面向不平衡网络评论数据挖掘的服务质量评价
2021-03-13顾永春顾兴全洪彩凤金世举
顾永春,顾兴全,武 娇,洪彩凤,金世举
1(中国计量大学 理学院,杭州 310018)
2(中国计量大学 标准化学院,杭州 310018)
1 引 言
随着我国旅游业由高速增长向高质量发展转变,酒店服务质量[1,2]越来越成为各类酒店在激烈的市场竞争中取得优势的关键因素之一,因此,对酒店服务质量的评价受到越来越多的重视和应用.酒店服务质量评价是指以顾客感知[3,4]为基础,以顾客评价为参照,以顾客满意为目标,一切从顾客出发的服务管理行为.国内外学者从顾客出发,对酒店服务质量评价方法进行了大量研究,从评价数据来源来看,这些方法大致可以分为两类:一类是以调查问卷为信息数据来源的研究方法.例如,尹华光等[5]以3个方面、24个问题为基本结构设计问卷,利用修改后的SERVQUAL量表来测评张家界高星级酒店顾客对服务质量的期望和感知.Nunkoo等[6]通过447份问卷对南非各星级酒店服务质量的顾客满意度进行了深入调查研究,为不同星级酒店提高服务质量和顾客满意度提供了有针对性的指导意见.但问卷设计严重依赖专家经验,受主观影响较大,无法反映问卷未涉及到的服务项目质量,并且数据获取成本过高.另一类是以网络评论为数据来源的研究方法.网络评论因其传播速度快,具有实时性,获取成本低,并且完全来自顾客亲身体验等特点而受到广泛关注,基于网络评论的服务质量评价正逐渐成为研究主流.这类方法通常使用自然语言处理(Natural Language Processing,NLP )技术对网络评论文本数据进行预处理,然后根据文本的词频(Term Frequency,TF)[7]或词频逆文档频率(Term Frequency Inverse Document Frequency,TFIDF)[8]等统计信息选取特征词作为研究主体的服务质量特征,最后利用聚类[9]和情感分析[10,11]构建计量经济模型分析服务质量与顾客满意度的关系.
尽管基于网络评论构建的服务质量评价模型能够从顾客自身体验的角度以更少的人工成本提供更为客观的评价结果,但是由于网络获取的评论数据通常分布不均衡,使得上述方法在实际应用中存在一些问题.首先,以TF作为特征选择的权值,会导致评论数目多的主体特征明显,评论数目少的主体特征不够显著,进一步导致行业共性特征被某些个性特征所替代.其次,很多基础性服务特征词会重复出现在多个酒店评论中,如果一个服务特征词在不同酒店评论中出现次数越多,说明该特征受到的关注越广泛,越能代表行业共性.还有,虽然TFIDF是一个很好的分类特征,但是评论数据分布不均衡使得这种代表行业共性的特征词的TFIDF值相对较低,从而导致其重要程度被错误判定.此外,在根据权重大小选取特征词方面,传统方法存在缺乏客观性的问题,通常都是依靠主观经验人为确定.另一种方法是利用齐普夫定律确定高频词进行特征词选择,但该方法在许多情况下效果并不理想[12].在情报学领域,G指数(G-index)[13]被用于衡量高质量论文对学者学术成就的贡献和评价期刊学术影响力等问题.近年来,文本挖掘领域的共词分析研究中出现一些应用G指数确定高频词的方法[14,15],取得较好的效果.最后,在服务质量评价计算模型中,当不同评价主体的评论数据分布不均衡时,会导致评论数量少的主体的评分趋于极高或极低的极端情况,从而引起评分不准确、顾客对各个主体服务质量满意度排名不合理等问题.
针对在酒店服务质量评价模型构建中由评论数据不均衡导致的上述问题,本文首先提出一种用于特征选择的主体频率(Subject Frequency,SF)权重,通过统计包含特征词的主体所占的比例来定义某特征词对行业共性表示的重要程度.其次,本文借鉴G指数的构建思想,提出SF-G指数用于对高频特征词的客观选取,建立服务质量评价指标体系.第三,在服务质量评分模型中,本文提出一种基于热度指数加权的顾客满意度评分方法,以定义的热度指数反映不同主体受顾客关注度的大小,从而有效地弱化数据不均衡产生的评价结果失真.最后,利用酒店网络评论数据对本文的评价模型及方法进行实证分析.
2 服务质量指标体系构建
面向不平衡网络评论的酒店服务质量评价指标体系构建主要包括以下步骤:1) 网络评论文本数据的采集和预处理;2) 词的向量表示;3) 特征词选择;4) 特征词聚类提取评价指标.构建流程如图1所示.
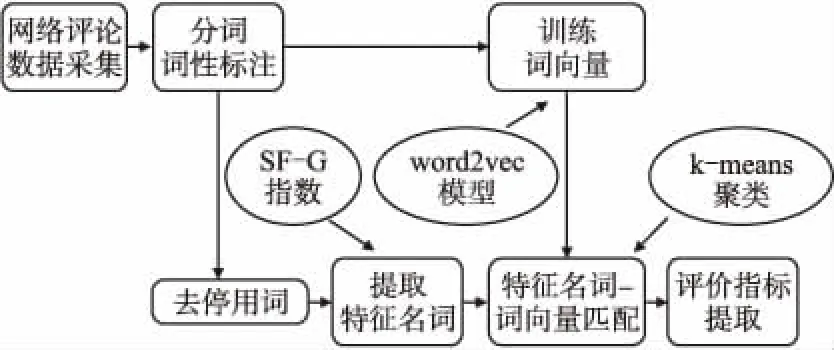
图1 服务质量指标体系构建流程Fig.1 Construction of service quality index system
2.1 语料获取及预处理
本文以酒店评论为研究对象,利用集搜客(1)http://www.gooseeker.com/网络爬虫工具获取猫途鹰网站(2)https://www.tripadvisor.cn/上中国所有省、直辖市、自治区(包括港澳台地区)的五星级酒店的中文顾客评论.为保证评论的有效性,首先需要对网络抓取的评论文本进行清洗,去除文本中的网页格式等无用信息.然后,对每条评论进行中文分词和词性标注,并去除停用词.本文使用python的第三方工具包jieba分词和哈工大停用词表进行中文分词和去除停用词等预处理工作.
2.2 词向量表示
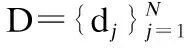
V={(w,v,wPOS)|w∈V,v∈RM}
(1)
2.3 特征词提取
特征词提取的方法很多,大多是基于特征规则排序的,例如将TF和TFIDF作为词的权值,通过对权值的排序提取特征词.评论语料词典V中的某个词W的TF和TFIDF权值的数学表示分别为:
(2)
(3)
其中,f(·)是权值函数,nw,d是词w在评论d∈D中出现的次数,∑d∈Dnw,d是词w在评论语料集D中出现的次数,∑d∈D∑w∈dnw,d是D中所有的词出现的次数,Nw是D中包含词w的评论数,N是D中评论总数.将V中所有词的TF和TFIDF权值从大到小进行排序,指定待选取的特征词个数|W|,选择前|W|个具有最大权值的词为特征词.或者,给定一个特征选择的阈值f0,将每个词的TF和TFIDF权值与其进行比较,得到特征词集合
W={(w,v,wPOS)|f(w)>f0,(w,v,wPOS)∈V}
(4)
这里,f0可以看成区分高频词和低频词的临界值,通常选取高频词作为特征词.
如前所述,在评论语料分布不均衡时,一方面TF和TFIDF权值会导致体现主体个性特征的词被错判成刻画行业共性的特征词,并容易弱化代表行业共性的特征词的重要度;另一方面,上述的特征选择方法依靠主观经验,缺乏客观性.本节提出主体频率(SF)权值和基于主体频率的G(SF-G)指数模型来解决这些问题.
2.3.1 SF权值
本文将服务质量评价的对象称为主体(Subject),例如酒店,不同的酒店对应于不同的主体.假设评论语料集D是由来自于P个不同主体S1,…,SP的子语料集D1,…,DP组成,即D={D1,…,DP}.将D中的评论进行分词和Word2Vec词向量训练后,对每个主体Sp可得到其对应的子词典
Vp={(w,v,wPOS)|w∈d,d∈Dp,v∈RM}
p=1,2,…,P
(5)
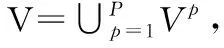
对字典V中的词w,其SF权值定义如下:
(6)
(7)
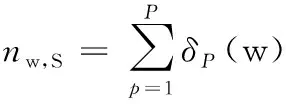
下面将通过一个简单的例子说明SF权值在缓解语料不均衡问题上的作用及效果.假设某行业由3个主体S1、S2、S3组成,词w1、w2和w3是行业的三个重要特征.在不均衡的网络评论语料中,主体S1有100条评论,且都包含w1;主体S2有10条评论,且都包含w1和w2;主体S3有90条评论,且都包含词w1和w3.显然,w1在整个行业中重要度最大,w2和w3的重要度相近且低于w1.由(2)式分别计算w1、w2和w3的TF权值为0.6667、0.0333、0.3000,可以看到,w2的权值仅是最大权值的1/20,在特征选择中很容易被忽略.由(3)式得到w1、w2和w3的TFIDF权值分别为0、13.01、31.21,归一化后为0、0.2942、0.7058,由于w1的权值为0,将导致最重要的特征被忽略.由(6)式计算w1、w2和w3的SF权值分别为1、1/3、1/3,归一化得到0.6、0.2、0.2,可见w1的SF权值最大,w2和w3的权值相同且略小于w1,说明SF权值能够更为准确地体现词语在刻画行业整体特征时的重要度.
2.3.2 基于SF-G指数的特征词提取
服务质量评价的目标通常对应于评论文本中的名词,因此为了确定顾客对服务质量的关注点,进一步确定服务质量评价综合指标,需要在语料词典的名词中进行特征词提取(3)为了简洁,本文将作为服务质量评价目标的特征名词简称为特征词。.将由名词构成的词典记为
VNoun={(w,v)|(w,v,wPOS=Noun)∈V}
(8)
文献[12]将G指数[14]应用于共词分析的主题词选取,提出词频G指数来确定高频词.文献[15]将词频G指数进行改进,解决了将多个具有相同频次的词语划分为高频或低频词的问题.借鉴上述工作,我们提出主体频率G(SF-G)指数的特征词选择方法.将VNoun中的名词按其SF权值从大到小进行排序,定义前G个词的累计主体频率(Cumulative Subject Frequency,CSF)为
(9)
则划分高低频词的SF-G指数的判别条件为
(10)
其中,P是主体总数,n是与第G个词wG具有相同SF的词(包括wG)的个数.由于
(n-1)fSF(wG)+fSF(wG+n)
(11)
因此,(10)式的判别条件可等价地表示为
(12)
也就是说,当前G个词的CSF值满足不等式(12)时,将选择前G+n-1高频词作为特征词,形成的特征词集合记为
WNoun={(wi,vi)|(wi,vi)∈VNoun,i=1,2,…,G+n-1}
(13)
2.4 基于特征词聚类的评价指标提取

3 服务质量评分模型
依据提取的服务质量评价指标,为了对行业某个主体的服务质量进行评价,需要进一步构建服务质量评分模型,根据网络评论语料计算得到顾客对主体服务质量的满意度分数.服务质量评价目标是由评论文本中的名词确定,而顾客对主体服务质量的感知则由评论文本中的情感词(形容词及副词)决定,根据情感词的情感极性来判断评论句的情感倾向,该内容属于NLP中情感分析的研究范畴.本文将直接利用已有的情感分析工具获取评论句的情感极性得分,并以此为基础,结合第2节提取的服务质量评价指标,设计服务质量评分模型.评分模型的构建过程需要解决以下几个问题:1) 评论句分类;2) 评论句情感极性分析;3) 服务质量评分计算.
3.1 评论句分类
依据中文书写格式和习惯,首先以标点符号或者空格为分割符号,将所有评论分割成短评论句.然后,根据特征词的聚类结果{W1,W2,…,WK},将评论句分派到服务质量各级评价指标相应的类别.在拥有大量标注语料的情况下,通常可以将已标注类别的评论句作为样本来训练分类器,再使用分类器对无标注评论句进行分类.然而,直接由网络获取的评论通常都是未标注语料,因此本文使用基于评价指标匹配的方法对评论句进行分类.
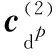
(14)
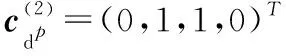
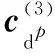
(15)
其中,k=1,2,…,K;i=1,2,…,|Wk| 同样,评论句dp可以属于不同三级指标对应的类别.
3.2 评论句情感分析
本文直接使用中文NLP的SnowNLP库中的情感分析工具包对分类后的评论句进行情感分析,并给出情感分.SnowNLP的情感分析的基本模型是Bayes模型,利用SnowNLP训练的情感分类器可对评论句的情感极性进行预测.对某条评论句d,将其情感分记为z(d),z(d)∈(0,1).情感分值越大表示评论句的情感越倾向于积极的一面,说明顾客满意度越高;反之,顾客满意度越低.
3.3 评分模型
对多个评价主体的评论句分别进行各级分类后,可以利用评论句的情感分计算各级指标的评分.并依据各评价主体的指标评分进一步对行业的各级服务质量指标进行评价,以及对各主体的顾客满意度进行排名.各级指标的评分一般可通过对下级指标得分取平均得到,然而当各评价主体的评论句分布不均衡时,将会导致仅具有少量评论句的主体的评分趋于极高或极低的极端情况,从而会引起各级指标评分不准确、以及各主体的顾客满意度排名不合理的问题.一般来说,对主体或与主体评价指标相关的评论数据越多,表示主体越受顾客欢迎,或者主体评价指标受关注度越高;反之亦然.基于此,本文将采用加权平均的方法计算各级指标的评分,同时在对不同评价主体的指标评分计算中引入一种热度指数,以缓解数据不均衡产生的问题.
3.3.1 行业指标评分
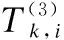
(16)
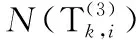
(17)
其中,k=1,2,…,K;i=1,2,…,|Wk|.
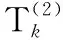
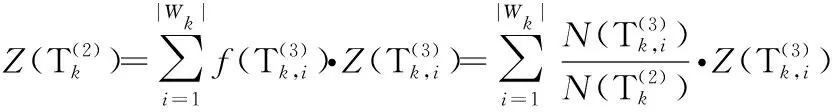
(18)
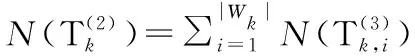

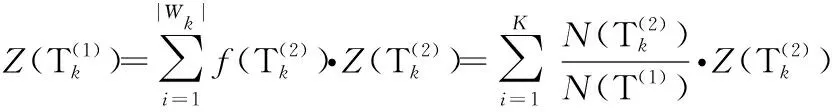
(19)
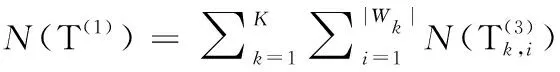
3.3.2 评价主体指标评分
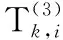
(20)
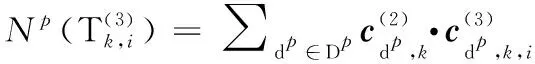
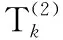
(21)
(22)
(23)
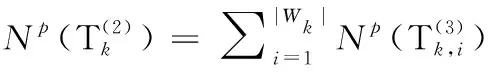
(24)
类似地,Sp的一级指标T(1)的评分定义为二级指标评分的热度加权平均,即
(25)
(26)
(27)
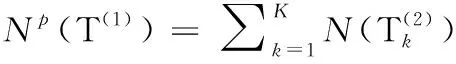
(28)
4 不均衡网络评论下的酒店服务质量评价
4.1 语料概况
本文使用爬虫技术收集“猫途鹰”网站上中国所有省、直辖市、自治区(包括港澳台地区)的五星级酒店的中文评论,共涉及438个五星级酒店,其中最早的评论来自2006年2月,最新的评论来自2019年10月.评论数据统计见表1.从表中可以看到,最大酒店评论数与最小酒店评论数的极差为8943,并且语料的标准差达到1037.41,说明语料中各酒店评论数据的分布极不均衡.如:
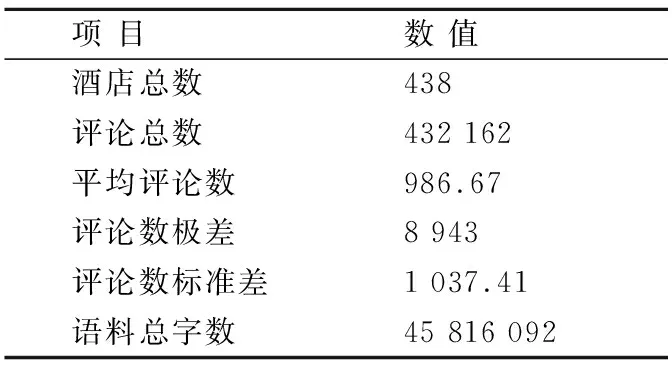
表1 酒店评论数据统计Table 1 Data statistics of hotel reviews
4.2 实验环境工具
实验运行在CPU型号为i5-4210M,内存为8 GB,操作系统为Windows 10 专业版 64位的笔记本电脑上.实验涉及的所有程序代码均采用python3.6.5实现,并在Spyder3下进行编译与运行.程序中主要使用的软件包及相应版本如下:机器学习包scikit-learn(0.22.1),数值运算包numpy(1.18.1),词向量训练工具包gensim(3.8.2),中文情感处理包SnowNLP(0.12.3)以及中文分词工具包jieba(0.42.1).
4.3 特征词提取
为发现顾客对酒店服务的关注情况,首先对上述语料数据进行分词并标注词性,将词语分为名词、动词、形容词、其他等四类,其分布情况如表2所示.酒店服务质量评价的目标一般为评论文本中的名词,本文从名词中提取特征词作为酒店服务特征.
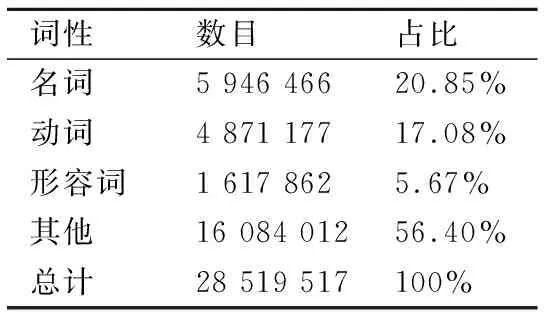
表2 词性分布Table 2 Part of speech
图2 给出评论名词的SF、TF和TFIDF三种权值梯度的变化趋势图,其横坐标按权值大小排序.可以看出TF和TFIDF两种权值在不平衡数据下会出现数值突变的情况,如果以突变点作为特征词权值分界点,则特征词数目过少,无法完整反映酒店特征;而SF权值变化更为平缓,能够更全面地表示酒店特征,因此基于SF权值提取特征词应更为合理.

图2 权值梯度变化图Fig.2 Changes of weights gradient
评论名词的SF权值由(6)-(7)式计算,并采用本文提出的SF-G指数提取特征词.由(12)式计算可提取365个特征词,其中高频词与低频词的临界主体频数fSF·P=281.特征词的分布如表3所示,表中括号内的数字表示其序号,词语下面的数字为其主体频数(fSF·P).
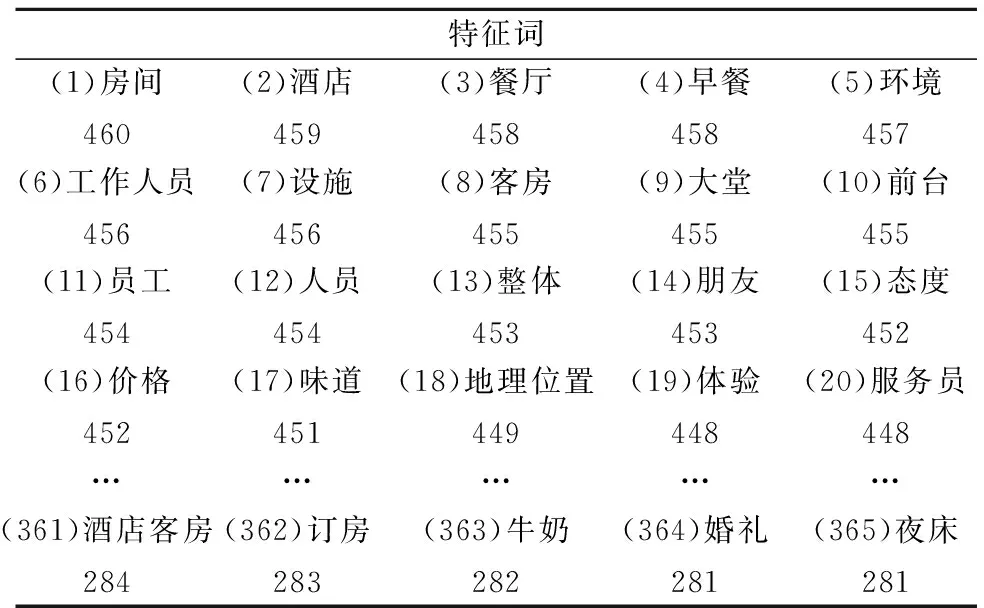
表3 酒店评论特征词Table 3 Feature nouns of hotel reviews
4.4 酒店服务质量评价指标体系构建
根据特征名词构建服务质量评价指标体系,其中以服务质量为一级指标,所有的特征名词为三级指标,二级指标通过对三级指标聚类得到.为了确定最佳的二级指标数目,采用k-means聚类算法,根据欧式距离对特征名词的词向量进行聚类.不断调整聚类簇目K的值,重复多次实验,依据Calinski-Harabaz聚类指标和专家决策共同决定最佳聚类簇目数为K=4,其Calinski-Harabaz值为27.23.由此,根据特征名词所属簇类可设置4个二级指标,分别为餐饮服务,住宿条件,住宿服务,周围环境.每个二级指标下有若干个不同的三级指标.然后,由(16)-(19)式计算得到五星级酒店整体行业的指标评分.各级指标名称含义和评分见表4.
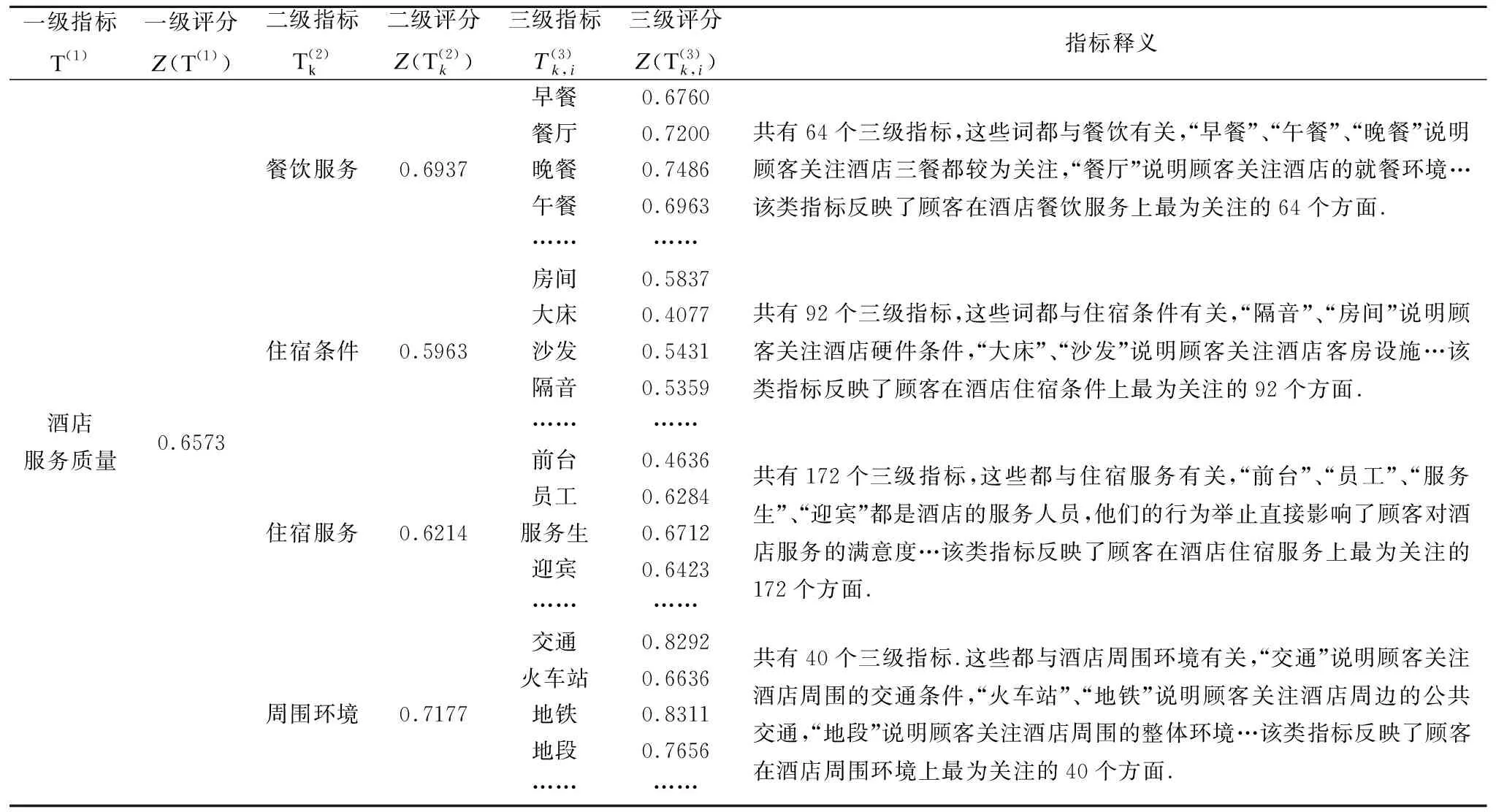
表4 服务质量评分Table 4 Service quality score
表5给出由本文方法和几个传统方法[17,18,20]得到的酒店评价指标模型的对比结果.其中文献[17]的数据由传统的问卷调查得到,并采用三重计量模型对评价指标进行人工提取;文献[18]和文献[19]分别采用内容分析法和变量分析法从网络评论数据中人工提取评价指标;本文则采用人工智能方法通过对网络评论数据的挖掘自动提取评价指标.可以看出,服务评价指标体系构建的数据来源已逐渐从问卷调查转向网络评论,而传统方法主要依靠专家经验对指标进行人工提炼.人工提取的酒店服务质量指标主要为酒店的位置、设施、客房和员工等方面及其总体评价,本文提取的评价指标与之相似.相比之下,本文采用数据挖掘方法能够以较小的人工成本有效地构建评价指标模型.
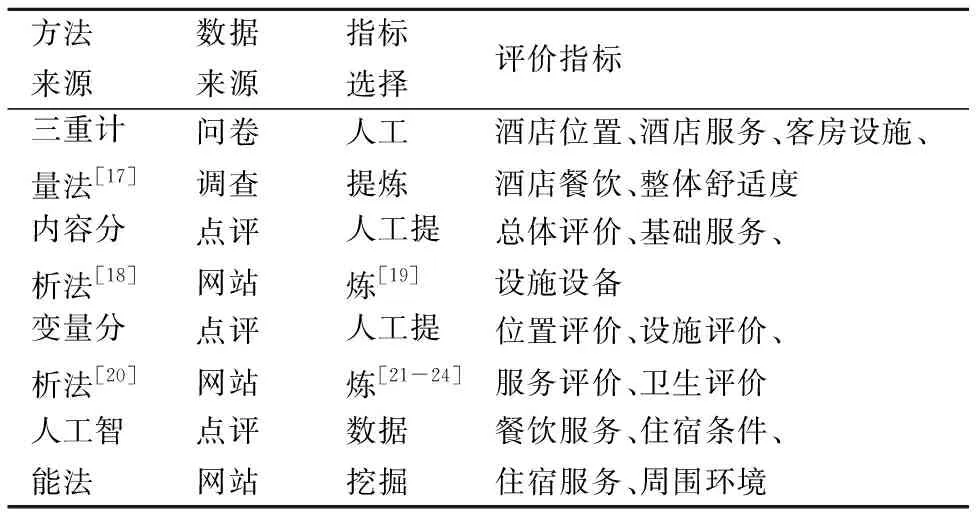
表5 酒店服务评价指标模型Table 5 Hotel service evaluation index model
4.5 酒店服务质量评分及排名
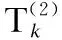
(29)
第p个酒店Sp的一级指标T(1)的顾客满意度排名评分,即服务质量综合评分,换算公式为
(30)
图3展示了热度指数加权后综合评分为前10的酒店评分排名情况.从图中可以看出香格里拉大酒店综合评分最高,且远高于其他酒店;在综合评分前十的酒店中香格里拉品牌酒店占据7席,除此之外只有中国大饭店、中茵皇冠假日酒店和北京嘉里大酒店三个酒店排名在前10.
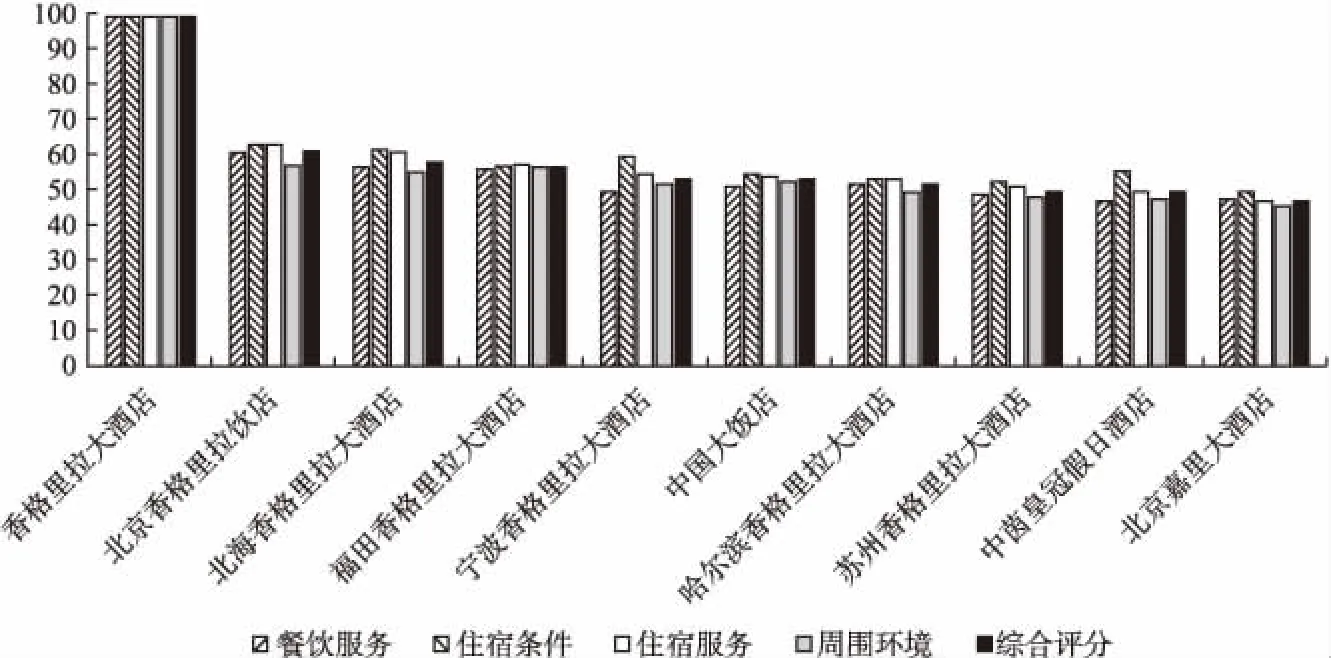
图3 五星级酒店评分排名(综合排名前10)Fig.3 Five-star hotels rating ranking (overall rank top 10)
表6给出热度指数加权方法对数据不均衡问题的性能分析.以排名第1的香格里拉大酒店和仅包含少量评论数据的1881公馆、香港瑰丽酒店和日月行馆国际温泉观光酒店为例,对其各二级指标的热度指数加权评分和未进行热度指数加权的评分排名进行对比,其中排名后带有字母(H)的表示热度指数加权后的评分排名,未带(H)的表示未进行热度指数加权的评分排名.可以看到,如果不进行热度指数加权评分,仅有少量评论的酒店其评分排名都很靠前,若以此作为最终评分进行排名显然很不合理.评论数目的多少可以反映顾客对酒店的关注程度,因此将顾客对酒店的偏好加入评分计算更为合理.本文定义的热度指数权值可以通过评论的数量来表示顾客的偏好.表6中1881公馆等酒店经热度指数加权后的评分排名明显低于未经热度指数加权的评分排名,并且香格里拉大酒店的热度指数加权评分位于第1名,说明热度指数加权能够有效地缓解数据不均衡导致的评分排名计算偏差和评价失真问题.
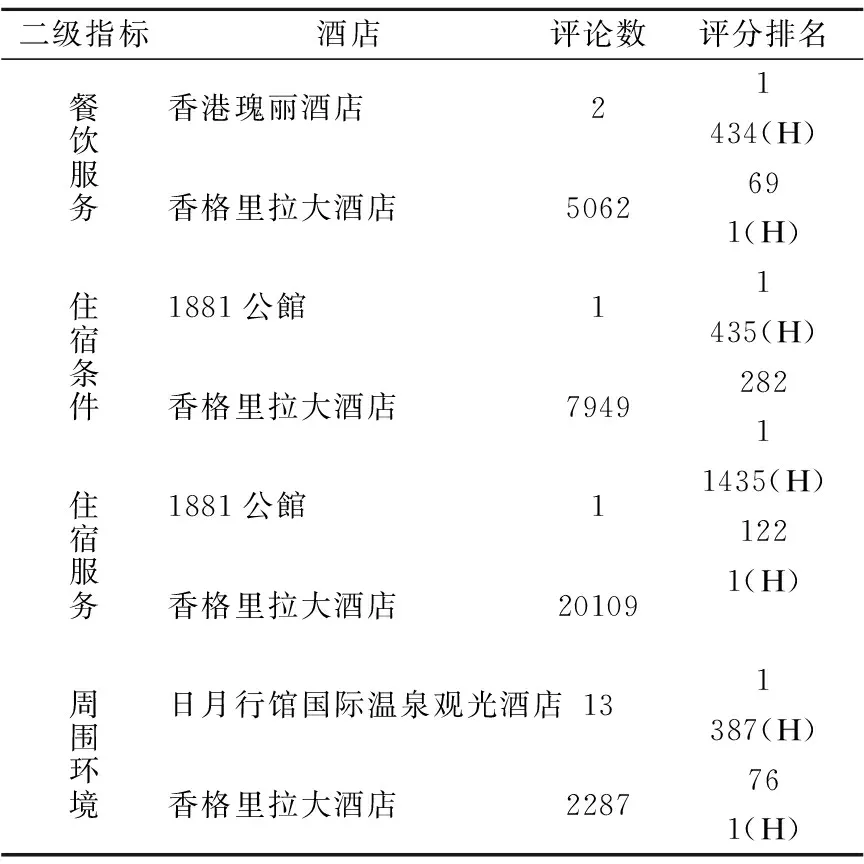
表6 酒店评分排名Table 6 Hotel rating
5 结 论
本文通过主体频率、主体频率G指数和热度加权等方法,构建的酒店服务质量评价指标体系,有效缓解了由于数据不均衡带来的评价结果失真的问题,增加了评价结果的客观性和评价方法的快捷性.将该模型应用在中国五星级酒店服务质量评价上,发现对旅客满意度影响最大的是酒店的餐饮服务、住宿条件、住宿服务、周边环境等四个指标.在计算酒店的综合评分并进行排名中发现排名前10的酒店只有三家不属于香格里拉品牌,说明品牌酒店保证了服务质量水平的一致性.该评价模型也可以推广到其他行业的服务质量评价.
