基于Mahout框架的社交网络服务数据过滤算法
2021-03-15刘丰年
刘丰年
(三门峡职业技术学院信息传媒学院,河南 三门峡 472000)
0 引言
近年来,由于移动设备数量和种类的猛增,社交网络服务的用户数量不断增加,由此产生的社交网络服务数据量也大幅增加。目前,社交网络已被广泛应用于多种社交信息的获取和分析。
社交网络的数据主要包括针对诸如经济、社会、文化等各个领域所表达的意见或内容。因此,通过对社交网络数据进行分析,可以有效获取关于社会、经济、政治等多个领域的流动信息和观点。然而,由于社交网络数据规模巨大,其中既包含了有助于人们分析的有价值数据,也充斥着大量的广告数据和不相关数据。因此,准确分析社交网络上的数据既困难又耗时。近年来,随着大数据研究领域的日益升温,如何基于有限的计算资源,以一种稳定而高效的方式收集和存储大数据,并对其加以处理成为一项重要的课题。
目前,关于大数据的研究主要集中在大数据基本理论和大数据分析应用两个方面。文献[1-4]深入分析了当前大数据理论的发展现状、取得的成绩以及未来的发展方向和可能面临的挑战,并对大数据特征的若干主要因素、机器学习工具以及典型的大数据处理引擎进行了描述和分析。相比大数据基本理论,大数据分析与应用研究显得更受重视,其主要研究热点在于任务调度[5]、网络流量预测[6]、工业大数据平台构建[7]以及专家系统构建[8-15]等领域。文献[5]设计了一种基于热感知和动态电压的大数据任务调度算法。李晓会等[6]构建了基于云计算和大数据分析的大规模网络流量预测模型,获得了较为理想的网络流量预测结果。文献[7]在现有大数据框架的基础上,提出了一种增强型的工业大数据平台,降低了数据处理时间和存储空间。文献[8]基于医院的结构化和非结构化文本大数据,提出了一种新的基于递归卷积神经网络的疾病风险评估模型;魏亮等[9]提出了一种新的大数据查询算法,该算法不仅具有较好的查询性能,而且计算复杂度较低;文献[10]提出了一种新的基于区块链的大数据市场公平数据交易协议,实验证明该协议具有很好的安全性;文献[11]设计了一种基于大数据和机器学习的博弈预测专家系统;Yang等[12]提出了一种使用文本分类方法的自动药物不良反应相关帖子过滤机制,能够有效地将这些有研究和参考价值的帖子过滤出来;文献[13]提出了两种去除噪声样本的大数据预处理方法,仿真实验表明该方法能够较好地将噪声数据进行滤除;文献[14,15]分别提出了物联网环境下有效信息与不良信息的过滤算法。
由以上文献分析不难看出,基于大数据技术进行专家系统构建,从而在生产、生活等方面为人们提供更可靠、更有价值的信息和决策已经成为大数据研究领域内的热点内容。以上文献虽取得了一定的进展,但关于社交网络服务的内容过滤却鲜有涉及。在此背景下,本文提出一种基于Mahout框架的社交网络服务数据过滤算法,从而进一步提升大数据分析精度与速度,仿真实验验证了本文算法的有效性。
1 本文算法
本文提出的社交网络服务数据过滤算法框架图如图1所示。该算法结构由三部分构成,包括数据分类生成器、数据分类器和数据分析器。其中,数据分类生成器主要用于执行数据分类。当输入初始学习数据时,系统通过形态学分析、分类算法等生成学习数据,并根据生成的数据创建数据分类模块;数据分类器用于接收待过滤的目标社交网络服务数据,即句子,并将其划分为三类:第一类是垃圾数据,第二类是广告数据,第三类为有价值的数据。其中,第一类垃圾数据和第二类广告数据会被再次输入到数据分类生成器中,并用于生成分类模块,通过词法分析等,将第二类和第三类中包含的句子输入到模式分析生成器以生成相应的模式分析模块;数据分析器接收由数据分类器确定的包含在第二组和第三组单词中的句子数据,并生成各种信息。
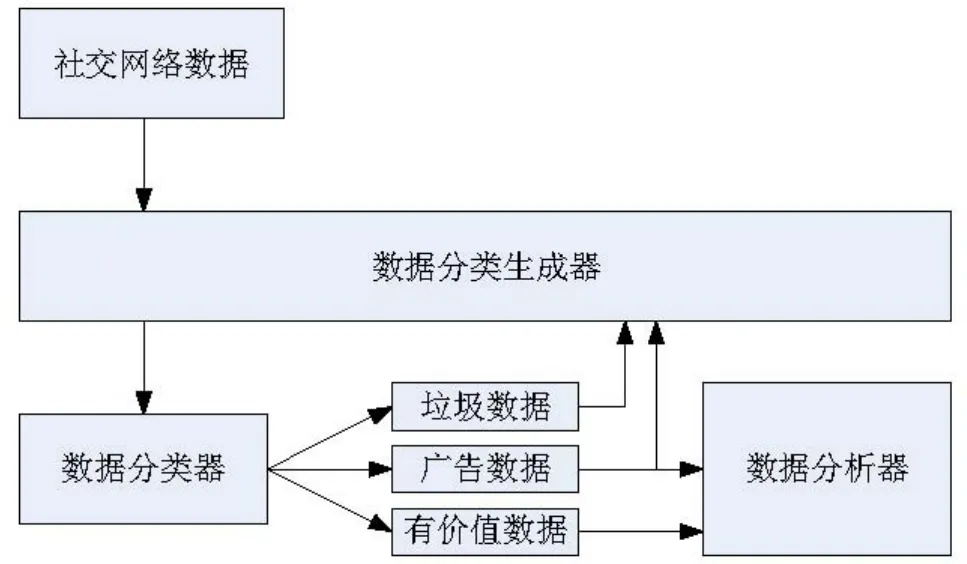
图1 垃圾数据过滤算法的主体结构
在本文算法中,数据分类生成器可以根据学习到的数据信息将数据初始划分为第一组至第三组。为了便于后续的数据过滤,本文采用当前Hadoop架构中的Mahout框架对数据进行分类,算法的详细步骤如下:
输入:原始数据(Source Data,SD),基于关键词的初始学习数据(Initial Learning Data,ILD),基于关键词学习到的数据(Learned Data,LD);
输出:第一类数据即垃圾数据(First Type,FT),第二类数据即广告数据(Second Type,ST),第三类数据即有价值的数据(Third Type,TT);
初始状态:SD被划分为若干个句子,即SD={SD1,SD2,…,SDi,…,SDk},SD=ILD+LD;FT,ST,TT三类数据的参考值分别为VFT,VST,VTT;
步骤1:针对SD中的每一个句子SDi,采用Mahout框架对原始数据中的语素进行分析,从而得出具有特定语素的单词;
步骤2:数据分类生成器根据语素分析结果为每个生成的语素词分配相应的权重,权重的数值将取决于每个单词的出现频率,并得出对应句子的评估值JSDi;
步骤3:若JSDi=VFT,则对应的句子SDi将被划分为第一类数据,将其标记为已经学习后的数据LD,并发送至数据分类生成器;否则,执行步骤4;
步骤4:若JSDi=VST,则对应的句子SDi将被划分为第二类数据,将其标记为已经学习后的数据LD,并将其分别发送至数据分类生成器和数据分析器;否则,执行步骤5;
步骤5:若JSDi=VTT,则对应的句子SDi将被划分为第三类数据,并将其发送至数据分析器;
步骤6:若LD=SD,则算法结束;否则,返回至步骤2。
来自第一组和第二组的数据被发送到数据分类生成器并用作训练集对后续数据进行训练和分类;来自第二组和第三组的数据则被发送到数据分析器以提取信息。通过这种递归学习过程,可以有效提升数据过滤的精度。
2 仿真实验分析
为了验证本文算法的合理有效性,本节将以社交网络服务数据作为样本进行一系列性能测试和分析,表1给出了本节的仿真实验环境。

表1 仿真实验环境
本节选取了国内某知名社交网络软件数据中的4个热门关键词,分别为“难”、“疫情”、“直播”、“摆摊”,并用与每个关键词相关的1 000条语句作为实验数据,整个实验共持续4天。在数据处理速度比较实验中,上述四个关键词分别使用了10 000个句子。因此,整个实验数据约为40 000个句子。
第一个仿真实验用于检测数据过滤的精度。本节在服务器上用与每个关键词相关的1 000条语句作为测试数据,然后使用本文算法将这些数据分别划分为垃圾数据、广告数据和有价值的数据。分类处理完成后,分析结果可以下载到PC机上加以保存。基于关键词可以对数据过滤精度加以分析,性能测试结果如图2所示。

图2 每个关键词的数据过滤结果

表2 过滤精度数值
以关键词“摆摊”为例,在1 000个句子中,有213个数据被本文算法过滤出来,在给出的正确答案数据中,156个句子被归类为广告数据或垃圾数据。因此,过滤精度为73.24%,而经典传统的基于自然语言的过滤算法得到的平均过滤精度仅为65.00%[16]。
3 结束语
社交网络服务数据中除了对人们和社会有价值的数据外,还存在着大量垃圾数据和广告数据,为了尽可能地将有价值的数据提取出来,本文提出了一种基于Mahout框架的社交网络服务数据过滤算法。该算法通过对原始数据中的语素加以分析,得出对应句子的权值,依据这一权值与不同类别数据的参考值比较结果,将原始的社交网络服务数据划分为垃圾数据、广告数据和有价值的数据。为了验证本文算法的有效性,本文还选取了国内某知名社交网络软件数据中的4个热门关键词加以测试,实验结果表明本文算法具有比传统过滤算法更理想的过滤精度。
