基于深度迁移学习的苹果叶病识别方法研究*
2021-03-11吴蔚
吴 蔚
(泰山学院 信息科学技术学院,山东 泰安 271000)
苹果因其重要的营养价值和经济价值,成为世界上最重要的水果作物之一。在中国,苹果的种植面积和经济产量位居世界前列,且有逐年增加的趋势。然而,苹果叶部时常遭受病虫害侵袭,而叶子状态常常是植物健康的晴雨表,很多病症的发展最初往往源于叶部。因此,对于苹果叶部病虫害种类进行及时有效识别,从而采取针对性措施进行防治,是保持苹果产量和质量进一步增长的重要举措之一,具有重要的经济价值和现实意义。
过去识别苹果叶部病虫害的方法主要通过专家诊断或者请教有经验的农民。然而,专家咨询可能存在花费高且缺乏时效性的缺点。而最有经验的农民由于其个体的局限性,也不能保证准确识别出所有叶部病虫害种类。因此,在智慧农业的背景下,由传统农业中完全依靠人力辅助转为借助机器智能的方式进行叶部病虫害识别,成为推动苹果产业增量增产的新趋势。前几年主要采用传统机器学习的方法进行叶病种类识别。该类方法主要通过手工的方式提取及处理不同病虫害种类的叶部形状、颜色、纹理等特征,然后采用诸如K-means、支持向量机(Support Vector Machines,SVM)、贝叶斯等方法实现分类。例如王建玺等[1]采用叶部病灶部位的颜色差异和边界轮廓追踪算法提取出病灶区域,然后采用SVM方法进行种类识别。李超等[2]提出一种基于特征融合和局部特征映射的方法识别苹果叶病种类,识别率高达96%。Sivakamasundari等[3]将RGB格式的图片转化为HSV格式的颜色空间并进行叶部病灶区域的颜色特征提取,得到的特征通过分割成相同大小的区域后进行纹理特征分析,之后输入到SVM分类器进行识别。该方法在苹果叶部病虫害种类识别的精度和计算效率上都得到提升。传统机器学习方法的分类精度很大程度上依赖于手工设计特征的优劣,在一些具有复杂背景的高噪音环境下的图像识别效果却会大打折扣。
深度学习属于机器学习领域的范畴,然而该技术更强调通过构建“深层”的网络结构,借助卷积的操作方式来强化对数据的非线性表达能力。相比传统的机器学习方法,深度学习具有更优秀的特征学习能力,即使在处理复杂图像的分类问题时仍然展现出高效的识别效果。随着机器学习的不断发展,深度学习技术逐渐在计算机视觉领域获得极大的突破,并被迅速而广泛应用到植物病虫害的识别和诊断中,其中就包括在苹果叶病识别领域的成功应用。比如Liu等[4]提出了一种基于AlexNet和GoogLeNet的深度网络模型用于苹果叶病诊断,识别准确率达到97.62%,高于传统的机器学习方法。Zhang等[5]将传统的深度网络结构中最后的全连接层替换为全局平均池化层进行苹果叶病识别,克服了过拟合的问题,提升了模型训练效率和识别准确率。
深度学习之所以能够获得成功,主要得益于大数据技术的发展以及设备计算能力的提升。一个典型的深度学习框架需要构建深度网络结构,并输入大量带标签的数据对海量网络参数进行调节,此即通常所说的“调参”或者“学习”过程。然而在实际的植物病虫害识别场景中,有些种类的数据往往不易获取,导致训练样本数量过少或者不同种类数据的分布不均,往往造成训练的模型过拟合或者无法快速有效收敛。因此在数据量较少或数据分布不均的情况下,仍使训练模型保持较高的识别准确率,是决定深度学习技术能否在具体应用领域进一步推广的关键。受到人类学习特点的启发,迁移学习技术可以有效解决小样本的问题。众所周知,人类认识新物体并不需要大量的数据加以训练,往往少量的几张图片就可以获取准确的辨别能力。这得益于人类对已有知识的总结、凝练,并运用到新知识的学习中,此即所谓人类的迁移学习能力。
本研究过程中,提出了一种基于深度迁移学习的苹果叶病识别方法,将迁移学习应用到基于Inception V3的特征提取网络结构中,并通过改进损失函数的方式,实现了对苹果叶病种类的准确识别效果。
1 相关理论
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习在图像分类和识别中获得突破性成果的重要基石。区别于传统机器学习手工设计特征的方式,基于CNN的神经网络结构能够实现端到端的自动特征提取。典型的CNN架构主要包括卷积层、池化层和全连接层。
1.1.1 卷积层
卷积层通过卷积核对输入特征进行卷积运算,并加上一个偏差值得到输出结果。卷积层的模型参数包括卷积核部分和偏差值部分。可以通过多个卷积层的叠加设计不同复杂程度的卷积网络。第i层卷积网络的特征输出yi可表示为:
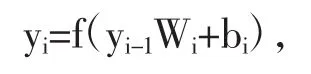
其中Wi表示第i层卷积核的权重;bi表示标准偏差;yi-1表示卷积层的特征输入(y0表示输入图像);f表示激活函数。
1.1.2 池化层
池化层的功能是减轻卷积层对位置的过度敏感性,从而使得模型对不同位置的同一物体也具备良好的识别能力。常用的池化方法有最大池化法和平均池化法,分别计算池化窗口内的最大值和平均值。第s层池化层的第j个池化区域的特征输出可表示为:
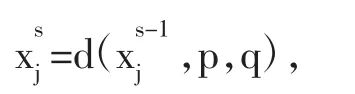
1.1.3 全连接层
经过深层网络的特征提取后,通常连接一层或多层全连接层进行图像分类任务。最后的输出层通常采用softmax函数将输出值变换成值为正且和为1的概率分布。第j个输出结果Oj可表示为:
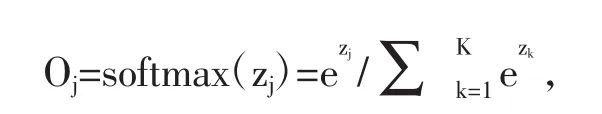
其中j∈{1,…,K},K表示最后一个连接层的输出个数;z代表示最后一个连接层的输出向量。
1.2 迁移学习
普通的深度学习模型是针对特定数据或者任务进行训练,当这些数据或任务变化时,学习到的模型通常具有较差的泛化性,需要重新进行模型训练。然而,很多时候模型学习到的知识可以被相似的任务重复利用。迁移学习就是研究如何对已学知识进行重用,从而避免模型从头训练,提升模型的训练效率和稳定性的技术。
一种典型的迁移学习方法是从预训练的模型中进行知识迁移。该方法首先通过大量的与目标任务相关的数据对网络模型进行预训练,学习到的模型参数即知识被保存下来。基于这些学到的知识再对目标数据集进行参数微调,从而学习到新数据集的知识信息。
2 研究方法
本研究提出一种基于深度迁移学习的苹果叶病识别方法,接下来从数据集、特征提取模块、迁移学习以及损失函数几个方面分别加以介绍。
2.1 数据集
本研究中选用的苹果叶病图片数据集来源于AIChallenger-Plant-Disease-Recognition(https://challenger.ai/),包括健康型、一般黑星病、严重黑星病、灰斑病、一般雪松锈病、严重雪松锈病共六种类型,对应的标签编号为0到5。将标签值转化为one-hot向量方式,以对应神经网络最后一层的输出。对于原始标签i,转化后的one-hot向量形式的标签长度为6,且第i个元素的值为1,其余值为0。比如一般黑星病类型的原始标签值为1,转化为 one-hot形式后的标签为[0,1,0,0,0,0]。
为了降低模型训练时由于数据量少造成过拟合的风险,本研究采用随机旋转、随机裁剪、随机颜色变化并对图像每个通道做标准化的方式进行数据预处理,处理后的数据共包含8169张图片,数据分布比例如图1所示,可以看出不同种类叶病图片的比例分布是不均衡的,后文将提出具体解决方法。
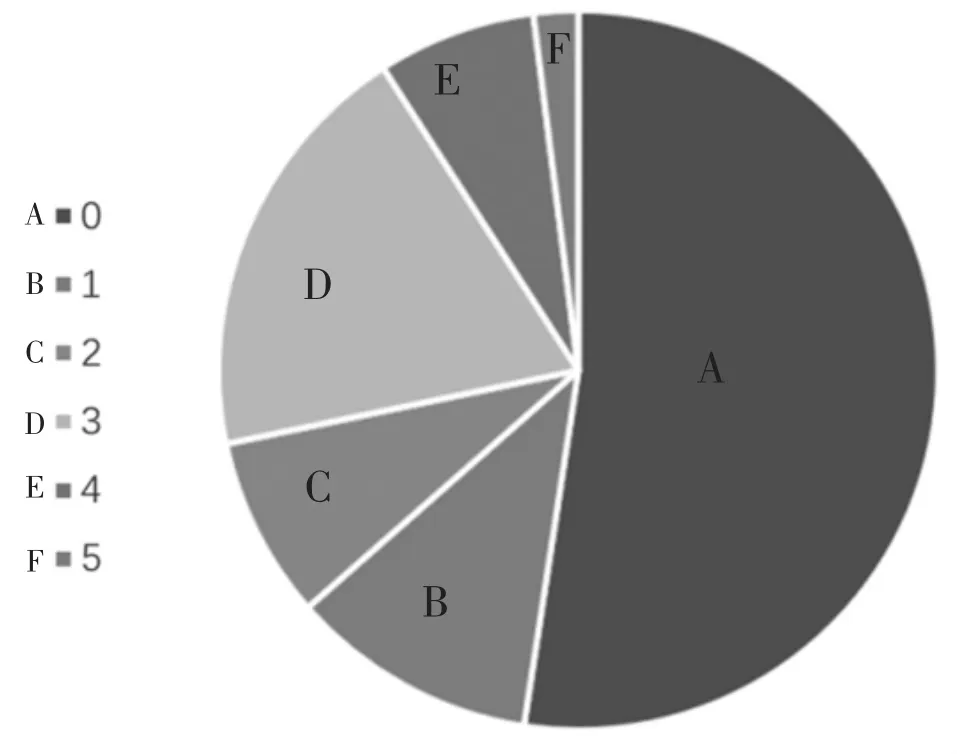
图1 苹果叶病数据分布
2.2 特征提取模块
本研究使用Inception V3模型[6]对输入图像数据进行特征提取。该模型使用的Inception模块组不像之前大多流行的CNN一样仅仅追求网络的深度,而是对网络的宽度和深度进行了均衡设计,增强了不同位置和大小信息的特征表达能力。同时它减少了全连接层的使用,并通过将较大的n×n卷积核尺寸分解为不对称的n×1和1×n两种卷积的方式,降低了模型的参数量,提升了模型运算和存储效率。
2.3 迁移学习策略
本研究对基于Inception V3的网络模型采取迁移学习的策略进行苹果叶病识别的训练。其主要分为以下步骤:
(1)首先将Inception V3模型的线性连接层之前的网络层定义为瓶颈层。提取使用公开数据集ImageNet进行预训练的瓶颈层网络参数,并在接下来的模型训练中保持固定不变。ImagetNet是一种大规模数据集,可以使网络模型学习到物体的几何、形状、姿态等低层次信息,从而增强网络识别的泛化能力。
(2)瓶颈层后面接上全连接层,使用苹果叶病图像数据作为模型的输入,训练一个新的全连接神经网络用于叶病种类的识别。网络模型基于已学到的底层特征识别能力对叶病种类识别进行参数微调,可以更快速准确地掌握新数据的识别能力。
2.4 损失函数
损失函数用来衡量网络模型预测的结果和真实标签之间的差异,并通过反向传播的方式更新模型参数以降低预测误差。在分类任务中最常用的是交叉熵损失函数,可定义为:
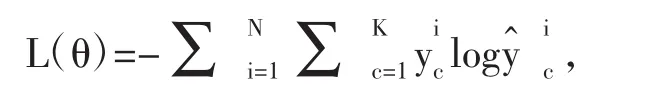
其中θ表示模型训练的参数;N表示训练样本数量;K表示分类总数目;y和分别表示真实标签和模型预测结果,且均为矢量表示第i个样本对应的真实标签中第c个标量值,表示第i个样本预测的结果中第c个标量值。
针对不同苹果叶病类型的数据分布不均衡且数据规模不大的特点,本文提出引入焦点损失[7]的方法对交叉熵损失函数进行改进,最终使用的损失函数为:
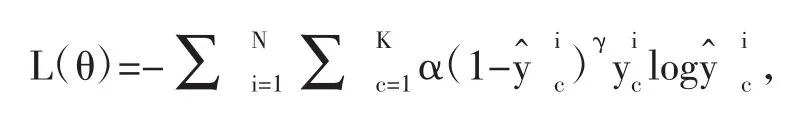
其中平衡因子α用于控制不同类别数据分布不均衡的问题;γ用于降低易区分样本的预测损失,提升难识别样本的重要性,从而使得模型训练时更好地挖掘数据中隐藏的重要信息。
3 实验结果及分析
为了验证本研究算法的有效性,进行了相关实验。输入图片大小固定为128×128,模型训练均采用小批量随机梯度下降算法进行损失函数优化,学习率初始化为0.001。针对苹果叶病数据集中占比较小的严重黑星病、一般雪松锈病和严重雪松锈病三种类型的焦点损失函数平衡因子α设置为0.25,其余类别设置为0.75,γ统一设置为2。
图2展示了使用迁移学习和使用随机参数进行苹果叶病类型识别训练的准确率和验证准确率对比折线图。可以看出迁移学习基于已学到的知识进行训练,可以使模型更快速地收敛,且模型训练准确率和验证准确率均更高,验证了迁移学习策略在苹果叶病种类识别的有效性。
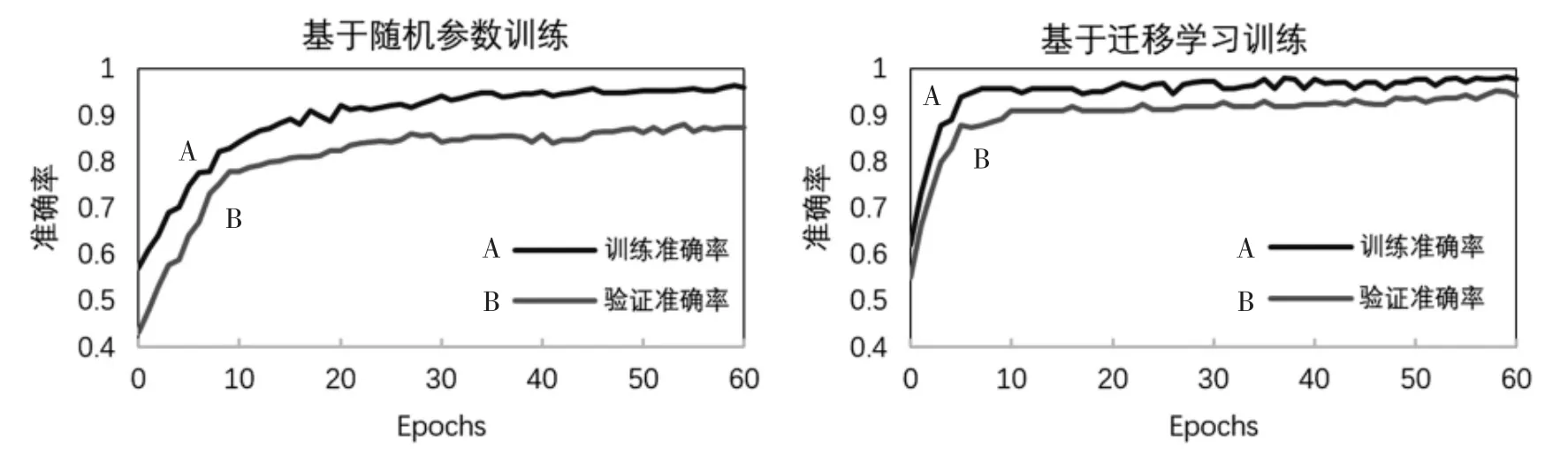
图2 基于随机参数和迁移学习的训练准确率和验证准确率对比
表1对使用普通交叉熵损失函数和焦点损失函数的苹果叶病测试集准确率进行了对比,实验中均使用迁移学习方法进行模型预训练。可以看出,使用焦点损失函数相比交叉熵损失函数的Top1准确率提升了0.927%,验证了损失函数改进后的网络模型分类准确率得到了有效提升。
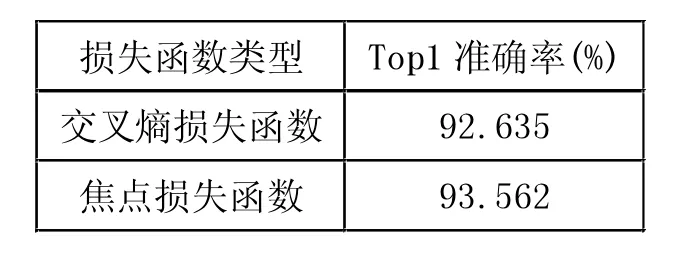
表1 基于交叉熵损失函数和焦点损失函数的分类准确率对比
4 结论
本研究基于深度迁移学习的策略,构建深度学习网络用于苹果叶病种类的识别,其准确率可达到93.5%以上,验证了迁移学习在苹果病虫害识别应用中的有效性和可行性。同时,针对数据分布不均衡的问题进行损失函数的改进,分类准确率进一步得到有效提升。未来将针对农作物中样本难以获取和标注成本高昂的问题继续开展迁移学习策略的研究。
