字词融合的双通道混合神经网络情感分析模型
2021-03-13杨小兵姚雨虹
陈 欣,杨小兵,姚雨虹
(中国计量大学 信息工程学院,杭州 310018)
1 引 言
随着互联网的快速发展,网购已经成为人们日常生活的重要组成部分,相对于传统购物中面对面的商品交易,网上购物看不见实际商品,仅通过商家上传的图片判断商品质量显然不太可靠,所以商品评论就成为大家在网上购买各种商品时的重要参考依据.淘宝、京东、拼多多等购物平台的用户往往在收货后会写下对商品的评价,其他消费者通过这些评价可以了解产品质量、售前售后服务等.销售商可以通过消费者对商品的文本评语,分析消费者对商品的看法,从而帮助改善制定的营销措施[1].而随着大数据时代的到来,信息规模的爆炸式增长,人工处理已经无法满足大规模文本分析任务,因此文本情感分析技术也得到了迅速发展.
最开始,研究者在情感词典和语义规则方面进行研究,基于词典和规则[2-4]的情绪分类方法解释性强,运算速度快.但是随着互联网上新词的不断涌现,基于词典和规则的方法在分类时灵活度不高,难以应对不断变化的词形词义.为提高情感分类的性能,研究者开展了基于机器学习的情感分析方法.通过选取大量有意义的特征来完成情绪分析任务.基于机器学习的方法[5,6]主要通过对数据集进行特征提取,训练分类模型,然后对测试数据进行预测.但是该方法依赖于提取的特征,而且需要构建复杂的特征工程.由于这些方法存在的问题,一些学者开始使用深度学习(Deep Learning,DL)方法进行情感分析研究,深度学习的方法[7-9]使用各种神经网络自主学习,提取文本特征,避免了机器学习由于人工提取的特征不准确而带来的分类误差.深度神经网络的多层非线性结构可以捕捉文本的深层次特征,实现对文本的深层理解.
2 相关工作
近年来,随着DL技术的突飞猛进,越来越多的研究者开始将循环神经网络(Recurrent Neural Network,RNN)算法及其优化算法和卷积神经网络(Convolutional Neural Network,CNN)算法应用于文本情感分析任务中.CNN最早应用在视觉领域中,经典的卷积神经网络整合了卷积层和池化层,最早是由Collobert等人[10]应用于情感分析任务.为了获得更好的句子表示,Kalchbrenner等人[11]把基本的CNN模型向两方面进行扩展,作者一方面使用动态池化技术,另一方面增加了CNN的层数.Kim[8]尝试将随机初始化词嵌入和预训练词嵌入两种不同类型的词嵌入整合在一起,虽然模型简单,但达到一个不错的效果.陈志等[12]在卷积神经网络基础上把类别标签权重引入损失函数,强化少数类对模型的影响,在文本分类任务中获取较好的结果.
虽然卷积神经网络有很强的局部学习能力,但是忽略了反映句法和语义的远距离依赖特性,这种特性对于句子的理解非常重要.循环神经网络是一种具有记忆功能的网络,在序列数据的建模上有很大优势,但是普通RNN存在不能处理长依赖的问题.Wang等人[13]使用长短时记忆神经网络(LSTM)为tweet的情感分析进行研究,和普通的RNN相比,LSTM可以更好的缓解梯度爆炸和梯度消失带来的影响.Teng等人[14]首先使用双向长短时记忆神经网络(BiLSTM)对句子进行建模,BiLSTM可以将一个句子表现的更加全面,每个词的表示输出可以与前后的词关联起来,但网络结构比较复杂,时间代价很高.门控循环神经单元(Gated Recurrent Unit,GRU)由Cho等[15]在2014年提出,GRU是对LSTM的一种改进.GRU将遗忘门和输入门合并为更新门,同时将记忆单元和隐藏层合并为重置门,相比LSTM参数少很多,因此运算相对简化且性能得以增强.双向门控循环神经网络(Bidirectional Gated Recurrent Unit,BiGRU)是两个单向GRU的结合,网络结构相比BiLSTM简单,时间复杂度更低.虽然BiGRU能够充分考虑到上下文信息,但是很难获取深层语义特征,因而本文使用CNN网络对BiGRU模型获取的序列信息进行提取(BiGRU-CNN),将特征优化,充分获取到文本上下文信息和深层语义.
近年来,注意力(Attention)机制[16,17]被广泛应用到基于深度学习的自然语言处理任务中,Attention可以快速提取稀疏数据的核心内容,从而使模型更好地利用与训练目标相关的特征.随着注意力机制在许多任务中取得优秀的效果,研究者开始将Attention机制添加到各种文本情感分析的模型中[18-23].冯兴杰等[18]将传统的CNN模型和注意力模型相结合进行情感分析.张仰森等[19]将BiLSTM和Attention机制相结合对微博文本进行情绪识别和情感分类.陈洁等[20]提将CNN和BiGRU并行的混合神经网络和注意力机制相结合进行情感分析.陶永才等[21]将池化层和Attention机制相结合,利用平均池化和最大池化提取文本特征,使用Attention机制生成权重进行分类,在收敛时间更短的情况下获取了较好的结果.高玮军等[22]提出一种AT-DCNN模型,使用Attention机制对词向量进行处理,降低冗余信息对于情感分析的影响,通过CNN模型进行分类,弥补了CNN特征提取过程中信息丢失的问题.王丽亚等[23]提出一种T-CBGA模型,使用字符级词向量表示文本,将相同的CNN-BiGRU-attention模型组成双通道形式对文本进行情感分析.在这些模型中,注意力机制的引入对文本分类任务的性能都有明显的正面影响.因此本文在BiGRU-CNN模型中引入Attention机制,对模型提取的特征进行权重分配,确定显著信息,从而提高模型的性能.
目前常用的模型大多使用字符级词嵌入或者词语级词嵌入进行文本表示,Zhang等[24]使用词语级词嵌入和情感符号进行结合,使用BiLSTM和注意力机制的双通道网络对微博文本进行分析.Dos Santos和Gatti[25]采用了词的字符特征进一步加强了词嵌入表示.刘龙飞等[26]将字符级词向量和词语级词向量分别作为原始特征,通过CNN进行特征提取,验证了在中文微博的情感分类任务中,字符级词嵌入效果更好.郑诚等[27]将CNN和GRU相结合提出一种DC-BiGRU_CNN模型,使用单词级和字符级词嵌入作为输入层,采用密集连接的BiGRU网络和CNN网络提取特征,在文本分类任务中准确率有明显提升.王根生等[28]将词嵌入特征、词语的情感特征和权重特征融合GRU神经网络对网络文本进行情感分类,在较少数据量时也能获得较好的效果.从这些研究中可以看出词语级词嵌入和字符级词嵌入都能够表示出文本的特征信息,为了更好的表示文本,本文分别将两者作为BiGRU-CNN-Attention模型的输入,将提取的特征进行融合,以获取更充足的信息.
综上所述,本文提出了一种字词融合的双通道混合神经网络文本情感分析模型(CW_BGCA).将字符级词嵌入和词语级词嵌入分别作为两个混合网络通道的输入层,每个通道采用BiGRU-CNN-Attention混合网络提取特征,最后将两个通道分别获取的特征拼接进行分类.实验结果表明,利用该模型进行文本分类的效果较优.
3 CW-BGCA模型
本文提出的CW-BGCA模型主要由3部分组成:基于字符级的BiGRU-CNN-Attention模型(记为C-BGCA模型)、基于词语级的BiGRU-CNN-Attention模型(记为W-BGCA模型)、C-BGCA和W-BGCA模型的融合分类层.CW-BGCA模型的整体架构如图1所示.
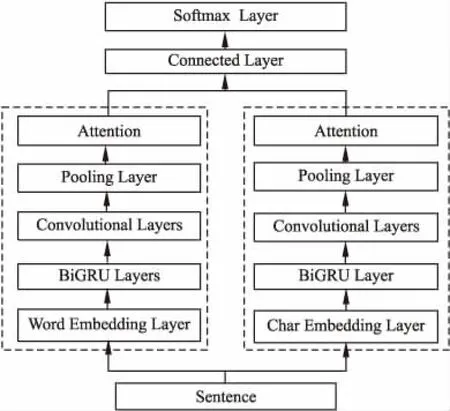
图1 CW-BGCA模型结构图Fig.1 CW-BGCA model diagram
3.1 嵌入层
词嵌入是将文本中的词语映射为低密度的数字向量的方法.词嵌入主要有Word2Vec和Glove两种方法.本文使用的是Word2Vec中的跳字模型(Continuous Skip-gram,Skip-gram).根据分词粒度,在目前文本研究中,存在字符级和词语级两种词嵌入.中文文本的研究大多数都是在词语级词嵌入的基础上进行的,分词的效果直接影响着情感分析的性能,而网络上的不规范用语比较严重,会对分词效果造成很大的影响;字符级词嵌入的方法不需要分词,但字包含的语义信息没有词语充分,因此本文将将字符级词嵌入作为C-BGCA模型的输入层,将词语级词嵌入作为W-BGCA模型的输入层,分别提取特征后融合进行分类.
3.1.1 词语级词嵌入层
词语级词嵌入层为基于词语特征系列模型的输入,一般通过加载预训练的词嵌入向量使用查字典的方法将文本表示为词向量.词典中单个向量的维度为k,词语个数为N,词典Dk×N通过大规模语料采用预训练模型训练得到.本文采用的是北京师范大学中文信息处理研究所与中国人民大学DBIIR实验室开源的使用Word2Vec模型(Skip-gram+负采样)训练的百度百科词向量[29,30].数据集中的每个文本由该文本中所有词语的词向量拼接而成,文本词向量表示如公式(1)所示:
Xw=w1⊕w2⊕…⊕wn
(1)
其中:n表示单个文本中的词语个数,wi∈Dk×N,表示文本中第i个词语的词向量(i=1,2,…,n),⨁表示行向量拼接操作,Xw为词语级的文本表示.
3.1.2 字符级词嵌入层
字符级词嵌入层为基于字符特征系列模型的输入,以字为基本单位.本文的字向量使用随机初始化的字嵌入层,字典中单个向量的维度和词语级词向量相同,也设为k,字个数为M,字典Dk×M是动态随机初始化得到的字典.字符级词嵌入层将文本切分的字映射为低维向量,对于一个字符级的文本序列,将文本中字向量拼接起来,就可以得到整个文本序列的字向量表示,如公式(2)所示:
XC=c1⊕c2⊕…⊕cm
(2)
其中:m表示单个文本中的字的个数,ci∈Dk×M表示文本中第i个词语的词向量(i=1,2,…,m),⨁表示行向量拼接操作,Xc为字符级的文本表示.
3.2 BiGRU层
GRU是循环神经网络系列中的一种效果很好的模型,能够有效的解决梯度损失和梯度爆炸的问题,而且模型结构也比较简单,训练速度很快.GRU模型中只有两个门:分别是更新门zt和重置门rt.具体结构如图2所示:
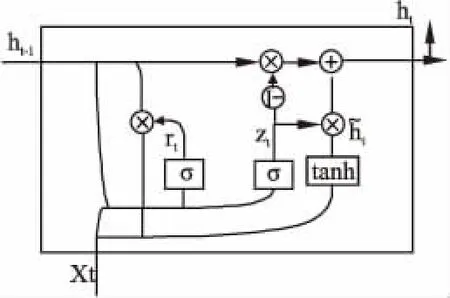
图2 GRU模型结构图Fig.2 GRU model diagram
前一个状态信息对于当前状态的影响由zt控制,zt越大,当前隐层受前一个状态影响越大;前一个状态信息的保留程度由rt控制,rt越小,写入的上一个状态信息越少.具体计算过程如公式(3)~公式(6) 所示:
zt=σ(Wz·[ht-1,xt])
(3)
rt=σ(Wr·[ht-1,xt])
(4)
(5)
(6)
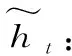
BiGRU使用两个GRU从两个相反的方向提取文本特征,输出由两个 GRU 的状态共同决定.词向量XW和字向量XC分别为词语级模型W-BGCA和字符级模型C-BGCA中BiGRU层的输入.
BiGRU 使用两个GRU从两个相反的方向提取文本特征,输出由两个 GRU 的状态共同决定.词向量XW和字向量XC分别为词语级模型W-BGCA和字符级模型C-BGCA中BiGRU层的输入.
(7)
(8)
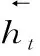
HW=(h1,h2,…,hn)
(9)
HC=(h1,h2,…,hm)
(10)
3.3 卷积层
卷积层.可以通过不同的卷积核对输入的序列进行局部特征提取.卷积核窗口宽度和BiGRU层的输出宽度一致.以词语级模型W-BGCA为例,长度为d的卷积核把HW序列分为{H0:d-1,H1:d,…,Hi:i+d-1,…,Hn-d+1:n},对每一个分量做卷积操作得到卷积特征如公式(11)所示:
Vc=(v1,v2,…,vn-d+1)
(11)
其中,vi是对分量Hi:i+d-1进行卷积操作后提取的特征.每次滑动窗口得到的vi计算如公式(12):
vi=relu(W·Hi:i+d-1+b)
(12)
W为卷积核权重,b为偏置.
同样的方式,字符级模型C-BGCA得到的卷积特征如公式(13):
Vw=(v1,v2,…,vm-d+1)
(13)
3.4 池化层
池化层.对卷积后得到的特征矩阵V执行下采样操作,从中选取局部最优特征,本文采用的是最大池化进行采样,得到的特征li,向量L为li的组合,词语级模型W-BGCA获取的最大池化特征LW如公式(14)-公式(15):
li=max(v1,v2,…,vn-d+1)
(14)
Lw=(l1,l2,…,ln)
(15)
同理,字符级模型C-BGCA获取的最大池化特征LC如公式(16)所示:
LC=(l1,l2,…,lm)
(16)
3.5 注意力层
注意力层对分别对字符级和词语级的BiGRU-CNN模型提取的特征进行处理,确定显著信息.其函数如公式(17)所示:
(17)
其中Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv,dk为调节因子,使得内积不至于太大.Attention层能够将n×dk的序列Q编码成了一个新的n×dv的序列.本文采用Self-Attention结构,即Attention(J,J,J),J表示输入序列.在序列内部做Attention ,寻找显著特征.
AW=Attention(LW,LW,LW)
(18)
AC=Attention(LC,LC,LC)
(19)
3.6 融合层
将字符级模型C-BGCA经过卷积层获取的C-BiGRU-CNN模型和词语级模型经过卷积层获取的W-BiGRU-CNN模型分别经过注意力机制提取的显著特征AW和AC进行融合,得到融合特征A:
A=(AW⊕AC)
(20)
3.7 输出层
将融合特征A输入到多层感知器(MLP),得到更高层的特征表示,并将其进行非线性函数f变换,情感标签的得分如公式(21)所示:
Score(S)=f(WhA+bh)
(21)
其中:Score(S)∈R|Y|为情感标签的得分向量;Y表示情感标签的集合;Wh和bh分别为MLP的参数矩阵和偏置量,MLP不包含任何隐藏层.本文采用RELU函数完成非线性变换.然后对情绪得分向量执行Softmax运算,具体过程如公式(22):
(22)
4 实验与分析
4.1 数据集
本次实验的数据主要来自于网络购物的评论,总共20000条数据,包括书籍、酒店、计算机等5个领域的评论.其中,酒店评论来自中科院谭松波博士(1)https://www.aitechclub.com/data-detail?data_id=29整理的酒店评论语料,其他数据从京东商城网站整理获取.正负样本各10000条,正面情感标记为1,负面情感标记为0.统计数据如表1所示.
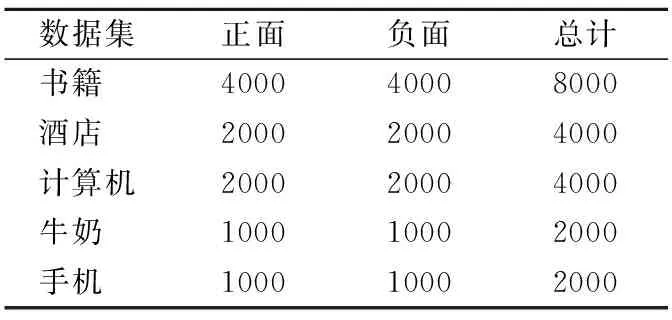
表1 数据统计表Table 1 Statistics table
将所有数据汇总为一个数据集,然后随机打乱,按照8:2的比例分为训练集和测试集,实验数据如表2所示.

表2 详细实验数据表Table 2 Detailed experimental data table
4.2 模型参数设置
本文实验基于Tensorflow实现,经过多次迭代调整,最终CW_BGCA模型参数如表3所示.
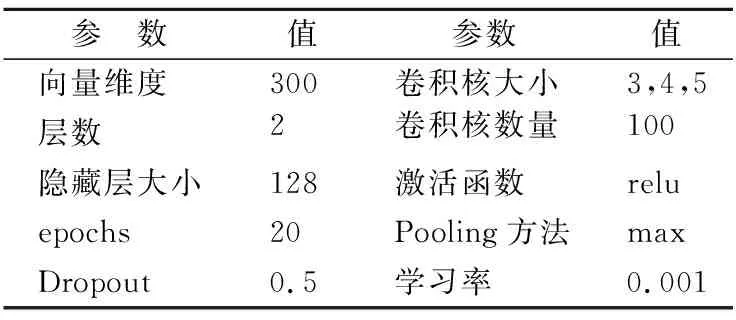
表3 CW_BGCA模型参数设置Table 3 CW_BGCA model parameter settings
4.3 评价标准
本文实验结果采用以下4种指标作为评价标准:Accuracy、Precision、Recall、F1,相关参数如表4所示.

表4 评价指标相关参数Table 4 Related parameters of evaluation indicators
(23)
(24)
(25)
(26)
4.4 对比实验设置
本文实验设置的对比模型有7组,包括单一网络与混合网络的比较,字符级词向量与词语级词向量的比较,添加注意力机制的网络对比,以及单通道与双通道的对比.
1)BiGRU:单一的BiGRU网络,单通道,输入词向量.
2)CNN:单一的CNN网络,单通道,输入词向量.
3)C-BGC:先添加BiGRU网络,再添加CNN网络,单通道,动态随机初始化字向量作为输入.
4)W-BGC:先添加BiGRU网络,再添加CNN网络,单通道,输入词向量.
5)CW_BGC:双通道,每个通道中均为先添加BiGRU网络,再添加CNN网络,最后将双通道分别获取的字词特征拼接,两个通道分别输入词向量和动态随机初始化字向量.
6)C-BGCA:先添加BiGRU网络,再添加CNN网络,最后引入注意力机制,单通道,动态随机初始化字向量作为输入.
7)W-BGCA:先添加BiGRU网络,再添加CNN网络,最后引入注意力机制,单通道,词向量作为输入.
8)CW_BGCA:双通道,每个通道中都是先添加BiGRU网络,再添加CNN网络,然后引入注意力机制,最后将双通道分别获取的字词特征拼接,两个通道分别使用词向量和动态随机初始化字向量作为输入.
4.5 实验结果分析
为验证本文模型的有效性,在相同实验环境下使用5个领域的20000条评论作为数据集,8组模型结果如表5所示.
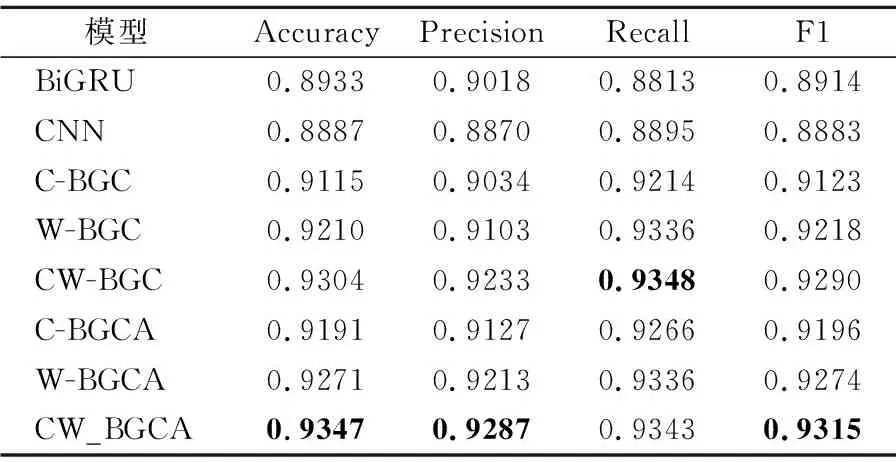
表5 实验结果Table 5 Experimental results
表5将本文的CW_BGCA模型和其他7组对比模型的Accuracy、Precision、Recall和F1进行了对比.由表格中的数据可以看出,本文提出的CW_BGCA模型在Accuracy、Precision和F1这3个指标上都取得了最优的结果.模型的分类效果和F1值正相关,该模型在数据集上的F1值为0.9315,高于其他模型0.25%~4%,说明模型的分类效果明显优于对比模型.
第4组W-BGC模型和第1、2组的单一的BiGRU和CNN模型对比,在4个指标上都有了明显的提升.在综合评价指标F1上,W-BGC模型比单一的BiGRU和CNN模型分别提升了2.09%和3.03%.由于BiGRU模型只考虑到文本的上下文信息,忽略了局部特征对于情感分析的影响;CNN模型只考虑了局部语义特征,没有考虑到上下文信息的影响.而使用CNN网络对BiGRU模型获取的序列信息进行提取,可以将特征优化,获取到上下文和深层语义,得到更好的分类效果,与我们上文的分析一致.
第3组C-BGC模型的效果明显低于第4组W-BGC模型.证明了词语级词向量的优势,由于词语是中文文本中表达信息的基本单位,所以在训练中使用词语级词嵌入相比字符级词嵌入有更好的性能.
第5、8组字词融合双通道CW_BGC模型和CW_BGCA模型的效果优于第3、4组和6、7组单独使用词语级词嵌入和字符级词嵌入,说明双通道的字词融合可以更加充分的提取到文本含义,对模型性能起到促进作用.
第6、7、8组模型分别在第3、4、5组模型的基础上添加了Attention机制,准确率和F1值都有明显的提高,说明在文本情感分类的模型中添加Attention机制能够有效的提升模型效果.Attention机制对BiGRU-CNN模型提取的特征进行权重分配,可以帮助模型快速提取到重要特征,提高模型的效果.
5 结束语
本文提出了一种CW_BGCA模型,首先将字符级词嵌入和词语级词嵌入分别作为双通道混合网络的输入层;然后通过BiGRU进行全局语义建模,获取上下文语义特征,再通过CNN对语义进行卷积池化获取局部语义特征,并分别引入Attention机制分配特征权重,优化特征;最后将获取的字词特征融合进行分类.实验验证,该模型能够提高文本情感分类的性能.同时,通过对比实验也验证了双通道的混合模型效果优于单独的神经网络模型;字词融合特征优于单独的字符级词嵌入和词语级词嵌入的效果;以及添加Attention机制能够明显提升模型的性能.下一步将对深层的神经网络模型对于情感分析的影响做深入的研究.
