融合多重注意力机制的卷积神经网络文本分类设计与实现
2021-03-13霍其润李天昊
闫 跃,霍其润,李天昊,毛 煜
1(首都师范大学 信息工程学院,北京 100048)
2(北京理工大学 计算机学院,北京 100081)
1 引 言
近年来,文本分类任务面临着文本信息数据量的增加和文本内容复杂度提升等问题,人工进行文本信息分类的效率较低,同时很容易受到主观因素的影响,使得分类的准确程度不高.基于深度学习的文本分类方法采用深度神经网络,摒弃了人工特征提取步骤,可以从大量数据中自动提取深层文本特征,进而解决了这一问题.目前主要将文本分类任务分为文本向量化和分类模型构建两个方面,首先将文本信息转化为向量形式,再通过深度神经网络对提取到的词向量进行特征抽取,在文本分类任务中取得了较好的表现.
在文本表示方面,词向量[1]概念的首次提出为探究文本语义之间的关系开辟了一条新的思路,其核心思想是通过神经网络降维将原始的文本表示为一定长度的稠密向量,从而提高文本特征的表达能力.2013年,Mikolov[2]提出了word2vec模型,该模型基于神经网络,通过将文本转化为向量形式对特征词语的语义相似度进行距离度量.ColloBERT[3]提出了将词向量与卷积神经网络相结合,将文本分类任务分为文本表示和分类器两个模块,提升了分类效果.
在之后的分类器构建中,传统的浅层机器学习算法有着特征工程构建繁琐、难以表示复杂函数等问题,CNN和RNN等深度学习框架[4]的应用较好的解决了这些问题.然而单一的深度神经网络模型提取特征能力有限,难以关注到词语在上下文的含义,注意力机制通过分配影响文本分类效果的关键特征更高的权值,从而提高特征提取效果,将深度神经网络模型和注意力机制相结合也成为了研究热点.Mnih[5]等将注意力机制结合RNN模型来进行图像分类,提高了分类性能.Bahdanau[6]等首次将注意力机制应用在NLP领域,提高了机器翻译效果.紧接着许多学者将注意力机制与RNN和LSTM等序列化建模任务相结合,在NLP领域有着出色的效果.Vaswani[7]等在机器翻译上抛弃了RNN和CNN等网络结构,完全采用了自注意力机制,并取得了较好的效果.在文本分类任务中,现有的研究多采用添加外部标签的注意力机制,通过分析不同语料特点添加影响文本分类效果的外部标签,进而提升文本分类效果.目前采用自注意力机制与CNN模型相结合的研究较少,针对上述问题,本文提出一种融合多重注意力机制的卷积神经网络文本分类模型,在CNN模型的基础上,深入探究自注意力机制在CNN模型不同层之间嵌入对文本分类效果的影响,实验验证该分类模型的准确性和有效性.
2 相关工作
在进行文本分类前,首先要对文本进行特征表示[8],当前的研究大多使用多种算法的组合来更好地表征文本以进行文本分类.宁亚辉[9]以领域高频词作为特征词,通过知网进一步扩展后实现文本分类,提高了分类器的性能.王盛[10]在特征扩展的过程中考虑了词语的上下文关系,解决了文本语义稀疏对文本分类的影响.朱磊[11]通过将语义信息和概率模型相结合,构建了VSM-TFIDF文本分类模型,提升了文本分类效果.Hinton考虑到文本的语序和上下词之间的联系,提出了词向量的概念.在词向量概念的基础上,Skip-gram和CBOW模型采用深度网络结构提升了词向量训练的效率和分类模型精度.
分类器的构建[12]影响着文本分类的效果.深度学习算法通过构建深度神经网络,摒弃人工构建复杂而低效的特征工程等步骤,从而有效提高了模型的稳定性和鲁棒性.2008年ColloBERT等[13]第一次在自然语言处理任务中使用卷积神经网络,在命名实体识别、语义标注等多项任务中都有着显著的提升.循环神经网络(recurrent neural networks,RNN)[14]模型的提出进一步提升了NLP任务的精度,RNN模型对具有序列特性的文本数据效果显著,能够挖掘出数据中的时序信息和语义信息,提升了文本分类的性能.Yoon Kim[15]在CNN模型的基础上,提出了更适用于NLP任务的TextCNN模型,在文本分类方面效果显著.
在模型的训练方面,深度神经网络模型结构单一,与其他算法相结合能够提升性能.注意力机制可以关注到影响模型精度的重要特征,近年来NLP领域聚焦于注意力机制嵌入深度神经网络模型的构建方法.Yang Z[16]等将注意力机制和RNN相结合,利用RNN捕捉文本的时序特征和语义特征,注意力机制通过赋予关键特征更高的注意力权值的方式进行特征筛选,提高了文本分类模型的精度.邵清等[17]使用注意力模型处理词向量结合卷积神经网络实现文本分类,获得了效果的提升.石磊[18]等将注意力机制和Tree-LSTM相结合,和多种情感分类模型进行对比,有效地提高了模型精度.朱烨[19]利用对象的实例信息,提出最近邻注意力和卷积神经网络的文本分类模型,通过引入基于加权卡方的最近邻改进算法训练文本,构建文本对象的注意力.
现有的注意力机制和深度神经网络结合的模型多采用添加外部标签的方式改进文本分类模型,未能深入探究模型层面上嵌入自注意力机制对文本分类效果的影响,因此,本文构建了融合多重注意力机制的卷积神经网络文本分类模型,深入分析自注意力机制嵌入卷积神经网络不同层之间对文本分类效果的影响.
3 融合多重注意力机制的卷积神经网络文本分类
3.1 ATTCNN模型结构设计
本文提出的融合多重注意力机制的卷积神经网络文本分类算法(ATTCNN)基于卷积神经网络架构,该分类模型如图1所示.首先在输入层将文本转化为词向量的形式,得到的词向量通过第一注意力层,赋予更多的关注在影响词向量质量的重要特征上,通过不断迭代为这些特征分配注意力权值,其次将重新分配权值的特征向量输入卷积层中用于抽取文本特征信息,提取的特征嵌入第二注意力机制,对影响文本分类效果的关键特征进行二次加权,然后通过池化层对卷积层所获得的特征向量抽取最为显著的上下文特征作为高维特征的一部分,最后将通过池化层所获得的显著高维上下文特征输出经过全连接后计算得到文本分类结果.

图1 融合多重注意力机制的卷积神经网络文本分类模型图Fig.1 Flow chart of text classification based on convolutional neural network with multiple attention mechanisms
3.2 自注意力机制
在词向量处理方面,传统的词向量处理方法通过计算词频实现[20],忽略了词之间的语义关系,为解决这一问题,本文采用注意力机制对词向量进行处理.注意力机制模型和人脑注意力机制类似,人脑在进行文本浏览中,会自动实现注意力分配,更加关注关键信息,从而快速得到需要的内容.注意力机制在神经网络中的运用也是提取出影响模型精度的重要特征,并赋予更高的权值.自注意力机制作为注意力机制的变体,实际上是对注意力机制的多次使用.其对句子内部词之间的语义关系进行深度解析,可以更好地利用短语和词组的语义特征,所以本文采用自注意力机制,对词向量进行处理,从而提升卷积神经网络输入层的词向量质量.
在卷积神经网络模型方面,和自注意力机制相结合能更好的筛选出影响文本分类效果的重要特征,通过不断地迭代提高这些特征的注意力权值,从而过滤掉对文本分类效果影响较小的无用特征.所以本文选用自注意力机制,嵌入卷积神经网络文本分类模型之中,从而提升卷积神经网络文本分类效果.
注意力机制的权重aij由softmax函数进行归一化得到,计算式见公式(1):
(1)

(2)
其中v表示注意力机制的偏移向量,将得到的注意力概率值与原矩阵S中对应的向量相乘,为影响文本分类效果的关键特征赋予更高的权重,得到新的文本特征x′,自注意力机制的权重矩阵的计算见公式(3):
(3)
本文将自注意力机制分别嵌入卷积神经网络的卷积层前后,分别对输入层和卷积层输出的特征进行注意力加权,聚焦于影响文本分类效果的关键特征上,实现不同粒度上的特征优化.
3.3 词向量层
词向量处理:将预处理后的文本数据转化成词向量的形式.本文采用word2vec中的CBOW模型,将生成好的词向量作为CNN模型的输入,用矩阵S∈Rn×d表示,其中d是词向量维度,n是句子中包含的词向量个数,矩阵计算式见公式(4):
S=[x1,x2,…xi,…xn]T
(4)
S作为卷积神经网络的输入,嵌入第一层注意力机制后传入卷积层.
嵌入第一层注意力机制:对卷积层输入的向量表示S进行注意力加权得到卷积层的输入S′,注意力加权定义见公式(5):
(5)
第一注意力层针对词向量进行注意力动态加权,能更好地捕捉句子内部词之间的语义关系,在原有词向量的基础上进行权值的再分配,从而提高词向量质量,输入卷积神经网络.
3.4 CNN模型训练层
卷积层:将通过第一层注意力机制加权的词向量输入到卷积神经网络的卷积层并采用多尺寸卷积核进行卷积.将文本特征x′输入到卷积层,与滤波器点乘后加上偏置项,通过激活函数Relu输出,卷积运算见公式(6):
(6)
其中Wi为卷积核的权重,i为滑动窗口大小,b为偏置项,j为卷积核高度,本文使用的卷积核高度分别为3、4、5,滑动步长为1,卷积核数目为128.卷积层的输出H见公式(7):
H=[h1,h2,…hi,…hn-j+1]
(7)
嵌入第二层注意力机制:对卷积层输入的向量表示H进行注意力加权得到池化层的输入H′,注意力加权定义见公式(8):
(8)
第二注意力层位于卷积神经网络中的卷积层和池化层之间,重点获取文本经过处理后的高维特征,对上一步经过不同卷积核过滤的特征进行权值的再分配,在卷积神经网络层面上对分类效果进行提升.
池化层:在池化层进行降维操作,从高维特征向量中提取较低维度的特征向量,平均池化从宏观角度提取特征,最大池化则更倾向于提取有益分类的特征,本文选择平均池化和最大池化相结合的方法,可以有效地减少特征图的尺寸,间接减少全连接层的参数数量,从而增加运算速度,避免过拟合现象的发生,平均池化定义见公式(9),最大池化定义见公式(10):
Pavg=Avg_pooling(H′+b1)
(9)
Pmax=Max_pooling(H′+b2)
(10)
如图2所示,将平均池化和最大池化结合,通过激活函数得到类别信息筛选结果P定义见公式(11),其中σ为激活函数,Pavg是平均池化结果,Pmax是最大池化结果,W1和W2为权重矩阵.

图2 池化层结构图Fig.2 Comparison with some classical models
P=σ(W1(Pavg)+W2(Pmax))
(11)
采用标准卷积操作对类别信息筛选结果进行特征降维,得到池化层输出结果P′见公式(12):
P′=σ(f(5×5)(P)+b)
(12)
其中,σ为激活函数,b是偏置项.
全连接层:将池化层输出结果通过全连接层融合到一起后经过softmax函数映射到每个类别的概率,从而输出文本分类结果,计算式见公式(13):
label[]=softmax(Fc(P′))
(13)
其中,label[]代表文档所属类别的标签,Fc表示全连接操作,softmax代表分类函数.
4 实验与分析
4.1 数据集
为了测试本文模型的性能,本文在中文数据集中选用了搜狗新闻文本分类数据集(SogouCS)和新浪新闻文本分类数据集(THUCNews),在英文数据集中选用了AG_news数据集进行实验.
SogouCS:该数据集来自搜狗新闻2012年6-7月期间收集整理的2万多篇新闻数据,划分出了教育、旅游、新闻、健康、等18个类别.
THUCNews:该数据集来自新浪新闻2005-2011年间的 74万篇新闻文稿,经整理后汇总为财经、房产、时政、游戏等14个类别.
AG_news:由ComeToMyHead从2000多不同的新闻来源搜集的超过100万且分为4个类别的新闻文稿.
4.2 实验评估指标
文本分类模型的预测能力和分类结果需要通过几个指标验证,包括:准确率(Precision)、召回率(Recall)和F1值,其计算式见公式(14)-公式(16):
(14)
(15)
(16)
4.3 基准模型对比
基于上述通用数据集,我们对本文提出的ATTCNN模型进行了实验测试,选取当前主流的深度神经网络文本分类模型作为基准模型进行了结果的定量分析与比较.
为了验证本文分类模型的正确性和有效性,选用了以下几种基准文本分类模型:卷积神经网络(CNN)[21]、长短时记忆网络(LSTM)[22]、双向长短时记忆网络(BiLSTM)[23],BERT[24].表1中列出了几种模型算法在不同数据集上的实验结果,图3直观地对比了几种模型算法在不同数据集上的F1值.

表1 基准模型对比结果(%)Table 1 Comparison with some classical models(%)
从表1和图3中可以看出:本文提出的ATTCNN模型的准确率、召回率以及F1值表现最好,在3种中英文数据集的F1值分别达到了97.6%、91.4%和91.0%,相比表现最好的BERT模型分别提高了1.4%、2.3%、1.1%.本文提出的ATTCNN模型将注意力机制嵌入到卷积神经网络中,采用动态的注意力概率分配策略,聚焦于影响文本分类效果的关键特征上,相比基准的深度神经网络和由注意力机制构成的BERT模型在文本分类效果上有所提升,实验证明了该模型的有效性.

图3 基准模型F1值对比结果(%)Fig.3 Comparison result of benchmark model F1 value(%)
4.4 注意力机制重要性分析
为了验证本文改进的注意力机制在卷积神经网络卷积层前后对文本分类准确率的不同影响,本文通过消融实验,对比了以下几种结构在不同数据集上的性能.
ATTCNN(-attention):在卷积层前后分别减去注意力机制的文本分类模型.
ATTCNN(-attention1):在卷积层前减去注意力机制的文本分类模型,聚焦于卷积后提取体征中影响文本分类效果的关键特征,并进行权值分配.
ATTCNN(-attention2):在卷积层后减去注意力机制,更关注注意力机制对词向量生成质量的影响.
ATTCNN:本文提出的融合多重注意力机制的卷积神经网络文本分类模型,在卷积层前后嵌入注意力机制,实现不同粒度上的特征提取优化.
从表2和图4中可以看出:嵌入注意力机制的ATTCNN模型、ATTCNN(-attention1)模型和ATTCNN(-attention2)模型相比未嵌入注意力机制的模型ATTCNN(-attention)在准确率,召回率以及F1值上均有着较大的提升,实验证明注意力机制的嵌入对文本分类效果有着显著的影响.同时本文提出的ATTCNN模型相比ATTCNN(-attention1)模型和ATTCNN(-attention2)模型在准确率、召回率以及F1值均有所提高.本文模型在THUCNews数据集的F1值达到了97.6%,比ATTCNN(-attention1)模型提高了0.5%,比ATTCNN(-attention2)模型提高了1.3%;在SogouCS数据集的F1值达到了91.4%,比ATTCNN(-attention1)模型提高了0.7%,比ATTCNN(-attention2)模型提高了1.3%.在AG_news数据集的F1值达到了91.0%,比ATTCNN(-attention1)模型提高了0.8%,比ATTCNN(-attention2)提高了1.6%.

表2 注意力机制重要性对比结果(%)Table 2 Comparison of the importance of attention mechanism(%)
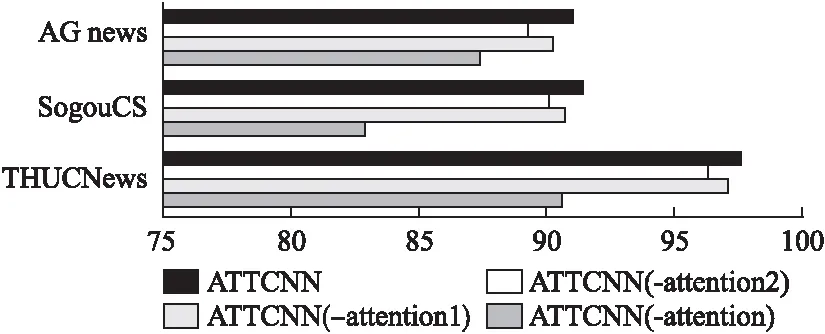
图4 注意力机制模型F1值对比结果(%)Fig.4 Comparison result of F1 value of attention mechanism model(%)
综上所述:本文提出的ATTCNN模型结合了多种注意力机制嵌入模型的优点,在卷积层之前嵌入注意力机制,对影响词向量质量的重要特征进行识别,通过不断迭代对这些关键特征再次加权,以提升词向量质量;在卷积层后嵌入注意力机制,更加关注高维特征的提取,从而得到更能区分类别信息的特征.实验证明,本文提出的ATTCNN模型实现了不同粒度上的注意力分配,提高了文本分类的效果.
5 结束语
本文重点关注如何将注意力机制和卷积神经网络相结合的问题,提出了融合多重注意力机制的卷积神经网络文本分类模型(ATTCNN),首先将注意力机制嵌入到卷积神经网络的卷积层之前,聚焦于影响文本分类效果的输入特征,其次对卷积后得到的特征向量进行注意力分配的二次加权,实现不同维度上的注意力分配,最后引入最大池化和平均池化相结合的方法,有效地减少特征图的尺寸,间接减少全连接层的参数数量,避免过拟合现象的发生.本文模型在中英文数据集上进行实验,并与当前主流的深度神经网络模型以及注意力机制嵌入卷积神经网络的不同方案分别进行了实验对比.实验证明,该模型结合了卷积神经网络提取特征和注意力机制分配权重的优点,在文本分类任务方面有着较大的性能提升.
