连续手语识别中的文本纠正和补全方法
2021-03-18,*
,*
(1.湘潭大学计算机学院·网络空间安全学院,湖南湘潭 411105;2.中国科学院计算技术研究所,北京 100190)
0 引言
随着残疾人信息无障碍建设的发展,自然手语和汉语互译越发重要,手语合成旨在将汉语语句翻译为符合手语语法的连续手语动作视频;而手语识别旨在将连续手语动作视频翻译为通顺可懂的汉语语句。手语识别面临两个难题:一是手语单词的边缘检测和时域分割;二是识别结果的手语文本语义可懂度的提升。近年来第一个难题已经得到有效解决,而第二个难题还处于探索阶段,本文基于该难题展开研究。
自然手语是一种视觉语言,有其自身的语法规则和特点。用自然手语表述事情时,通常把描述主体排在前面,然后再对主体进行描述,即宾语前置,其语序和汉语语序完全不同。此外还存在否定词后置、量词省略、动名词一体,没有“双重否定”等规则[1],如表1、2 所示。自然手语和汉语不同的语法规则使得连续手语识别结果的手语文本语义模糊,造成了健听人理解困难。此外,多数健听人和少数听障人掌握的手语为文法手语,即按照汉语语法顺序表达手语单词,这部分人对自然手语的理解也存在比较大的障碍。因此如何提高连续手语识别结果的可懂度,非常值得研究探讨。
在连续手语识别领域,目前多数研究为对视频的逐词翻译,得到的结果是不通顺的语句,并且受限于手语的复杂性和多模态性,难以收集和注释大规模的连续手语数据集。现今,国外连续手语的数据集以RWTH-Phoenix[2]为代表,其包含大约7 千条德国天气预报句子;国内连续手语的数据集为中国手语数据集(Chinese Sign Language,CLS)[3],包含少量日常语句以及对应的手语视频。以上两个数据集仅提供句子级注释,因此并不适合用来研究手语和传统语言的端到端互译问题。数据集的缺乏阻碍了国内外关于将连续手语动作直接翻译为传统语言的研究。在2018 年,Camgoz 等[4]首次探讨了这个问题,并基于RWTH-Phoenix 重新构建数据集,包含视频切分、注释以及对应的德语文本单词,利用机器翻译的方法实现手语视频到德语文本的端到端转化,将手语翻译上升到语义层次,而国内尚未有关于这一问题的专门研究。

表1 自然手语与汉语语序对比示例Tab.1 Word order comparison between natural sign language andChinese

表2 自然手语省略词示例Tab.2 Examples of word omitting in natural sign language
本文提出的方法将提高连续手语识别结果的可懂度转化为两种语言的翻译问题,直接对识别结果的手语文本进行处理,将研究重点完全转移到语言的处理上。由此,本文研究内容可阐述为:将连续手语识别结果的手语文本转化成符合汉语语法的通顺的汉语语句。
将不通顺的语句调整为符合语法的语句,以及语句补全等任务属于自然语言处理范畴,国内外对此都进行了许多研究。Yuan等[5]首次提出将神经网络机器翻译应用于文本语法错误纠正任务,利用翻译模型对大约200 万条平行语句进行训练,实现英文语法错误纠正。由于神经网络机器翻译模型依赖于大规模标注数据,难以应用在缺乏相关数据集的领域。国内Alibaba 的自然语言处理团队[6]在第八届自然语言处理国际联席会议(The 8th International Joint Conference on Natural Language Processing,IJCNLP 2017)共享任务中基于长短期记忆神经网络结合条件随机场(Long Short-Term Memory neural network and Conditional Random Field,LSTM-CRF)模型对汉语语句进行错误位置诊断,取得了综合指标第一名的成绩,该任务诊断冗余词(R)、缺词(M)、用词不当(S)和乱序(W)四种类型的语法错误。第七届CCF自然语言处理与中文计算国际会议(The Seventh CCF International Conference on Natural Language Processing and Chinese Computing,NLPCC-2018)提出中文语法错误修正任务恰好弥补了上述IJCNLP 2017任务只诊断不纠正的不足,在该任务中,有道团队[7]利用Transformer 的翻译模型取得了最好的结果。针对N-gram 模型依赖共现序列概率的缺点,Gubbins 等[8]以依存句法分析为基础,训练节点之间的N-gram 模型来实现语句补全,相比传统N-gram 模型提高了8.7%的准确率。Park 等[9]通过微调单词级循环神经网络模型的网络结构和超参数在微软研究院句子补全挑战中取得最好结果,但该工作略微缺乏在模型上创新。Islam 等[10]构建了包含单词排列错误、单词缺失的孟加拉语数据集,并利用LSTM 实现孟加拉语文本的校正和自动补全,在测试集上的准确度可达79%。
根据前文所述,在手语研究领域,国内缺乏解决连续手语识别文本结果的语义模糊、语序不通顺等问题的相关研究;且在相似任务上,国内外研究大多采用基于深度学习的方法,这些方法依赖于大规模标注数据,而难以获取和构建相关标注数据集正是阻碍国内研究进程的重要因素。针对这一问题,本文提出一种利用现有少量标注数据,将连续手语识别结果的手语文本转换为通顺汉语文本方法。
本文的主要工作如下:
1)设计转换规则,基于规则和N-gram 模型将手语文本语序转换为汉语文本语序,以此规避深度学习方法需要大量字符级标注数据的问题。
2)设计量词定位和补全模型,解决手语表达中量词省略的问题。根据量词的特性,利用序列标注的方法对量词的定位更准确。
1 基于规则和N-gram模型实现文本调序
针对手语表达中宾语前置以及否定词后置的特点,在N-gram 统计语言模型[11]的基础上,引入自然手语语法规则作为约束,将自然手语文本语序转换为汉语文本语序。
1.1 基于转换规则的文本调序
参考国家通用手语语法[12]以及上海、福建自然手语协会整理的语法,制定出自然手语文本到汉语文本的转换规则。调序流程如图1所示。对输入的自然手语文本进行分词、词性标注,分析出依存句法树,然后检测该文本是否符合规则库中的转换规则,若符合则根据相应的自然手语规则进行调序。自然手语文本与对应的汉语文本的规则转换示例如图2所示。

图1 调序流程Fig.1 Flowchat of ordering

图2 规则转换示例Fig.2 Example of rule transformation
1.2 基于N-gram模型的文本调序
基于N-gram 语言模型对文本进行调序,处理规则转换后的文本。利用语料库训练出N-gram 语言模型的N元词表,该词表包含训练语料中的所有N元词序列频度,集束搜索(Beam Search)算法利用N元词表对待调序的文本进行搜索,依据概率选择词汇,由此生成基于训练语料的概率最大词序列。如图3所示。
N-gram 模型全称为N元语言模型,其假设第N个词的出现只与前面N-1个词相关,常见的有二元语言模型Bi-gram 以及三元语言模型Tri-gram。
假设S表示某一个有意义的句子,S=(w1,w2,…,wn),其中wi是组成句子的词语,n是整个句子中词语的数量。则S出现的概率P(S)为:P(S)=P(w1,w2,…,wn),利用条件概率公式则有:

其中:P(w1)表示第一个词w1出现的概率;P(w2|w1)表示在w1出现时,w2出现的概率,以此类推。二元语言模型即第N个词的出现只与第N-1 个词相关;三元语言模型即第N个词的出现只与第N-1、N-2个词相关,由此分别得出概率公式如下:

N-gram 的精确度依赖于语料库的大小和质量,若某些N元词序列在训练的语料库中从未出现,但实际是符合语法并且存在的,此时N-gram 将会面临零概率问题。为此需要进行数据平滑,数据平滑的方法是重新分配整个概率空间,使所有的概率之和为1,并且使所有的概率都不为0。本文采用的是Add-one平滑模式,即让所有的N元词序列至少出现一次。
集束搜索(Beam Search)本质上是贪心的思想[13],不同于贪心搜索每一步只选择概率最大的假设,集束搜索则是维护一个容量为K的搜索结果库,第t步搜索结果库记为Ht,容量K称为集束宽度(Beam Width)。

其中:第t步的每一个搜索结果记为i∈{1,2,…,K}在第t+1 步对于每一个搜索结果均产生K个搜索结果,共K2个结果,保留其中概率最大的K个结果,记为Ht+1;当搜索到指定长度后,选择搜索结果库中概率最大的搜索结果作为最终输出。
图4 为单词序列“我”“爱”“北京”“天安门”的集束搜索示例,其中集束宽度为2。最终,以概率最大的“我爱/北京/天安门”这一序列作为最终结果。

图4 Beam Search示例Fig.4 Example of Beam Search
此外,在自然语言处理中,分词的准确度很大程度上影响着模型的性能,分词直接决定每个分词单位的语义是否完整,也决定了词表空间的构成,在本文工作中也不例外。因此,为保证手语词汇的语义完整,根据2019 年出版的《国家通用手语词典》构建的包含8 214 个手语词汇的词典,利用Hanlp 分词工具,优先使用该词典进行分词。
2 基于Bi-LSTM对缺失量词定位及补全
利用字符级双向长短期记忆(Bidirectional Long-Term Short-Term Memory,Bi-LSTM)模型对不包含量词的文本序列进行处理,预测出缺失量词的位置以及正确填补该量词。本文使用序列标注任务[14]的思想来处理这一问题,对于某一输入序列X={x1,x2,…,xn},其中xi表示该序列的第i个字符,预测序列的字符级标签L=(l1,l2,…,ln)。其中,li为量词表中对应的量词标签或者非量词标签。
Bi-LSTM 是LSTM 的一种变体[15],它将两个时间方向相反的LSTM 结构连接到相同的输出,以获取历史和未来的上下文信息,如图5 所示。前向网络接受输入x1,x2…,xt,从第一时刻到第t时刻,计算隐状态,反向网络则接受输入xt,xt-1…,x1,计算隐状态,由此可获取每个时刻的双向特征yt:

其中:W1为前向网络的权重矩阵;W2为反向网络的权重矩阵;b是偏置。

图5 Bi-LSTM 网络结构Fig.5 Bi-LSTM network structure
图6 为文本“我有三狗”的量词标注示例,在输入层,将每个汉字映射成字嵌入即一个固定维数的多维向量,并依次输入Bi-LSTM 进行处理,构造一个包含上下文信息的序列双向表达,输出经过softmax层进行分类,映射到相应的标签。
本文使用删除量词后的文本序列作为输入,前置位缺失量词的字符使用对应量词进行标注,其余字符都被标注为非量词标记符“O”,由此训练模型后既可定位到量词位置又可得到量词本身。

图6 量词标注示例Fig.6 Examples of quantifier annotation
3 实验验证与结果分析
3.1 数据集
文本调序采用的训练数据集是维基百科问答语料[16],该语料总共含有150 万条预先过滤过的、高质量问题和答案,每个问题属于一个类别,总共有492 个类别,其中频率达到或超过10次的类别有434个,语料内容以日常交流用语为主,基本涵盖了常见领域。本次实验对该语料截取50 万条数据并只保留“title”“desc”“answer”属性的内容进行训练。测试数据是《中国手语日常会话》[17]的日常用语500 条,部分示例如表3所示。
量词补全采用的训练数据是根据汉语常用量词构建的量词标注数据集,数据示例如表4 所示。此外,对所有数据都进行了清洗、去停用词等预处理。

表3 自然手语和对应汉语的文本示例Tab.3 Examples of natural sign language and corresponding Chinese text

表4 量词补全训练数据示例Tab.4 Training data examples of quantifier completion
比起单独采用N-gram 模型,融合规则信息,实验结果的综合指标明显提升,表明将规则融入N-gram 模型中是解决自然手语文本转换汉语文本的实用手段。

表5 文本调序实验评估 单位:%Tab.5 Evaluation of text ordering experiment unit:%
为了验证Bi-LSTM 的有效性,量词补全实验使用隐马尔可夫模型(Hidden Markov Model,HMM)[19]、LSTM、Bi-LSTM、Bi-LSTM+CRF 四个模型进行对比,并评估准确率、召回率、F1分数。HMM 是序列标注任务中应用较早的模型,一般作为基线模型。为了排除其他因素的影响,实验中LSTM 和Bi-LSTM模型的词向量维度以及所有的超参数设置相同。
由于中文量词具有同形词特性,一般会干扰量词定位,测试语句中包括了部分采用量词同形词的语句,如表6所示。
3.2 结果分析
双语评估替换(BiLingual Evaluation Understudy,BLEU)是目前用于评价序列到序列任务的最流行的指标之一,如文献[2,4]均用BLEU 作为评估指标。BLEU 采用一种N-gram 的匹配规则,计算出预测文本和真实文本间N元词共现的占比并不能很好地反映语法结构的调整[18],因此不适合用于评估该文本调序实验。为了验证提出方法的有效性,本文设计用以下方法进行评估:
1)绝对准确率(Absolute ACcuracy,AAC):预测语句与真实语句进行汉字一一对比,若某个汉字位置不能对应,则整句判定结果为错误。
2)最长正确子序列(Longest Correct Subsequence,LCS)匹配:将预测语句与真实语句进行最长子序列匹配,计算整个测试集最长正确子序列的平均占比。
本次文本调序实验分别对Bi-gram、Tri-gram、4-gram、5-gram 模型进行对比验证,设置集束宽度为20。文本调序的实验结果如表5 所示,只基于规则转换绝对正确率达68.60%,表明转换规则已经可以正确处理多数语句;此外,从Bi-gram到4-gram,随着上下文的依赖增长,各项指标均有所上升,说明上下文信息有助于调整语句结构。根据理论基础,在Ngram 模型中,N越大,实验结果应越好,但基于5-gram 模型的指标却不升反降。这是由于平均每条测试语句的词汇约为4.9 个,当N≥5 时,依据N-gram 原理,在训练语料有限的条件下,每条测试语句组成的N元词序列频度在训练好的N元词表中将会随着N的增大而减小,由此会影响模型的整体性能。此外,实验结果也表明,仅训练50 万条语料,4-gram 的模型大小和训练时长均约为Tri-gram 的2倍。因此,对于小规模短序列数据集,并不是N越大,模型效果越好,需视情况择优选择。

表6 包含量词同形词的语句Tab.6 Sentences containing quantifier homograph
量词定位和补全的实验结果如表7 所示,实验结果表明LSTM 模型综合指标最低,Bi-LSTM 的综合指标优于其他模型。HMM 是统计模型,其对转移概率和表现概率直接建模,统计共现概率。在该量词定位实验中,量词位置具有明显的特征,例如量词通常跟在数词或代词后,并且每个量词有相对固定的搭配如“一条狗,一只鱼”,HMM 能很好地提取这一信息。而LSTM 虽能捕获长距离依赖,但其只能提取上文信息特征,无法利用下文信息特征,序列的特征抽取不够充分,因此标注效果不理想。相比之下,Bi-LSTM 解决了LSTM 的问题,又得益于非线性的建模,所以取得更好的结果。另外,根据文献[14]可知,Bi-LSTM+CRF 作为目前主流的序列标注模型,其实验结果应优于Bi-LSTM,而本次实验训练数据为低维时序数据,且样本量相对较小,这是造成Bi-LSTM+CRF 性能稍次于Bi-LSTM的主要原因。
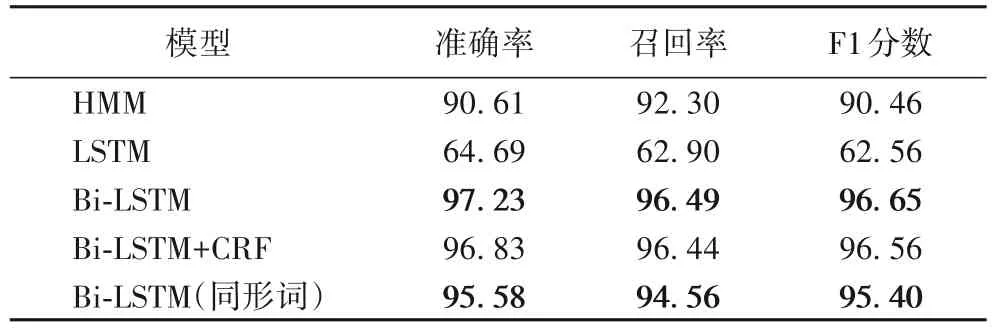
表7 量词标注实验评估 单位:%Tab.7 Evaluation of quantifier annotation experiment unit:%
包含量词同形词的量词定位和补全的准确率、召回率、F1分数分别为95.58%、94.56%、95.4%,表明该模型在有同形词的情况下仍然能够准确、有效地定位量词;但各项评估指标对比无同形词时有所下降,这是由于某些量词同形词也具有量词的特征,即跟在数词或代词后,易以较大的概率被标记为量词。
4 结语
本文针对自然手语语法存在宾语前置、否定后置、省略量词等特点,提出了两步法来对连续手语识别结果的文本进行语序调整以及量词补全,生成符合汉语语法的通顺语句。首先,基于自然手语和汉语的转换规则以及N-gram 模型对连续手语识别结果进行文本调序;然后,在此基础上利用Bi-LSTM模型对缺失量词的文本进行量词定位及补全;最终,将连续手语识别结果转化为语义清晰、语序通顺的汉语文本。实验结果表明,该方法可以有效提升连续手语识别结果的通畅度和可懂度。
此外,本文对基于视频的连续手语识别的文本结果中存在动名词一体、双重否定的现象未作处理,因此在接下来的工作中,需要进一步挖掘文本的上下文信息,解决自然手语翻译成汉语时的动名词一体问题。
