基于不确定性感知的语音分离方法*
2021-03-12涂斌炜吕俊
涂斌炜 吕俊
技术应用
基于不确定性感知的语音分离方法*
涂斌炜 吕俊
(广东工业大学自动化学院,广东 广州 510006)
为抵御噪声的干扰,提出一种基于不确定性感知的语音分离方法。在训练阶段,采用双链路架构分别学习噪声和语音源成分的编解码子网和分离子网;在测试阶段,以闭式解的形式自适应更新噪声编码子网,减小训练与测试噪声在特征空间的均值偏移,降低认知不确定性,并尽量保持重要参数不变,间接限制语音分离的经验误差。在公开数据集LibriSpeech, NoiseX和NonSpeech上的实验结果表明:本文提出的方法能够快速有效地提高噪声干扰下语音分离的尺度不变信噪比。
语音分离;噪声干扰;不确定性感知
0 引言
语音分离一词最初源于“鸡尾酒会问题[1]”,是指从混合的两个或多个说话人的声音中得到想要的目标说话人(一人或多人)的语音信号,广泛应用于语音识别、情感识别或翻译等任务的前端处理。按信号输入的通道数划分,语音分离可分为单通道语音分离和多通道语音分离2种。本文主要讨论单通道语音分离技术。
单通道语音分离技术又分为有背景噪声和无背景噪声2类。无背景噪声的单通道语音分离技术发展较早,常见方法包括基于听觉场景分析[2]、基于非负矩阵分解[3-4]和基于深度神经网络的语音分离方法[5-6]。这些方法推动了单通道语音分离技术的发展,但没有考虑噪声干扰的影响,与真实使用场景相差较大。
近年,许多专家学者逐渐关注有背景噪声的单通道语音分离技术。文献[7]~文献[9]通过串联方法将语音降噪网络和语音分离网络结合起来,该方法已被证明能够改善嘈杂环境下的语音识别性能;文献[10]通过多场景训练方法将语音降噪和语音分离结合在一起,2个任务共用1个网络。上述方法改善了语音分离技术在噪声环境下的分离效果,但没有考虑异常噪声带来的分布差异问题。由于噪声具有较强的多样性,因此测试信号中难免会出现与训练集噪声相差较大的噪声信号,这些异常噪声会严重影响语音分离效果。
为抵御噪声的干扰,本文提出一种基于不确定性感知的语音分离方法(speech separation based on uncertainty perception, SSUP)。该方法采用变换域特征的均值偏移来度量预测不确定性,采取双链路网络结构,通过自适应更新噪声编码网络的参数,减小噪声带来的均值偏移,同时采用弹性权重固化(elastic weight consolidation, EWC)策略[11],间接保持较小的训练集经验误差。
1 分离网络
1.1 问题描述

1.2 网络结构
现有的单通道语音分离方法主要采用单链路架构[12-13]。但由于噪声与语音信号的分布不一样,采用不同的表达方式更合理。本文提出的SSUP采用双链路网络架构,如图1所示。

图1 SSUP双链路网络架构
SSUP双链路网络包括网络结构相同的2个链路,每个链路皆包含编码器、分离器和解码器3个主要部分。编码器和解码器分别为一维卷积和一维逆卷积网络;分离器由多个双路循环神经网络(dual-path RNN, DPRNN)模块组成[12]。其中,链路1的输出为2个说话人的语音信号,链路2的输出为噪声信号。首先,在训练集中训练得到初始模型;然后,根据每条测试信号,有针对性地更新链路2中编码器的参数,并保持其他参数不变。
依据验证集的分离性能,SSUP双链路网络的参数设置如表1所示。模型训练采用的优化器为Adam,迭代步长为10-3,迭代次数为100。

表1 SSUP双链路网络参数设置
1.3 训练目标
网络最终输出是估计信号的时域波形。本文采用的训练目标为最大化尺度不变信噪比(scale-invariant source-to-noise ratio, SI-SNR)[14]。在单通道语音分离中,标准的信号失真比(source-to-distortion, SDR)可能出现误导性结果,即在感知上并没有改变估计信号的情况下,仅依靠缩放估计信号便能提高SDR值,然而这种提高没有实际意义[14]。为避免这种情况,SI-SNR取代SDR作为语音分离的评价指标[12,15],其定义为
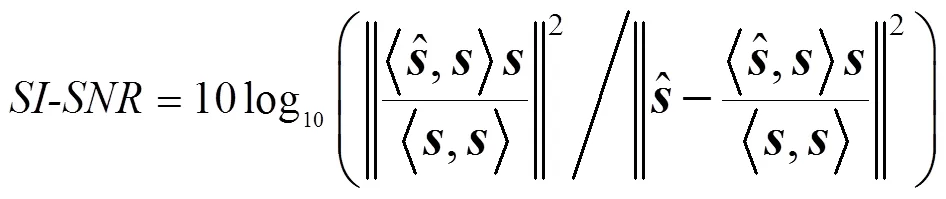
2 基于不确定性感知的语音分离
2.1 不确定性感知



2.2 参数更新方法
测试信号与训练集的编码特征分布应尽量接近,以减小分离模型的认知不确定性。与此同时,采用弹性权重固化策略[11],间接保持较小训练集经验误差,自适应地学习有利于目标信号实现语音分离的变换域。因此,设计代价函数为


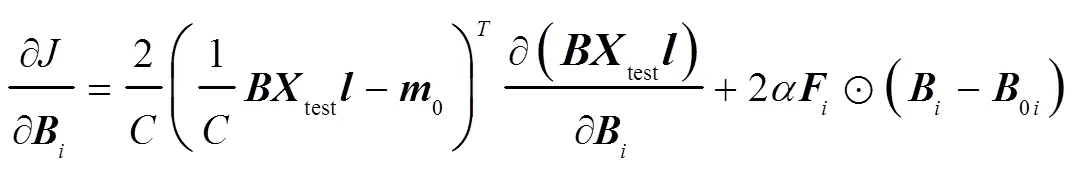



若不引入费雪信息,式(5)的最后一项是Frobenius范数正则化约束,此时式(5)可改写为


2.3 噪声信号在特征空间上的均值偏移
为探究噪声信号在特征空间上的均值偏移,本文从Nonspeech数据集中选取8种不同的噪声数据[19],与语音信号生成8个测试集,每个测试集的样本个数和所采用的语音信号皆相同。计算每个测试集的噪声特征至训练集噪声特征中心的平均偏差为

8种不同噪声特征至训练集噪声特征中心的平均偏差如图2所示。
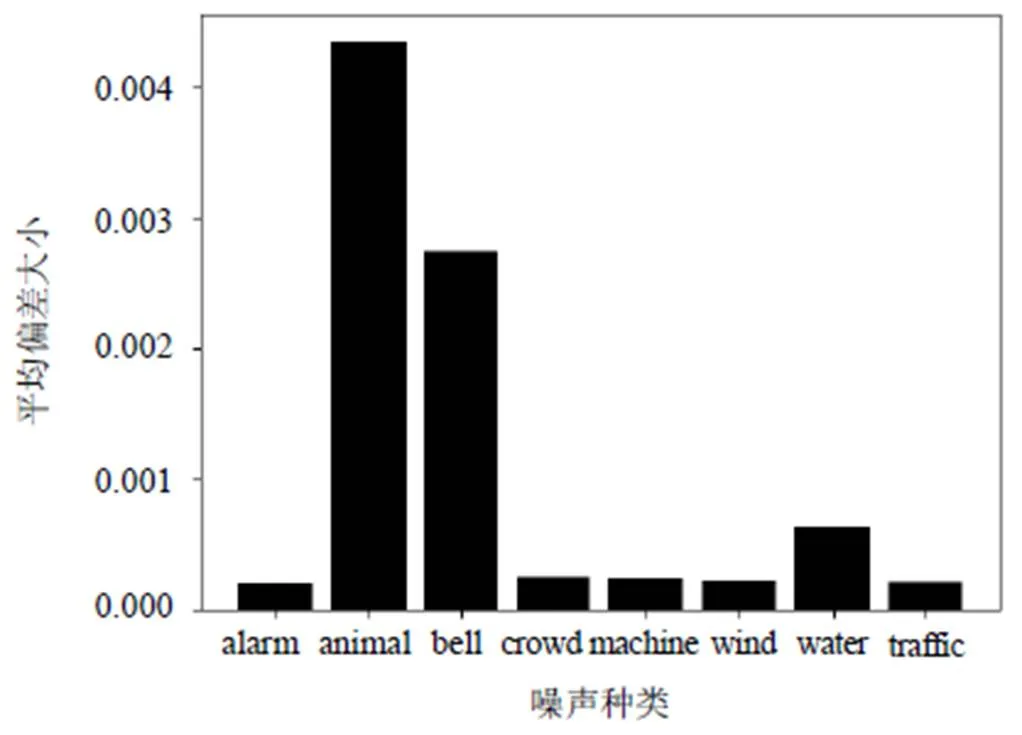
图2 8种不同噪声特征至训练集噪声特征中心的平均偏差
由图2可知:animal和bell这2种噪声的编码特征偏离训练数据均值中心0的程度非常明显,给语音分离模型带来较大的泛化风险;而另外6种噪声的编码特征偏离均值中心比较小,可见并非所有的噪声都会在特征空间上带来严重的均值偏差。因此,需要设置1个阈值,只有满足阈值要求的测试信号才会触发参数更新。
2.4 参数更新触发条件
本文采用变换域特征的均值偏移来度量预测不确定性。针对不确定性较大的测试数据,将进行参数的动态调整。因此,设置了1个不确定性阈值,计算公式为

当测试信号的值大于,通过式(8)或式(10)对编码器2的参数进行更新。
3 实验及参数分析
3.1 实验设置
实验采用的深度学习框架为Pytorch,服务器CPU为8核3.90 GHz AMD Ryzen 3700X,内存为 32 GB,GPU为Nvidia RTX 2080 Ti。
本文采用公开的语音数据集LibriSpeech[20],噪声数据集NoiseX[21]和Nonspeech[19]进行实验。为方便网络训练,所有数据统一采样率为8 kHz。本文的语音数据全部来自于LibriSpeech数据集中的“train-clean-100”子集,该子集包含了100 h来自251个不同个体的语音数据。首先,取任意2个不同说话人的语音以-2.5 dB~2.5 dB的任意比例混合,得到干净的2个说话人的混合数据;然后,选取NoiseX数据集中的10种噪声生成训练集数据,同时将Nonspeech数据集中的8种噪声生成测试集数据,详情如表2所示。其中,噪声与说话人声按-5 dB~10 dB的任意信噪比混合,训练集的样本个数为8000,测试集中每种噪声数据的样本个数为3000。

表2 噪声数据集
3.2 实验结果
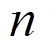

表3 4种方法的分离性能比较
由表3可知:1) BPU取得了比单链路更好的分离性能,说明双链路网络方法是有效的;2) FNR和FIW-FNR方法获得的SI-SNR指标高于BPU,其中FIW-FNR是4种方法中分离性能最好的,可见本文提出的参数更新方法可以改善模型的分离性能。
3.3 参数分析

表4 取不同值时,3种方法的SI-SNR指标
表5 取不同值时,3种方法的SI-SNR指标
3.4 运行效率
针对每一条测试信号,本文提出的基于不确定性感知的语音分离方法都可以通过式(8)或式(10)闭式更新噪声编码网络参数,而无需经过反向梯度传播,从而保证了模型的运行效率。经过测试1000条数据,FIW-FNR方法平均处理一条测试信号的时间约为(0.150.01) s(每条数据长度为5 s)。
4 结语
为减小噪声的干扰,本文提出一种基于不确定性感知的语音分离方法。针对每一条测试信号,自适应更新噪声编码网络的参数,减小噪声带来的均值偏移,并尽量保持重要参数不变,间接限制语音分离的经验误差。该方法具有闭式解,执行效率高,能够快速调整编码网络参数,增强语音分离模型对环境噪声的泛化能力。
[1] BELL A J, SEJNOWSKI T J. An information-maximization approach to blind separation and blind deconvolution[J]. Neural Computation, 1995,7(6):1129-1159.
[2] WANG D L, BROWN G J. Computational auditory scene analysis: principles, algorithms, and applications[J]. IEEE Trans. Neural Networks, 2008,19(1):199.
[3] LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401(6755):788-791.
[4] 李煦,屠明,吴超,等.基于NMF和FCRF的单通道语音分离[J].清华大学学报(自然科学版),2017,57(1):84-88.
[5] WANG D L, CHEN J. Supervised speech separation based on deep learning: an overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018,26(10):1702-1726.
[6] 刘文举,聂帅,梁山,等.基于深度学习语音分离技术的研究现状与进展[J].自动化学报,2016,42(6):819-833.
[7] MA C, LI D, JIAN X. Two-stage model and optimal SI-SNR for monaural multi-speaker speech separation in noisy environment[J]. arXiv preprint arXiv: 2004.06332, 2020.
[8] LIU Y, DELARIA M, WANG D L. Deep casa for talker- independent monaural speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020: 6354-6358.
[9] WANG X, DU J, CRISTIAN A, et al. A study of child speech extraction using joint speech enhancement and separation in realistic conditions[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 7304-7308.
[10] WU Y K, TUAN C I, LEE H Y, et al. SADDEL: Joint Speech separation and denoising model based on multitask learning[J]. arXiv preprint arXiv: 2005.09966, 2020.
[11] KIRKPATRICK J, PASCANU R, RABINOWITZ N, et al. Overcoming catastrophic forgetting in neural networks[J]. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521-3526.
[12] LUO Y, CHEN Z, YOSHIOKA T. Dual-Path RNN: efficient long sequence modeling for time-domain single-channel speech separation[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020:46-50.
[13] LUO Y, MESGARANI N. Conv-tasnet: surpassing ideal time- frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(8): 1256-1266.
[14] ROUX J L, WISDOM S, ERDOGAN H, et al. SDR half-baked or well done[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019: 626-630.
[15] LUO Y, CHEN Z, MESGARANI N. Speaker-independent speech separation with deep attractor network[J]. IEEE/ACM Transactions on Audio Speech & Language Processing, 2018, 26(4):787-796.
[16] TAGASOVSKA N, LOPEZ-PAZ D. Single-model uncertainties for deep learning[C]. In Advances in Neural Information Processing Systems, 2019: 6414-6425.
[17] WELLING M, YEE W T. Bayesian learning via stochastic gradient Langevin dynamics[C]. Proceedings of the International Conference on Machine Learning (ICASSP), 2011: 681-688.
[18] GAL Y, GHAHRAMANI Z. Dropout as a Bayesian approximation: representing model uncertainty in deep learning[C]. Proceedings of the International Conference on Machine Learning (ICML), 2016: 1050-1059.
[19] HU G, WANG D L. A tandem algorithm for pitch estimation and voiced speech segregation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010,18(8): 2067-2079.
[20] PANAYIOTOU V, CHEN G, POKEY D, et al. LibriSpeech: an ASR corpus based on public domain audio books[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015: 5206-5210.
[21] VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ii.noisex-92: A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993,12(3): 247-251.
Speech Separation Method Based on Uncertainty Perception
Tu Binwei Lü Jun
(School of Automation, Guangdong University of Technology, Guangzhou 510006, China)
In order to resist the disturbances of noises, we proposed a speech separation method based on uncertainty perception. In the training phase, a two-link architecture is adopted to learn the codec subnet and separate subnet of noise and speech source components respectively. In the testing phase, the noise coding subnet is updated adaptively in the form of closed solution, so as to reduce the mean deviation of training and testing noises in the feature space, reduce cognitive uncertainty, keep the important parameters unchanged as far as possible, and indirectly limit the empirical error of speech separation. Experimental results on the public datasets LibriSpeech, NoiseX and NonSpeech show that the proposed approach can rapidly and effectively improve the scale-invariant source-to-noise ratio of speech separation under the interferences of unknown noises.
speech separation; noise interference; uncertainty perception
TN912
A
1674-2605(2021)01-0008-06
10.3969/j.issn.1674-2605.2021.01.008
广东省自然科学基金(2018A030313306)
涂斌炜,男,1995年生,硕士研究生,主要研究方向:机器学习,语音分离。E-mail: tubinwei@mail2.gdut.edu.cn
吕俊(通信作者),男,1979年生,博士,副研究员,主要研究方向:生物信号检测与识别。E-mail: lujun.rylj@gmail.com
