数据挖掘中的数据分类算法综述
2021-03-17程一芳
程一芳
(山西国际商务职业学院,山西 太原 030031)
1 决策树分类算法
1.1 C4.5分类算法的简介及分析
C4.5分类算法在我国是应用相对较早的分类算法之一,并且应用非常广泛,所以为了确保其能够满足在对规模相对较大的数据集进行处理的过程中有更好的实用性能,对C4.5分类算法也进行了相应的改进。C4.5分类算法是假如设一个训练集为T,在对这个训练集建造相应的决策树的过程中,则可以根据In-formation Gain值选择合理的分裂节点,并且根据分裂节点的具体属性和标准,可以将训练集分为多个子级,然后分别用不同的字母代替,每一个字母中所含有的元组的类别一致。而分裂节点就成为了整个决策树的叶子节点,因而将会停止再进行分裂过程,对于不满足训练集中要求条件的其他子集来说,仍然需要按照以上方法继续进行分裂,直到子集所有的元组都属于一个类别,停止分裂流程。
决策树分类算法与统计方法和神经网络分类算法相比较具备以下优点:首先,通过决策树分类算法进行分类,出现的分类规则相对较容易理解,并且在决策树中由于每一个分支都对应不同的分类规则,所以在最终进行分类的过程中,能够说出一个更加便于了解的规则集。其次,在使用决策树分类算法对数据挖掘中的数据进行相应的分类过程中,与其他分类方法相比,速率更快,效率更高。最后,决策树分类算法还具有较高的准确度,从而确保在分类的过程中能够提高工作效率和工作质量。决策树分类算法与其他分类算法相比,虽然具备很多优点,但是也存在一定的缺点,其缺点主要体现在以下几个方面:首先,在进行决策树的构造过程中,由于需要对数据集进行多次的排序和扫描,因此导致在实际工作过程中工作量相对较大,从而可能会使分类算法出现较低能效的问题。其次,在使用C4.5进行数据集分类的过程中,由于只是用于驻留于内存的数据集进行使用,所以当出现规模相对较大或者不在内存的程序及数据即时无法进行运行和使用,因此,C4.5决策树分类算法具备一定的局限性。通过对C4.5分类算法的简介和分析可知,在使用C4.5分类算法的过程中,一定要明确数据集的具体使用特征,然后再选择相应的分类算法,防止由于分类算法选择不正确,而导致在后期对数据进行分类使用的过程中,出现工作效率低,工作质量差的问题,同时负责C4.5分类算法和决策树分类算法的研究的工作人员,还应该明确现阶段决策树分类算法中存在的劣势,并且针对这些劣势进行相应的改进。确保C4.5决策树分类算法能够具备更好的适用性。
1.2 SLIQIQ算法的简介及分析
SLIQ算法是在C4.5决策树分类算法的基础上进行了相应改进的算法。在使用SLIQ算法的过程中,主要针对决策树的构造阶段进行了合理的改进,这里使用了预排序技术和广度优先技术。其中,预排序技术的主要工作原理是,对于连续性的属性来说,由于在内部的节点可以找到最好的分裂标准,因此,可以根据这一特性对训练集进行属性的取值和排序。但是,由于排序的过程中工作量相对较大,并且需要浪费很多的时间,所以通过SLIQ算法中的预排序技术和预排序功能,能够减少在决策树节点对数据进行排序过程中所需要做的工作量。预排序技术可以针对数据集中不同属性进行相应的取值,然后根据时间的先后顺序或者从小到大的顺序进行合理的排序。在具体实现的过程中,必须要针对数据集中的所有数据,根据不同的属性创立相应的属性列表,然后每一个属性列表中,对元组的类别进行合理的归类。再根据不同元组类别创立类别列表的过程中,其列表的主要形式如表1所示。
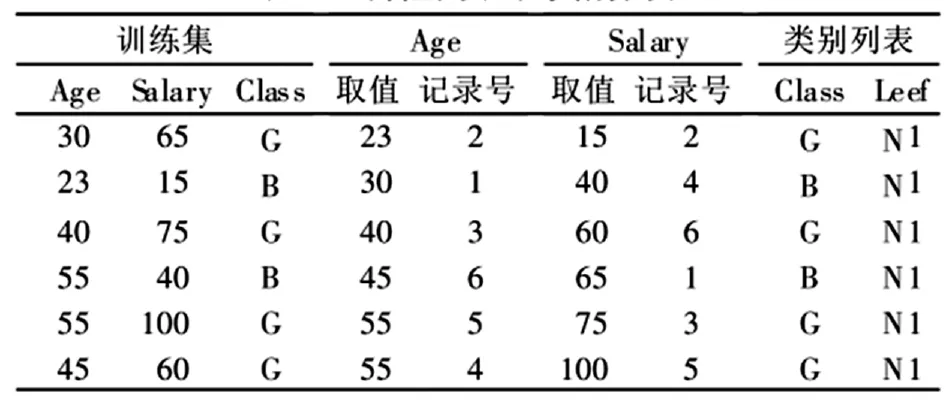
表1 属性列表和类别列表
通过表1中的数据分析可以得出,在建立属性表和类别列表的过程中,第一列代表了数据集中属性的取值,第二列代表了记录的顺序号。在类别列表中,第一列则代表了每一行记录的类别,第二列代表了不同的节点编号。在算法进行实现的过程中,还要确保计算机设备能够有较大的内存量来保存相应的列表数据。
广度优先策略的实际使用原理是在C4.5决策树分类算法的基础上,对决策树进行构造的过程中,需要按照深度优先的原则进行构造,并且要根据不同属性列表的节点进行相应的扫描。由于在传统决策树构造的过程中,需要针对每一个节点都进行扫描,这样即会浪费过多的时间,又会造成很大的工作量,而使用广度优先策略进行决策树构造的过程中,只需要对每一层的属性列表进行扫描即可,这样既提高了数据分类的效果,又可以使决策树中的节点有最优的分裂标准。
在使用SLIQ算法的过程中,由于使用了与排序技术和广度优先的技术,所以在数据处理的过程中能够比C4.5决策树分类算法具有更高的使用效率,同时也可以适用于规模更大的数据集进行分类的过程中,但是其实际使用中仍然存在一定的缺点,主要体现在以下两个方面:一是由于需要在预排序技术使用过程中,将类别列表放入在内存中进行使用,所以这就对内存的储存量具有较大的挑战,而类别列表的长度和训练集的长度是一样的,所以这对数据集的大小进行了相应的限制,从而导致SLIQ算法在实际使用过程中也具备一定的局限性。二是由于在使用与排序技术的过程中,虽然可以极大地降低工作量,提升工作效率,但由于算法相对复杂,并且数据的记录个数和排序算法的复杂度不呈线性关系,因此导致SLIQ算法的扩展性相对较低。
2 以关联规则为基础的分类算法
以关联规则为基础的分类算法主要包含CBA算法。CBA算法在进行分类的过程中主要包含两个工作流程:第一个工作流程是通过发现又不为类别的类别关联规则;第二个工作流程是通过对已发现的类别关联规则进行选择,然后通过高优先度的规则,对整个训练集进行覆盖。通过这种算法,在对训练集进行扫描的过程中,只需要进行一遍扫描即可,因此,具有较高的工作效率。CBA算法主要通过关联规则进行分类器的构造,而关联规则的算法为aprior,通过这种算法能够对大量交易记录中的规则进行相应的比较,并且有利于提高分类算法的工作效率,但是使用这种分类规则时,可能会出现某些规则的遗漏现象,因此,必须要将最小的支持度设置为0。但是在设置支持度的过程中,可能会导致CBA算法的优化作用降低,因此,使结果产生的频繁及在内存中无法显示和容纳,从而导致程序运行停止。CBA算法最大的优点是其在分类的过程中准确度相对较高,并且其发现的规则也较为全面。
3 以数据库技术为基础的分类算法
以数据库技术为基础的分类算法主要包含MIND算法。MIND计算法是根据数据库对用户的定义使用的相关函数,也叫做实现发现分类规则的算法,在使用这种算法的过程中和SLIQ算法较为类似,但是,由于这种算法主要根据数据库提供的UDF方法和语句进行决策树的构造,所以在术的工作过程中需要对每一层建立相应的属性为表,然后对不同的节点进行编号。使用这种方法在对决策树进行构造的过程中,是需要对每一个不是终点的节点进行数据集的信息计算和分裂标准的数据及分裂,而通过UDF进行实现可以使数据库系统的集成更加方便。这种算法的缺点是,由于需要使用高级语言进行分类计算,所以导致数据库法提供相应的查询机制,从而不能够使查询更加优化。
4 结束语
综上所述,现阶段针对数据挖掘所使用的数据分类方法相对较多,既有基于决策树的分类方法,又有基于数据库技术为基础和关联规则为基础的分类方法,在每种分类方法使用的过程中,又都有相应的优缺点,所以在选择分类方法时,要根据实际需求进行合理的选择。
