优化非线性激活函数-全局卷积神经网络的物体识别算法
2021-03-13安凤平
安 凤 平
(淮阴师范学院 物理与电子电气工程学院,江苏 淮安 223300)
(北京理工大学 信息与电子学院,北京 100081)
1 引 言
物流仓储物体实时检测属于物体检测的范畴,它的主要任务是提取得到物流仓储物体的位置信息和类别信息.因此,能否快速、准确地识别和抓取物流仓储的物体是当前面临的巨大挑战[1].传统的物体识别算法主要有:Csurka 等人[2]提出了一种贝叶斯和支持向量机的融合方法,并利用该方法对物体进行分类,但是该物体分类效果较低.Yang 等人[3]提出了基于稀疏编码进行物体分类方法,但是该方法需要建立足够可信的稀疏集.Ning等人[4]提出了一种基于结构化支持向量机的方法,它在对象跟踪基准测试中表现较好的分类性能.但是,复杂的优化方法限制了它们在实际应用中的部署.Alhalah等人[5]提出了一种层次化模型进行物体分类识别,在实际应用中取得了较好的效果.但是该方法的自适应性能较弱.Gualdi 等人[6]提出了一种新的多级粒子窗口搜索方法.虽然该方法取得了较好的应用效果,但存在较难收敛的问题.传统的物体识别算法在某些应用场景下,尽管取得了一定的效果,但是存在识别精度低、自适应能力弱等问题.这一缺点被Hinton在2006年提出的深度学习(Deep Learning)技术所打破[7].深度学习技术[8]由于具有高度的特征提取能力,它已经被应用到计算机视觉[9]、图像分类[10]等领域.鉴于此,很多学者将其引入到物体识别领域中.在物体分类方面主要有:Alex在2012年的ILSVRC会议上提出了AlexNet模型,它较传统的卷积神经网络模型(Convolutional Neural Networks,CNN)[11]进行了优化,并应用到物体分类当中,它将分类错误率从25.8%下降到16.4%,该方法成为当年会议中图像分类的冠军.Girshick 提出了Fast Region-based Convolutional Network[12]进行物体分类,它与之前的工作相比,它采用了多项新思路来提高训练和测试速度,提高了分类精度.Gao等人[13]提出了一种物体分类方法,通过创建LIDAR数据上采样的点转换为像素级深度信息,进而获得车辆特征信息,并进行分类.在物体识别方面主要有:Redmon 等人[14]提出了一种新的物体识别方法 YOLO.该方法通过回归方法来实现物体位置、尺寸和类别等信息的识别,它可以有效提升检测速度与精度.但是,该方法存在缺乏候选区域生成机制、无法精确定位等问题.Liu 等人[15]提出了将 YOLO 的回归思想和快速卷积神经网络的锚点机制相融合,该方法在VOC2007测试集上的识别平均准确率为74.3%,也基本满足实时处理要求.综上可知,深度学习理论在物体识别中得到了一定程度的应用.但是待识别物体特性千差万别,如何依据这些物体特性构建性能更优异的卷积神经网络,获得更好的物体识别效果,依然是一个比较棘手的问题.而且现有的卷积神经网络存在过拟合、非线性建模能力、大量重复的池化操作丢失信息等问题.鉴于此,本文提出了一种可学习的指数非线性单元.通过在ELU(Exponential Linear Units)中引入两个学习的参数,它能够表示分段线性函数和指数非线性函数,因而它具备更强的非线性建模能力.同时,为了改善池化操作丢失信息的问题.本文提出了一种深度全局卷积神经网络模型,该模型充分利用了网络中不同层特征图的局部和全局信息.它可以减少丢失特征信息的问题.基于上述思想,本文提出了一种优化非线性激活函数-全局卷积神经网络的物体识别算法.
本文第2节将主要阐述本文提出的优化非线性激活函数模型;第3节阐述提出的全局卷积神经网络模型;第4节介绍提出的优化非线性激活函数-全局卷积神经网络的物体识别算法;第5节对本文提出的算法进行实例分析,并与主流算法进行对比.最后对全文进行总结和讨论.
2 基于优化表达的非线性激活函数
卷积神经网络在物体识别中主要有两个方面考虑:1) 找到更优化的非线性建模模型;2) 找到可以避免模型训练过程的过拟合问题.从卷积神经网络的发展来看,增加网络非线性建模能力的同时,配合降低过拟合风险的方法.因此,本节通过解决非线性单元表达问题,从而提高网络的非线性建模能力,同时配合正则机制降低过拟合风险.最终提升模型泛化能力和特征信息提取的目的.鉴于此,本文提出了一种参数形式统一且可学习的MPELU,并引入两个学习的参数.它具有线性和非线性变换方法,使得该参数形式既可以表示分段线性函数,也可以表示指数非线性函数.因而它具有更强的非线性建模能力.
2.1 MPELU设计
本节定义的MPELU前向传递公式为:
(1)
式(1)中,α和β是该模型当中可以通过学习的参量,β>0,y代表该模型的参数输入,i代表参数输入的元素索引,c代表通道索引.故c∈{1,…,M}.故yi示输入中第c个通道中的第i个元素.针对过拟合问题,本文参考PReLU(Parametric Rectified Linear Unit)[16]的方法,对这两个参数分别设置“通道共享”和“通道独立”.第1个模式下,输入共用α和β,而且M=1;在第2个模式下,一样通道输入共用α和β.M为通道总数目个数.
MPELU利用改变βc线使得该形式在分段线性性和指数非线性函数相互切换.若βc较小,比如小于1,MPELU在yi<0内相当于线性函数.此时,它相当于PReLU.若βc较大,比如大于1,MPELU在yi<0内相当于非线性函数.MPELU函数类型可以通过αc调整得到,若αc=βc=1,它相当于ELU.此情况下若继续减小βc,它会变成LReLU(Leaky Rectified Linear Unit).若αc=0,那么它相当于ReLU.
通过分析可知,MPELU已经包括了ReLU、LReLU、PReLU和ELU等激活函数.同时,MPELU形式上具有很强的灵活性,它可以涵盖上述激活的有点,并且避免不足.
同时,MPELU处处可导,故αc和βc利用梯度更新数值,具体为:
top′=f(yi)+αc
(2)
(3)
(4)
(5)
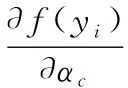
(6)
式中,Σ的求和范围为αc和βc对应的位置索引i.αc和βc对物体分类效果影响较大.本文通过大量实例总结可知,若αc=0.13或1.2,βc=1,网络最终的识别误差最小.
2.2 过拟合处理
由于MPELU加入了α和β,它会导致模型的过拟合问题.所以,本文对MPELU加入了α和β分别给予“通道共享”和“通道独立”.在第一种模式中,均共享参数数,故网络增加的参数量为网络深度的1.5倍,可以忽略对模型训练的影响.当为第二种模式时,各个通道内部才共享参数,不同通道不共享参数,新增参量也仅为网络的1.5倍,对模型训练不构成影响.因而,本文提出的激活函数不会增加模型训练过程中的过拟合问题.相关参数优化通过L2正则实现.大量实验证明,对模型参数使用L2正则可以提升模型泛化能力.
2.3 计算效率估计
本文所提出的参数学习方法会增加一定的计算时间.鉴于此,本文对提出的激活函数作优化操作,从而保证本文所提出的算法的计算效率较其他激活函数具有一定的优势.首先,本文对本文提出的激活函数的后向传递优化.其次,本文优化python框架下的程序实现,在不同循环下分别计算获得,不增加计算时间.为了对比相关激活函数的计算效率,本文以NVIDIA TitanX GPU为平台,对其在python框架下网络结构为32层网络进行对比.
本部分对32层ReLU、PReLU、ELU和MPELU分别训练700k次迭代,再计算单次迭代时间的平均值.具体结果如表1所示.通过表1可知,虽然MPELU引入了额外的参数,但是单次迭代所需要的平均时间与其他方法相近,甚至还有所减少.

表1 非线性激活函数计算效率对比表Table 1 Comparison table of calculation efficiency of nonlinear activation function
3 全局卷积神经网络模型
本节提出的全局卷积神经网络模型设计了局部特征信息和全局特征信息相融合的框架,为了准确突出细节信息,嵌入6个全局卷积模块(Global Convolution Module,GCM)和24个边界细化模块(Boundary Refinement Module,BRM)到网络架构中.
3.1 网络结构
对于给定的图像F,先将图像F大小调整512×512,它是网络的输入模块.再通过6个卷积块(定义为 Conv-1 到 Conv-6)生成了相应特征图,大小均为3×3.受全局卷积网络[17]的启发,本文提出了通过全局卷积模块优化卷积块和特征联系.此外,本文提出的模型架构容桂加入边界细化模块来获得更为丰富的边缘信息.
全局特征图TG通过特征图{Ti,i=1,…,6}获得特征信息,计算公式为:
TG=Conv(T6)
(7)
在 Conv-6块中加入具有128特征的3个卷积层,使得T6分辨率为1×1.
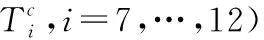
(8)
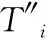
(9)
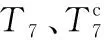
(10)
3.2 全局卷积模块
全局卷积模块可以提升模型的物体识别,全局卷积模块的内核较大,它有利于提取得到更多的空间特征信息,进而提升物体位置的定位精度.本文所提出的全局卷积模块由左右两侧卷积操作构成.左侧卷积操作由7×1卷积块和一个1×7 卷积块组成.右侧卷积操作由1×7卷积块和7×1卷积块组成.此外,该全局卷积模块模型的计算效率较高,它可以使得模型达到更高的计算速度.
3.3 边界细化模块
为了进一步提高模型定位精度,在该模型中再引入边界细化模块,该模块可以提升物体的边缘特征信息,尽可能保留更多的边缘特征.本文所引入的边界细化模块是通过经典的卷积神经网络的残差模型得到的[18].该模块的输入输出尺寸相同.
3.4 物体识别
令SM为显著图,GI为基准显著图,其计算公式如下:
(11)
式中,(wL,vL)和(wG,vG)分别为局部和全局特征图的线性运算符.本文模型损失函数定义为交叉熵损失(用LossCE表示)和边界损失(用LossB表示)之和,其计算公式如下:
(12)
式中αr和βr为LossCE和LossB的加权常数.其中,LossCE计算公式如下:
(13)
LossB为像素p在BT和BM的边界损失,计算公式如下:
(14)
4 基于优化非线性激活函数-全局卷积神经网络的物体识别算法
基于上述内容,本节构建优化非线性激活函数-全局卷积神经网络的物体识别算法.首先通过解决非线性单元表达问题,从而提高网络的非线性建模能力,同时配合正则机制降低过拟合风险.提出了一种参数形式统一且可学习的指数非线性单元MPELU,从而能够表示分段线性函数和指数非线性函数,它具备更强的非线性建模能力.而后,为了改善大量重复的池化操作丢失信息的问题,本文提出了一种基于深度全卷积神经网络模型来进行物体图像的识别,减少大量池化操作丢失特征信息的问题.所提出物体识别算法的基本流程图如图1所示,它的基本步骤如下:
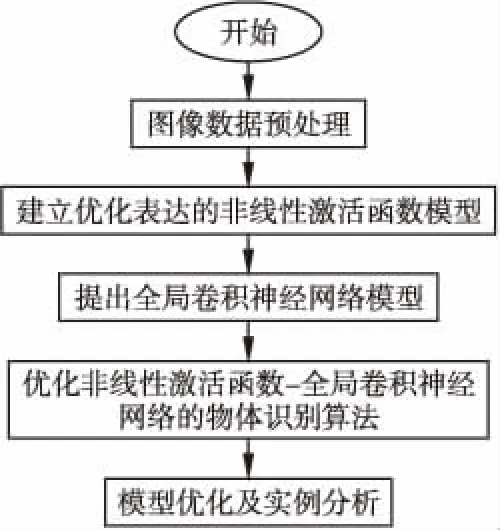
图1 优化非线性激活函数-全局卷积神经网络的物体识别算法基本流程图Fig.1 Basic flow chart of object recognition algorithmfor optimizing nonlinear activation function-globalconvolutional neural network
1)首先对需要识别的物体图像进行去噪或增强等处理.
2)利用本文提出的优化表达的非线性激活函数模型对卷积神经网络进行激活并初始化,由于该函数具有很强的非线性建模能力.与其他方法相比,本文方法有较强的非线性建模能力和良好的初始化能力,并提升卷积神经网络模型的自适应能力,从而能够获得更多的待识别物体的特征信息.
3)为了改善大量重复的池化操作丢失信息的问题.本文提出了一种基于优化卷积神经网络模型进行物体识别,该模型充分利用了网络中不同层特征图的局部和全局信息.减少大量池化操作丢失特征信息的问题.实现更准确物体识别的目的.
4)将步骤3)的方法引入到步骤2)当中,通过步骤1)-步骤 3)建立优化非线性激活函数-全局卷积神经网络的物体识别算法,利用该算法对相关实例进行分析,并与其他算法进行对比和分析.
5 实例分析
5.1 CIFAR100数据集实验
为了验证本文所提算法对物体的识别效果,本节将通过对CIFAR100数据集[19,38]进行分类识别测试,并与主流物体识别算法进行对比分析.
5.1.1 数据集及识别过程说明
CIFAR100数据集共有100个类别,每个类别包含500张训练图片和100张测试图片,总共包含60000张图像.部分示
例如图2所示.本文利用标准数据拓展策略对CIFAR100数据集进行处理[20],具体为:首先对数据集所有图片边界填充3个 0像素,原图像调整为38×38像素;再随机裁剪,得到尺寸为32×32图像.

图2 CIFAR100数据集部分示例图片Fig.2 Some example pictures of CIFAR100 data set
本实验中所采用的深度学习模型基于Pytorch实现,在Titan-X GPU上进行训练.深度学习模型中激活函数为本文第2部分所提出的激活函数,深度学习模型的网络架构为第3部分提出的架构.初始学习率是0.1,模型训练到60和100个Epoch时学习率降为其1/10,训练共持续180个Epoch.本文所提出的模型基于随机梯度下降法进行训练,每个批次样本的数量被设置为128.
5.1.2 物体识别结果与分析
利用本文提出物体识别算法与其他主流物体识别算法分别对CIFAR100数据集进行物体识别,识别结果如表2所示.

表2 CIFAR100数据集物体识别结果对比表Table 2 Comparison table of CIFAR100 data set object recognition results
通过表2可知,本文提出的基于优化非线性激活函数-全局卷积神经网络的物体识别算法的识别精度比传统物体识别算法、其它深度学习算法的识别精度有所提升,具有一定的优势.具体来说,文献[21,22]所提出的传统机器学习方法对物体识别错误率分别为35.68%和32.39%.传统机器学习方法是上述所列类别方法当中精度最低的一类.这是因为传统机器学习方法对CIFAR100数据集的模型训练效果较差.文献[23-25]所提出的深度学习方法的物体识别错误率分别25.28%、26.52%和24.46%.它们的识别精度基本处于一个量级水平,但是文献[23-25]所提出的方法的识别精度较传统机器学习方法提升7%左右.这主要得益于深度学习模型能够对大规模数据进行建模,将得到一个更为合理、可靠的物体识别模型.它表明深度学习方法适用于物体的识别.文献[26-28]所提出的深度学习的物体识别错误率分别为21.95%、21.27%和21.05%.它们是物体识别精度高于文献[23-25]所提出的深度学习方法.这是因为文献[23-25]所提出的深度学习模型结构比较简单,还不能完全提取获得所有物体的特征信息.它也进一步证明了基于深度学习的物体识别模型能够获得比传统机器学习方法更好的识别效果.本文所提方法错误率最低,仅为19.32%.这主要是因为本文所提方法较文献[23-28]所提方法,不仅优化了深度学习模型的网络结构,而且还改进了深度学习模型中的激活函数部分.
5.2 ImageNet数据集实验
为了进一步验证本文所提算法对物体的识别效果,本节将通过对ImageNet数据集[29]进行分类识别测试,并与主流物体识别算法进行对比分析.
5.2.1 数据集及识别过程说明
ImageNet数据集是用于ImageNet Large Scale Visual Recognition Challenge(ILSVRC)的子集.部分示例如图3所示.
图3 ImageNet数据集部分示例图片Fig.3 Some sample pictures of ImageNet dataset
本实验中所采用的深度学习模型基于Pytorch实现,在Titan-X GPU上进行训练.深度学习模型中激活函数为本文第2部分所提出的激活函数,深度学习模型的网络架构为第3部分提出的架构.初始学习率设为0.001,学习率共下降3次.训练图片先被调整到256×256,并裁剪至224×224,再输入到本文提出的深度学习网络,在模型训练过程中不使用其它的数据增强技术.所有的测试结果均为平均准确率.
5.2.2 物体识别结果与分析
利用本文提出的算法与其他主流算法分别对该数据集进行识别,结果如表3所示.
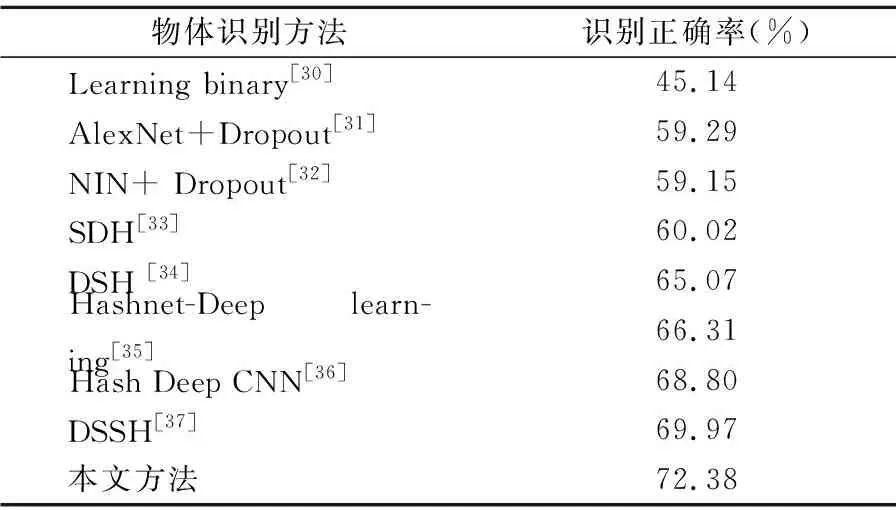
表3 ImageNet数据集物体识别结果对比表Table 3 Comparison table of object recognition results in ImageNet dataset
通过表3可知,文献[31-33]所提出的深度学习方法的物体识别正确率分别59.29%、59.15%和60.02%.它们的识别精度基本处于一个量级水平,较传统的机器学习方法已有较大幅度提升,提升精度高达14%.这是因为传统机器学习方法对包括大量样本的ImageNet数据集的模型训练效果较差,它直接导致实际物体识别精度低.同时,文献[31-33]所提出的深度学习方法获得的较高识别精度得益于深度学习模型能够对大规模数据训练得到一个更为合理、可靠的物体识别模型.文献[34-37]所提出的深度学习的物体识别正确率分别为65.07%、66.31%、68.80%和69.97%.它们是物体识别精度高于文献[31-33]所提出的深度学习方法,提升精度最少的也达到了5%.这是因为文献[31-33]所提出的深度学习模型结构比较简单,不能提取得到ImageNet数据集各类复杂图片所蕴含的特征信息.同时,通过对文献[31-33]的测试结果进行分析,可知该结果也进一步证明了基于深度学习的物体识别算法能够得到比传统机器学习方法更好的识别精度.本文所提方法得到物体识别正确率高达72.38%,它是所有方法当中识别精度最高的.它充分证明了本文提出的方法能够更好地提取得到ImageNet数据集各类复杂图片所蕴含的特征信息,进而大幅度提升物体识别准确率.
总之,传统分类算法在物体识别任务中存在识别精度不高和稳定性差的缺点,它说明传统物体识别方法对于物体识别效果难以进一步提升.深度学习分类算法在上述CIFAR100数据集和ImageNet数据集中的识别精度明显地优于传统机器学习算法,它从侧面证明了深度学习模型所具有的优势.此外,深度学习模型的物体识别算法具有很好的稳定性和鲁棒性,其中,本文提出的基于优化非线性激活函数-全局卷积神经网络的物体识别算法,相比其他提出的深度学习识别算法如Hashnet-Deep learning、Sparse CNN等,它可以得到最好的识别精度.这是因为本文提出的深度学习模型不但解决了模型网络架构大量池化操作丢失信息问题,而且还解决了模型的激活函数问题.
6 结 论
为了更好地对物体进行识别,本文根据待识别物体特性构建性能更优异的卷积神经网络,并提出了一种参数形式统一且可学习的MPELU,它可以进行分段线性函数和指数非线性函数的表述,提升卷积神经网络的非线性建模能力.同时,为了减少深度学习模型中大量重复的池化操作丢失各类信息等问题,本文提出了一种全新的全局卷积神经网络模型,该模型充分利用了网络中不同层特征图的局部和全局信息.它可以减少大量池化操作丢失特征信息的问题.并提出了优化非线性激活函数-全局卷积神经网络的物体识别算法.
CIFAR100数据集和ImageNet数据集的实验结果表明,本文所提物体识别方法识别精度最高,高达80.68%和72.38%.这是因为本文较好地解决了深度学习模型过拟合、非线性建模能力若、大量重复的池化操作丢失信息等问题.同时,本文所提物体识别方法能够较好地对物体的特征信息进行提取,它有利于提升CIFAR100数据集和ImageNet数据集的实验效果.所以,本文所提物体识别方法取得了最好的识别精度.但是,本文所提方法在ImageNet数据集上的识别精度低于CIFAR100数据集识别精度,这主要是因为ImageNet数据集的物体类别远大于CIFAR100数据集,其物体类别相似度远高于CIFAR100数据集的物体类别相似,这些信息对后续的深度学习建模训练产生了较大影响.因而,后续的相关工作可以专门针对该类问题进行深入细致研究.
