基于BERT的民事相关问答问句分类
2021-03-15武钰智常俊豪
武钰智 常俊豪


摘要:[目的]针对当前民事问句数据集不完全以及法律问答问句分类模型中存在无法利用语境信息或难以学习到复杂语句表示的问题,构建了基于BERT的问句分类模型。[方法]通过爬取的6万人工标记的民事相关问句作为分类的训练样本,构建了基于BERT-Base-Chinese的民事相关问句分类模型进行分类研究,并与SVM方法做对比基準。[结果]基于BERT的民事相关问句分类模型的分类效果均优于SVM方法,精准率和F1值分别达到0.978和0.973,F1值比SVM方法高出25.5%。[局限]仅对法律领域下的民事类别做了分类实验,没有将法律全部领域纳入。[结论]基于BERT的问句分类方法能够显著提高民事相关问句的分类效果,可以作为民事问答系统的问句分类模型。
关键词:问句分类;BERT;民事问句
中图分类号: TP311 文献标识码:A
文章编号:1009-3044(2021)01-0004-04
Abstract:[Objective] Aiming at the problems of the data set of the current civil question is incomplete and unable to use contextual information or difficult to learn complex sentence representation in the legal question answering classification model ,the question classification model based on BERT was constructed.[Methods] This study takes 60,000 manually marked civil issue-related question sentences as training samples for classification, and constructs a civil issue-related question classification model based on the BERT-Base-Chinese to perform cataloguing research, and the SVM method was used as a comparison benchmark. [Results] The question classification model of civil-related questions based on BERT is better than the SVM model in classification effect, the F1-score and precision respectively reaches 0.978 and 0.973, and the F1-score is about 25.5% higher than the SVM model .[Limitations]It only classifies the civil categories in the field of law,but does not include the whole field of law. [Conclusion] The question classification model based on BERT can significantly improve the classification effect of civil-related question and can be used as the question classification model for the civil-related question answering system.
Key words:question classification ; BERT; civil issues
随着我国社会主义法制建设的不断加强,民事法律由于关系民生大众而变得炙手可热。然而由于人们提出的民事问题只能由持证律师进行解答,并且我国现在的人均律师拥有率远远低于欧美等国家,这就导致一大批在线法律问答平台的回答率较低并且很难及时对提出的问题进行解答[1]。近年来,由于深度学习和人工智能的高速发展,金融、教育、医疗等领域都开始使用人工智能技术来完成各种各样的工作,因此如何将人工智能技术应用到法律领域成为重要的课题,而构建出一个专业的民事领域问答模型能够更好地解决回答率较低以及满足大众的需求[2-4]。问答系统(Question Answering System, QA)是自然语言处理和信息检索相关的重要学科,它可以满足人们对快速、准确地获取信息的需求[5]。在问答系统中一般有三个研究的基本问题,分别是问题分析、信息检索和答案抽取,其中问题分析主要是通过对问句分类等方面进行分析,是问答系统的重要模块,也是提高问答系统检索效率的关键要素[6][7]。
当前关于问句分类的研究,传统机器学习方法和深度学习方法均有广泛的应用。传统机器学习问句分类方法是利用人工标注得到训练样本,再经过预处理后,经过特征工程得到特征表征,然后交给分类器监督训练,得到预测结果。常用的模型有朴素贝叶斯[8]、支持向量机[9-11]、K-邻近模型[12]等。深度学习问句分类方法是通过一些深度学习网络自动进行特征提取,然后进行分类。常用的模型有FastText、RCNN和TextRNN等[13-15]。随着深度学习的不断发展,基于预训练的神经网络语言模型GPT(Generative Pre-trained Transformer)、BERT(Bidirectional Encoder Representations from Transformers)等在分类任务的各项指标上取得了显著提升[16]。
法律领域作为一个有大量数据积累的领域,非常适合现在由数据驱动的各种人工智能技术应用,然而法律领域的数据集标注需要大量法律领域的专业人士,这就导致法律领域的很多数据集规模并不够大而且质量也不够高[17]。因此针对法律特定领域,只有少数研究人员展开了法律问答系统应用的研究。莫济谦构建了基于CNN模型的中文法律问句分类模型,对采集到的250000条包括法律各个领域的问句进行粗细粒度分类研究,其中细粒度分类达到了92.14%的精度。此外还提出了基于长短期记忆网络(Long Short-Term Memory,LSTM)的层次分类模型,细粒度分类达到了93.82%的精度[18]。刘葛泓等重点研究了基于文本卷积神经网络(Text-CNN)的合同法律智能问答系统,并针对合同法的文本特征对其问句进行分类,实现了95.9%的合同法问句分类准确率[19]。
基于CNN、LSTM等架构的神经网络模型存在无法利用语境信息或难以学习到复杂语句表示,因此针对上述研究及问题,本文研究构建基于BERT的问句分类模型,并与SVM方法分别进行民事相关问句分类实验,然后分析其效果差异原因。
1 研究方法
1.1数据集的构建
针对当前法律特定领域的数据集规模不大质量不高的问题,本文通过爬虫技术在国内专业法律问答平台(www.110.com/ask)爬取18种常见的民事领域的问句,18种民事类别如表1所示。
为了将爬取到的民事问答数据转换成可用于问句分类的数据集,需要将爬取到的语料进行预处理(去除网页信息、回答信息等),随后按照6:3:1的比例划分训练集train_data、开发集dev_data和测试集test_data,从而构建民事问句分类数据集,数据结构如图1所示。
1.2基于BERT的问句分类方法
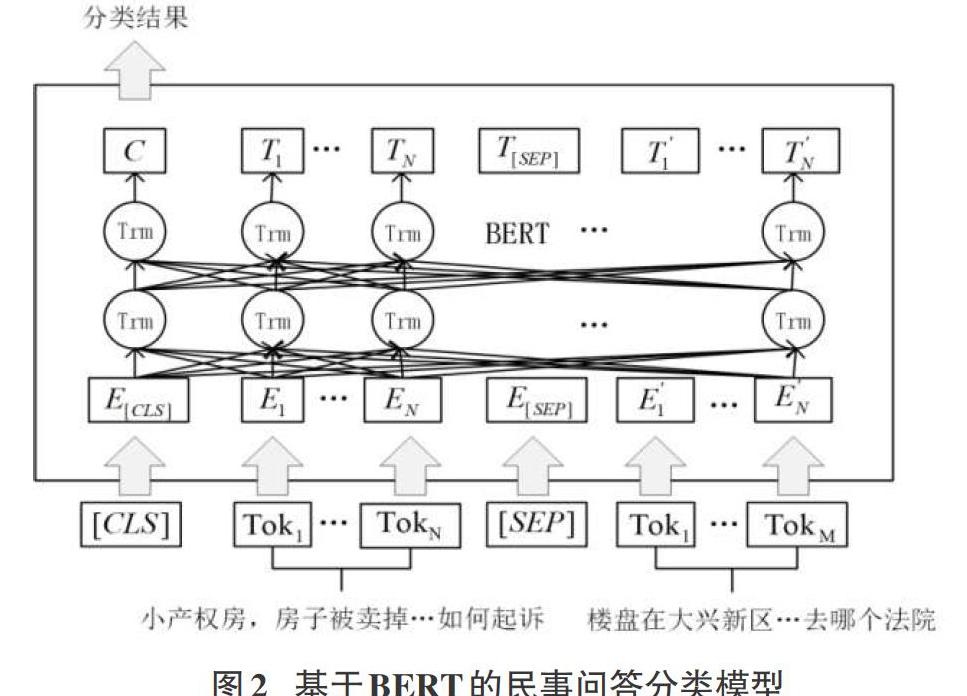
进行自然语言处理任务时通常会借助于语言模型,通常有两种在下游任务应用预训练语言表示的方法,分别是以ELMo为代表的基于特征的方法[20],在特定任务使用特定结构,将使用预训练语言模型训练出的词向量作为特征,输入到下游目标任务中;还有一种是基于微调的方法,以GPT为代表,指在已经训练好的语言模型的基础上,加入少量的特定任务参数, 例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行微调。在上述模型中由于ELMO使用的是两个单向LSTM替代双向LSTM,两者之间的参数并不互通,所以ELMO和GPT一样都是单向语言模型。而BERT是一种新的基于双向Transformer的语言模型,相比于单向语言模型它能够更深刻地理解语境,并且BERT进一步完善和扩展了GPT中设计的通用任务框架,使它适用于各种自然语言处理任务(如阅读理解任务、分类任务)。因此本文构建了基于BERT的民事问句分类模型,其模型结构如图2所示。
其中Toki表示第i个Token(随机遮挡部分字符),Ei表示第 i个Token的嵌入向量,Ti表示第i个Token在经过BERT处理之后得到的特征向量。
BERT的输入部分是线性序列,两个句子之间使用SEP进行分割,在开头和结尾分别加一个CLS和SEP字符作为标记。对于每一个字符都是由三种向量组成:词向量、分段向量和位置信息向量,三种向量叠加便是BERT的输入,如图3所示。
本文中基于BERT的问句分类方法为直接调用Google发布的BERT-Base-Chinese模型,在加入训练数据得到输出结果后增加一个分类层进行微调,再将其应用到问句分类任务中。
1.3 SVM分类方法
由于SVM具有可靠的理论依据,可解释型较强,在一些机器学习任务中具有良好的表现,并且经过发展也开始应用于多元分类任务,故选用SVM作为BERT的对比基准模型[21][22]。
在进行SVM分类实验时,本文采用一类对余类(One versus rest,OVR)方法构建多类分类器,如图4所示。
即假设总共有M个类别,对于每一个类,将其作为+1类,而其余M-1个类的所有样本作为-1类,构造一个二分类SVM。对于1类,将2类和3类都当成-1类,构造二分类SVM,其决策边界为d1;对于2类,则将1类和3类都当成-1类,构造二分类SVM,其决策边界为d2;类似地得到d3。
实验通过控制变量的方法分析分词方法、特征提取等因素对SVM模型分类效果的影响,选择分类效果最好的模型作为基于BERT问句分类实验方法的对比基准。
1.4评估指标
本文对于问句分类模型的评估指标有三个,分别是精准率P(Precision)、召回率R(Recall)以及F1值(F1-Score)。精准率又称查准率,是针对预测结果而言的一个评价指标,在模型预测为正样本的结果中,真正是正样本所占的百分比。召回率又称为查全率,是针对原始样本而言的一个评价指标,在实际为正样本中,被预测为正样本所占的百分比。针对精准率和召回率都有其自己的缺点:如果阈值较高,那么精准率会高,但是会漏掉很多数据;如果阈值较低,召回率高,但是预测的会很不准确。所以最后采用调和平均数F1值来综合考虑精准率和召回率两项指标:
2 实验结果分析
根据以上实验方法,本文分别构建了基于BERT的问句分类模型和SVM分类模型,使用经过预处理的同一数据集进行基于两种方法的分类实验。
2.1基于BERT问句分类模型的实验
使用BERT-Base-Chinese進行分类实验,经过不断对训练轮数(num_train_epochs)、学习率(learning_rate)、最大序列长度(max_seq_length)、批量大小(atch_size)等参数调整,本文参数选择如下:
num_train_epochs=6;learning_rate=2e-5;max_seq_length=512;train_batch_size=16;dev_batch_size=8;test_batch_size=8,实验结果如表2所示。
2.2基于SVM问句分类模型的实验
为了分析分词方法、特征提取等因素对SVM模型分类效果的影响,本实验采取控制变量的方法进行对比分析。经过对比发现,当选用jieba分词进行语料预处理,设置一元词、二元词,通过TF-IDF方法进行词频加权,参数C的值设置为0.4时效果最好,实验结果如表3所示。
2.3分类效果分析
为方便分析两种方法在问句分类效果上差异的原因,将每组实验中分类结果的平均精准率、平均召回率和平均值整理在一起,如表4所示。
从表4可以得出,基于BERT的问句分类模型的分类效果均优于SVM方法,平均F1值比SVM方法高出25.5%。
对于基于BERT的问句分类方法,整体分类效果较好,原因可能在于BERT相较于原来的语言模型可以做到并发执行。提取词在句子中的关系特征的同时,能够在多个不同层次提取关系特征,进而更全面反映句子语义。因此即便在有大量数据的多类别分类任务中BERT也可以取得很好的效果。
原因可能在于SVM方法最初是为解决二分类问题而提出的,而面对本文中多分类问题,使用OVR方法构建多类分类器时,一方面会出现样本不对称的情况,导致分类结果出现偏差。另一方面SVM在求解二次规划问题时,训练速度与m阶矩阵的大小有关(m为样本数),当m越大时,机器计算该矩阵的时间就越久。因此面对大量数据的多类别分类任务SVM方法难以有较好的表现。
综上,本文提出的基于BERT的分类模型表现出了良好的分类效果,证明了该模型的有效性并能够很好的应用到面向民事领域的问答问句分类问题。
3 结论
本文针对民事问句数据集不完全以及法律问句存在语义信息复杂的问题,构建了基于BERT的民事问答问句分类模型。对比分析了BERT和SVM两种模型对民事问句分类效果的差异原因,由实验结果可知,基于BERT的问句分类模型的精准率、召回率和F1值均高于SVM方法,表明基于BERT的问句分类模型能够更高效提取文本的语义特征,对后续的分类效果有很大的提升。
本文的局限性在于仅对法律领域下的民事类别进行了分类实验,并没有将法律全部领域纳入。在下一步工作中尝试将其拓展到法律全领域当中,更好地满足人们对于法律问题类别识别的需求。
参考文献:
[1] 朱颂华.常年法律顾问业务的现状与对策[J].法制博览,2020(7):170-171.
[2] Nakata N.Recent technical development of artificial intelligence for diagnostic medical imaging[J].JapaneseJournalofRadiology,2019,37(2):103-108.
[3] TimmermanA.Neural networks in finance and investing.Using artificial intelligence to improve realworldperformance[J].InternationalJournalofForecasting,1997,13(1):144-146.
[4] 周铭. 大数据时代的人工智能发展的法律思考[C]. 世界人工智能大会组委会.《上海法学研究》集刊(2019年第9卷 总第9卷).世界人工智能大会组委会:上海市法学会,2019:223-233.
[5] Prager J.Open-domain question:answering[J].Foundations and Trends in Information Retrieval,2006,1(2):905-912.
[6] 郑实福,刘挺,秦兵,等.自动问答综述[J].中文信息学报,2002,16(6):46-52.
[7] 张宁,朱礼军.中文问答系统问句分析研究综述[J].情报工程,2016,2(1):32-42.
[8] El Hindi K,AlSalmanH,QasemS,et al.Building an ensemble of fine-tuned naive Bayesian classifiers for text classification[J].Entropy,2018,20(11):857.
[9] Ou W,Huynh VN,Sriboonchitta S.Training attractive attribute classifiers based on opinion features extracted from review data[J].Electronic Commerce Research and Applications,2018,32:13-22.
[10] Jafari A , Hosseinejad M , Amiri A . Improvement in automatic classification of Persian documents by means of Na?ve Bayes and Representative Vector[C]// International Econference on Computer & Knowledge Engineering. IEEE, 2011.
[11] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,17(9):1848-1859.
[12] 李荣陆.文本分類及其相关技术研究[D].上海:复旦大学,2005.
[13] Zhang S,Chen Y,HuangXL,et al.Text classification of public feedbacks using convolutional neural network based on differential evolution algorithm[J].International Journal of Computers Communications &Control,2019,14(1):124-134.
[14]Lai S, Xu L, Liu K, et al. Recurrent convolutional neural networks for text classification[C]. national conference on artificial intelligence, 2015: 2267-2273.
[15]Le T, Kim J, Kim H, et al. Classification performance using gated recurrent unit recurrent neural network on energy disaggregation[C]. international conference on machine learning and cybernetics, 2016: 105-110.
[16] Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[EB/OL].2018:arXiv:1810.04805[cs.CL].https://arxiv.org/abs/1810.04805
[17] 盧新玉.浅谈我国目前作为法律人工智能基础的司法大数据存在的问题[J].法制博览,2020(21):202-203.
[18] 莫济谦.基于深度学习的法律问题层叠分类研究[D].长沙:湖南大学,2018.
[19] 刘葛泓,李金泽,李卞婷,等.基于Text-CNN联合分类与匹配的合同法律智能问答系统研究[J].软件工程,2020,23(6):8-12,4.
[20] Peters M E,Neumann M,Iyyer M,et al.Deepcontextualizedwordrepresentations[EB/OL].2018:arXiv:1802.05365[cs.CL].https://arxiv.org/abs/1802.05365
[21] 萧嵘,王继成,张福炎.支持向量机理论综述[J].计算机科学,2000,27(3):1-3.
[22] 白小明,邱桃荣.基于SVM和KNN算法的科技文献自动分类研究[J].微计算机信息,2006,22(36):275-276,65.
【通联编辑:唐一东】
