]也利用Deeplab v3网络对道路和建筑物进行提取,得到了较高的分割精度。
在一个典型的语义分割网络之中,每一个卷积层之间的连接关系会影响到最终训练的精度。残差网络(residual neural network,ResNet)[19]通过跳接的方式使网络的训练精度更高,解决了传统的AlexNet和VGGNet网络最大的缺陷。本文以ResNet50以及ResNet101残差网络作为解码器的基础,对Deeplab v3,金字塔场景解析网络(pyramid scene parsing network,PSPNet)[20]和ShelfNet[21]3个以ResNet网络为骨架的语义分割网络的内部网络结构进行对比分析,并通过同一高分遥感影像城市建成区数据进行对比实验,比较得出提取城市建成区时最适用的语义分割网络。
1 ResNet网络原理分析
ResNet由He等提出[19]。该网络在ILSVRC比赛中取得冠军,分割效果非常理想。与早期的AlexNet和VGGNet[22]相比,能够在保持更低参数量的同时得到更好的效果,并且解决了VGGNet及其他更早的卷积神经网络中的诸多缺陷。AlexNet网络和VGGNet网络仅仅是由上而下的编码结构,此类结构的层数通常会存在最大值,而超过最大值的网络很容易出现过拟合的问题,从而导致精度的降低。ResNet最大的创新点在于网络内部的残差单元,其基本结构如图1所示。残差单元保证了ResNet网络可以达到很深的层次。图中的x为残差学习模块的输入层,F(x)为残差学习网络的映射。
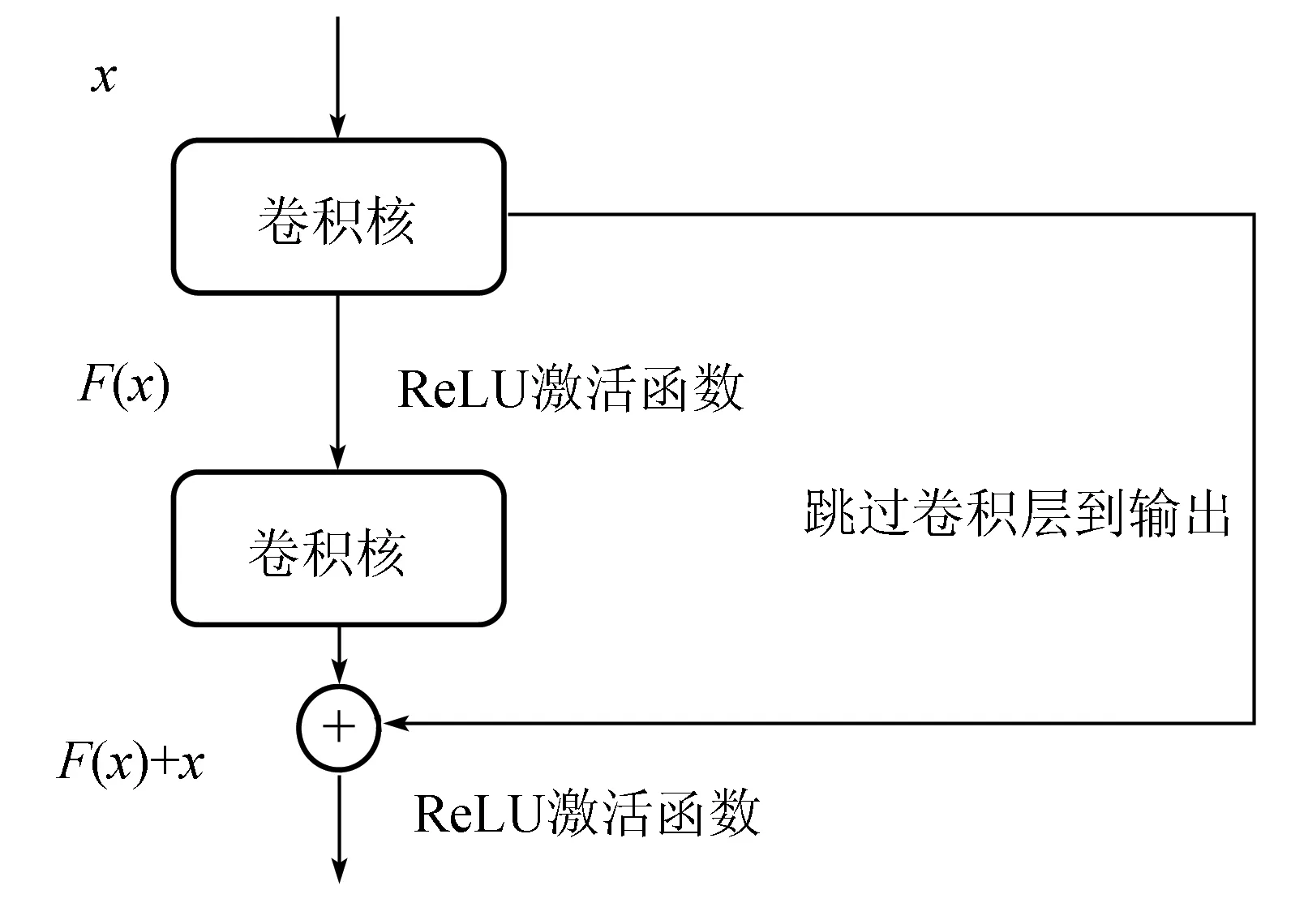
图1 ResNet基本结构
传统的AlexNet和VGGNet网络最大的缺陷在于,当网络变得越来越深的时候,训练误差曲线会趋于平缓,准确率不再上升,VGGNet达到19层后甚至会导致分类性能的下降。ResNet很好地解决了这类问题: 它不再用堆叠的卷积层直接拟合期望的特征映射,而是将原本的映射和输入本身做差,拟合残差映射。假设卷积层的映射为H(x),那么残差映射F(x)=H(x)-x。ResNet网络将输入的信息绕道直接传到输出端,这样做的优势在于浅层的信息成功进入了深层的卷积层,使得整个卷积网络中融合了大量浅层信息,避免了梯度消失问题。ResNet网络常用层数有34层、50层、101层以及152层。
由于ResNet网络的优异表现,现如今很多语义分割网络都基于ResNet网络搭建,包括Deeplab v3网络、PSPNet网络以及ShelfNet网络等。它们都将ResNet作为基本骨架,再加上自身的创新点,从而形成了各自网络的优点。
2 语义分割网络原理及对比分析
2.1 Deeplab v3网络原理
Deeplab v3语义分割网络中设计了不同采样率的空洞卷积并将其进行融合。架构中的空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)模块可以提取不同尺度上特征图的卷积特征,从而使准确率得到进一步的改善。Deeplab v3语义分割网络的原理示意图如图2所示。

图2 Deeplab v3语义分割网络结构[17]Fig.2 Deeplab v3 semantic segmentation network structure[17]
Deeplab v3网络主要解决了2个传统语义分割网络的缺陷: 一是不能很好地顾及不同尺度物体的信息,很容易出现漏识别小物体或误识别大物体的情形; 二是当网络本身层次太深,卷积核本身又不大的情况下,很容易出现漏识别,以及识别结果分辨率过低的情况。
在连续下采样的过程中,图片越小,细节信息丢失越多,这对于语义分割是不利的。故在ResNet残差网络得到输出后,Deeplab v3网络在卷积的最后一层直接通过某一采样率的空洞卷积保持输出步幅(图2中采样率=2)。这样既保证了图片质量,也没有增加参数。ASPP模块的设计则更为高级。ASPP金字塔池化模块通过3个不同采样率的3*3空洞卷积和一个1*1卷积保证不同尺度物体的信息。同时,在采样率接近特征图的大小时,3*3的滤波器不能很好发挥捕捉全图的作用,故Deeplab v3网络在最后加入全局平均池化,输出256个通道,经过卷积以后再和其他特征图融合起来。该方法很好地提升了分类效果。
然而,Deeplab v3网络同样存在缺陷,即在编码过程结束后直接解码到原尺寸,这可能会导致输出结果放大的效果不好,信息太少。其次,Deeplab v3网络存在正则化调参的过程,该进程也是网络中非常耗时的一个步骤。除此之外,过多的通道数也有可能导致训练速度慢,网络效率偏低等问题。
2.2 PSPNet网络原理
PSPNet是针对相对复杂的场景解析问题而提出的网络,解决的是计算机视觉的基本问题。传统的卷积神经网络没有很好地运用场景中上下文的信息,并且一些不明显的类别不易被察觉,于是网络引入金字塔结构来解决这一问题。PSPNet的网络结构示意图如图3所示。

图3 PSPNet语义分割网络结构[20]Fig.3 PSPNet semantic segmentation network structure[20]
PSPNet的网络结构与Deeplab v3网络相似,都是以ResNet残差网络为主体骨架,在ResNet网络结束后加入各自的设计。网络首先通过预训练的残差网络提取出feature map特征图,特征图的大小是输入的1/8,随后特征图经过金字塔池化模块得到带有整体上下文信息的小图。小图经过上采样后恢复到特征图的尺寸,并且与池化以前的特征图相结合,经过最后一个卷积层后得到最终输出结果。
该金字塔池化模块融合了4种不同金字塔尺度的特征信息,这样做有利于帮助网络结合全局的上下文信息。以最上层为例,最上层为最粗糙的1*1全局池化,生成单个像素多通道输出,后面几层为不同尺度的池化(文中为2,3,6)。如果金字塔中设定了N个级别,在池化以后都要使用1*1卷积将通道数降为原先的1/N。卷积后各层次通过双线性插值实现上采样,并和原先的特征图融合在一起。
PSPNet网络同样存在缺陷。与Deeplab v3网络相同,过多的通道数和大量的卷积、池化运算耗费了大量的时间,影响到了网络的运行效率。PSPNet网络和Deeplab v3网络类似,都将卷积神经网络进行了扩张的操作。相比于传统的卷积神经网络,扩张后的网络虽然参数没有增加太多,但是空间尺寸大得多,因此导致了运行速度的降低。但是相比于Deeplab v3网络,PSPNet网络缺少了正则化的过程。
2.3 ShelfNet网络原理
ShelfNet网络是一个同样以ResNet网络为骨架的编码-解码网络。它和普通的编码-解码网络结构的不同点在于,该网络中有很多种编码-解码的路径,并且在每一个空间级别上都存在跳跃连接。这种多路径的算法大大提高了网络的精度。ShelfNet网络的原理图如图4所示。图中A-D代表了ResNet网络中不同的层次; 列1-4代表了不同的分支。为了尽可能地减少通道数量从而提升训练速度,网络在第一列的运算中使用了1*1卷积层后接以batch normalization正则归一以及ReLU激活函数,并且将通道的数量减少为ResNet网络中的1/4。

图4 ShelfNet语义分割网络结构[21]Fig.4 ShelfNet semantic segmentation network structure[21]
除此之外,分支1和3为编码分支; 分支2和4为解码分支。编码器分支中采用跨距为2的卷积; 在解码器中采用跨距为2的转置卷积。从图中可见,该网络最大的特点就是丰富了路径的选择。从输入到输出可以有很多种选择的途径,而不再拘泥于传统编码-解码网络中的单一途径。图4中2~4列的残差块均为共享权值。共享权值的优点在于结合了跳跃连接优点的同时,比标准残差单元减少了很多参数。它能更有效地提取特征,并且可以加快模型的运行速度。ShelfNet网络实现了在不同的层次上进行跳转的功能,捕捉了更多的浅层和深层特征,也使得运行速度和分割精度有了显著提升。
3 实验及结果分析
3.1 实验设置及实验流程设计
本文在同一个Nvidia GeForce GTX 1080ti GPU显卡上,使用Deeplab v3-50,Deeplab v3-101,PSPNet50,PSPNet101,ShelfNet50和ShelfNet101共6个网络进行了对比实验。实验的深度学习模型基于PyTorch搭建,使用ResNet网络作为基础框架。采用公开的Coco-2014数据集和ImageNet数据集对网络进行预训练,实验开始时统一将输入图片的大小设置为256像素×256像素。循环设置为80,因为数据集训练到50个循环附近就会收敛。初始学习率设为0.001,学习率会随着训练的深入而下降。
实验第一步是图像裁剪。网络需要有固定尺寸的输入,故需要将原始图片切割成相应尺寸,在本实验中为长宽为256像素×256像素的图像瓦片。除原始的影像外,还需生成与之一一对应的真实值(ground truth)标签。
第二步是网络训练。遥感影像每一个像素点的像素值会作为输入传入网络。经过卷积神经网络的运算得到输出,并且和相应的真实值标签进行比较,由损失函数算出损失值。
第三步是返回调参。根据第二步得到的损失函数值的反馈,整个网络框架会返回到卷积的部分调参,对网络整体进行完善。
第四步是结果预测。训练结束以后会得到已完成调参的实验模型。根据模型和测试集进行网络预测,得到最后的预测结果。
3.2 实验数据来源
本实验采用中国深圳市的正射遥感图像作为实验的数据源。选择深圳作为数据集的原因在于该地区城市面积大,易于划分训练集区域,并且在Google影像地图中存有不同时相的数据,便于进行深度学习的研究。数据为深圳市2018年和2019年Google影像18级高分辨率影像,手工划分出训练集建成区矢量文件作为与影像相对应的标签图。首先通过裁剪得到了9 577张256像素×256像素大小的影像,其中的80%作为训练集,其余作为验证集。验证集的瓦片影像不会参与训练,但是可以起到验证网络精度的作用。数据集中的部分影像样本如图5所示。

图5-1 部分训练数据集Fig.5-1 Partial training data set

图5-2 部分训练数据集Fig.5-2 Partial training data set
3.3 实验结果与分析
实验中,每个网络均进行80个循环,其中每次循环显示一次结果; 每5次保存一个模型,故最后可以得到16个训练不同阶段的模型。实验每一次结果显示均输出6个不同参数,分别为: 训练集平均损失、验证集平均损失、验证集平均准确率、验证集平均重叠度(intersection over union, IOU)(mIOU)、背景IOU和前景IOU。为了防止偶然偏大或偏小的结果带来的影响,本实验再选取2个评价指标: 使用前20循环平均前景IOU表示网络前期收敛速度; 使用51-80循环平均前景IOU来表示网络稳定后的平均IOU水准。本实验共6个网络参与训练,分别为Deeplab v3-50,Deeplab v3-101,PSPNet50,PSPNet101,ShelfNet50,ShelfNet101,其中数字表示ResNet的层数。为了比较网络在前期的收敛速度,实验列出第20个循环的6个参数,以及前20个循环平均前景IOU,结果如表1所示; 为了比较网络在收敛后的准确度,实验列出最终的6个参数,以及51-80循环平均前景IOU和训练时长,结果如表2所示。随机森林分类器和支持向量机分类器是遥感影像分类中较经典的机器学习分类器,但由于二者结构与语义分割网络有明显的不同,不能像语义分割模型一样通过模型分类器直接预测得到等尺寸的预测结果图片。所以,在训练这2个分类器前需要对影像数据和标签数据分别进行预处理编码成特征向量形式以适应分类器结构。本实验同样针对随机森林分类器和支持向量机分类器进行数据集的预测,但由于二者结构的局限性及特殊性,无法对随机森林分类器和支持向量机分类器进行前期精度的比较以及训练时长的统计。本文只进行最终验证集平均准确率及验证集mIOU的横向比较,比较结果如表2所示。

表1 网络前期训练精度比较Tab.1 Network early stage training accuracy comparison (%)

表2 网络最终训练精度比较Tab.2 Network final training accuracy comparison
从表1中可以比较得出网络初期的收敛效率。PSPNet50网络在验证集损失值和背景IOU上表现更好; 而ShelfNet50网络在其余的5项指标中均为最优。IOU算法为输出结果与真值的交集除以并集,故前景IOU最可以反映网络的精度。从表1的数值中可以得出,ShelfNet50网络的前期收敛速率是非常理想的,而Deeplab v3网络均没有达到很好的效果,这与网络本身的结构有较大的关系; 其次,所有以ResNet50为骨架的网络在训练前期均比以ResNet101为骨架的网络有更好的表现,这是因为ResNet101中的参数数量要远多于ResNet50,故参数少的网络前期收敛更快。
相比于表1,表2则可以体现网络的性能优劣。随机森林分类器和支持向量机分类器虽然在平均准确率方面与语义分割网络相近,但是在mIOU上却相差甚远。在实验训练时长方面,ShelfNet网络占据了绝对的优势,并且ShelfNet网络的运行速率不会随着ResNet网络层级的加深出现过大的变动。相比之下,Deeplab v3网络和PSPNet的4个网络在训练上花费了过多时间。这说明了在讲究网络的运行速率时,ShelfNet网络是绝对的最优选。
在准确率指标中,PSPNet101网络拥有最高的精度,其次是ShelfNet50网络和ShelfNet101网络,而Deeplab v3网络在最终的准确率一项同样表现不佳。在验证集前景IOU一项中,PSPNet101网络能够达到78.01%的精度,比ShelfNet50网络高出1个百分点,这说明PSPNet101网络在分割建成区的领域可达到非常优异的效果。值得注意的是,ShelfNet101网络的各项指标低于ShelfNet50网络,说明网络可能在训练时出现了过拟合。
综上,PSPNet101网络的分割精度最优,但是考虑到PSPNet101网络的训练时长过长,综合各种指标可以得出: ShelfNet50网络是在识别建成区中综合效率最高的选择。
由实验结果回推至理论本身,ShelfNet网络正是拥有了共享权值以及可以在不同空间层次上进行跳转连接的功能,使其比标准残差单元减少了很多参数。实验证明,这些改变可以显著加快模型的运行速度。除此之外,ShelfNet网络最大的特点就是丰富了路径的选择。正是这一个特点使得网络能够学习到各种浅层和深层的信息,从而保证了网络优秀的性能。
相比之下,PSPNet和Deeplab v3网络在卷积运算时空间尺寸大得多,因此导致了运行速度的降低。而相比于PSPNet网络,Deeplab v3网络在编码过程结束后直接解码到原尺寸,从而减少了信息的读取。实验结果表明,Deeplab v3网络的指标确实稍逊于其他2种网络。这可能是因为网络本身的缺陷,同样可能是因为Deeplab v3网络不适用于上下文联系较强的识别任务,而专长于另一些种类的识别任务。
本文使用ShelfNet50网络识别2019年深圳市18级遥感影像,结果如图6所示。
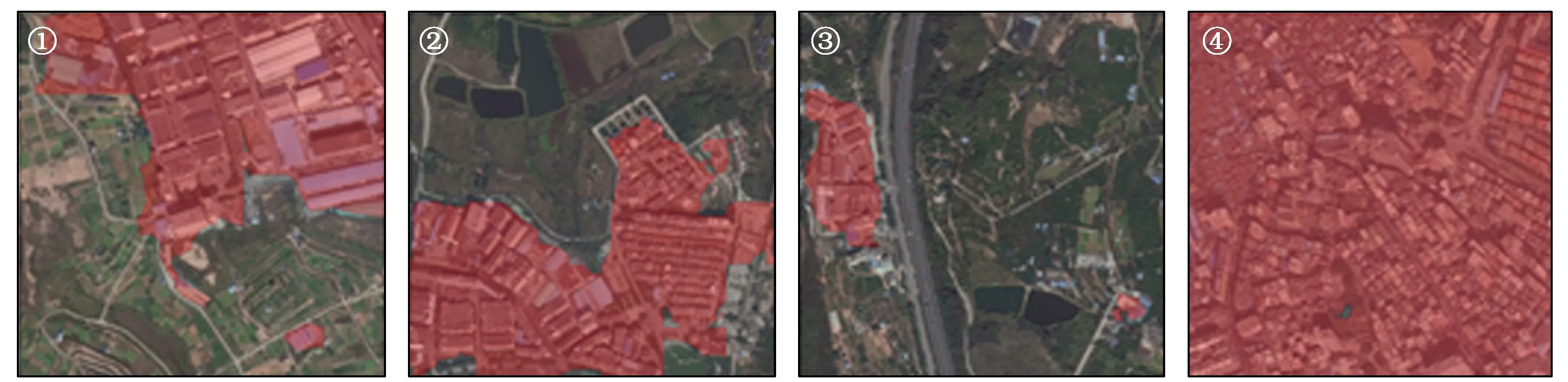

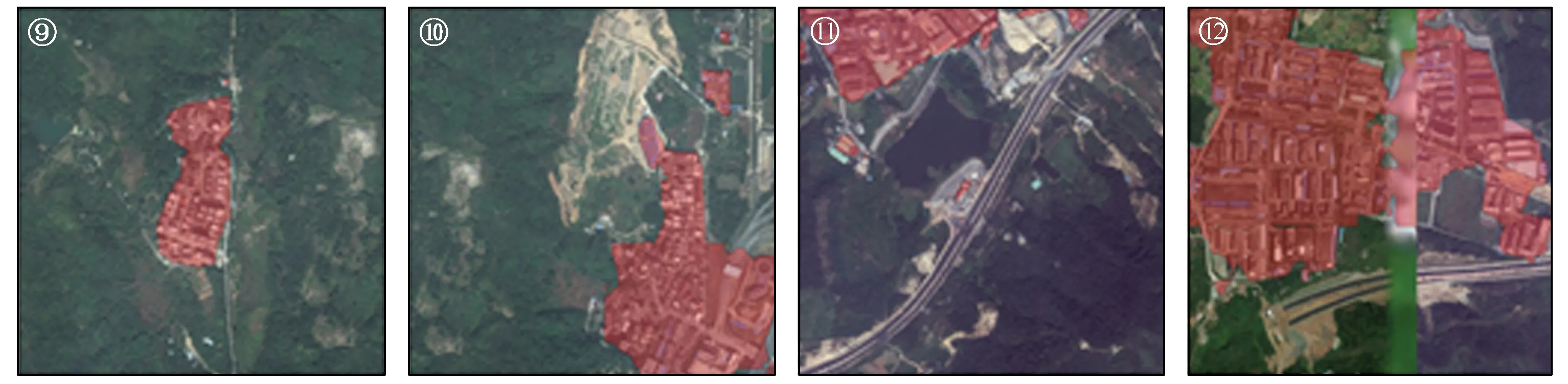
图6-1 ShelfNet50网络测试集分割结果Fig.6-1 ShelfNet50 network test set segmentation results

图6-2 ShelfNet50网络测试集分割结果Fig.6-2 ShelfNet50 network test set segmentation results
从图6中可见,其中红色为建成区,除去边界上的细微识别误差,ShelfNet50网络可以很好地识别深圳市2019年遥感影像中各种不同类别的建成区。预测结果同样表明,ShelfNet50网络有较好的上下文推理能力。城市小区的绿化和乡村大片的植被地物特征完全相同,而ShelfNet50网络能够从周围的地物特征推断该地区的具体类别,这也体现出了空洞卷积的重要性。实验表明,ShelfNet50网络可以适用于遥感影像城市建成区的识别,并且拥有很好的识别效果。
然而,ShelfNet50网络在识别时同样存在误差,如图7所示。

图7 ShelfNet50网络测试集分割误差Fig.7 ShelfNet50 network test set segmentation error
图7中反映出3个ShelfNet50网络的问题。首先,当原始影像有云时,网络不能判断云下的地物,这也是所有语义分割网络共同的缺陷; 其次,对于城区内一些大型非建筑物(公园绿地、大型立交桥),ShelfNet50网络还是欠缺识别此类地物的能力,而这也与空洞卷积核的大小有关; 最后,小部分建筑物存在漏识别的现象,这也说明了训练集中缺少该类标签,此类问题可以通过扩充数据集的方法解决。
4 结论
本文基于多种深度学习语义分割方法,针对高分遥感影像城市建成区提取问题做了深入的比较研究。本文首先从网络的基本原理出发,深入分析并比较了Deeplab v3网络、PSPNet网络以及ShelfNet网络这3种均以ResNet残差网络为骨架的语义分割网络的结构差别,并通过网络结构分析了每一个网络存在的优缺点。其次,本文通过控制变量法,使用同一套实验装置以及同一个数据集对6种语义分割网络进行了测试及结果分析。本文通过实验得出的结果返回原理分析部分,验证之前分析的合理性。最后,实验针对综合表现最佳的ShelfNet50网络进行结果预测,印证语义分割网络在高分遥感影像城市建成区分割中的可行性。综合以上,本文得到以下结论:
1)实验的初始收敛阶段,ResNet50残差网络的表现普遍好于ResNet101网络,其中ShelfNet50网络的收敛效果最为优异。
2)在网络最终分割效果的评定中,PSPNet的各项指标均处于6个语义分割网络的第1名; 验证集前景IOU比ShelfNet50网络高出1个百分点。
3)运行时长方面,ShelfNet网络远远短于另外2类网络,且ShelfNet网络基本不受网络层数的影响。综合网络精度以及运行速度2方面因素综合考虑,ShelfNet50网络是解决高分遥感影像城市建成区识别的最优网络。
4)ShelfNet50网络在最终的预测过程中表现优异,具有良好的识别效果,说明ShelfNet50网络可以完美解决城市建成区的识别问题。
