基于多粒度和语义信息的中文关系抽取①
2021-03-19张安勤许春辉
陈 钰,张安勤,许春辉
(上海电力大学 计算机科学与技术学院,上海 201306)
随着大数据时代的到来,数据的规模不断增大,信息过载的问题日益严重.因此快速准确地抽取关键信息有着重大意义.关系抽取在信息抽取中有着举足轻重的作用,目的是提取自然语言句子中实体对之间的语义关系.实体关系抽取作为自然语言处理的一项基本任务,是知识图谱、自动问答、机器翻译,自动文摘等领域的关键模块.随着深度学习的不断发展,引起了人们对NRE的兴趣,现在大多使用神经网络来自动学习语义特征.
1 相关工作
作为先驱,Liu 等提了一个基于CNN的关系抽取模型[1].在此基础上,Zeng 等提出一个带有最大池化层的CNN 模型[2],并且引入了位置嵌入来表示位置信息,然后他们设计了PCNN 模型[3],但是PCNN 模型在句子选择方面存在问题.为了解决这一问题,Lin 等[4]将注意力机制应用于其中.尽管PCNN 模型有着不错的效果,但是它不能像RNN 类型的模型一样挖掘上下文的信息.因此,带有注意力机制的LSTM 网络也被应用于关系抽取任务中[5,6].
尽管NRE 不需要进行特征工程,但是它们忽略了不同语言输入粒度对模型的影响,特别是对于中文关系抽取.根据输入的粒度的不同,现有的中文关系抽取方法可以分为基于字符的关系抽取和基于词的关系抽取的两种.
对于基于字符的关系抽取,它将每个输入语句看作一个字符的序列.这种方法的缺点是不能充分利用词语级别的信息,想比较于基于词语的方法捕获到的特征少.对于基于词语级别的关系抽取,首先要进行分词,导出一个词序列,然后将其输入到神经网络模型中.但是,基于词的模型的性能会受到分割质量的显著影响[7].
比如说,一句中文语句“乔布斯设计部分苹果”有两个实体,“乔布斯”和“苹果”,它们之间的关系为“设计”.在这种情况下,对于这句话的分词为:“乔布斯/设计/部分/苹果”.但是,随着对语句切分的变化,句子的含义可能变得完全不同.如果该句话分割为:“乔布斯设计部/分/苹果”,那么这句话的实体就变为“乔布斯设计部”和“苹果”,它们之间的关系转变为“分发”.因此,无论是基于字符的方法还是基于词语的方法都不能充分利用数据中的语义信息.因此,要从纯文本中发现高层实体关系,需要不同粒度的综合信息的帮助.此外,中文的词语存在大量的多义词,这限制了模型挖掘深层次语义信息的能力.例如,词语“苹果”含有两种不同的含义,即一种水果和电子产品.但是,如果没有语义信息的加入,就很难从纯文本中学习到这种信息.
本文提出了一种能够综合利用句子内部的多粒度信息以及外部知识的网络框架(PL-Lattice)来完成中文关系抽取任务.(1)该模型采用基于Lattice-LSTM 模型的结构,将基于词语级别的特征动态的集成到基于字符级别的特征中.因此,可以利用句子中的多粒度信息而不受到分词错误的影响.(2)为了解决中文中多义词的现象,改模型加入了HowNet[8]这一外部知识库对词语的多种语义进行标注,在训练阶段结合语义信息,提高模型的挖掘能力.
2 问题描述与建模
给定一个中文句子和其中的两个标记实体,中文关系抽取的任务就是提取两个标记实体之间的语义关系.本文提出用于中文关系抽取的PL-Lattice 模型,该模型的整体结构如图1所示.
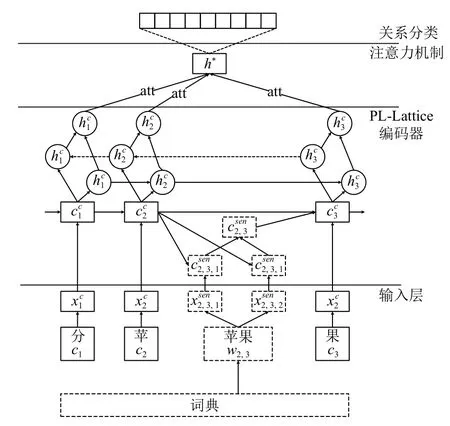
图1 模型整体结构
(1)输入层:给定一个以两个目标实体为输入的中文语句,该部分表示语句中的每个单词和字符.该模型可以同时提取和利用字级和词级的信息.
(2)PL-Lattice 编码器:这一部分使用Lattice-LSTM网络结构为基础,改进了字级别和词级别的输入的循环结构,并且将外部语义知识融入到网络里面来实现语义的消歧.
(3)注意力机制:使用词级注意力机制和句级注意力机制.
(4)关系分类层:通过Softmax函数输出关系类型.
2.1 输入层
本文模型的输入是一个带有两个标记实体的中文句子.为了利用多粒度信息,本文在句子中同时使用字级和词级信息.
(1)字符集向量表示
本文将每个输入的中文语句看作一个字符序列.给定一个由M个字符组成的句子s,表示为s={c1,···,cM},使用Skip-gram 模型[9]将每个字符映射到一个dc维的向量,表示为∈Rdc.
此外,在关系抽取任务中,句子中的字到命名实体的距离能够影响关系抽取的结果.所以,本文采用位置特征来指定句子中的字符,即当前字符到第一个命名实体和第二个命名实体的相对距离[2].具体来说,第i个字符ci到两个命名实体的距离分别表示为和.对于本文使用以下的方法来计算:

其中,b1和e1为第一个命名实体的开始和结束索引,的计算方法与等式1 类似.然后,和分别映射为dp维度的向量,表示为∈Rdp以及∈Rdp.
(2)词级向量表示
虽然模型有字符特征作为输入,但是为了充分捕捉句子中的多粒度特征,本文还需要提取句子中的所有潜在的词级的特征,潜在词为是由字符组成的句子中的任意子序列.这些子序列与构建在大型原始文本上的字典D相匹配得到真正的词级特征.
用wb,e来表示由第b个字符开始,第e个字符结束的词.为了将wb,e表示为向量形式,大部分文章使用Word2Vec 模型[9]来将其转化为词向量.
但是,Word2Vec 模型只是将词语映射为一个嵌入向量,忽略了一词多义这一事实.本文使用SAT 模型来解决这一问题,SAT 模型是基于Skip-gram 模型改进出来的,它可以同时学习词语以及意义之间的关系,并将其转换为词向量.
给定一个词语wb,e,首先通过检索HowNet 这一知识库来获得该词语的K种意义.用S ense(wb,e)表示词语wb,e所有意义的集合.通过SAT 模型将每种意义映射为向量形式,表示为∈Rdsen.最终,wb,e表示为一个向量集合,即
2.2 编码器
本文的编码器是在Lattice-LSTM的基础上,进行改进,加入词的意义这一特征,改进了基于字符级别和基于词级别的循环单元的网络结构;通过改进结构,减轻了Lattice-LSTM 编码器中对词的特征的提取导致的字符级别的特征被削弱的现象;并且使用了双向循环单元的结构,使编码器能够同时捕捉学习正向和反向的信息,能够显著提高模型的准确率以及合理性.
(1)Lattice-LSTM 编码器
LSTM 神经网络是循环神经网络的变种,主要思想就是引入一种自适应门控机制来控制LSTM 单元保留以前状态的同时学习当前数据输入的特征.LSTM神经网络有3 个门:输入门ij、遗忘门fj和输出门oj.基于字符的LSTM 网络表示为:

其中,σ ()为激活函数,W和U为可训练权重矩阵,b为偏置.
在输入语句中给定一个词语wb,e,与外部词典D相匹配,可以表示为:

其中,b和e表示词语在句子中的开始与结束的索引,ew表示一个查找表.在这样的情况下,对的计算需要结合词语级的表示,先构建词语级别的门控逻辑单元,再与字级的LSTM 网络相结合,形成Lattice-LSTM 编码器.使用来 表示的细胞状态.的计算方法如下:

其中,和分别表示词级的门控逻辑单元里面的输入门和遗忘门.
第e个字符的细胞状态将通过合并以索引e结束的所有词语的信息来计算,这些单词wb,e具有b∈这样的特征.为了控制每个词语的输入,设计了一个额外的门:

第e个字符的细胞状态计算方法如下:



虽然Lattice-LSTM 编码器能够利用字符和词的信息,但是它不能充分考虑中文的一词多义的特征.例如,如图1所示,w2,3(苹果)这个词有两种意义,代表一种水果,但是在Lattice-LSTM 中只有一个表示w2,3.并且Lattice-LSTM 编码器会造成对词的信息的过度提取会减弱字符级别的信息,甚至会忽略字符的信息,影响模型的效果.
为了解决这两个缺点,本文改进了模型.首先在模型中加入了感知层,将外部语义融入其中,如1.1.2 节中所示,本文使用来词语wb,e的第k种意义.其次,改进了词级和字符级的LSTM 结构,加强了字符之间的信息传递,减弱词级信息的提取.
并且本文采用了双向循环网络的结构,使编码器能同时提取句子上下文的关系与信息对于字符级的循环神经网络单元,本文改进的前向传播的计算方法如下:
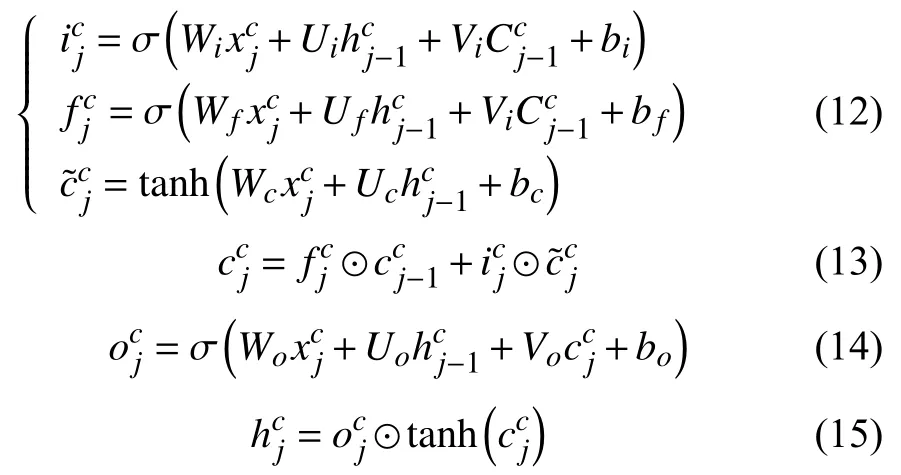
其中,σ ()为激活函数,W和U为可训练权重矩阵,b为偏置.
这种结构将上一个单元的细胞状态合并进入当前单元的各个门控逻辑单元中,增强了对的影响,即增强了字符级别的信息的提取能力.
对于词级的循环神经网络单元,本文的改进的前向传播的计算方法如下:

其中,表示词语wb,e的的第k个意义的细胞状态.这种结构将遗忘门合并进输入门,会在传入信息的时候就遗忘一部分信息,从而起到减弱词级别信息的作用.
然后,将所有的意义的细胞状态结合起来,得到,表示词语wb,e所有意义的细胞状态,计算方法如下:

所有感知层的细胞状态都被合并为,这样可以更好的表示一个词语多义的现象.然后,类似于式(9)到式(12),以索引e结尾的所有词语的细胞状态融入到第e个字符的细胞状态:

隐含状态h的计算方法与式(5)相同.
最终将每一个单元前向传播与后向传播得到的隐含状态结合起来,计算方法如下:

其中,⊕表示将两个向量拼接起来.然后送入注意力层.
(3)注意力机制与关系分类
近年来,注意力机制在深度学习的各个领域取得了成功.从本质上讲,深度学习中的注意力机制和人类的选择性注意力类似,都是从众多的信息中选择出对当前任务目标更重要的信息.本文采用了双重注意力机制.
由双向PL-Lattice 网络训练产生的输出向量组成矩阵h=[h1,h2,h3,···,hM],其中M表示句子的长度.
基于词级的注意力机制的句子表示的计算方法如下所示:

其中,ω为可训练参数矩阵,α为h所对应的权重向量.
为了计算每种关系相对于句子的权重,使用句子级的注意力机制,将句子S的特征向量h∗送入Softmax分类器:

其中,W∈RY×dhb∈RY为变换矩阵,为偏执向量.Y表示关系类型的数量.y表示每种类型的概率.
最终,给定所有的训练样本T=(S(i),y(i)),本文使用交叉熵作为目标函数来计算模型输出结果分别与真实结果分布的差距,如式(28)所示:

其中,θ表示模型中所有的参数.
3 实验数据与参数设定
3.1 实验数据的选取
由于公开的中文关系抽取语料库的匮乏,目前还没有较为通用且权威的中文远程监督关系抽取数据集.
本文使用的数据为中文的散文数据[10].该数据集收录837 篇中文文章,包含9 中关系类型,其中训练集695 篇,测试集84 篇,验证集58 篇.
3.2 性能评估指标与参数设定
本文实验采用3 种评估指标.召回率,F1 以及AUC.
召回率(Recall)是度量的是多个正例被分为正例:

式中,TP表示将正类预测为正类的数量,FN表示将正类预测为负类的数量.
F1是分类问题的一个衡量指标,数值在0~1 之间:

式中,FP表示将负类预测为正类的数量.
本文实验参数的设定如表1所示.

表1 实验参数设定
4 实验结果与分析
为了验证PL-Lattice 模型在中文实体关系抽取方面的效果,本文设置了5 组实验:
(1)BLSTM[5]:提出了一种双向的LSTM 用于关系抽取.
(2)Att-BLSTM[6]:在双向LSTM的基础上加入了词级注意力机制.
(3)PCNN[3]:提出来一种具有多实例的分段CNN模型.
(4)PCNN+Att[4]:利用注意力机制改进了PCNN.
(5)Lattice-LSTM[7]:使用基础的Lattice-LSTM 模型加注意力机制作为对比实验.
实验结果如表2所示.
各模型的召回率随训练次数的变化如图2所示.

表2 实验结果

图2 各模型召回率随训练次数的变化曲线
PL-Lattice 模型的F1 值和AUC 随训练次数的变化如图3所示.
从实验结果可以看出,注意力机制的加入能够使模型关注到句子中更重要的部分,从而提升模型的表现能力.由于LSTM 模型相对于CNN 模型在处理序列数据上拥有天然的优势,所以会表现出更好的水平.
本文提出的PL-Lattice 模型在各方面都优于其他5 种模型.经过分析,认为主要的原因是本文对于分词更加精准,模型使用了多粒度的信息,使词向量的表示更加合理化,并且加入了双重注意力机制,从多个方面提升了模型的可解释性和能力.

图3 PL-Lattice 模型F1和AUC 随训练次数的变换曲线
5 结论与展望
本文提出了一种用于中文关系的PL-Lattice 模型,该模型同时使用了字符级别和词级别的信息,并且引入了外部语义库来表示词向量,使其拥有更深层次的语义信息,避免了一词多义的现象.加入了基于词级和基于句子级别的双重注意力机制,关注了词和句子的多个方面.在散文数据集上与其他5 种模型进行了对比,表现出更好的优越性.
在未来,可以将更多粒度的语料信息融入到模型中,这些信息可能会由于模型挖掘更深层次的意义特征.
