声纹识别技术在电力调度领域的应用研究
2021-03-10张敏单祖植张馨介蒋迪
张敏 单祖植 张馨介 蒋迪
(云南电网有限责任公司 云南省昆明市 650200)
电话语音通信作为所有电力调度机构最重要的调度指挥通信方式,调度指令下发或现场情况报送均高度依赖于电力调度语音系统。应用语音语义识别技术、声纹识别技术完成调控人员与现场人员的任务自动交互,使得调度软件系统也将由现在的被动静止结构转变为具有主动识别语音执行的智慧系统,让调度运行、信息检索更加人性化、智能化。因此需要开展对声纹识别技术在调度领域的研究与应用。
1 声纹识别的基本原理
声纹识别,生物识别技术的一种。也称为说话人识别,有两类,即说话人辨认和说话人确认。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官--舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。每个人的语音声学特征既有相对稳定性,又有变异性,不是绝对的、一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音。
声纹识别的主要任务包括:语音信号处理、声纹特征提取、声纹建模、声纹比对、判别决策等。而在系统应用中主要分为声纹注册阶段和声纹测试阶段。
在声纹注册阶段,每个可能的用户都会录制足够的语音然后进行说话人特征的提取,从而形成声纹模型库。这个模型库就像字典,所有可能的字都会在该字典中被收录。节目中的大合唱阶段就是声纹注册阶段。
在声纹测试阶段,测试者也会录制一定的语音,然后进行说话人特征提取,提取完成后,就会与声纹模型库中的所有注册者进行相似度计算。相似度最高的注册者即为机器认为的测试者身份。声纹识别的一般步骤如图1所示。

图1:声纹识别的一般步骤
1.1 声学特征提取
语音信号可以认为是一种短时平稳信号和长时非平稳信号,其长时的非平稳特性是由于发音器官的物理运动过程变化而产生的。从发音机理上来说,人在发出不同种类的声音时,声道的情况是不一样的,各种器官的相互作用,会形成不同的声道模型,而这种相互作用的变化所形成的不同发声差异是非线性的。但是,发声器官的运动又存在一定的惯性,所以在短时间内,我们认为语音信号还是可以当成平稳信号来处理,这个短时一般范围在10 到30 毫秒之间。
这个意思就是说语音信号的相关特征参数的分布规律在短时间(10-30ms)内可以认为是一致的,而在长时间来看则是有明显变化的。在数字信号处理时,一般而言我们都期望对平稳信号进行时频分析,从而提取特征。因此,在对语音信号进行特征提取的时候,我们会有一个20ms 左右的时间窗,在这个时间窗内我们认为语音信号是平稳的。然后以这个窗为单位在语音信号上进行滑动,每一个时间窗都可以提取出一个能够表征这个时间窗内信号的特征,从而就得到了语音信号的特征序列。这个过程,我们称之为声学特征提取。这个特征能够表征出在这个时间窗内的语音信号相关信息。如图2所示。

图2
这样,我们就能够将一段语音转化得到一个以帧为单位的特征序列。由于人在说话时的随机性,不可能得到两段完全一模一样的语音,即便是同一个人连续说同样的内容时,其语音时长和特性都不能完全一致。因此,一般而言每段语音得到的特征序列长度是不一样的。
在时间窗里采取的不同的信号处理方式,就会得到不同的特征,目前常用的特征有滤波器组fbank,梅尔频率倒谱系数MFCC 以及感知线性预测系数PLP 特征等。然而这些特征所含有的信息较为冗余,我们还需要进一步的方法将这些特征中所含有的说话人信息进行提纯。
1.2 说话人特征提取
在提取说话人特征的过程中通常采用经典的DNN-ivector 系统以及基于端到端深度神经网络的说话人特征(Dvector)提取系统。两套系统从不同的角度实现了对说话人特征的抓取。
1.2.1 算法1 DNN-ivector
目前被广泛采用的声纹识别系统。其主要特点就是将之前提取的声学特征通过按照一定的发声单元对齐后投影到一个较低的线性空间中,然后进行说话人信息的挖掘。直观上来说,可以理解成是在挖掘“不同的人在发同一个音时的区别是什么”。
首先采用大量的数据训练一个能够将声学特征很好的对应到某一发声单元的神经网络,如图3所示。
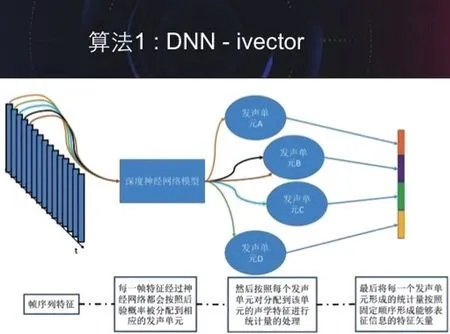
图3
这样,每一帧特征通过神经网络后,就会被分配到某一发声单元上去。然后,对每一句话在所有的发声单元进行逐个统计,按照每个发声单元没单位统计得到相应的信息。这样,对于每一句话就会得到一个高维的特征矢量。
在得到高维的特征矢量后,采用一种称之为total variability 的建模方法对高维特征进行建模:
M=m+Tw
其中m 是所有训练数据得到的均值超矢量,M 则是每一句话的超矢量,T 是奇通过大量数据训练得到的载荷空间矩阵,w 则是降维后得到的ivector 特征矢量,根据任务情况而言,一般取几百维。最后,对这个ivector 采用概率线性判别分析PLDA 建模,从而挖掘出说话人的信息。
1.2.2 算法2 基于端到端深度学习的说话人信息提取
如果说上一套方法还借鉴了一些语音学的知识(采用了语音识别中的发声单元分类网络),那么基于端到端深度学习的说话人信息提取则是一个纯粹的数据驱动的方式。通过海量数据样本以及非常深的卷积神经网络来让机器自动的去发掘声学特征中的说话人信息差异,从而提取出声学特征中的说话人信息表示。
首先通过海量的声纹数据训练一个深度卷积神经网络,其输出的类别就是说话人的ID,从而得到了能够有效表征说话人特性底座网络。在根据特定场景的任务进行自适应调优。具体过程如图4所示。
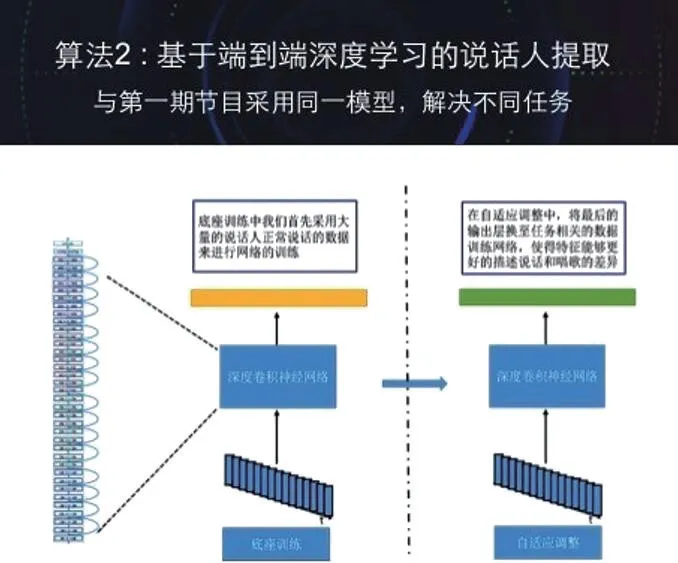
图4
在完成网络的训练后,得到了一个能够提取说话人差异信息的网络,每一句话通过该网络就得到了说话人的特征。
2 声纹识别的技术优势
2.1 先进的声音处理技术
领先业界的前后端语音处理技术,包括人声检测VAD 算法、语音降噪、快速语音增强算法、语音质量评估算法,有效保证注册和验证的效果。
2.2 先进的特征提取算法
使用学术界最先进的深度神经网络,以及端到端神经网络的训练方法,从大量样本中学习到高度抽象的音素特征,在相同的声纹数据中能提取更多的特征信息,并对噪声有很强的免疫力,大大提升算法准确率。
2.3 高准确率
在调度领域中,声纹识别一般使用长自由文本算法模型,在长自由文本模型下,EER 小于0.64%,准确率达98.1%以上。在1:N比对中,TOP1 命中率超过96.1%,在此种准确率前提下,可为调度应用提供最好的落地保障。如图5所示。

图5
2.4 高鲁棒性
调度领域应用中,检材都是五花八门,录音文件都可能使用各种不同的设备录制的,那么就需要考验声纹识别算法在不同噪声环境下的适应性、各种文本类型适应性、跨信道适应性上的表现,当具备了上述的优秀表现后,才保证了在不同应用场景下算法性能的稳定。图6 为在不同噪音下可以通过动态分数偏移的算法,保持了高鲁棒性。

图6
3 声纹识别在电力调度领域的应用展望
3.1 身份认证应用
相对于指纹、虹膜、人脸等识别技术,声纹在远程采集与识别上具备先天的优势,且仅需普通麦克风或其它易于集成麦克风的设备。声纹技术大幅提高了远程采集的成功率及识别的准确性,从技术上具备了远程采集与识别的可行性。
运用声纹识别技术可以在调度人员登录时进行身份确认,提高调度安全性。调控人员通过声纹认证后,调度员在语音通话中无需人工操作即可全面、快速获取上述信息,调度员通过语音交互向现场人员下达指令,并对任务指令进行闭环管理。实现对下令、现场复诵、回令内容和其他关键信息上进行安全防误判断和有效监护。利用声纹识别技术应用在调控运行实际业务中,保证受令、回令人员的资格能够通过声纹智能识别,结合持证上岗的信息,给调控运行人员进行提示,保证受令、回令人员具备相应的资格。
3.2 多人语音识别
通过独特的算法,可在多人对话场景中进行精准的声纹识别,分离出单个说话人音频,并识别出每个人的说话内容。在调度语音下令时,通过运用声纹识别技术可以辨认下令人声纹,提取下令内容,规避其他人员及背景杂音干扰,提高调度语音识别的准确率与可靠性。
4 结语
声纹识别是一种高质量的身份辨认技术,基于声纹识别技术可以实现调控中心现有调控管理工作的智能化升级,通过建立调度人员的声纹识别模型,并依此进一步实现调度人员身份认证及语音识别,最终实现通过语音的程序化成票、下令、回签、统计、查找等全部工作任务,可以大幅有效减轻人工压力,提升调控工作的执行效率。
