结合特权信息与注意力机制的场景识别
2021-03-17王龙玉刘佶鑫
孙 宁,王龙玉,2,刘佶鑫,韩 光
(1.南京邮电大学 宽带无线通信技术教育部工程研究中心,江苏 南京 210003;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引言
场景图像由于其类内差异大和类间差异小的特点,一直是图像识别中一项颇具挑战性的任务。随着深度学习方法,特别是卷积神经网络(convolutional neural networks, CNN)的蓬勃发展,图像识别的性能在大规模图像数据库(如ImageNet[1])的支持下已取得了显著的提高。为了支撑基于大规模深度神经网络的场景识别研究,各国研究人员也构建了一些大型的场景图像数据库。如Places数据库[2]和Places2数据库[3]等。其中Places2搜集了365种场景类别,图像数量超过600万张,是目前最大型的场景图像数据库。在这些大型数据库的帮助下,基于深度神经网络模型的场景识别方法[3]将场景识别的正确率推向了一个新的高度。
虽然大规模CNN模型辅以海量训练图像可以有效地提高场景识别的性能,但场景图像目标多、空间布局复杂、类间差异小的特点,使得完全依靠RGB图像一种模态的数据获得的场景识别性能与人类的认知能力仍有巨大的差异。
近年来,随着深度传感器的快速发展,将RGB图像与深度图像相结合的场景识别方法引起了研究人员的关注。研究结果表明,RGB图像与深度图像之间具有明确且强烈的互补性。基于RGB-D双模态图像进行场景识别比使用单模态数据的方法有明显的优势[4-5]。
然而,深度图像获取不易:一方面,现有的RGB-D图像数据库相比RGB图像数据库要小得多;另一方面,在场景识别的实际应用中,输入算法的往往只有RGB图像。如果能将训练时由双模态数据学习得到的互补信息应用到只有单模态数据的测试阶段,将明显改善目前基于RGB-D图像的场景识别研究严重受到有限训练数据库制约的现状。
针对上述问题,本文将深度图像作为特权信息进行使用。所谓特权信息是指在训练时可用,测试时不可用的信息[6]。本文结合特权信息和注意力机制构建了一种端到端可训练的深度神经网络模型,称为PIA-SRN (scene recognition network using privilege information and attention mechanism)模型。该模型通过图像转换(image-to-image translation)建立RGB图像和深度图像的关系。该过程可以描述为RGB图像编码得到RGB图像高层语义特征,再进行特征解码得到深度图像,最后进行深度图像编码得到深度图像高层语义特征。为了进一步提升双模态数据互补信息的结合效果,使用注意力机制对双模态高层语义特征进行融合,最后得到场景的预测信息。PIA-SRN在训练时基于双模态图像数据,在测试时只用输入RGB图像便可以取得更优的场景识别结果。
1 相关工作
1.1 基于RGB-D图像的场景识别
近年来,研究人员通过双流神经网络模型从RGB和深度图像中分别学习特定模态的特征,将两者融合后得出场景识别结果。Wang等[5]以模块感知融合的方式从不同的模式中提取融合深层特征。Xiong等[7]提出模态分离网络来提取模态一致性和特异性特征。然而,这些方法只考虑将颜色线索转移到深度网络,而忽略了深度线索也可以使RGB网络受益。Du等[8]据此提出了TRecgNet模型,其在编码网络上连接一个解码模块,并用语义损失对其进行优化,实现了缺失模态的生成,同时优化了编码网络,提升了识别效果。TRecgNet模型的核心是通过两个模态图像相互生成的过程,使各自的编码器网络学习有益的互补信息。从数据使用的角度来看,上述方法在训练和测试阶段都利用了RGB-D双模态图像进行场景识别。而本文方法则致力于结合特权信息和注意力机制实现训练时使用双模态数据,测试时只使用单模态数据的场景识别。
1.2 特权信息
特权信息(privilege information, PI)[5]是一种仅在训练期间可用而测试时无法获取的信息,已被应用于分类[5]、回归[9]等任务中。在计算机视觉中,许多信息可以被视为特权信息,例如文本和属性[9]等,这些信息根据具体问题设计和预定义。然而,现有的PI研究大多是基于支持向量机[5]的,随着深度学习研究的深入,研究人员开始探索基于CNN的特权信息使用方式。Hoffman等[4]以深度图片作为特权信息,用幻觉网络的方式学习一种新的和互补的RGB图像表示。Garcia等[10]同样使用深度图像作为特权信息对基于RGB图像的行为识别进行补充。在训练时,通过对抗学习与幻觉网络依据深度模态从RGB图像中模拟深度图像特征,从而在测试时缺失深度模态的状态下,提高RGB图像识别性能。本文利用双模态图像转换这种显性的操作,来隐性地实现双模态图像对单模态图像特征学习的有益补充,在训练阶段实现PI的嵌入,并在测试阶段发挥提升识别效果的作用。
1.3 注意力机制
图像识别算法中注意力机制的应用来自于对人类视觉系统的显著性研究。最近的工作证明,加入注意力机制的深度神经网络能提升多数图像识别任务的性能[11-12]。与针对单帧图像空间注意力建模和多帧图像时间注意力建模不同,本文方法中的注意力机制主要面向特征提取中的通道注意力。相关工作中,Wang等[11]提出编码器解码器样式的残差注意力网络,通过在普通Resnet[13]中增加由一系列卷积和池化操作组成的侧分支,突出特征图中有用特征,抑制无意义信息。Hu等[12]提出加入门控机制的SE-Net,挖掘通道间关系,选择性放大有价值的特征通道,抑制无用通道。本文考虑提取的特权信息特征与RGB特征间仍然存在着必然的联系,提出将注意力与特权信息相结合,促进彼此特征的提取,提高解码器生成特权信息的语义质量。
2 结合特权信息与注意力机制的场景识别网络
2.1 PIA-SRN模型概述
本文以深度图像为特权信息,构建了一个端到端可训练的深度神经网络PIA-SRN来实现场景识别任务。在训练时,通过上述网络将深度图像的语义信息迁移到对RGB图像的特征学习中,提升网络对场景图像的特征提取。在测试时,训练后的上述网络在只有RGB图像的条件下,可以获得较没有特权信息嵌入的网络更优的识别效果。
PIA-SRN模型主要由编码器网络(E-Net)、解码器网络(D-Net)、语义一致性网络(S-Net)、特权信息提取网络(PI-Net)、分类器网络(C-Net)和注意力模块(A-Mod)6部分组成,如图1所示。其中语义一致性网络在训练时,通过语义一致性损失拉近生成深度模态图像与真实深度模态的语义,保证了编解码器网络生成图像的语义质量;在测试时编解码器网络将无须语义一致性网络的指导,为减少运算,语义一致性网络将会去除。PIA-SRN模型的工作原理如图1所示。

图1 PIA-SRN模型结构示意图Figure 1 Schematic diagram of PIA-SRN model structure
从信息流程上看,RGB图像经过E-Net和D-Net后可以生成相对应的深度图像Igh和由RGB图像学习得到的高层场景语义特征Fr。Igh输入PIA-SRN后,可以得到与Fr对应的由深度图像得到的高层场景语义特征Fh。Fr和Fh经过A-Mod的处理后得到注意力加权后的高层场景语义特征Fa,输入C-Net后,便可以得到场景图像的识别结果。
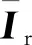
2.2 PIA-SRN模型的组成部分
2.2.1 编码器网络(E-Net)
编码器网络E-Net,由预训练好的Resnet18模型中的特征提取部分所构建,图1中S表示Resnet基本残差块中的步长。编码器输入尺寸为224×224×3的RGB图像Ir,输出14×14×512特征图Fr。为了防止信息的丢失,去除了Resnet18中的池化层。经过卷积核尺寸为7,步长为2的卷积块后通过4个基本残差块输出Fr,作为解码器网络的输入。
2.2.2 解码器网络(D-Net)
解码器网络分别由残差上采样模块和7×7卷积模块组成。输入为Fr,输出为224×224×3的深度图像Igh。为了提高模型在训练时的有效性,编码器与解码器间通过1×1卷积跳跃连接(skip connection)。编码器输出Fr作为解码器的输入,每经过一次残差上采样,尺寸扩大2倍,最终生成深度图像Igh,作为特权信息提取网络输入,在训练阶段也作为语义一致性网络的输入。
2.2.3 语义一致性网络(S-Net)
语义一致性网络采用了文献[8]中的网络结构,训练时解码器由Fr生成Igh提供损失信息。其同样使用Resnet18模型为基础,语义一致性网络输入为深度图像Igh与真实深度模态Ig,输出语义一致性损失为Lcontent。为更有效地拟合深度图像特征,本文先使用深度图片对Resnet18网络进行了预训练。本文摒弃了使用L1损失来生成深度图像Igh与真实深度模态Ig之间的语义,使用幻觉损失[4](hallucination loss)的方法来拉近每层特征。本文设定生成图像为Igh,特权信息为Ih,语义一致性损失为:
(1)
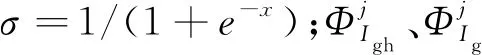
2.2.4 特权信息提取网络(PI-Net)
特权信息提取网络与编码器网络结构一致,但作用的对象不同:编码器网络从RGB图像中提取高层语义特征Fr,特权信息提取网络则是从深度图像中提取高级语义特征Fh,其输入为Igh,输出为Fr。
2.2.5 注意力模块(A-Mod)
注意力模块实现特权信息与单模态特征的结合,用于获取一组语义加权特征Fa,然后输出给分类器网络,得到最终场景分类结果,结构如图2所示。本文中采用了门控点乘的方式结合Fh与Fr。为了让Attention层适应特权特征和RGB特征,在Attention层前二者分别进行了一次卷积。Fh卷积后通过Sigmoid激活层生成了权重矩阵Fh1,选用Sigmoid的目的是将结果限制在0~1,以便于实现对Fr1的结果进行加权。Fh1如式(2)所示:
(2)
Fr卷积后获得特征Fr1:
(3)
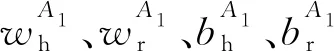
(4)

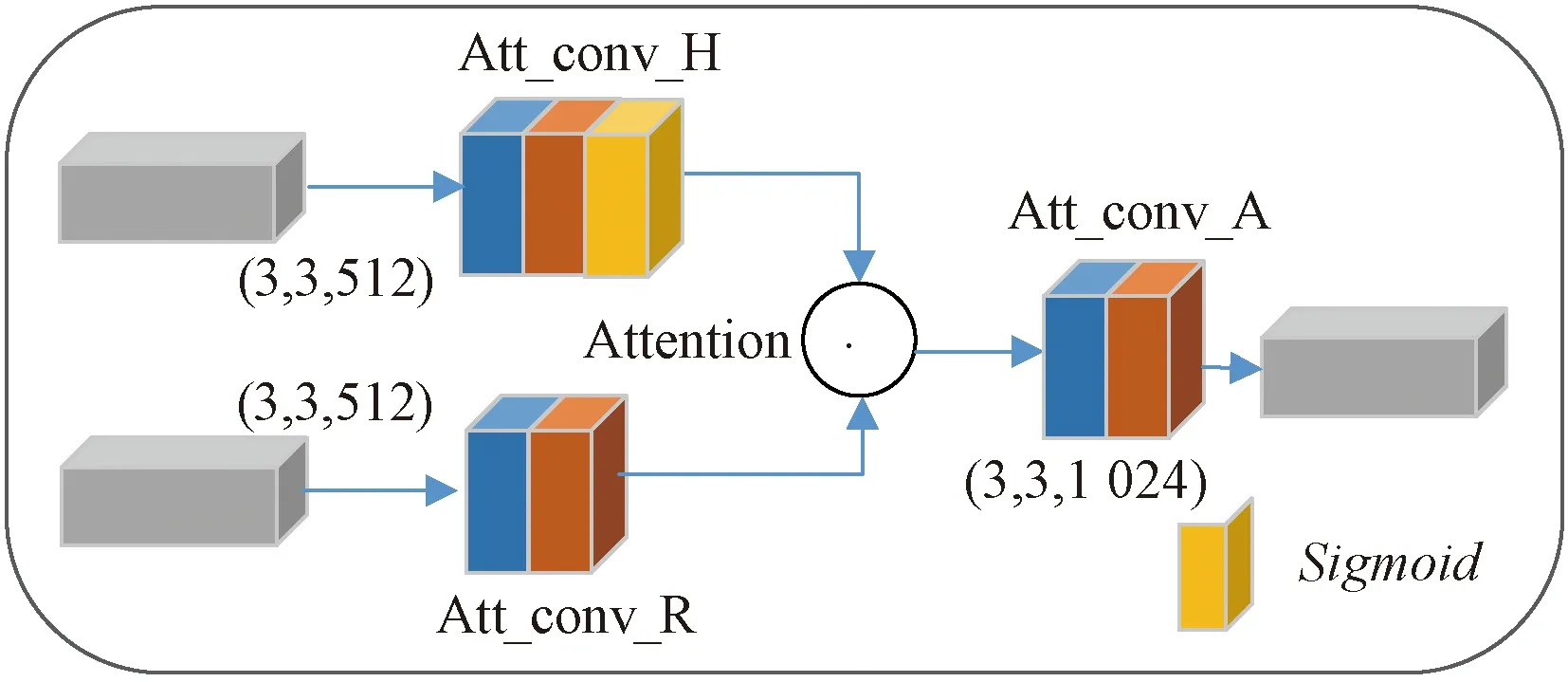
图2 注意力模块结构示意图Figure 2 Schematic diagram of attention module
2.2.6 分类器网络(C-Net)
分类器网络实现对Fa的最终特征学习和类别预测,由全局平均池化和3个全连接层构成。输入为Fa,输出为分类结果。全局平均池化维度为14×14×1 024,最后一层全连接层维度为类别数,经过softmax输出场景类别。
2.3 PIA-SRN模型的多任务训练
本文包含两个任务:一是对RGB图像进行分类,二是要拉近生成深度图像Igh与真实深度模态图像Ig之间的语义,利于特权信息提取网络提取高级语义特征。
对于网络参数的更新,通过多任务学习的方式进行学习,如式(5)所示:
Ltotal=αLcontent+βLcls。
(5)
式中:Lcontent为语义一致性损失;Lcls为分类损失;α、β为损失权重,本文中分类损失为交叉熵损失,经过多次实验,为突出语义一致的重要性,将α设为15,β设为1。
另外,由于所使用数据库中存在数据不均衡现象,本文对交叉熵损失采用权重重分配的方式平衡类别分类效果,如式(6)所示:
(6)
(7)
式中:N(y)为类别y的图像数量;c_max和c_min分别为训练数据类别中最多与最少的图像数量;δ设置为0.01。
3 实验与分析
在本节中,基于两个RGB-D场景图像数据库对本文方法进行全面的测试,并对实验结果进行了详细的分析。
3.1 实施细节
实验中,对深度图片采用HHA编码[14](水平视差、离地高度和重力角度)几何编码,以更好地表征深度图像信息。配对后的RGB图像与深度图像的尺寸先调整到256×256。为缓解训练中出现的过拟合现象,进行了数据扩增操作,将图像随机裁剪为224×224,并进行概率为0.5的随机水平翻转。使用Adam算法[15]作为优化器进行网络优化。设定训练样本的批尺寸(batch size)为16;学习周期为200次迭代;初始学习率为0.000 2,前30次迭代保持不变,之后进行线性衰减。实验结果中的正确率为3次实验的平均值。
本文方法使用PyTorch深度学习框架实现。所有实验在配置为2.4 GHz,8核英特尔至强处理器,128 GB内存,2块显存为12 GB的英伟达Titan Xp显卡的图像工作站中运行。
3.2 数据库介绍
SUN RGB-D数据库是目前最大的RGB-D场景图像数据库。包含10 355张RGB-D图像对。这些图像来自不同的采集设备,如Asus Xtion、Microsoft Kinect v1和Intel RealSense。本文遵循文献[16]中的标准实验设定,选取19个超过80张图像的主要场景类别进行实验。其中训练集共有4 845张,测试集共有4 659张。
NYU Depth v2 (NYUD2)数据库相对较小,包括27类室内类别。按照文献[17]中的标准划分,这些类别被分为10个类别,包括9个最常见的类别和1个代表其余类别的其他类别。按照标准划分方法,训练集、测试集分别划分为795、654张图像。
3.3 基于SUN RGB-D数据库的实验
3.3.1 特权信息有效性实验
这一小节测试了本文方法中特权信息的有效性。实验中使用了4种RGB高层特征与特权信息相融合的方法,分别为点乘、拼接、求和与基于门控点乘的注意力机制。比较了使用注意力前后网络的识别效果。通过表1的实验结果可以发现,本文将特权信息提取网络的特征与编码器网络的特征通过点乘、拼接、求和3种方式融合时,识别正确率分别比单独使用Resnet18取得的47.4%要高1.2、2.6和3.9个百分点;如果采用门控点乘的注意力机制,则识别正确率可以达到51.5%。由此,证明了特权信息和注意力机制对单模态图像识别性能的促进作用,验证了PIA-SRN模型可有效地将训练阶段学习的特权信息融合进单模态特征中。

表1 SUN RGB-D数据库中的特权信息有效性实验结果Table 1 Experimental results of privilege information validity in SUN RGB-D dataset
3.3.2 与基于RGB-D双模态数据的场景识别方法的对比
目前几乎没有公开报道的场景识别方法如本文方法那样在训练阶段以深度图像为特权信息,一般在测试阶段只使用RGB图像。只有在文献[8]中的TRecgNet方法有在SUN RGB-D数据库上只使用RGB图像测试的结果。其他绝大多数的方法在训练和测试时都使用了RGB-D双模态数据。尽管如此,将本文算法的结果与基于RGB-D双模态数据的场景识别方法进行比较,由此进一步证明特权信息的使用对于单模态图像场景识别具有促进作用。
根据测试时使用的数据不同,表2中列出了本文方法与3种只使用RGB图像的方法,以及10种使用了RGB-D图像的方法的比较结果。可以看出,在只使用RGB图像进行测试的方法中,本文方法取得了最优的识别正确率,并明显地高于其他3种方法。与使用RGB-D图像进行测试的方法相比,本文方法的正确率比其中的4种方法的要高,与2种方法的正确率很接近,低于另外4种方法的结果。一方面,再次证明了本文方法在训练阶段学习到的RGB-D的互补信息,在测试时发挥了明显的作用,在只使用RGB图像进行识别时,接近甚至超过了一半以上的使用RGB-D两种图像方法的识别性能;另一方面,本文方法只使用了全局图像特征,未采用局部特征等方式深入挖掘图像中上下文语义,或是使用RGB-D图像对进行模态间差异性的学习等技巧,正确率低于最新的几种RGB-D场景识别方法。这也是本文方法下一步的重点研究方向。

表2 本文方法与基于双模态数据方法在SUN RGB-D数据库上的比较Table 2 Comparison of the method in this paper with the two-modal methods in SUN RGB-D dataset
本文在图3中给出了在SUN RGB-D数据库中的混淆矩阵。通过观察混淆矩阵可以发现,本文采用了权重重分配等方法,已经大大改善了由于SUN RGB-D中类别不均衡较为严重,在场景分类时易误分类比例较高的现象,如bedroom。但由于有的类别如study_space类别数量确实过少,一定程度上还是有误分类的现象,这也将是本文接下来的工作重点。
3.4 基于NYUD2数据库的实验
3.4.1 特权信息有效性实验
与SUN RGB-D类似,本文在NYUD2数据库上也进行了特权信息有效性的实验。结果如表3所示。可以看出,在NYUD2库中所得的结果与在SUN RGB-D库中结果一致,再次验证了特权信息的有效性。同时值得注意的是,两次实验求和融合的结果都比较接近门控点乘的注意力融合的结果。这是由于E-Net和D-Net间跳线连接时采用的是相加的方式,特权信息特征更容易与RGB图像特征相匹配。
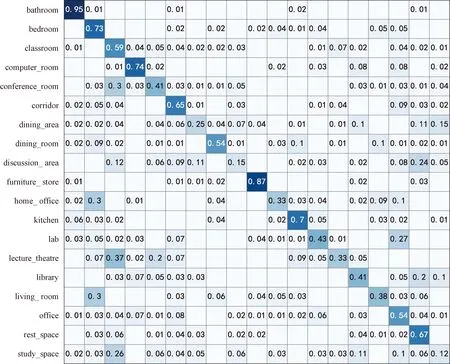
图3 本文方法在SUN RGB-D中的混淆矩阵Figure 3 The confusion matrix of this method in SUN RGB-D

表3 NYUD2数据库中的特权信息有效性实验结果Table 3 Experimental results of privilege information validity in NYUD2 dataset
3.4.2 基于RGB-D双模态数据的场景识别方法对比
同样,本文方法在NYUD2数据库上与其他12种方法的结果进行了比较,如表4所示。由结果可以看出,本文方法直接在NYUD2数据库上训练得到的结果要低于TRecgNet Aug。这主要是由NYUD2数据库过小(训练图像只有795张)导致的过拟合现象。所以本文采用在SUN RGB-D数据库上进行预训练的策略来缓解过拟合问题,由此得到了最高为65.4%的识别正确率。与其他使用RGB-D图像的方法相比,本文方法要优于其中的2种,与其中1种正确率一致,低于另外4种方法。与在RGB-D数据库上得到的结果趋势相同,也进一步验证了本文方法的有效性。同时,本文给出了在NYUD2数据库中进行场景分类的混淆矩阵,如图4所示,以便于观察实验结果。可以看出,NYUD2中类别间相对均衡,相较于SUN RGB-D中的实验结果也有了进一步的改善。

表4 本文方法与基于双模态数据方法在NYUD2数据库上的比较Table 4 Comparison of the method in this paper with the two-modal method in NYUD2 dataset

图4 本文方法在NYUD2中的混淆矩阵Figure 4 The confusion matrix of this method in NYUD2
4 结论
提出了一种端到端可训练的深度神经网络模型(PIA-SRN)。该模型结合了特权信息和注意力机制,在训练阶段学习RGB-D双模态图像特征,在测试阶段仅使用RGB图像进行场景识别。一定程度上缓解了深度模态图片难以获取,RGB图像特征提取不充分的现状。深度图像以特权信息的方式,提升了单模态RGB图像进行场景识别时的正确率,达到了多数使用RGB-D双模态图像识别的效果。在两个公开的RGB-D场景识别数据库SUN RGB-D与NYUD2上验证了本文方法的有效性。
