手机信令的时空密度轨迹点识别算法
2021-03-18陈略,熊宸,蔡铭
陈 略,熊 宸,蔡 铭
(中山大学智能工程学院广东省智能交通系统重点实验室,广州 510006)
0 概述
近年来,手机信令作为一种持续时间长、覆盖范围广的新型大数据被广泛用于交通出行行为和规律的研究。手机信令数据量大、采样频率不均、定位精度低以及基站振荡等问题,给其研究带来诸多难题。要实现手机信令在现实中的广泛应用,针对手机信令数据的基础性研究尤为关键。手机信令预处理与轨迹点分析作为手机信令研究的第一步,其分析结果是研究用户出行行为的基础,对研究用户出行行为与规律具有重要意义。
本文通过阐述手机信令特性,总结现有对数据预处理与停留点识别的研究成果,提出一种手机信令时空密度轨迹点识别算法。采用网络轨迹时空联结消除手机信令的空间不确定性,融合轨迹的曲折性、移动时间和停留时间重新定义网格簇内轨迹点时空移动能力,以网格簇时空密度为特征识别停留簇,同时使用基于簇的时空关系渐进聚类算法合并时空邻近的停留簇,并将其识别为停留区域。
1 相关工作
1.1 手机信令的特性
手机信令是一种时间序列数据,由基站的经纬度和时间戳构成。手机信令的产生有主动产生和被动产生两种方式。主动产生方式主要包括用数据流量上网、发短信、打电话等主动行为触发的基站响应;被动产生方式主要包括收短信、接电话等被动行为触发的基站响应。由于手机数据的产生无规律性,因此手机信令存在采样频率不均[1]、轨迹点时间间隔不规则以及轨迹点密度分布不均等问题。如果以0.5 h 为单位,将一天24 h 划分为48 个区间[2]来统计手机信令轨迹数据的区间数,则一天中未达到16个区间分布的轨迹数据视为稀疏数据。由于手机信令采样频率不均,在手机主动上网或移动的过程中,手机信令的采样间隔最小为1 s,并会连续触发同一个位置的基站,造成未经预处理的手机信令数据量大且信息冗余,不适合直接进行轨迹点识别。
手机信令相较GPS、卡口数据具有更大的空间不确定性,该特性由手机信令的定位精度和工作机制所决定。用户位置一般用其所在基站的位置表示,由于基站覆盖范围从几百米到几千米不等[3],因此手机信令精度较差。同时,受手机信令工作机制的影响,用户所在位置实际连接的基站可能并不是与其最接近的基站,由于某些区域的基站密度较大,某个地理位置可能同时被几个基站所覆盖,因此在该区域手机信号常随基站信号强度变化而不断切换基站,出现乒乓切换现象。一般而言,基站有负荷优化调节机制,当邻近基站用户负荷过大时,会自动切换到更远但用户负荷较少的基站,从而出现信号漂移[4]现象。此外,地形起伏、高楼遮挡等因素还会造成异常切换,从而引起手机在两个或多个基站之间相互切换的乒乓效应或信号漂移现象。据文献[5]统计,出现乒乓切换和信号漂移的数据量约占总数据量的30%。
乒乓切换和信号漂移并不代表用户存在真实的移动,如果不及时对其进行处理,会因高速度和远距离的切换或漂移影响停留点聚类,导致产生许多虚假出行数据。因此,针对乒乓切换和信息漂移造成的空间不确定性,研究人员尝试用速度或距离清洗规则清除含有该特征的数据,但由于乒乓切换与信息漂移规律尚不明确,清洗规则依据不足,且清除效果未知,因此通过清洗来消除空间不确定性还有待研究。本文采用不同于上述方法的思路,不以清除所有乒乓切换和漂移数据为目的,而将轨迹点震荡特征作为时空邻近一簇轨迹点徘徊与潜在停留的标志,并将具有这种特征的轨迹点通过时空关系联结为轨迹簇。通过将震荡的轨迹点同化为一个整体,忽略簇中轨迹点的经纬度和时间戳,并在算法中以簇为聚类单元,消除乒乓切换和漂移数据产生的空间不确定性。
手机信令具有空间不确定性,其除了是轨迹数据之外,还是一种典型的时空数据[6-8]。这类轨迹在聚类时需要同时考虑时间和空间两个维度,而目前缺乏以时间和空间两个维度度量轨迹点停留属性强度的指标,大部分算法仍采用时空分离的聚类算法,按照先时间后空间或者先空间后时间的顺序进行聚类。本文结合轨迹点簇内部以及前后轨迹簇间的时间、距离和曲折性定义轨迹簇的移动能力,并根据轨迹簇移动能力及其与前后轨迹簇的时空距离提出轨迹簇时空密度函数MAST 来度量轨迹簇停留属性的强度,并为停留点识别提供具体的参照指标。
1.2 手机信令预处理
手机信令预处理包括对时间连续的同位置点进行合并以减少轨迹量,以及对原始数据中大量乒乓切换数据和漂移数据进行处理,以消除空间不确定性。目前对乒乓切换数据和漂移数据的处理[4,9]有分层清洗[10-11]和多阶段去噪[1]两种方式。
分层清洗是先将噪声分为乒乓切换数据、漂移数据等,再针对各类噪声的特征制定不同规则进行清洗。乒乓切换数据主要有速度规则[12]和模式规则[5,13]两种清洗规则。速度规则为:若基站之间存在ABA 切换形式,且基站间速度超过一定阈值,则认为是乒乓切换,可按照一定规则清除。在模式规则方面,文献[11]通过定义乒乓切换形式,设定在基站间切换的模式,若检测到该模式则进行清除。文献[14]中结合速度规则和模式规则的乒乓切换清洗也较常见。对于漂移数据,通常认为其在短时间内与前后两个轨迹点相距较远,一般采用设定中间轨迹点与前后轨迹点间的速度来检测漂移数据[10],如果速度超过阈值,则认为是漂移数据;或者检测漂移点与前后轨迹点形成的角度,通过设置角度阈值来清洗漂移数据[11]。
多阶段去噪是将乒乓切换数据和漂移数据导致的偏差视为由移动通信机制和采集系统故障引起的系统误差,这种误差难以用数学工具来描述,即无法用任何随机分布形式来模拟和表达,但可将其在二维上表现为离群点,采用离群点检测算法进行处理[1]。与制定多种检测规则来清洗数据的分层清洗不同,多阶段去噪是将乒乓切换数据与漂移数据统一视为离群点进行处理。实际上,由于乒乓切换和漂移效应的形式具有多样性,且目前乒乓切换数据与漂移数据的内在规律尚不明确,因此无法评价清洗的有效性。文献[15]借鉴贪婪算法思想根据位置出现频率提出时空贪婪同化算法,寻找短时间内该位置点之间夹杂的其他位置点并形成集合,以实现位置点同化,从而消除空间不确定性,锚固长时间停留点的位置。但是仅按照频率自上而下合并,缺乏对于不同时间段的同一位置点(手机信令时间序列性)的考虑,容易将某些经常移动的点识别为停留点从而打乱轨迹序列。
消除空间不确定性在聚类中表现为受到噪声点的影响较小。由各种消除空间不确定性的算法可知:清洗思想以轨迹点为研究单元,通过划分时间阈值和距离阈值进行聚类,易被乒乓切换噪声点及漂移噪声点割裂为几个小簇;同化思想是将有震荡和徘徊等潜在停留特征的轨迹点同化为簇,并以簇为研究单元在轨迹簇之间进行聚类,受噪声影响较少。
由上述可知,同化算法更适合应用于噪声多、精度低以及复杂度大的手机信令数据。针对现有同化算法未考虑手机信令时间序列性,将高频率位置点间夹杂的低频率位置点归为一簇,并将所有时刻的该位置点归于其轨迹簇而忽视轨迹复杂性等问题,本文根据乒乓切换和数据漂移共有的震荡特征及交通出行时间的定义,设计在一定时间内空间邻近位置点及其夹杂的位置点互相环扣进行交织联结的时空联结流程,同时兼顾轨迹的时序性与时空紧密性。
1.3 停留点识别
停留点是一次出行的起讫点,其通常被定义为有目的的活动地点,且该地点的停留时间超过5 min。由于停留时间需要连续的空间累积,因此停留点的识别算法包括基于距离、时间、形状和密度的聚类算法。
基于距离的聚类算法[16-17]基于手机信令采样频率不固定的特征,通过相邻轨迹点间的距离来反映用户出行情况,以代替用相邻轨迹点间的时间差作为停留时间来判断用户是否停留。因此,可根据前一个轨迹点的移动或停留状态,以及前一个轨迹点与当前轨迹点的距离与时间差判断当前轨迹点的状态。但这种基于距离的算法易受到漂移点和前一个轨迹点状态判断错误的影响。此外,距离阈值和时间阈值的设定对聚类结果也有较大影响。
基于时间的聚类算法[18]沿时间轴将距离小于阈值的轨迹点聚类成簇,并通过判断簇的停留时间来识别是否为停留区域。基于时间的聚类算法易受漂移点和震荡点影响,从而将停留区域切分为多个小簇,且由于沿时间轴进行聚类,会将真正引起簇内距离过大的时间轴靠前的轨迹点纳入簇中,造成簇的划分错误。因此,时间阈值和距离阈值的选取在很大程度上会影响聚类划分结果。
基于轨迹形状[11]用定义的最小覆盖圆沿时间轴将轨迹点划分到簇中,当轨迹点超过最小覆盖圆时判断簇的停留时间,若大于停留时间阈值则判断为停留簇,若小于停留时间阈值则排除簇中时间轴最靠前的轨迹点,并从簇中第二个轨迹点开始循环。基于形状的聚类算法不受聚类顺序的影响,较基于时间聚类的算法能更有效地划分距离近的簇,但容易受到噪声影响而分为多个小簇,且该算法受停留时间阈值的影响较大。
DBSCAN 等基于密度的聚类算法根据手机信令的时间序列性,将Eps 空间邻域拓展到时间维度[10,19-20]。时空密度被定义为时空阈值范围内的轨迹点个数,对于采样频率不均的手机信令数据而言,不能将轨迹个数作为时空密度的度量标准,加上密度聚类参数选取困难,当采样频率不均时,聚类质量较差。
目前轨迹聚类算法存在以下问题:
1)对停留点构建指标的判断未结合时空两方面属性,只能定性判断轨迹点停留与否,无法定量反映轨迹点停留属性的大小。
2)仅将轨迹作为线性曲线处理,未考虑轨迹形状、曲折性等其他复杂的特性。
3)对于时间、距离、个数等聚类算法的阈值采取统一方式,未兼顾不同用户的出行特征。
针对上述问题,本文提出解决方案如下:
1)定义了融合时空特性的时空密度函数MAST指标,其用来度量轨迹簇中轨迹点的时空密度,并定量反映轨迹点停留属性的强度。
2)根据轨迹簇的曲折性以及移动时间和停留时间比例定义簇的移动能力,并作为轨迹特性融合到时空密度函数计算中。
3)不同于聚类算法中的阈值设置方法,本文根据时空密度函数MAST 的概率密度分布特征,自动划分符合个人移动特征的停留点密度阈值,避免了手动设置阈值不适用于全局数据的问题。
2 本文算法
本文提出基于时空联结移动能力的轨迹点识别算法,其流程如图1 所示。

图1 本文算法流程Fig.1 Procedure of the proposed algorithm
2.1 轨迹点网格化
为便于统一算法评估尺度与简化计算量,将研究区域网格化,并将基站的经纬度归入网格中,以网格序号代替。例如,将第i条记录轨迹点基站的经纬度(i,lngi,lati,ti)替换为网格坐标(i,xi,yi,ti)。
将研究区域网格化后,对连续的同网格轨迹点记录进行合并,只保留第一条和最后一条。例如,序列{(i,x,y,ti),(i+1,x,y,ti+1),…,(j,x,y,tj)}简化为{(i,x,y,ti),(j,x,y,tj)}。连续的网格轨迹点记录合并后成为前后两条相同网格的时间戳记录,由此可以明确在此两个时间戳及其之间时段内该网格的停留时间,并将该网格视为停留网格。由于部分网格无连续轨迹点记录,只有单个网格的时间戳,因此将此类网格视为单网格,无法知道该网格的停留时间。
2.2 网格轨迹时空联结
本文时空联结的思想是基于手机信令的振荡噪声及其停留与徘徊的特点:从起点切换到某地再回到起点附近的过程如果发生在短时间内,那么这段时间用户实际并未出行,仅在起点和切换点之间的某处静止或小范围地运动。由各城市居民出行的调查结果可知,一次出行的耗时通常大于5 min,其中在出行目的地的耗时超过5 min。由于从某地点出发再返回该地点附近的过程涉及一个活动和两次出行[15],因此该过程的最小时间间隔为15 min。
算法1网格轨迹时空联结算法


上述算法具体步骤如下:
1)假设网格化后轨迹数据集为D,cluster 为标识的网格记录集合,del_cluster 为待循环删除的网格记录集合,Cm 为所有网格簇集合,当前轨迹点记录(i,xi,yi,ti)∈cluster。
2)按时间序列输入当前轨迹点记录(i,xi,yi,ti),若下一条记录(i+1,xi+1,yi+1,ti+1)为相邻网格,则xi+1∈[xi-1,xi+1]且yi+1∈[yi-1,yi+1]。若(i+1,xi+1,yi+1,ti+1)不在cluster 中,则将下一条记录(i+1,xi+1,yi+1,ti+1)加入簇和del_cluster中,当前记录变为下一条记录(i+1,xi+1,yi+1,ti+1),即i=i+1,然后再从步骤2 开始;否则转到步骤4。若下一条记录所在网格与当前网格不相邻,则转到步骤3。
3)检测ti<t<ti+15 min 时间范围内是否有与当前轨迹点网格相邻的记录,即xi+1∈[xi-1,xi+1]且yi+1∈[yi-1,yi+1],将与当前轨迹点网格相邻的记录集合记为cf。如果该时间段内存在相邻网格记录,即length(cf)>0,则检测相邻网格记录是否存在不属于cluster 的轨迹记录,并将其记为ss,如果存在该轨迹记录,即length(ss)>0,则将这部分不属于cluster的相邻网格轨迹记录及其时间范围内所有不属于cluster 的轨迹记录全部加入cluster 和del_cluster,当前记录转为cluster 中最后一条记录,即i=cluster[-1].order number。若不存在不属于cluster 的轨迹记录,则转到步骤4,执行算法2;若ti<t<ti+15 min 时段内没有与当前轨迹点网格相邻的记录,即length(cf)=0,则转到步骤4,执行算法2。
4)删除del_cluster 中所有与当前轨迹网格序号相同(x=xi且y=yi)的记录,若del_cluster 仍不为空,则按时间排序,当前轨迹记录跳转到del_cluster 中时间排序最后的轨迹记录,即i=del_cluster[-1].order number(见算法2 中步骤1~步骤3)。若删除当前轨迹记录所在网格后del_cluster 为空,则转向步骤5。
5)将cluster 中网格轨迹记录标记为潜在的停留簇,并将cluster 加入Cm,当前记录跳转到cluster 中最后一条记录的下一条,即i=cluster[-1].order number+1(见算法2 中步骤5~步骤6)。
算法2删除与循环联结算法

算法2 是网格轨迹时空联结算法的子算法,其执行的是算法1 中在当前轨迹点不能再向后联结轨迹点的情况下,在簇轨迹点中从后向前寻找能继续沿时间序列向后联结的轨迹点作为当前轨迹点的过程。若簇内没有可以继续向后联结的轨迹点,则结束该簇联结流程,并将簇加入到Cm 中。算法2 的具体步骤为:在当前轨迹点与下一个轨迹点的网格位置不相邻,且当前轨迹点时间戳后的15 min 内无相邻网格可以联结情况下,删除del_cluster 簇中全部当前网格序号的轨迹点,并在簇del_cluster 剩余的网格轨迹点中选择时间戳最后的轨迹网格作为当前网格,继续对该簇循环执行算法1 的联结流程。如果删除后del_cluster 为空,无法再向后联结,则结束该簇的联结流程,将簇cluster 添加到Cm 集合中,向后联结下一簇。
在时空联结的簇中,停留网格记录需成对出现。通过时空联结的循环流程,可按照时间序列将一定时段和地理范围内停留或徘徊交织的轨迹点簇联结为网格簇。时空联结流程伪代码见算法1 和算法2。经过时空联结,网格主要有单网格、停留双网格以及网格簇3 种类型。
2.3 网格时空密度
本文参考文献[21-22]中密度的定义提出一种新的时空密度函数MAST,根据轨迹段的移动曲线特征并结合距离和时间分布情况,定义网格簇的移动能力和网格簇的时空密度,以体现出信令的时空特性与时间序列性。
图2为两种轨迹的移动情形。可以看出在同一个起始点和目的地的轨迹段中,移动的轨迹偏向进行直线运动(见轨迹1),而停留或徘徊的轨迹更偏向进行曲线运动(见轨迹2)。文献[21]根据图2 提出移动能力的概念,基于此,下文对直线距离和曲线距离进行定义。

图2 两种轨迹移动情形Fig.2 Two cases of track movement
定义1(直线距离)存在n-m+1 个点的轨迹段Traji={pm,pm+1,…,pn},Traji的直线距离为轨迹段起点pm和终点pn之间的直线距离,其表达式如下:

定义2(曲线距离)存在n-m+1 个点的轨迹段Traji={pm,pm+1,…,pn},Traji的曲线距离为各子轨迹段的距离之和,其表达式如下:

移动能力被定义为直线距离和曲线距离的比值[21],其表达式如下:

文献[21]对MA 的定义仅考虑整个轨迹段的曲折性,而长时间在职住地或者基站覆盖范围较大的区域停留时,与其他基站的切换较少但停留时间较长,如果只考虑曲折性,那么在停留区域位置不变的点的移动能力为1,其移动能力反而会异常大。因此,本文综合考虑轨迹的曲折性、移动时间和停留时间后,对网格时空移动能力进行重新定义。文献[21]针对核心点通过该点所在轨迹段的MA 及其周围网络接入点(Nap)对其产生的影响来定义,但其利用周围轨迹点个数划定移动能力的计算范围不适用于采样频率不均的手机信令数据。文献[22]基于轨迹点邻域半径R内包含所有轨迹段的最小值对轨迹点的移动能力进行定义,其划定邻域半径R作为轨迹点移动能力计算范围,但对于存在乒乓切换和信号漂移的手机信令而言,邻域半径R将轨迹的时间序列切割为多个轨迹段,而移动能力最小的轨迹段不能有效反映该连续时间序列的轨迹段移动能力。
本文网格轨迹N经过时空联结后形成网格簇序列{Traj1,Traj2,…,Trajf}(f为联结后的网格簇总数)。每个网格簇的移动能力通过自身轨迹与该网格簇和前后网格簇之间转移轨迹的影响,以及网格簇内的轨迹来定义。假设网格簇自身轨迹为Traji={pm,pm+1,…,pn},该网格簇与前后网格簇之间转移轨迹为dis(pm-1,pm)与dis(pn,pn+1)之和,转移时间为travel time(pm-1,pm)与travel time(pn,pn+1)之和,网格簇总时间为移动时间与停留时间之和。
定义3(网格簇移动时间)网格簇移动时间是当前网格簇Traji={pm,pm+1,…,pn}与前后网格簇转移时间以及网格簇内单网格与单网格、单网格与停留网格的转移时间之和,计算公式如下:
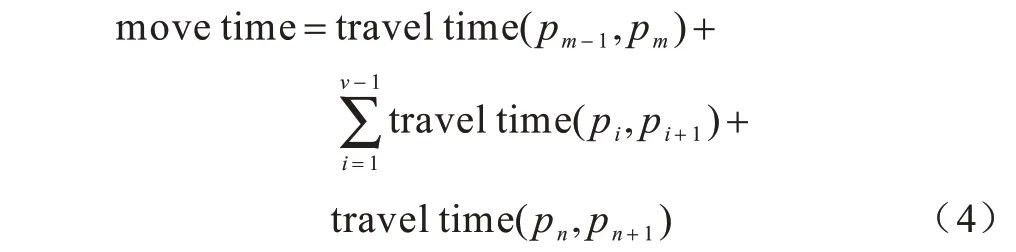
其中,v为当前网格簇内单网格与停留网格的总个数。
定义4(网格簇总时间)网格簇总时间是从网格簇Traji={pm,pm+1,…,pn}的前一点pm-1到网格簇的后一点pn+1所经历的时间,计算公式如下:

定义5(网格移动能力)网格移动能力是前后网格簇和当前网格簇的转移轨迹与当前网格簇内轨迹自身曲折性和移动时间比例的乘积,计算公式如下:
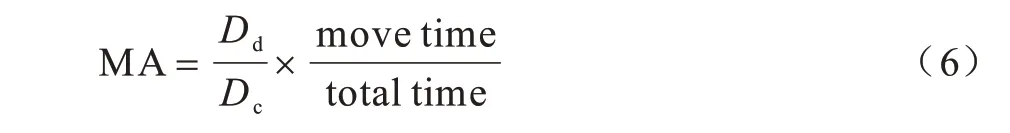
由式(6)可知:轨迹起始点与目的地之间轨迹越曲折,则网格移动能力MA 越小;整个轨迹运动中移动时间占总时间比例越小,则网格移动能力MA 也越小,与经验认知相符。
根据数据域理论,空间中每个数据点都会受其周围数据点的影响,且该影响随距离的增加而减弱。由于轨迹停留区域内数据点聚集程度明显高于移动区域内数据点,因此停留区域内每个点所受影响也高于移动区域内数据点[22]。与以轨迹点为研究单元,并以轨迹点与其周围轨迹点间的影响定义轨迹点密度不同,本文以网格簇轨迹为研究单元,结合数据域理论,通过时间序列前后网格簇及网格簇自身影响定义网格簇时空密度函数MAST,计算公式如下:

其中,σMA和σdis分别为移动能力权重函数和距离权重函数的标准偏差,ST(pk)=tk+1-tk为网格簇转移轨迹与簇内轨迹网格间的停留时间。
由式(7)可知:网格轨迹移动能力MA 越小,则网格间距离越小,停留时间越长;网格簇时空密度函数MAST 越大,则其为停留簇的可能性越大。与以往时空密度的定义不同[21-22],本文以网格簇为对象,利用时空联结形成网格簇来实现簇内轨迹的时空连贯性,同时簇与簇之间的转移距离与转移时间进一步保证手机信令的时间序列性不被空间邻域半径所割裂,并与轨迹曲折性相结合,充分应用手机信令特性,增强了时空密度判断的合理性。
通常采用速度来判断是否为移动和停留状态,但是由于手机信令的固有特性,用户定位基站并不代表用户的实际位置,且基站覆盖范围较广,存在覆盖区域相互重叠的情况,因此基站内停留时间较实际时间偏大,基站间转移时间较实际时间偏小,从而造成基站间移动速度较实际速度偏大。同时,因为存在噪声,乒乓切换和信息漂移的速度均较大,所以速度波动幅度较大。将各网格簇的平均移动速度与其时空密度函数值进行对比,结果如图3 所示。
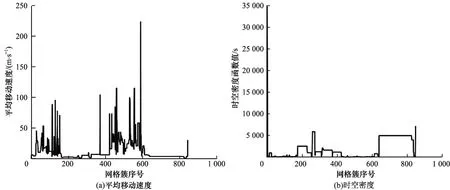
图3 网格簇的平均移动速度和时空密度Fig.3 Average moving speed and space-time density of grid clusters
由图3 可以看出:移动速度大的区域与许多速度小的区域交织,说明移动过程中存在个别减速或拥堵时段;网格簇的移动速度与时空密度的变化相反,移动速度大的网格簇时空密度小,而移动速度小的网格簇时空密度大,说明时空密度能够反映移动和停留的特性;时空密度较移动速度更稳定,对移动和停留更有区分性,因此其更适合作为判断移动和停留状态的指标。
时空密度函数参数包括密度函数中的σMA、σdis以及时空密度函数MAST 的最小密度阈值。对于σMA和σdis的选取,本文通过自行开发的基站采集APP 采集真实手机信令轨迹数据来验证参数选取的可靠性。将不同的σMA和σdis进行组合计算得到各网格簇的时空密度函数MAST,通过其数据概率密度分布自动确定最小密度阈值,筛选得到大于时空密度函数MAST 的最小密度阈值的网格簇个数,对比不同σMA和σdis组合下停留簇的变化情况,结果如图4 所示。

图4 不同σMA和σdis组合下网格簇时空密度的概率密度分布Fig.4 Probability density distribution of space-time density of grid clusters with different combinations of σMAand σdis
由图4 可以看出,σMA的取值为0.1~0.9,σdis的取值为0.5~50,不同σMA和σdis组合下网格簇的MAST 的概率密度分布基本相同。由此可知,σMA和σdis的取值对MAST 的概率密度分布影响较小,且σMA对MAST 的影响大于σdis。此外,MAST 概率密度分布曲线有两个峰值,较大峰值为用户职住地的时空密度,较小峰值包含移动簇和短时间的停留簇。根据经验可知,用户在工作地和居住地的活动时间通常占一天内大部分时间,其时空密度远大于移动点与短时间停留区域,因此两个峰值之间存在一段MAST=0 的分布。因此,可先采用K-means 算法将MAST 聚类为职住地、常规移动点和停留点两大类,再将MAST 密度小的一类(常规移动点和停留点)用K-means 算法再聚类为两类,将这两类的分界值作为MAST 最小密度阈值以区分移动簇和停留簇。综上所述,将MAST 用K-means 算法聚类为A、B、C和D 4类,不同σMA和σdis组合下MAST的聚类效果如图5 所示(彩色效果参见《计算机工程》官网HTML 版)。

图5 不同σMA和σdis组合下网格簇时空密度的K-means 聚类分布Fig.5 K-means clustering distribution of grid cluster space-time density under different combinations of σMAand σdis
由图5 可以看出,在不同σMA和σdis组合下网格簇MAST 的K-means 聚类分布中,移动簇和停留簇的分布基本相同,均识别出7 个停留区域,说明参数σMA和σdis的选取对停留区域的识别影响较小,通过K-means 聚类算法自动选取MAST 阈值得到的识别结果具有较好的稳定性。
2.4 网格簇时空聚类
从网格簇中识别出移动簇与停留簇后,将时空距离较近的簇进行时空聚类,以锚固停留区域并避免停留区域被噪声分割。
根据停留和出行的定义,一次停留时间需大于5 min,一次出行时间需大于5 min 且出行距离大于500 m。本文定义一次出行起讫点簇最小覆盖圆的圆心距离需大于500 m 且两圆相离,设计时空聚类流程如下:
1)计算各停留簇最小覆盖圆的圆心c、半径r以及簇停留时间st=tn-tm,即Traji={pm,pm+1,…,pn}中轨迹点首尾时间戳的差值。
2)若当前停留簇Traji={pm,pm+1,…,pn}与下一个停留簇Traji+1={px,px+1,…,py}首尾时间间隔tx-tn>5 min,当前停留簇Traji最小覆盖圆与下一个停留簇Traji+1最小覆盖圆相离,且其圆心ci与ci+1的距离大于500 m,满足出行条件,则转到步骤3;否则转到步骤5。
3)若当前停留簇Traji的停留时间st(i)>5 min,满足停留条件,则将停留簇Traji标记为停留区域,下一个停留簇成为当前停留簇;否则转到步骤4。
4)若当前停留簇Traji的停留时间不满足停留条件,则将该停留簇标记为延误区域。
5)将下一个停留簇Traji+1加入当前停留簇Traji,合成Traji={pm,pm+1,…,pn,px,px+1,…,py},重新计算最小覆盖圆的圆心ci、半径ri以及簇停留时间st(i),转到步骤2。
本文提出的网格簇时空聚类算法,考虑了停留簇之间时间间隔与空间的关系,是一种渐进的聚类算法[23]。该算法将一定区域的小空间簇进行聚合有利于锚固有意义的停留区域。
3 算例与结果分析
本文采用自行开发的基站采集APP 采集志愿者的轨迹数据(包括时间戳、基站经纬度、移动或停留标签数据)以验证算法的识别效果。基站采集频率设置为5 s 采集一次(由于各品牌手机硬件不同,因此,实际采集频率大于该值)。记录志愿者一天24 h 的轨迹数据,得到10 582 条数据,其中包括5 个停留区域与3 次交通换乘记录,由于换乘时间均大于5 min,因此3 个换乘站点在轨迹识别结果中均视为停留区域。将10 582 条记录进行网格化,并与同网格数据合并,只保留首尾两条数据,将数据简化为846 条,并通过时空联结操作将846 条网格数据划分为时空紧密相连的144 簇。表1 为时空联结生成的网格簇轨迹记录。以簇2 为例,将序号4 和序号5 记为组1,序号7 和序号8 记为组2,序号6 记为组3,序号9 和序号10 记为组4,组1 和组2、组3 和组4 分别表示簇2 内两个地理位置相同和两个地理位置相邻且时间间隔小于15 min 的网格簇轨迹记录,上述各组区域相互交织,共同形成簇2。

表1 时空联结生成的网格簇轨迹记录Table 1 Track record of grid clusters generated by space-time connections
从空间识别有效性和时间识别有效性将本文算法与改进DBSCAN 时空密度算法[21](以下称为文献[21]算法)得到的停留点识别结果进行对比,采用停留点个数、停留时间的准确率P、召回率R以及准确率和召回率的加权平均值F1 来评价本文方法的有效性,并通过对比两种算法的耗时以评价算法效率。文献[21]算法参数设置为:σMA=0.5,σdis=0.5,Nap=51。本文算法参数设置为:σMA=0.5,σdis=0.5。两种算法得到的停留点识别结果如表2 所示。可以看出:文献[21]算法检测到的停留区域个数在准确率和召回率上均明显低于本文算法,本文算法在空间上识别有效性更高;在时间的识别有效性方面,文献[21]算法检测到的停留时间等于与实际相符的停留时间且远小于标记停留区域的停留时间,停留区域个数多于标记的停留区域个数,说明文献[21]算法难以检测到停留区域的边缘点,且在噪声影响下将一个大的时空停留区域切分成几个小区域。
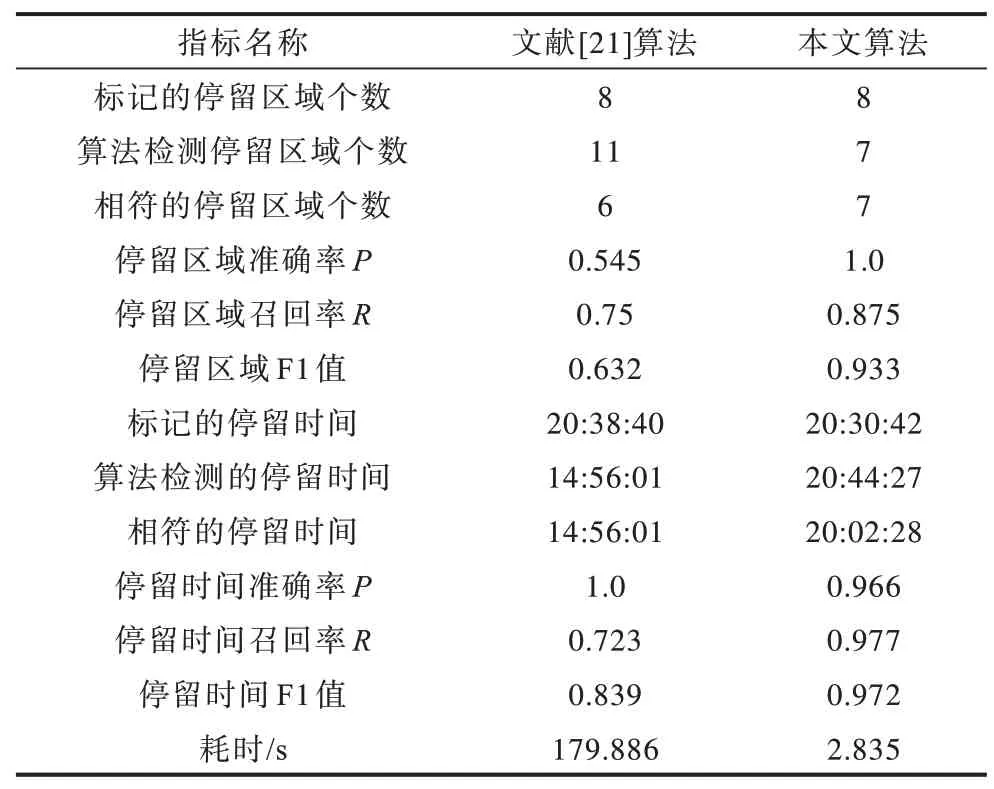
表2 两种算法的停留点识别结果Table 2 Recognition results of stop points of the two algorithms
在时间效率方面,文献[21]算法的时空密度计算次数为Nap×N(N为轨迹点的个数),本文算法的计算次数为网格轨迹时空联结后所得簇数S,文献[21]算法作为DBSCAN 聚类算法的变型,其复杂度为O(N2)。在计算效率方面,本文算法的耗时远低于文献[21]算法,计算效率更高,可直接应用于大样本的手机信令数据计算,而文献[21]算法无法应用于大样本数据的计算。
图6 为标记的停留区域与不同算法检测到的停留区域(彩色效果参见《计算机工程》官网HTML版)。其中,标记的停留区域stay4 被文献[21]算法分割为stay7、stay8(被stay9 覆盖)、stay9、stay10 和stay11 共5 个小区域,而本文算法检测到的停留区域与标记的停留区域stay4 地理位置一致,说明本文算法能将时空紧密的轨迹点联结为一个整体,并有效识别出停留区域,在较大程度上消除噪声以及采样不均造成的空间不确定性对停留点识别的影响,从而锚固住停留区域,不易使停留时空区域被分割。此外本文算法中时空移动能力相较文献[21]算法具有更好的区分性与稳定性,可使网格簇的时空密度测定更准确。
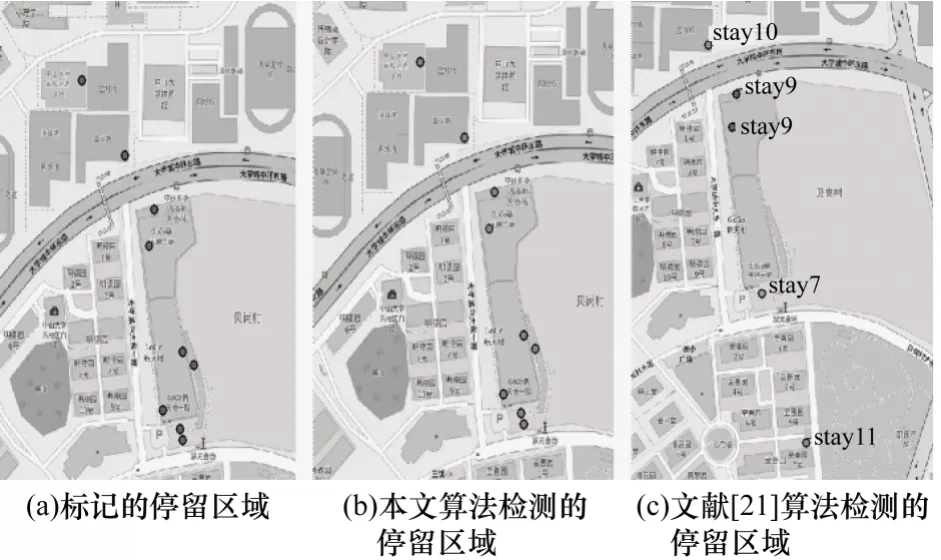
图6 标记的停留区域与不同算法检测的停留区域Fig.6 Marked residence area and residence area detected by different algorithms
由上述分析可知,文献[21]算法的可靠性除了选定σMA和σdis外,还与采样间隔及Nap 参数选取相关,而参数选取对本文算法影响较小,可根据时空密度分布自动选取阈值,因此本文算法的稳定性和可靠性较文献[21]算法更优。结合图6 中数据质量来看,由于本文实验采集的出行轨迹较密集,而现实中手机信令频率远小于实验采集频率,合并连续同位置的网格与现实中信令数据的触发更接近,且本文基于网格簇空间密度划分轨迹点,较基于轨迹点密度划分轨迹点在空间上的可行性更强,因此本文算法更适用于现实中手机信令轨迹点识别。
4 结束语
手机信令因具有数据采样率不均、定位精度低与空间不确定性,给网络轨迹点分析、出行链提取等基础性研究带来困难,而现有消除空间不确定性的预处理算法缺乏从时空角度综合度量轨迹点移动与停留情况的指标。本文提出一种时空密度轨迹点识别算法,根据出行定义和振荡噪声特征通过时空联结识别潜在停留簇,以消除空间不确定性对后续聚类的影响,同时结合轨迹的曲折性、移动时间和停留时间重新定义网格簇内轨迹点的移动能力,基于前后网格簇间与簇内轨迹点间的时空关系和轨迹簇移动能力构建时空密度指标进行轨迹点停留区域分析。实验结果表明,与改进DBSCAN 算法相比,该算法识别精度和时效性更高。由于轨迹点识别结果是具有停留属性的轨迹点集群,其中包括真实活动区域、候车区域以及交通拥堵区域等,因此后续将对停留区域的真实活动属性进行研究,以挖掘个体活动规律,进一步提高识别精度和效率。
