相似度保持跨模态哈希检索
2021-03-13房小兆唐宝动孙为军滕少华
房小兆,唐宝动,韩 娜,孙为军,滕少华
1(广东工业大学 计算机学院,广州 510006)
2(广东工业大学 自动化学院,广州 510006)
1 引 言
随着互联网技术的迅速发展,人们对多模态数据之间的交叉检索的需求越来越迫切.多模态数据的最大特点是用多种异构数据描述同一个对象[1-5].例如在维基百科网上,一般由图片、文本等多个不同模态的异构数据描述同一个语义对象;YouTube视频网站上每一段视频大都有相应的文本或者标签进行描述;在微博上发布动态消息时,往往会同时附加一段文字或者一些标签描述上传照片或者视频中的内容.这里的“模态”(Modality)是指数据的类型或者表现形式,不同数据类型对应不同的模态,如:“图像”是一个模态、“文本”是一个模态、“音频”也是一个模态等等.相应的多模态是指用不同的数据类型描述一个共同的语义.在实际应用中,人们经常需要利用图片检索相关文本或者用文本检索相应的图像,类似这种用一种模态的数据去检索另外一个模态数据的任务被称为跨模态检索.然而不同模态数据之间结构上的异构性(Heterogeneous gap)以及语义鸿沟(Semantic gap)等因素给跨模态检索任务造成一定的困难.
为了消除异构多模态数据之间的差异性,很多研究者提出通过算法学习异构数据的统一的潜在语义表示.如:典型相关性分析(Canonical Correlation Analysis,CCA)[6]投影两种模态数据到统一的潜在空间中.偏最小二乘法(PartialLeast Squares,PLS)[7]不但学习统一的空间而且进一步考虑模态内以及模态之间的潜在关联.然而这些方法面对海量样本时由于需要大量的内存消耗以及大规模运算等原因造成算法性能急剧下降.鉴于基于哈希检索算法计算相似度的高效性以及低存储等特点,近年来许多研究者提出将哈希的思想应用到异构跨模态检索(Cross-modal retrieval hashing)任务中.
基于哈希的跨模态检索方法一般是指将描述同一语义对象不同结构的数据映射到相应的潜在语义空间中,再通过某种变换形式用特定长度的“0”、“1”二进制串表示该对象并用于检索的方法.基于哈希思想的算法在计算相似度时可以直接使用二进制编码的位运算(异或,xor)来提升计算效率.另外由于是给每一个样本生成一个对应的二进制序列,所以在存储原始样本时可以极大的节省内存储空间[8-10].Michael[11]等人提出的相似敏感哈希(Learning Using Similarity-Sensitive Hashing)算法第一次将哈希的思想应用到多模态检索任务上,并获得了较好的表现.但该算法只考虑了原始样本模态内的相关性而忽略了模态间的关联性.为解决这一问题,Kumar[12]等提出通过最小化相似样本对对应的哈希码之间的距离并最大化不相似样本对对应的哈希码之间的距离来学习哈希码.Zhen[13]等提出(Multimodal Latent Binary Embedding,MLBE)通过联合的多模态字典学习以获取不同模态样本对的稀疏哈希码,然后利用得到的哈希码来进行跨模态检索.这些工作表明了基于哈希码的跨模态检索算法相对传统的检索算法更具优越性.
现有的基于哈希码的跨模态检索算法中按照是否利用样本的标签信息可分为有监督跨模态检索哈希算法和无监督跨模态检索哈希算法.无监督的算法一般是指直接利用原始样本对之间的相关性以及原始样本的特征将多模态数据转换成哈希序列的方法.例如:Ding等[14]首次提出利用联合矩阵分解(Collective Matrix Factorization Hashing,CMFH)的思想保持模态间的相似性并利用该相似性来进行跨模态检索.Zhou等[15]提出潜在语义稀疏哈希(Latent Semantic Sparse Hashing,LSSH)算法通过利用稀疏编码和联合矩阵分解分别学习不同模态数据之间潜在的语义空间.相比无监督的跨模态检索哈希算法,有监督跨模态检索哈希算法通过同时利用原始数据的标签和特征去学习更加高效以及有鉴别力的哈希序列.例如:zhang等[16]提出的语义相关性最大化(Semantic Correlation Maximization,SCM)算法,该算法通过将标签信息嵌入到哈希函数学习过程,并将学习的正交投影(Orthogonal projections)作为哈希函数.Shaishav[17]等提出的跨视角哈希(Cross-View Hashing,CVH)算法,该算法通过利用标签信息将哈希函数学习过程转换成一个求解广义特征值问题(Generalized eigenvalue problem).从实验结果及分析来看,通常有监督的跨模态检索算法检索效果要优于无监督的跨模态检索算法.这说明利用原始样本的标签信息可明显提升跨模态检索的准确率.语义标签信息和原始样本的局部几何结构也可以用来提高检索准确率.例如协同正则化哈希(Co-Regularized Hashing,CRH)[18]算法,该算法利用标签信息和不同模态内部的相似度来学习哈希编码.Tang等[19]提出的有监督矩阵分解哈希(Supervised Matrix Factorization Hashing for Cross-modal Retrieval,SMFH)算法,该算法通过利用原始样本的语义标签一致性和模态内数据的局部几何一致性来学习更具鉴别能力的哈希码.上述众多跨模态哈希检索算法中依然存在如下可以改进的地方:1)大部分有监督的跨模态哈希算法利用标签信息保留哈希码之间的相似性,没能充分利用标签信息挖掘样本之间的可分性信息;2)大部分有监督跨模态检索哈希算法仅仅考虑不相同模态数据之间的相似性结构,忽略了同一模态数据之间的相似性结构;3)大部分基于矩阵分解的有监督的跨模态检索哈希算法在进行矩阵分解时仅仅关注分解的过程,忽略矩阵分解时的残差结构.
为此,本文提出一种新颖的相似度保持跨模态检索的哈希算法(Similarity Preserving Cross-Modal Hashing,SPCMH).该算法利用原始样本对的标签信息对SPCMH目标函数中的每个子目标函数进行约束并利用联合矩阵分解学习多模态样本之间的统一潜在语义空间,并兼顾模态内和模态间的相似度学习,使得1)模态内数据矩阵在分解的过程中能够保持数据分解时的残差结构;2)相同模态数据能够保持数据的局部几何结构;3)不同模态的数据能够保持数据之间的相似性结构;4)学习到的哈希码具有较强的鉴别能力.图1描述了整个算法的主要流程.
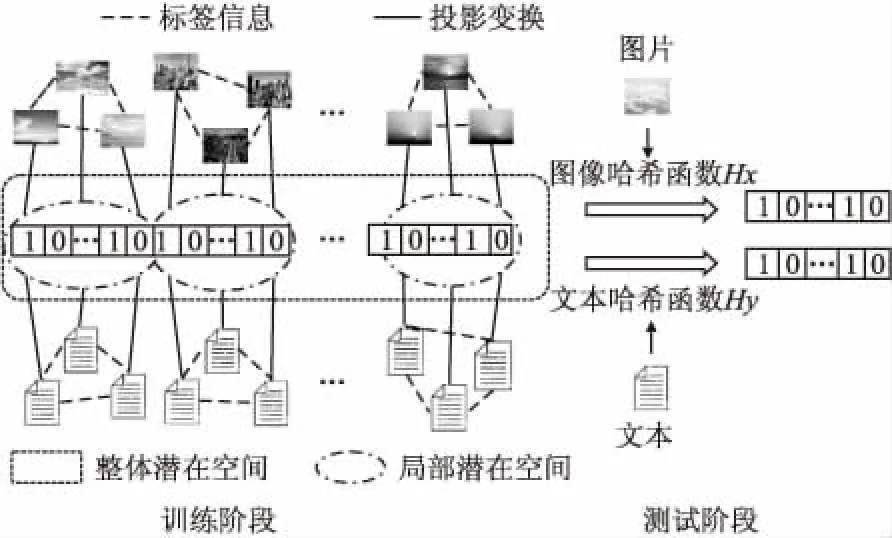
图1 算法框架图Fig.1 Framework of our approach
本文将在第2部分介绍子空间学习、近邻图等相关工作.在第3部分逐步介绍SPCMH算法以及优化算法.实验结果、参数敏感性分析在第4部分介绍.第5部分对本文的工作进行总结.本文出现的主要符号说明见表1.

表1 主要符号解释Table 1 Explanation of main symbols
2 相关工作
2.1 子空间学习
子空间学习在机器学习、模式识别等领域中有着广泛的应用.它可以将原始高维数据用低维度的数据表示,并尽可能多的保留原始数据的特征.常见的子空间学习方法有主成分分析(Principal Component Analysis,PCA)[20]、线性鉴别分析(Linear Discriminant Analysis,LDA)[21]、局部保持投影(Locality Preserving Projection,LPP)[22]等方法.但是这些方法大都是在同一个模态下进行子空间学习,并不适用于多模态情况下各个异构数据之间的子空间学习.在跨模态检索领域里也有很多研究关注于学习多模态数据之间潜在子空间结构.其中典型相关分析CCA及其对应的改进算法被广泛应用在多模态学习和跨领域学习.CCA的目标函数如式(1)所示:
(1)
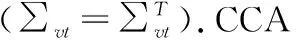
2.2 近邻图
近邻图能够很好地揭示原始数据的局部几何结构,因此在数据挖掘和模式识别等领域中有着广泛的应用[25,26].基于近邻图正则化的学习方法首先是构造一个表示局部关系的相似矩阵,然后通过构造类似如下所示的优化目标进行学习:
(2)
P为需要学习的线性投影矩阵,W的定义可以如下:
(3)
xi∈Nk(xj)表示样本xi是样本xj的前k个最邻近的样本之一,也意味着这两个样本不但相似而且具有较大的概率归属于同一类.通过这种方式可以让原始的样本通过投影之后在对应的空间里依然保持原始样本之间的近邻关系.
3 相似度保持哈希
3.1 相关矩阵说明
不同模态内部样本的局部几何结构信息对于保持该模态内部的近邻关系起到非常重要的作用,而模态间的相似性度量侧重点在于挖掘模态与模态之间的潜在关联.这些特征对充分保留原始样本的特征有重要意义.接下来将给出几个在本文中用到的矩阵的说明.
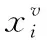
(4)
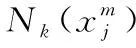
语义关联矩阵R表示模态X和Y之间的标签关系.如果来自图像模态中的样本xi与来自文本模态的样本yi具有相同的标签信息,则Rij的值为1,反之为0.具体公式如下:
(5)
3.2 模型介绍
3.2.1 分类器学习
哈希码要具有一定的鉴别能力.假设样本xi对应的哈希码bi,通过引入矩阵W转化bi到对应的标签li,即:
li=WTbi,i∈{1,…,n}
(6)
其中W∈Rr×c为线性分类器参数(c是对应数据集类别的个数).通过求解如下的目标,可以得到W的解:
(7)
3.2.2 哈希函数学习
通过联合矩阵分解可以将不同结构的数据映射到统一的潜在语义空间里,进而探究异构数据之间的关联[27-29].据此,我们可以通过线性投影矩阵U,V分别将图像模态及文本模态的数据映射到共同的潜在语义空间中去,这样可极大的保留原始多模态样本对之间的特征.本文通过使用相似度矩阵来约束矩阵S(m)分解的残差来进一步保持不同模态数据的局部结构.因此我们定义如下的目标函数:
(8)
其中U∈Rd1×k,V∈Rd2×n是线性投影矩阵,即投影原始数据为对应的哈希编码.通过使用S(m)约束原始图像和文本数据的分解残差,使得相似的样本具有相似的残差,从而保证学习到的哈希码能够保持数据的局部结构通过最小化式(8)可以使得不同模态的样本投影后能够逼近对应的哈希码.
3.2.3 模态内部相似度学习
有效利用模态内部数据之间的局部几何结构可使得学习到的统一潜在语义空间能够尽可能的保留原始空间的近邻结构.
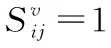
(9)
通过变换,式(9)可转换为如下形式:
(10)
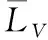
3.2.4 模态间相似性学习
表示相同语义的样本对在投影后的目标空间里应该有相似的结构,因此,针对模态间相似性学习我们构造如下的目标函数:
(11)
如果来自图像模态的样本xi与来自文本模态的样本yj具有相同的标签,则Rij的值为1.通过最小化式(11)可使得来自于不同模态但是相同类别的样本通过线性投影变换之后依然能保持相似的结构并且能够聚集在一起.
通过变换,式(11)可转换为如下形式:
(12)
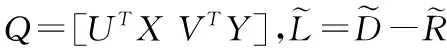
(13)
3.3 整体目标函数
结合分类器学习、哈希函数学习、模态内部相似度学习和模态间相似度学习,完整的SPCMH算法的总体目标函数如下:
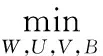
(14)
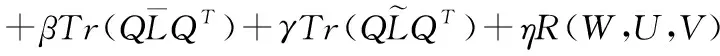
(15)
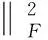
3.4 优化算法
目标函数式(14)是一个非凸优化问题.但是,对于每一个优化变量是一个凸优化问题[30].我们使用如下的迭代优化来解决优化目标式(15):
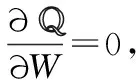
W=(BBT+ηI)-1BLT
(16)
其中I∈Rr×r表示单位矩阵,(.)-1表示矩阵的逆.
Step2.(更新U,V):固定W,V,B,式(15)可转变为:
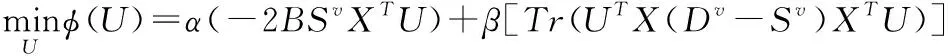
(17)
U=[2βX(Dv-Sv)XT+2γXD3XT+2ηI]-1 (2αX(Sv)TBT)+γXRYTV+γXRYTV
(18)
同样地,固定W,U,B,式(15)也可转变为:

(19)
V=[2βY(Dt-St)YT+2γYD4YT+2ηI]-1(2αY(ST)TBT+γYRTXTU+γYRTXTU)
(20)
Step3.(更新B):固定W,U,V,式(15)也可转变为:
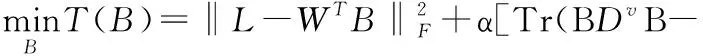
(21)
-2WL+2WWTB+α(B(Dv)T+BDv)-2αUTX(Sv)T+α(B(Dt)T+BDt)-2αVTY(St)T=0
(22)
式(22)可变换为:
AB+CB=E
(23)
其中:
A=WWT.C=α(Dv+Dt).E=WL+α(UTX(Sv)T+VTY(St)T)
这是一个典型的希尔维斯特方程(Sylvester).
当输入一个任意模态的检索样本qi时,SPCMH算法会通过相应的哈希函数生成对应的哈希序列bi=sgn(UTqi) orbi=sgn(VTqi).算法1描述了SPCMH算法更新迭代的具体步骤.
算法1.相似度保持跨模态哈希
输入:图像矩阵X,文本矩阵Y,样本标签矩阵L,关联矩阵Sv、St、R等.随机初始化哈希矩阵B、线性变换矩阵U,V与分类器W.
输出:哈希码B,以及线性变换矩阵U,V.
1.中心化图像矩阵X,文本矩阵Y,初始化矩阵L,S与R;
2.重复步骤3-步骤5;
3.通过式(16)更新W;
4.通过式(18)、式(20)更新U,V;
5.通过式(23)学习矩阵B;
6.直至收敛.
4 实 验
本部分将详细介绍SPCMH算法在Wiki[31]、NUS_WIDE[32]、MIRFlickr-25k[33]3个基准数据集上的实验结果与分析,每一个数据集都包含若干个图像及文本对.此外本文还对算法的各个参数的敏感性进行了分析.值得注意的是,本算法也可直接应用到其它模态数据的交叉检索,例如图像-视频、文本-音频等.
4.1 数据集介绍
Wiki数据集:总共包含10个类别(Categories)共2,866个样本,每一个类代表不同的语义.这些样本都是从维基百科(Wikipedia)网站上收集而来,每一个样本对都包含一张图片和对应的文本,两者共同描述同一个对象.在数据特征上,数据集中每张图片都是用128维的SIFT(Scale-invariant feature transform)特征向量进行表示,每个文本用10维的Latent Dirichlet Allocation(LDA)特征向量进行表示.为了实验对比,实验时随机选取2,173个数据对构成训练集,剩余的693个数据对作为测试集.
NUS_WIDE:新加坡国立大学公开的数据集,总共包含269,648张从Flickr网站上收集的图片.每一个样本对都有一张图片与对应的文本进行注释,每张图片上有多个标签,全部样本被分为81个类别.为了实验对比,本文筛选了样本数量最多的10个类别进行实验,总共有186,577个样本对.其中图片用500维的视觉词袋SIFT直方图表示,对应的文本用1,000维的BOW向量表示.实验时随机选取5,000图像-文本对构成训练集,然后在余下的数据中随机挑选1,866个图像-文本对作为测试集.
MIRFlickr-25k:包含25,000张从Flickr网站上下载下来的图像以及附带的文本标记构成,每一个数据样本分别属于24个语义类之一.每一张图像也都对应着唯一的与其相关的文本标签.用150维直方图特征(Edge Histogram)表示图像数据,对应的文本用500维的特征向量表示.数据集样本选择时,本文剔除那些标签不超过20个的样本.余下的数据集中随机选取5,000对图像-文本对作为训练集,836个图像-样本对为测试集.
4.2 评估度量及参数设置
本文选取跨模态信息检索中最常用的平均查准率Mean Average Precision(mAP)作为主要指标评价算法的整体性能.
平均准确率(Average Precision,AP)定义如下:
(24)
其中M是被检索数据集中与检索数据样本相关联的数据的个数,G表示前G个查询结果.Precision(r)表示被检索到的前项数据的精确度,δ(r)=1时表示被检索到的第r个数据项与要检索的数据是相关联的,相反δ(r)=0时表示被检索的第r个数据项与要检索的数据一定不是同一类.在Wiki数据集中,具有相同标签的样本称之为相似样本,在MIRFlickr-25k、NUS_WIDE多标签数据集上,至少有一个相同的标签则称为相似样本.
计算每个样本的平均准确率的平均值即为mAP:
(25)
Q是查询集合的大小.本文主要验证两种跨模态检索任务,一种是利用图像去检索相关文本,即“Img2Txt”,另一种是文本检索相关图片,即“Txt2Img”.本文实验是在Matlab2016a,Intel(R) Core i9CPU @3.6GHz环境下进行的.
在后续试验中,我们设置η的值为1,对于α,β,γ我们从{0,1e-6,1e-5,…,1}中选取最优组合.K-近邻的参数设置为5.为了全面的评估本文算法,哈希码长度设置为16bits、32bits、64bits以及128bits.
4.3 实验结果与分析
为了验证算法SPCMH的有效性,本文选取了6个相关的跨模态检索算法进行对比.具体为LSSH、CMFH、CRH、SMFH、DCH、语义保持哈希(Semantics-preserving hashing,SePH-km)[34].
其中LSSH、CMFH为无监督算法,CRH、SCM、SePH、DCH为有监督算法.LSSH通过稀疏编码和联合矩阵分解分别学习不同模态数据之间潜在的语义空间;CMFH是无监督的联合矩阵分解哈希,通过利用联合矩阵分解来学习多模态统一的潜在空间并且兼顾了模态之间的关联性.但该算法未能充分利用标签信息;CRH既利用了标签信息也考虑了样本之间的关联.但该算法未能考虑模态内部之间的关联;SMFH算法虽然利用了原始样本的标签信息,但是没能充分利用给定的标签信息挖掘样本之间的分类信息.SePH算法通过利用概率分布最小化Kullback-Leibler散度来学习哈希码.DCH算法利用了标签信息指导不同模态样本的哈希函数学习.
实验过程中,对比算法的实验参数都是依据相关文献建议中的参数进行设置的.本文取5次相应的实验结果的平均值作为最终的实验结果.
4.3.1 在Wiki数据集上的结果
实验中设置α=1e-6,β=1e-6,γ=0.001附件时可取得较高的mAP值.相应的结果如表2所示.
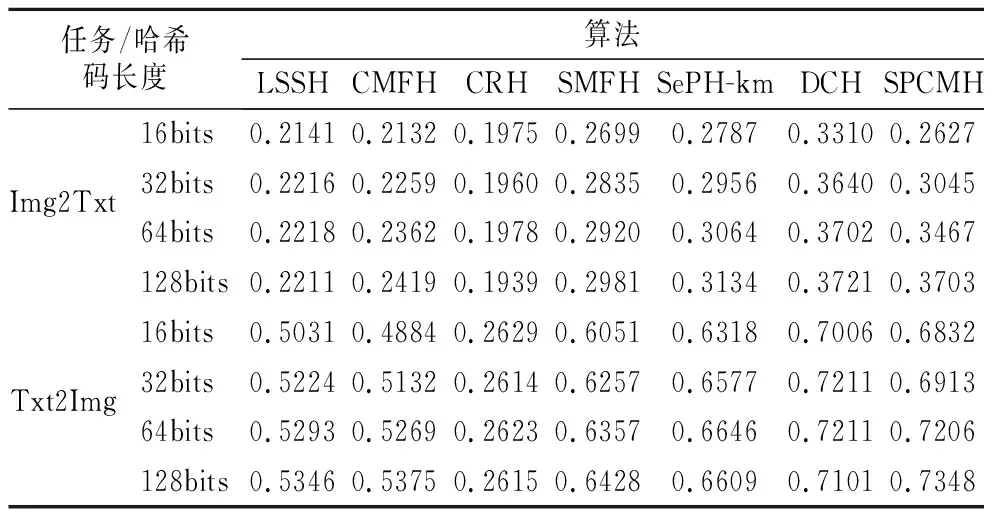
表2 在Wiki数据集上的mAP值Table 2 MAP results on Wiki data set
由表2可知:
1)本文提出的SPCMH算法的mAP值在整体上均优于对比算法.特别是在Txt2Img检索任务上,SPCMH算法相对无监督算法CMFH等最高提升了约19%,相对于有监督算法DCH最高提升约3%.这说明SPCMH算法确实能够有效地提高交叉检索的准确率;
2)整体上有监督的跨模态哈希检索算法效果要优于无监督的算法,这说明有效利用语义标签信息可以提升检索的准确率;
3)总体上,Img2Txt任务的mAP值要低于Txt2Img任务.其原因可能是因为通常文本的特征描述相对于图像的特征描述更接近于实际样本的语义特征.
4.3.2 在NUS_WIDE数据集上的结果
本文进一步在数据集NUS_WIDE上进行实验.算法中相关参数范围的设定如同在Wiki数据集上一样,实验结果如表3所示.
从表3中可知:
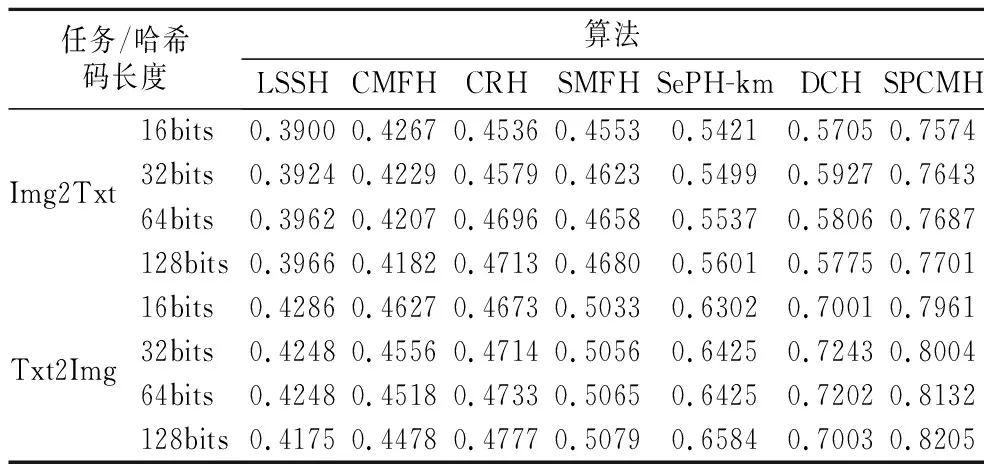
表3 NUS_WIDE数据集上的mAP值Table 3 MAP results on NUS_WIDE data set
1)SPCMH算法在NUS_WIDE数据集上的表现也比较稳定,相对于无监督算法LSSH、CMFH或者是有监督的跨模态交叉检索哈希算法DCH、SMFH等,SPCMH在Img2Txt与Txt2Img任务上mAP的值都有明显的提升.尤其是相比有监督的DCH,SPCMH在Img2Txt任务上最高提升约20%,在Txt2Img任务上最高提升约12%.主要原因可能是有效地利用语义标签的同时在联合矩阵分解时保留了原始数据的残差结构;
2)实验中可以发现随着哈希编码的位数增加SPCMH算法在Img2Txt任务和Txt2Img任务的mAP值呈现出平稳的增长趋势,这说明在一定哈希码长度范围内,越长的哈希码有利于保持更多地鉴别信息.而有的算法甚至出现了略微下降的现象,例如:LSSH算法在Txt2Img任务上,CMFH算法在Img2Tx任务上.这主要的原因可能是这些算法随着哈希码长度的增加,可能引入了噪声等负面因素,导致算法性能下降;
3)对比无监督算法CMFH和有监督算法SMFH、DCH等,SPCMH在mAP值上有明显的提升.原因可能是本文将标签信息应用到优化目标的各个部分对提升检索准确率有很大的帮助.
4.3.3 MIRFlickr-25k数据集上的结果
在数据集MIRFlickr-25k上的参数的设置依然如上述两个数据集一样.实验结果如表4所示.
从表4中可知:
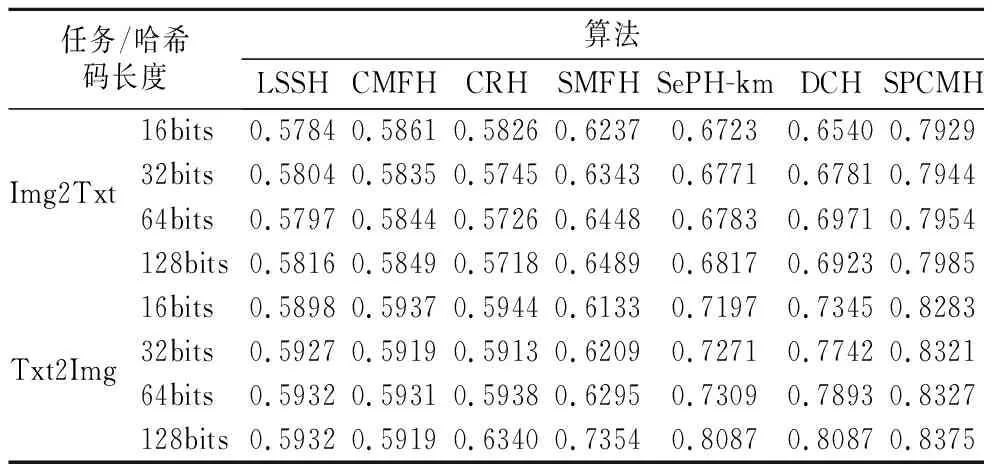
表4 MIRFlickr-25k数据集上的mAP值Table 4 MAP results on MIRFLICKR-25k data set
1)SPCMH算法在MIRFlickr-25k数据级上明显优于对比的无监督或者是有监督的跨模态检索哈希算法.在Img2Txt任务上相对于表现最好的DCH算法提升了约14%,在Txt2Img任务上相对于DCH提升了约4%;
2)大部分算法随着哈希码长度的增加mAP的值也相应地增加,但是,SPCMH算法的增长并不是很明显.这说明了该算法在实际应用中能用较少的哈希码表示原始样本的特征,相比其他算法可以进一步节省存储内存以及提升运算效率;
3)SPCMH算法的效果都要明显高于另一个有监督算法SMFH.其中在Img2Txt任务上mAP提升约16%,在Txt2Img任务上提升约10%.本文算法明显优于SMFH的原因可能是:1.联合矩阵分解过程中保持数据的残差结构可以使得哈希码保持数据的局部几何结构;2.模态间的相似性学习对提高哈希码鉴别能力十分重要.
4.3.4 参数敏感性分析
本文进一步分析了优化目标式(14)中各个参数的敏感性.因为在所有的实验中η=1,所以在本节不在对此参数进行讨论.在分析参数α,β,γ时采用固定其中一个分析另外两个参数对算法性能的影响.本文选择NUS_WIDE数据集作为基准数据集,哈希长度固定为32bits.整体上α可视为哈希函数学习过程的权重,β为不同模态内部的相似度学习权重,γ为不同模态间的相似度学习权重.
图2中(a)(d)对应固定γ,分析β、α在区间{0,1e-6,1e-5,…,1}范围内在Img2Txt和Txt2Img两个任务上mAP数值.相应的(b)(e),(c)(f)分别表示固定β,α而分析另外两个参数时的结果.图(a)(d)对应的是固定γ=1e-3.由结果可知当α∈{1e-1,1e-2,1e-3}且β∈{1e-6,1e-5,1e-4,1e-3}时算法可取得较高的mAP值.图(b)(e)是固定β=1e-4得到的结果.由图可知当α∈{1e-3,1e-2,1e-1}且γ∈{1e-3,1e-2,1e-1}时可得到较高的mAP值.图(c)(f)中说明在实际应用中,固定α=1e-3,当γ∈{1e-1,1e-2,1e-3}区间时可得到较高的mAP值,此时的最优值范围区间较大.另外当α,β,γ中其中一个参数数值为0时,相比于非0时对应的mAP值有明显的降低.综上可知该算法对参数α,β,γ在{0,1e-6,…,1}区间变换时大都能取得较高的mAP值,这说明了SPCMH算法的几个参数在该区间内不敏感.另外,由于参数α,β,γ分别控制算法的各个部分的重要性,所以上述的分析结果说明本算法的哈希函数学习部分、模态内部相似度保持部分、模态之间相似度保持部分对提升算法检索的准确率都至关重要.
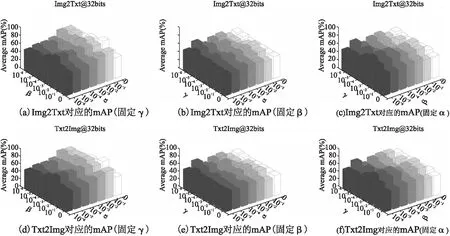
图2 参数敏感性分析Fig.2 Parameter sensibilityanalysis
5 结 论
本文提出一种新颖的相似度保持跨模态检索哈希算法.该算法将原始样本的标签信息嵌入到算法的每一个子目标的学习过程中,同时本算法通过在联合矩阵分解过程中保持数据的残差结构,以提高跨模态检索的检索性能在3个常用的基准数据集Wiki、NUS_WIDE、MIRFlickr-25k的实验结果显示,与相关的跨模态哈希检索算法相比,SPCMH算法能更好地提升跨模态检索性能.
