基于微调语义分割模型的街景影像变化检测方法
2021-03-12李文国左小清王译著
李文国,黄 亮,2,左小清,王译著
(1.昆明理工大学国土资源工程学院;2.云南省高校高原山区空间信息测绘技术应用工程研究中心,云南昆明 650093)
0 引言
街景是沿着城市道路拍摄的序列全景影像,记录了房屋建筑、市政设施以及交通标志等丰富内容[1]。信息技术的发展使数码相机、手机相机等图像采集设备得以广泛使用,积累了海量的街景影像。车载移动式街景测绘系统或固定的街景测绘系统使街景影像采集更加方便、快捷。街景影像不仅覆盖城市绝大部分区域,而且包含丰富的城市特征,能提供真实的三维城市场景,具有极高的应用价值。2007 年谷歌推出了街景影像服务,服务范围不断扩大,应用实例愈加丰富,推动了街景影像与地理空间信息的整合发展,随后百度和高德也相继开发出全景地图。全景地图由真实场景构建生成,通过图像绘制技术提供360°观察视角,从而增强沉浸感,使用户如同置身于真实场景一般[2]。全景地图由街景影像构建而成,由于近距离拍摄能真实还原拍摄街景场景,所以具有拍摄速度快、数据量小、容易存储和传输等优点。在交通管理、城市规划建设、商业广告、旅游等领域全景地图应用较多。相对于传统电子地图,全景地图不仅能全方位展示真实地图场景,而且能实现更快速和更精度的定位。物联网、云计算等新一代信息技术发展不断推动智慧城市形成,智慧城市需要三维立体地表达城市场景,单纯使用立体线框模型和贴图难以表达真实城市场景。街景影像可以全方位、连续地呈现真实城市环境,形成全新的三维空间立体效果,因此在智慧城市地理信息公共服务中应用广泛。
影像变化检测研究目的是根据对同一物体或现象在不同时间的观测,确定不同的处理过程,即找出感兴趣的变化信息,滤除不相干变化信息[3-4]。遥感影像具有宏观性、客观性、周期性、便捷性等特点,常作为变化检测的主要数据来源。自动和半自动化的多时像遥感影像变化检测技术已广泛应用于土地调查、城市研究、生态系统检测、灾害检测评估以及军事侦查等领域[5-11]。
国际摄影测量与遥感学会(The International Society for Photogrammetry and Remote Sensing,ISPRS)为遥感影像变化检测研究设置专项工作组,致力于推动利用遥感技术手段进行多领域变化检测发展[12]。我国政府也高度重视遥感变化检测技术在地理国情监测中的应用,从2010 年开始国土资源部每年开展全国土地遥感监测工作,利用多时相遥感影像变化检测技术持续更新全国土地调查成果[13]。虽然遥感变化检测技术研究已取得丰硕成果,但许多变化检测方法依赖于人工参与,如几何配准、辐射校正和遥感目视解译等均需人工参与才能达到较高精度。相比遥感影像,街景影像具有以下特点:①街景影像在地面成像,受大气干扰较小,与遥感影像相比,无需辐射校正;②街景影像成像距离短,街景影像分辨率高,同时地物边界清晰,因此相比遥感影像更加容易配准;③街景影像视角与人类视角类似,目视解译难度低甚至无需目视解译;④遥感影像从空中对地表观测,因此遥感影像以平面的方式观测地物信息,而街景影像则从地面成像,能立面观测地物信息;⑤街景影像采集设备和方式多种多样,使街景影像成像方式更加方便、快捷。综合而言,街景影像可提供新视角、更为详尽的信息和更便捷的预处理方式。
街景语义分割研究较为丰富,但对多时相街景影像进行变化检测的研究则相对较少。文献[14]提出了基于BOVW 模型的场景变化检测方法,并对比分析了不同字典构建方法对最终结果的影响;为了解决独立分析引起的误差累计问题,文献[15]提出核化慢特征分析方法,并通过贝叶斯理论融合场景变化概率和场景分类概率;文献[16-17]提出利用二维图像进行场景变化检测。该方法根据不同时间段获取的图像对场景进行建模,然后与基于其他时间段图像建立的模型进行差异对比。但该类方法仅针对拍摄视角一致的图像,不同视角拍摄的图像则无法处理;文献[18-21]将场景变化检测转换为三维领域的问题。这类方法首先建立稳定持续的目标场景模型,然后将查询图像与目标图像进行比较以检测变化。但不同区域城市环境差异较大,因此场景模型并不适合其他地区。近年来,深度学习在计算机视觉领域表现优异,在自动驾驶、人机交互、医学等方面有诸多应用,也有学者利用深度学习进行场景变化检测。文献[22]提出结合CNN 和超像素方法对街景进行变化检测。该方法利用CNN 网络提取多时像影像特征,然后将不同时像的特征图进行对比形成差异图,再结合超像素形成的差异图构建整幅图像的差异图,最后去除天空和建筑,得到建筑物变化检测结果。但CNN网络由于不断将特征图下采样,导致小尺度地物特征丢失,因此CNN 网络不适合街景影像特征提取。
综上所述,三维建模方法不具有普适性,而传统卷积神经网络由于特征图分辨率不断变小的原因,会丢失小尺度地物。近年来,在CNN 网络的基础上衍生出许多性能优秀的神经网络,本文针对街景影像特点,研究适用于街景影像变化检测的神经网络。首先引入对小尺度地物具有很好识别能力的DeeplabV3+网络模型,并对该网络进行微调,然后将其用于街景影像分类,接着对分类结果进行CVA 运算得到差异影像,最后对差异影像进行二值化与精度评价。
1 研究方法
本文提出基于Deeplabv3+的街景影像变化检测方法。方法架构包括3 个部分:①采用微调的DeeplabV3+训练模型分类;②采用CVA 获取差异影像;③差异影像二值化和精度评价。具体而言,首先将两幅不同时像的街景数据输入到微调的DeeplabV3+训练模型得到分类图,然后将此分类图进行CVA 运算得到差异图,最后将差异图二值化并进行精度评价,流程如图1 所示。

Fig.1 Change detection process图1 变化检测流程
1.1 街景影像语义分割
现有语义分割网络较为丰富,如U-Net、ICNet、PSPNet、HRNet、Segnet、Deeplab 系列。其 中,于2018 年提出的DeeplabV3+网络是目前Deeplab 网络系列中性能最优的网络,DeeplabV3+结合了空洞卷积与ASPP(Atrous Spa⁃tial Pyramid Pooling),与传统卷积相比,DeeplabV3+网络可保持特征图分辨率不变,对尺寸小的地物具有很好的识别能力,且能够较好地保留边缘细节信息。DeeplabV3+网络在PASCAL VOC 2012 数据集上取得新的最佳表现,mIoU=89.0,验证了Deeplabv3+的优秀性能[23]。
DeeplabV3+网络由编码和解码两部分组成,编码模块由特征提取网络与ASPP 组成。其中特征提取网络可以选用目前特征提取效果优秀的网络,特征提取网络性能决定了DeeplabV3+网络分类精度,因此选取性能优秀的特征提取网络至关重要。本文设计不同特征网络下DeeplabV3+网络性能对比实验,将特征网络为VGG 的DeeplabV3+网络和Xception 的DeeplabV3+网络进行对比,实验采用相同的训练方式,训练完成后将训练模型用于街景影像分类,分类结果如图2 所示,从分类结果可以看出特征提取网络为Xception 的DeeplabV3+网络具有更优秀的性能,因此本文选取Xception 网络为特征提取网络。

Fig.2 Classification results of Deep lab V3+networks with different feature extraction networks图2 不同特征提取网络的DeeplabV3+网络分类结果
ASPP 由4 种不同空洞率的卷积层和全局平均池化层组成,将4 种卷积后的特征图和全局平均池化后的特征图合并作为ASPP 的输出。空洞卷积用于扩大特征图的感受野,提高小尺寸地物识别能力。全局平均池化层则防止过拟合,同时提取鲁棒性强的特征。由于空洞卷积对小尺寸地物无法重建,同时会丢失空间层级信息,因此对ASPP 结构进行微调,将Xception 输出的特征图与ASPP 输出的特征图进行合并,这样做有利于小尺寸地物重建,并加入空间层级信息,微调后的DeeplabV3+网络结构如图3 所示。
本文首先制作39 幅街景影像标签用于微调后的Deep⁃labV3+网络训练,然后将训练模型用于街景影像分类,分类结果如图4(a)所示,可看出训练模型分类性能极差,原因在于深度学习需要大量优质的标签,但制作标签需要大量时间。考虑到时间成本,同时目前有许多公开的街景数据可供使用,如Cityspaces 数据集和Camvid 数据集,Camvid 数据集场景与本文使用的街景数据场景类似,因此本文将街景数据与Camvid 数据集联合用于DeeplabV3+网络训练,然后将训练模型用于街景影像分类,分类结果如图4(b)所示,从分类结果可以看出混合数据训练得到的训练模型分类性能远优于街景数据训练得到的训练模型。
1.2 差异影像获取与二值化
为了获取两期街景影像语义分割结果的变化区域,本文采用CVA 方法。CVA 是一种常用的多波段影像差异分析方法,每个像元特征采用向量的方式表示,对应为每个波段的一维列向量。由于本文数据集为3 个波段,初始化n=3。设时相t1和时相t2中像元灰度矢量为G=,其中g1,2,3和h1,2,3对应图像的3 个通道,(t1)和(t2)分别是时相t1和时相t2第1 波段中第i行、第j列像元灰度。
对时相t1和时相t2进行差值计算,得到每个像元变化值,即为变化矢量Δ,公式为:

Δ包含两期图像中所有像元变化信息,其变化强度用欧式距离‖Δ‖表示,以此可以生成两期影像变化强度图。
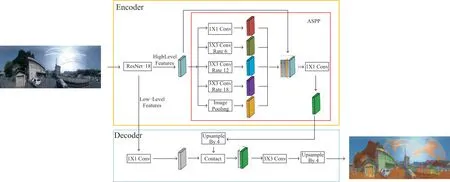
Fig.3 DeeplabV3+network structure图3 DeeplabV3+网络结构

Fig.4 Training model classification results of street view image data set and joint data set图4 街景影像数据集与联合数据集训练模型分类结果
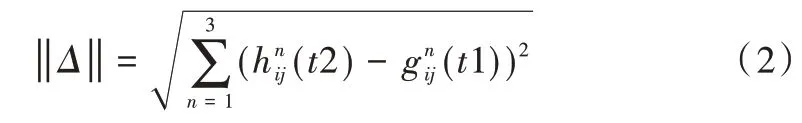
其中,‖Δ‖表示是全部像元灰度差异,当‖Δ‖越大,变化可能性越大。因此可通过确定变化强度大小选择分割最佳阈值,从而分割变化像元和非变化像元。
实验在获取差异影像后,将差异影像像素分为两种类型:一种为0 值,代表未变化区域;另一种为非0 值,代表变化区域。然后将差异影像中为0 值的像素更改为255,将差异影像中非0 值像素更改为0,该过程即为二值化。二值化后黑色像素代表变化区域,白色像素代表未变化区域。
1.3 精度评价
本文采用3 种客观评价指标:错检率(False Negatives Rate,FPR)、漏检率(False Positives Rate,FPR)和正确率(Percentage Correct Classification,PCC),其中错检率计算公式为:

其中,TN 代表非变化区域正确的分类个数,TP 代表变化区域正确的分类个数,FN 代表漏检数,FP 代表错检数。漏检率计算公式为:
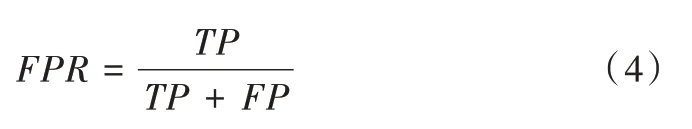
正确率计算公式为:
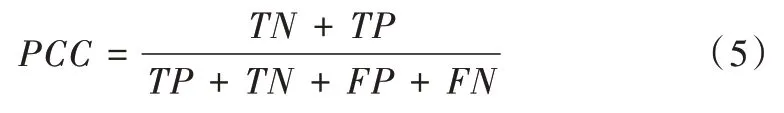
2 实验结果与分析
2.1 数据介绍
本文采用的街景数据集为TSUNAMI 数据集,TSUNA⁃MI 数据集来源于文献[24],是日本某地区海啸前后的全景街区影像。实验选取的两组街景影像及参考图如图5 所示,两组影像均为1 024 像素×224 像素,对两组街景影像分别命名为G1 和G2,其中t0 代表变化前影像,t1 代表变化后影像,G1 组t0 和t1 影像分别如图5(a)、(b)所示,G2 组t0 和t1 影像分别如图5(c)、(d)所示,G1 和G2 参考图分别如图5(e)、(f)。G1 组影像的变化区域像素为50 242,非变化区域像素为179 134;G2 组影像变化区域像素为55 052,非变化区域像素为174 324。从每组数据两幅不同时刻的影像中看出建筑物尺度变化范围大,远处建筑物边界十分模糊,在阴影地方建筑物与植被界限混淆在一起;同时车辆及电杆等地物也存在尺度范围变化大、与周围地物界限模糊的问题,因为不同天气的原因天空像素不均,高亮区域和灰暗区域同时存在。

Fig.5 Street images and reference figures of G1 and G2图5 G1 和G2 街景影像及参考图
2.2 实验设计
为验证本文方法在街景影像变化检测中的有效性,将该方法与OTSU[25]和K 均值[26]进行对比。实验分别对G1和G2 两组影像进行变化检测。G1 和G2 两组影像采用OT⁃SU 方法得到的结果如图6(a)、(b)所示,采用K 均值方法得到结果图如图6(c)、(d)所示,本文方法结果图如图6(e)、(f)所示。实验结果精度如表1 所示。

Fig.6 Experiment results of the first group图6 第一组对比实验结果

Table 1 Accuracy comparison of experimental results表1 实验结果精度对比
OTSU 将图像分割为两类,阈值由类间方差求出,因此OTSU 不适用于地物类别丰富的影像。影像光谱信息越简单,分辨率越低,OTSU 得到的效果越好。从差异图可以看出,OTSU 在天空、道路和植被等区域均存在大量错检,由此可以看出OTSU 不能处理光谱信息多样的街景影像。K均值错检区域少于OTSU,但依旧在天空和道路等区域存在大量错检,这源于K 均值聚类时,同物异谱的地物会聚类形成多种类别,因此造成错检。由此可以看出K 均值不适合高分辨率的街景影像。相比OTSU 和K 均值,本文方法对天空和道路的错检远少于这两种方法,本文方法可针对同物异谱现象,有效提取地物特征和影像空间信息。从G1和G2 两组数据的差异图中可以看出天空和道路等类别错检区域很少,这是因为本文方法提取的地物类别特征具有很好的鲁棒性,在具有相同地物的影像上能产生相似的分类效果,这是OTSU 和K 均值不具有的优点。
本文方法由Camvid 数据集和街景数据集混合训练得到,这两个数据集虽然都是拍摄于城市场景,但属于不同国家的城市,因此两个数据集存在差异,如街景数据级天空在影像中占比大,而Camvid 数据集建筑占比大。本文方法在两个数据集上都表现出良好的分类性能,因此说明本文方法具有很好的泛化能力。
从精度评价结果来看,本文方法得到的总体精度比OTSU 分别高39%和41%,比K 均值分别高32%和29%。但由于训练数据中街景样本只有39 幅,而Camvid 数据集总有701 幅,样本不平衡导致街景样本训练不充分,本文方法得到的精度仅大于70%,精度还有待提升。加入更多的街景训练样本,或改善DeeplabV3+网络损失函数平衡样本,会得到更好的训练结果及精度。
综上所述,本文方法相比OTSU 和K 均值,可适用于高分辨率、地物多样和光谱信息复杂的街景影像变化检测,同时本文方法具有较强的鲁棒性和泛化能力。
3 结语
本文针对多时相街景影像变化检测,提出了一种微调的DeeplabV3+网络模型变化检测方法。设计两组对比实验验证该方法,实验结果表明,本文方法精度比传统统计方法、机器学习方法提升25%以上。实验利用混合样本训练方法对街景数据进行分类,但这种未经过大量街景样本训练的神经网络分类和泛化能力有待加强,后续可对数据集街景数据加入大量标注样本,重新测试从而改进网络。
