一种基于邻居结构的影响传播模型
2021-03-18尹月双孙艳红
尹月双,孙艳红,刘 勇
(黑龙江大学计算机科学与技术学院,哈尔滨 150080)
0 概述
社交网络充实了人们的生活,脸书、新浪微博、推特等社交网站的出现,使人与人之间的交流与沟通变得更为紧密。目前很多在线社交网站都支持评论、转发等操作,在此过程中,社交影响也随之产生,主要表现为人与人之间在情感、意见和行为等方面所产生的相互影响。由于社交影响出现在人类现实生活和网络生活的各个方面,因此其为数据挖掘领域一项重要的研究课题。
HANSEN 提出了影响的三度理论[1],他认为人们的行为能够影响到那些素未谋面的人,然而影响的过程复杂,仍然需要更深入的探究。例如:当用户在新浪微博上想要转发一条他的好友也转发过的消息时,他更有可能进入消息原始发起者的页面来转发该信息,但并不知道消息的原始发起者与好友之间的关系。在此方面,文献[2]对社交网络中的影响与关系进行描述,文献[3]研究社交网络中影响传播的最大化问题,文献[4]则提出一种异质网中测量基于不同主题社交影响的方法。然而上述文献都集中于研究目标用户与某个好友之间的相互影响,忽略了多个好友所形成的不同结构对用户本身的影响。文献[5]指出结构多样性的影响,表明邻居用户所形成的多样性结构会对目标用户的行为产生不同的影响,但是该文献只进行了结构多样性影响的理论研究,没有进行量化。文献[6]列举了20 种邻居结构,通过统计周围活跃节点和不活跃节点的数量来计算每种结构的影响概率,但由于每种邻居结构的影响概率被独立计算,因此其未考虑多个结构的联合作用,从而导致计算结果不够准确。
本文研究不同邻居结构对目标用户的影响,构建基于邻居结构的影响传播模型NS-IC,并通过期望最大化(Expectation Maximization,EM)算法学习邻居结构的影响概率。EM 算法利用迭代更新参数的方式最大化完全似然函数,因而可以得到更准确的结果。通过NS-IC 模型所得到的结构影响概率,可预测引文网络中论文是否会被广泛引用[7],也可预测社交网络中用户与用户之间成为好友的可能性[8]。
1 相关工作
社交影响是数据挖掘领域的热点研究方向,下文将把社交影响分为个体影响和结构影响两类分别进行介绍。
1.1 个体影响
现有对于社交影响的研究讨论了不同形式的社交影响。最初,影响传播问题几乎都集中在流行疾病传播领域,之后发展到社交网络传播,如新思想的传播、新技术的采用等。2003 年,KEMPE 提出了社交网络中影响传播的最大化问题[3]。2008 年,ANAGNOSTOPOULOS 研究了社交网络中社交影响和关系,指出一个用户的行为可以促使他的朋友进行相同的动作,这都是社交影响的作用[2]。同年,SAITO 等人在独立传播模型[3]的启发下提出了测量两个用户之间成对影响的方法[9],基于用户与用户之间的社交关系和交互情况进行问题定义,其中,成对影响可能发生在直接相连的两个用户之间,也可能发生在没有直接相连的用户之间。2009 年,TANG 等人指出基于不同的原因会产生不同的社交影响,比如一个人的工作可能会受到同事的影响,而一个人的生活可能会受到朋友的影响,由此提出一个模型来模拟大规模网络中基于不同主题的社交影响[10]。此后,ZHANG 等人从个体的自我中心网络展开研究,并将其形式化地定义为社交影响局域性,其认为影响概率与活跃邻居的数量成正比,与邻居所形成的不同结构的数量成反比[11]。2012 年,LIU等人提出一种在异质网中测量基于不同主题的社交影响的方法[4]。2017 年,YU 等人通过对边上权值以及每个节点激活时间的观察,描述了影响传播过程中传播结构的学习问题[12]。2018 年,YOOSOF 等人在独立传播模型的基础上提出两种加权的方法来评估信息传播的概率[13]。同年,WANG 等人探讨了如何有效利用社交影响来完善推荐[14]。前期研究大多认为相互关联的用户具有相似的喜好,而后期较多研究都表明了社交影响的复杂性并对社交影响进行了深入分析,从而进行更合理的推荐。
1.2 结构影响
2012 年,JOHAN 等人指出社交网中结构的多样性对信息传播以及用户本身会造成影响,表明结构是影响个体决策的重要因素,传播的概率与和它相连的不同结构的数量紧密相关。此后,这个思想被广泛应用于不同的场景[5]。2014 年,FANG 等人将该思想应用到游戏领域,研究在游戏网络中用户的支付行为是如何相互影响的[15]。2015 年,KLOUMANN等人在应用程序网络中使用了该思想,认为用户使用应用程序的概率依赖于本地网络的属性结构[16]。2017 年,ZANG 等人量化了信息传播的结构模式,对微博7 天内产生的所有信息传播进行整理,使用七维度量的方法反映了信息传播的规模和方向,并且通过对7 种指标的分析发现了全新的结构模式[17]。此后,又将七维度量的方法升级为十维度量,因为他们发现信息传播的结构复杂性远远超过了之前的推测,所以使用一个十维度量的方法来量化信息传播的结构特征,反映信息传播的方向、规模和轮廓等信息[18]。ZHANG 等人认为现有的研究不能区分特定的影响模式,进而提出一种模式挖掘算法列举所有可能的影响模式。2018 年,HUANG 等人提出了三元关系动态预测问题,指出三个用户之间由两条边过渡到三条边时社交关系强度会发生改变,并通过时间效应和用户与用户之间形成的不同结构信息来研究第三条边的形成是如何影响现有两条边的强度的[19]。同年,ZHAO 等人指出传统的PageRank 计算都是基于一条边,忽略了用户之间形成的不同结构对预测的影响,并将结构信息应用到传统的PageRank 计算中来衡量社交网络中用户的影响力,促使PageRank 更好地工作[20]。
目前,除StructInf-Basic 算法[6]以外,明确计算结构影响概率的研究较少。本文通过使用期望最大化算法,提出一种新的结构影响概率计算方法,并与StructInf-Basic 算法进行对比。
2 问题定义
本节介绍预备知识和文中所用符号,在此基础上给出问题定义。
社交网用G=(V,E)表示,其中,V表示用户集合,E⊂V×V表示边的集合,vi∈V表示某个用户,eij∈E表示用户vi与用户vj之间的关系,本文中所提到的社交网用户之间的关系指的都是好友关系,社交网中某一用户vi的邻居集合为Nvi。社交网可分为有向网和无向网。在有向网中,只有箭头所指的方向是有影响的,如存在一条vi指向vj的边,就表示用户vi的行为会对vj产生影响。而在无向网中,影响则是双向的,即被一条边连接的两个用户是相互影响的。研究结构影响问题所需要的另一个输入是用户的动作日志,用L表示。日志L中的每条记录格式为l=(u,s,t),代表用户u在时间t参与了事件s,所有事件的集合记为S。要计算影响概率的结构(即影响结构)是由2、3、4 个节点形成的所有拓扑结构C={C0,C1,…,C19},如表1 所示。其中,白色节点表示目标节点,灰色节点表示在目标节点活跃之前活跃的邻居节点。

表1 2、3、4 个节点构成的所有影响结构Table 1 All influence structures composed of two,three or four nodes
研究结构影响问题的一项重要工作是获取目标节点周围的影响结构,本文根据给定的社交网拓扑结构G=(V,E)和动作日志L获取行为传播图,行为传播图的定义由定义1 给出。之所以要获取行为传播图,是因为社交网仅描述了用户之间的好友关系,动作日志仅描述了某个用户在某一时刻的动作,想要获得节点周围的影响结构,就要知道在特定的时间段内该节点的活跃是受到哪些活跃邻居的影响,也就是遍历该节点的邻居节点,找到在该节点活跃之前参与过相同事件的邻居节点,使该节点及其活跃邻居节点组成一个图,这个图就是行为传播图,然后利用行为传播图挖掘该节点周围的影响结构。
定义1(行为传播图)行为传播图可以用有向图Gd=(L,Ed)表示,其中,节点l∈L是一条动作日志l=(u,s,t),它的边是两条动作日志之间的关系,表示li=(vi,s,ti)动作的发生会对lj=(vj,s,tj)产生的潜在影响。两条动作日志之间有边相连需要满足以下条件:1)节点vi与节点vj在社交网中是好友关系;2)两条动作的发生时间差小于给定的时间间隔τ,即ti-ti<τ。在行为传播图中,节点l的邻居集合记为。
为计算某一结构的影响概率,需要找到该结构周围的活跃节点和不活跃节点来构建行为传播图。活跃节点指每一条刚发生的动作l=(u,s,t),不活跃节点指用户u在[t,t+τ]这个时间间隔内未能激活的邻居节点。根据行为传播图列举节点周围的所有影响结构,然后计算影响概率,下文将给出结构影响的定义。
定义2(结构影响)目标用户vi在时间ti参与了事件s,周围与其相距γ跳(因为所列举20 种结构中目标节点与最远邻居节点的距离是3,所以本文选取γ=3)之内的邻居节点在[ti-τ,ti]这个时间段内也参与了事件s,记为活跃的邻居节点,则结构影响定义为:目标节点与γ跳之内的所有活跃的邻居节点所组成的不同结构对目标节点的影响。
定义3(影响结构挖掘)挖掘目标节点周围的若干个活跃邻居所组成的不同结构,计算它们对目标节点的影响概率。该问题的输入是社交网G=(V,E)和动作日志L,输出是不同邻居结构的影响概率。
3 解决方法
本节介绍一个新的影响传播模型,并在该模型上使用期望最大化算法学习邻居结构的影响概率。
3.1 基于邻居结构的影响传播模型
为计算邻居结构的影响概率,本文构建基于邻居结构的影响传播模型NS-IC。将邻居结构的影响概率作为NS-IC 模型的参数,通过求解模型参数来获得邻居结构的影响概率。
NS-IC 模型在IC 模型的基础上加入了结构影响的因素。IC 模型的工作原理如下:已知初始时刻活跃的节点集合,在t时刻每个活跃节点u有且仅有一次机会去激活其邻居节点v,激活的概率为Pu,v,如果节点v有多个邻居都是活跃的,那么这些活跃节点将以任意次序去激活节点v,如果节点v被激活,那么在(t+1)时刻,节点v将尝试激活其不活跃邻居节点,以此类推,直到下一时刻没有节点被激活,传播过程结束。假设目标节点周围的邻居结构对目标节点的影响都是独立的,NS-IC 模型的工作原理如下:根据社交网用户的动作日志可知t=0 时刻活跃的节点信息,当t≥1 时,如果目标节点v周围的任意邻居结构c在(t-1)时刻变得活跃,那么它就有一次机会去激活其邻居节点v,激活的概率为Pc。因此,在节点v多个邻居结构同时活跃的条件下,节点v被激活的概率如式(1)所示:
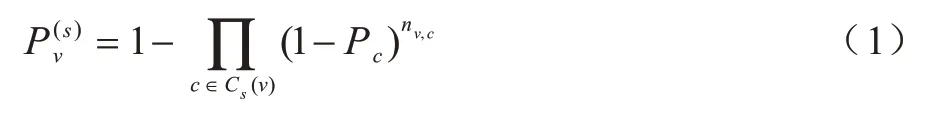
其中,Cs(v)表示事件s中可能影响节点v的拓扑结构集合(v)表示事件s中一定不影响节点v的拓扑结构集合。2 个集合中的元素都是不重复的,但是在节点v的周围可能存在多个相同的拓扑结构都对v有影响,因此,式(1)中的nv,c表示可能影响节点v的拓扑结构c的实例数。此过程持续到没有被激活的节点为止。
IC 和NS-IC 最主要的区别在于:IC 模型只考虑了活跃节点对相连目标节点的影响概率,而未考虑多个活跃邻居形成的不同结构对目标节点的影响,而NS-IC模型同时考虑了邻居结构对目标用户的影响。
以上内容可由图1 进行解释。给定社交网拓扑结构G=(V,E)和用户的动作日志{(v1,a,t0),(v4,a,t0),(v8,a,t0),(v3,a,t0),(v2,a,t1),(v5,a,t1),(v9,a,t1)},将v0看作要研究的目标节点,在初始时刻活跃的目标节点是v1、v3、v4和v8,根据IC 模型工作原理可知,活跃节点有且仅有一次机会去激活他们的邻居节点。再由动作日志可以看出v2、v5、v9相继活跃,如图1(a)所示,如果在下一时刻v0活跃,那么IC 模型只会认为是v2、v3、v5或v9的功劳,但是在现实生活中,一个人的行为不仅会受到朋友的影响,同时也会受到朋友的朋友的影响,即v1、v4和v8也可能对v0产生影响,并且他们所形成的不同结构会对v0产生不同的影响。如图1(b)所示,节点v0周围存在C1和C5两种结构,即Cs(v0)={C1,C5},这两个结构作用于v0,使得v0被激活的概率为Pv0(s)=1-(1-PC1)2(1-PC5)。同时可以发现,在结构C5中也包含C1,在这种情况下计算C5的影响时,并不会重复计算其中包含的子图的影响。

图1 结构影响传播示例Fig.1 Example of structural influence propagation
3.2 期望最大化学习算法
本节使用期望最大化学习算法求解结构影响概率,该算法的输入是社交网络G=(V,E)和用户的动作日志L={(u,s,t)}。令S代表事件集合,在学习中假设每个用户只能参与同一个事件一次,并且用户的动作日志流L中的用户u都属于G中的节点集合V。
在事件s∈S的传播过程中,以分别表示在事件s中活跃的节点集合和不活跃的节点集合。当节点时,节点v被结构c激活的概率为,其中,Pc表示邻居结构c的影响概率表示事件s中节点v被激活的概率。参照标准EM 算法的符号表示,以表示参数θ的当前估计,那么在当前参数设置下,事件s中节点v的邻居结构激活节点v的概率为:

其中,nv,c表示对节点v可能产生影响的结构c的实例数。在时间差τ小于正无穷的前提下,虽然活跃节点v的邻居结构存在多个实例,但是由于时间差的影响,并不是所有的结构都会对v产生影响,如在图1(b)中,C1的实例数是3,即nv0,c1=3,但是只有C1中的2 个节点对v0起作用,因此表示一定影响节点v的结构c的实例数表示一定不影响节点v的结构c的实例数。综合考虑以上情况,完全数据的对数似然函数(Q 函数)定义如式(3)所示:
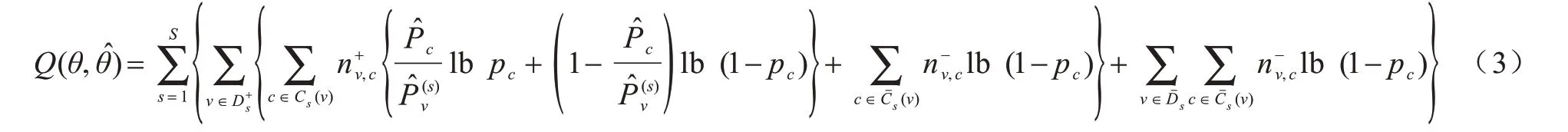
其中,S表示全部事件集合,θ表示全部参数集合。Q 函数的前一部分表示每一个事件s中所有的活跃节点v的对数似然函数,节点v的活跃可能存在两种情况:一种是受到某一结构c的影响;另一种是不受结构c的影响。Q函数的后一部分表示每一个事件s中所有不活跃的节点v一定不受结构c影响的对数似然函数。
由Q函数推导结构影响概率的具体过程如下:

算法1学习NS-IC 模型参数的EM 算法

以结构C0的影响概率为例的试验结果如表2 所示,可以发现ε在[0.001,0.01]区间取值时邻居结构的影响概率差别很小,运行时间随着ε的增加而逐渐降低,因此,下文实验中选择ε=0.01。

表2 不同ε 对运行时间的影响Table 2 Effect of different ε on running time
在算法1 中,步骤1~步骤3 的复杂度为O(|C|),步骤6~步骤8 的复杂度为O(|V|),因此,步骤5~步骤9 的复杂度为O(|S|×|V|),步骤10~步骤12 的复杂度为O(|C|×|S|×|V|)。因此,学习NS-IC 模型参数所使用的EM 算法总的复杂度为O(N×(|C|×|S|×|V|)),其中,|S|表示所有事件的个数,|V|表示所有节点的个数,|C|表示所有影响结构的数量,N表示收敛次数。由于EM 算法不到10 次就能收敛,因此可将N看作常数。影响结构的数量|C|在本文中设置为20,也是常数。综上,EM 算法总复杂度为O(|S|×|V|)。
算法2利用GetPattern算法获取


算法2 初始化一个行为传播图Gd以及一个队列Q,并且初始化两个空集合以及初值为0 的前两者分别用于存储当前事件s中任意结构c可能激活的节点集合以及一定不激活的节点集合,后两者分别用于存储对节点v有影响的结构c的实例数以及没有影响的结构c的实例数。的获取过程为:当一个新节点到达时,首先找到从队列Q中弹出的节点(算法2 步骤4~步骤6),遍历被弹出节点的邻居节点,判断哪些邻居节点不存在于队列Q中,也就是被弹出的节点在特定的时间段内没能激活的邻居节点,即为所研究的不活跃的目标节点v,本文目的就是要找到该目标节点周围不激活它的影响结构,因此,遍历该目标节点的邻居节点,判断哪个节点存在于队列Q中,从它们出发分别向目标节点引一条边构建行为传播图(算法2 步骤8~步骤9)。然后列举不活跃节点周围的影响结构,列举过程为:初始化两个节点集合Vsel和Vnei,将当前被研究的目标节点v放入Vsel中,它的活跃邻居节点放入Vnei中,每次从Vnei中选择一个节点放入Vsel中,再把被取出的节点的邻居节点放入Vnei中,但是Vnei和Vsel中的元素不能重复(算法2步骤10~步骤18),当Vsel中的元素个数大于1 且小于N时,在中加入该节点,通过GetPattern 找出Vsel中元素所组成的结构c,然后通过getpatternID 获取结构c对应的序号,当前结构c对应的个数加1(算法2 步骤19~步骤26)。的获取过程为:把每一个新到达的动作日志添加到队列Q中,然后遍历其邻居节点,判断有哪些邻居节点在队列Q中,找到存在于队列Q中的该节点的邻居节点,向其加一条边构建行为传播图(算法2步骤27~步骤29),然后再列举活跃节点周围的影响结构,步骤与列举不活跃节点周围的影响结构的过程一致(算法2 步骤30~步骤45)。
在算法2 中,步骤8~步骤10 和步骤27~步骤29的时间复杂度为O(|L|dmax),其中,L表示动作日志的长度,dmax是社交网G=(V,E)的最大度,步骤12~步骤26 和步骤31~步骤45 的复杂度是综上,算法2 总复杂度为,其中是行为传播图Gd的最大度,N是所有影响结构中节点的最大个数。
4 实验结果与分析
在大规模的微博数据集上测试和评估所提出的算法,并与现有算法进行比较。本文使用的源码和数据可从https://github.com/Vimotus/NS-IC 下载。
4.1 实验设置
实验所用数据来源于新浪微博(Weibo.com),其是一个社交网站,与推特(Twitter.com)类似,允许用户与用户之间进行信息评论或转发。基于用户之间的好友关系以及信息分享,从http://aminer.org/structinf 提供的数据中截取实验所需数据。首先选择20 个用户作为种子用户,记录每个用户的关注用户以及粉丝用户,分别选取这些用户在2012 年9 月至2012 年10 月期间转发和发表的所有微博消息,这个过程产生了1 000 个事件以及397 691 条记录,包含社交网G=(V,E)和一组动作日志L={(u,s,t)}。在社交网G中,如果存在vi指向vj的边,则表示用户vi关注了用户vj,而L中包含的元组(u,s,t)代表用户u在时刻t转发了消息s。将所选数据集用于算法2,得到每一个事件上每一个节点周围的影响结构,然后计算影响概率。
实验中的所有算法均使用C++编写,在VS 环境下编译。所有实验均在配置Intel®Core i7-7700K 4.2 GHz CPU、16 GB RAM 的台式机上运行。
4.2 对比算法和评价指标
将本文使用的EM 算法与以下算法进行对比。
1)StructInf-Basic 算法[6]:一种从社交流中评估结构影响的精确算法,其将结构影响定义为条件概率:其中,Xk表示对当前活跃节点有影响的结构Ck的实例数,Yk表示对当前不活跃节点有影响的结构Ck的实例数。
2)StructInf-S1、StructInf-S2、StructInf-S3 算法[6]:评估结构影响的3 种采样算法,分别对应以概率pnk对节点进行采样、以概率qmk对边进行采样、同时对边和节点进行采样,其中,nk表示模式Ck中节点的个数,mk表示Ck中边的个数,Xk表示由StructInf-Basic算法得到的精确结果分别表示由StructInf-S1 和StructInf-S2 得到的近似结果,并且保证所得结果是Xk的无偏估计,通过实验验证,p=0.6、q=0.9 时效果最佳。
将所有事件按照8∶2 的比例分成训练集和测试集,并且保证一个事件的传播日志或者全在训练集,或者全在测试集。首先在训练集上学习模型的参数,然后在测试集上进行测试,计算每个节点被激活的概率。节点激活概率的计算方法如下:首先通过NS-IC 模型可以得出每一个节点周围不同结构的影响概率,然后根据式(1)得到每一个节点被激活的概率,即为预测值,最后根据预测的概率值计算如下指标来分析预测的性能。
1)均方误差(Mean Square Error,MSE):计算节点vi的预测值与真实值Pi(活跃为1,不活跃为0)之差Ei的平方,然后累加求和再求平均值。
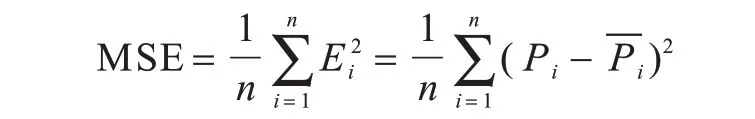
2)准确率A:所有被正确预测的节点数占节点总数的百分比。其中,TP 表示实际是活跃状态,预测也是活跃状态的节点数,FP 表示实际是不活跃状态而预测是活跃状态的节点数,TN 表示实际是不活跃状态,预测也是不活跃状态的节点数,FN 表示实际是活跃状态而预测是不活跃状态的节点数。

3)精度P:在所有被预测为活跃状态的节点中,真正活跃的节点所占的百分比。

4)召回率R:在所有真正活跃的节点中,被正确预测的活跃节点所占的百分比。
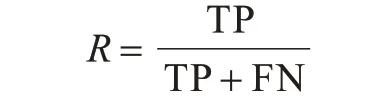
5)F1 分数(F1-score):模型精度和召回率的调和平均数。

4.3 不同算法的结果对比
通过在不同指标上的对比情况来表明本文算法的有效性。
StructInf-Basic 算法和3 个采样算法以及NS-IC模型在微博数据集上的均方误差、精度和准确率如表3 所示。可以看出:StructInf-Basic 算法及其近似变体的误差较大,因为它们在计算结构影响概率时使用了数学统计的方法,不同结构的概率计算完全独立,没有考虑多个结构的联合作用,使得预测结果较差;NS-IC 模型尽管假定不同结构的影响独立,但是考虑多个结构的联合作用构造完全数据的似然函数,并通过EM 算法逐步迭代优化计算出使完全数据似然函数最大化的结构影响概率值,因此其预测效果明显优于StructInf-Basic 算法及其近似采样变体。
为获得准确率和精度,将式(1)得到的节点预测激活概率与阈值δ进行对比,如果预测概率大于阈值δ,则认为节点活跃,否则认为节点不活跃。因为式(1)代表节点的激活概率,所以本文设置阈值δ=0.5。由表3 可以看出:NS-IC 模型在精度和准确率两个指标上明显优于其他算法,因为NS-IC模型同时考虑多个结构的联合影响,使用完全数据上的整体似然函数进行估计,不断迭代修正参数,直至收敛,使预测效果得到大幅提升;StructInf-Basic算法及其近似变体独立计算每个结构的影响概率,没有考虑多个结构的联合作用,因此预测效果较差。

表3 5 种算法的预测性能对比Table 3 Prediction performance comparison of five algorithms
综合实验结果和分析可以得出以下结论:NS-IC模型计算出的结构影响概率更准确,在实际中的预测效果更好。
4.4 时间间隔τ 的影响
在同一数据集上选择不同的时间间隔τ,由于节点周围存在的影响结构有所不同,因此会产生不同的结果。为证明时间间隔τ对结构影响概率存在影响,在实验中只考虑结构C0在不同时间间隔上的影响概率变化情况,通过改变τ值来观察C0影响概率的变化,如图2 所示。可以看出,C0的影响概率随时间的增长而快速增加,直到τ=25 以后才趋于平缓,因此,本文在选取数据集时设置τ=25。

图2 时间间隔τ 对结构影响概率的影响Fig.2 Effect of time interval τ on structural influence probability
4.5 应用
为进一步证明所获得的影响结构在实际中的作用,本节在微博数据集上利用影响结构来预测转发性能。首先在一些用户所具有的基本特征(如年龄、身份地位、好友数量等)下计算用户转发某一消息的概率;然后把结构影响模式作为特征加入,再次计算转发概率;最后将两个概率值进行对比得出结果。具体操作过程如下:已知每个节点的状态是活跃还是不活跃,随机采样相同数量的活跃节点和不活跃节点,训练一个梯度提升决策树(GBDT)分类器;然后先把每个节点的基本特征(Basic)加入到分类器中,预测每个节点的转发概率,再把影响结构作为特征加入到分类器中,但不是将20 种结构影响概率全部加入,而是分别将NS-IC 模型和文献[6]中的StructInf-Basic 方法所得到的影响概率中概率最大的前五个影响结构加入,计算节点的转发概率后进行对比;最后计算精度、召回率、F1 分数和准确率,实验结果如表4 所示。可以看出,将NS-IC 模型选出的影响结构作为特征填加到分类器中,转发预测效果改善更明显。这是因为NS-IC 模型和StructInf-Basic方法选出的前五个影响结构并不完全相同,NS-IC模型选出的影响概率模式更适合作为预测转发的特征。

表4 精度、召回率、F1 分数和准确率对比Table 4 Comparison of precision,recall,F1 score and accuracy
5 结束语
本文构建基于邻居结构的影响传播模型NS-IC,通过社交网和用户的动作日志流挖掘每个节点周围存在的影响结构,并将不同结构的影响概率作为NS-IC 模型的参数,使用期望最大化算法进行学习。实验结果表明,基于NS-IC 模型计算的结构影响概率能够准确预测用户转发行为。由于人们对不同的主题会发生不同的兴趣,进而形成不同的邻居结构,因此后续将对基于不同主题的结构影响问题进行研究,进一步优化NS-IC 模型。
